






线性模型与回归
线性模型一般表示为:
![]()
向量形式可表示为:
![]()

其中的W与b就是要求解的参数
通过最小二乘实现参数求解
线性回归目标:回归预测值与真实值的误差最小

因此我们需要对参数w和b求偏导求解误差最小值

求解得

对数线性回归
对数线性回归目的:通过线性模型预测非线性的复杂函数


逻辑斯蒂回归
逻辑斯蒂回归:
虽然名字是回归,但本质上是一个分类任务
sigmoid函数:
获得分类概率
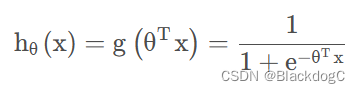

损失函数:
定义:

转化为成本函数
![]()
梯度下降
用梯度下降法来求得使代价函数最小的参数。

简单实现逻辑斯蒂回归
学习几个小时能通过考试
import torch
import torch.nn.functional as F
import numpy as np
import matplotlib.pyplot as plt
x_data = torch.tensor([[1.0],[2.0],[3.0]]) #x设置为tensor类型数据
y_data = torch.tensor([[0.0],[0.0],[1.0]]) #y设置为tensor类型数据
class LogisticRegressionModel(torch.nn.Module):
def __init__(self):
super(LogisticRegressionModel,self).__init__()
self.linear = torch.nn.Linear(1,1)
def forward(self,x):
y_pred = F.sigmoid(self.linear(x))
return y_pred
model = LogisticRegressionModel()
criterion = torch.nn.BCELoss(size_average=False)
optimizer = torch.optim.SGD(model.parameters(),lr = 0.01)
optimizer = torch.optim.SGD(model.parameters(),lr = 0.01) #定义梯度优化器为随机梯度下降
for epoch in range(10000): #训练过程
y_pred = model (x_data) #向前传播,求y_pred
loss = criterion (y_pred,y_data) #根据y_pred和y_data求损失
print(epoch,loss)
optimizer.zero_grad() #将优化器数值清零
loss.backward() #反向传播,计算梯度
optimizer.step() #根据梯度更新参数
x = np.linspace(0,10,200)
x_t = torch.Tensor(x).view((200,1))
y_t = model (x_t)
y = y_t.data.numpy()
plt.plot(x,y)
plt.plot([0,10],[0.5,0.5],c='r')
plt.xlabel = ('hours')
plt.tlabel = ("Probability of Pass")
plt.show()















 400
400











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









