







代码原理
CNN-BiLSTM-Adaboost是一个结合卷积神经网络(CNN)、双向长短期记忆网络(BiLSTM)和Adaboost算法的混合模型,用于数据回归预测。以下是该模型的简单原理及流程:
1.原理
(1)CNN(卷积神经网络):
- 主要用于提取数据的局部特征。对于时间序列数据,CNN可以通过卷积操作捕捉数据的局部时序模式。
- 通过卷积层和池化层,可以有效降低数据维度,减少计算量,同时保留重要特征。
(2)BiLSTM(双向长短期记忆网络):
- LSTM(长短期记忆网络)是一种特殊的RNN(循环神经网络),能够较好地捕捉长时间依赖关系。
- 双向LSTM通过同时考虑从前向后和从后向前的时序信息,能够更全面地捕捉数据中的时序依赖性。
(3)Adaboost(自适应增强算法):
- Adaboost是一种集成学习方法,通过结合多个弱学习器来提升预测性能。
- 在CNN和BiLSTM提取的特征基础上,Adaboost可以进一步提升回归预测的准确性。
流程
(1)数据预处理:
- 收集并清洗数据,将其标准化或归一化,以适应模型训练的需要。
- 对时间序列数据进行分割,形成训练集和测试集。
(2)特征提取(CNN部分):
- 通过卷积层提取数据的局部特征。
- 使用池化层(如最大池化或平均池化)进行降维,保留重要特征。
(3)时序特征捕捉(BiLSTM部分):
- 将CNN提取的特征输入到BiLSTM层,捕捉数据的时序依赖性。
- 通过前向和后向LSTM单元的结合,获取更加全面的时序信息。
(3)回归预测(Adaboost部分):
- 将BiLSTM层输出的特征作为输入,训练多个弱学习器。
- 使用Adaboost算法结合这些弱学习器的预测结果,形成最终的回归预测模型。
(4)模型评估与优化:
- 使用测试集评估模型的性能,计算误差指标(如均方误差、平均绝对误差等)。
- 根据评估结果,调整模型参数或架构,进一步优化模型性能。
优点
- 特征提取能力强:CNN能够有效提取数据的局部特征,BiLSTM能够捕捉长时间依赖关系,Adaboost能增强预测精度。
- 适应性强:该模型可以适应不同类型的时间序列数据。
- 预测性能好:结合多种方法,能够显著提升回归预测的准确性。
缺点
- 计算复杂度高:由于结合了多种复杂的模型,计算量较大,对硬件要求较高。
- 参数调试复杂:模型参数较多,调试起来较为复杂,需要较长的训练时间。
总结
CNN-BiLSTM-Adaboost模型通过结合卷积神经网络的特征提取能力、双向LSTM的时序依赖捕捉能力和Adaboost的集成学习优势,能够有效提升数据回归预测的准确性。其主要挑战在于计算复杂度和参数调试的复杂性。
部分代码
%% 清空环境变量
warning off % 关闭报警信息
close all % 关闭开启的图窗
clear % 清空变量
clc
%% 导入数据
data = readmatrix('回归数据集.xlsx');
data = data(:,1:14);
res=data(randperm(size(data,1)),:); %此行代码用于打乱原始样本,使训练集测试集随机被抽取,有助于更新预测结果。
num_samples = size(res,1); %样本个数
% 训练集和测试集划分
outdim = 1; % 最后一列为输出
num_size = 0.7; % 训练集占数据集比例
num_train_s = round(num_size * num_samples); % 训练集样本个数
f_ = size(res, 2) - outdim; % 输入特征维度
P_train = res(1: num_train_s, 1: f_)';
T_train = res(1: num_train_s, f_ + 1: end)';
M = size(P_train, 2);
P_test = res(num_train_s + 1: end, 1: f_)';
T_test = res(num_train_s + 1: end, f_ + 1: end)';
N = size(P_test, 2);
% 数据归一化
[p_train, ps_input] = mapminmax(P_train, 0, 1);
p_test = mapminmax('apply', P_test, ps_input);
[t_train, ps_output] = mapminmax(T_train, 0, 1);
t_test = mapminmax('apply', T_test, ps_output);
%% 数据平铺
for i = 1:size(P_train,2)
trainD{i,:} = (reshape(p_train(:,i),size(p_train,1),1,1));
end
for i = 1:size(p_test,2)
testD{i,:} = (reshape(p_test(:,i),size(p_test,1),1,1));
end
targetD = t_train;
targetD_test = t_test;
numFeatures = size(p_train,1);
layers0 = [ ...
% 输入特征
sequenceInputLayer([numFeatures,1,1],'name','input') %输入层设置
sequenceFoldingLayer('name','fold') %使用序列折叠层对图像序列的时间步长进行独立的卷积运算。
% CNN特征提取
convolution2dLayer([3,1],16,'Stride',[1,1],'name','conv1') %添加卷积层,64,1表示过滤器大小,10过滤器个数,Stride是垂直和水平过滤的步长
batchNormalizationLayer('name','batchnorm1') % BN层,用于加速训练过程,防止梯度消失或梯度爆炸
reluLayer('name','relu1') % ReLU激活层,用于保持输出的非线性性及修正梯度的问题
% 池化层
maxPooling2dLayer([2,1],'Stride',2,'Padding','same','name','maxpool') % 第一层池化层,包括3x3大小的池化窗口,步长为1,same填充方式
% 展开层
sequenceUnfoldingLayer('name','unfold') %独立的卷积运行结束后,要将序列恢复
%平滑层
flattenLayer('name','flatten')
bilstmLayer(25,'Outputmode','last','name','hidden1')
dropoutLayer(0.1,'name','dropout_1') % Dropout层,以概率为0.2丢弃输入
fullyConnectedLayer(1,'name','fullconnect') % 全连接层设置(影响输出维度)(cell层出来的输出层) %
regressionLayer('Name','output') ];
lgraph0 = layerGraph(layers0);
lgraph0 = connectLayers(lgraph0,'fold/miniBatchSize','unfold/miniBatchSize');
%% Set the hyper parameters for unet training
options0 = trainingOptions('adam', ... % 优化算法Adam
'MaxEpochs', 100, ... % 最大训练次数
'GradientThreshold', 1, ... % 梯度阈值
'InitialLearnRate', 0.01, ... % 初始学习率
'LearnRateSchedule', 'piecewise', ... % 学习率调整
'LearnRateDropPeriod',70, ... % 训练100次后开始调整学习率
'LearnRateDropFactor',0.01, ... % 学习率调整因子
'L2Regularization', 0.001, ... % 正则化参数
'ExecutionEnvironment', 'cpu',... % 训练环境
'Verbose', 1, ... % 关闭优化过程
'Plots', 'none'); % 画出曲线代码效果图
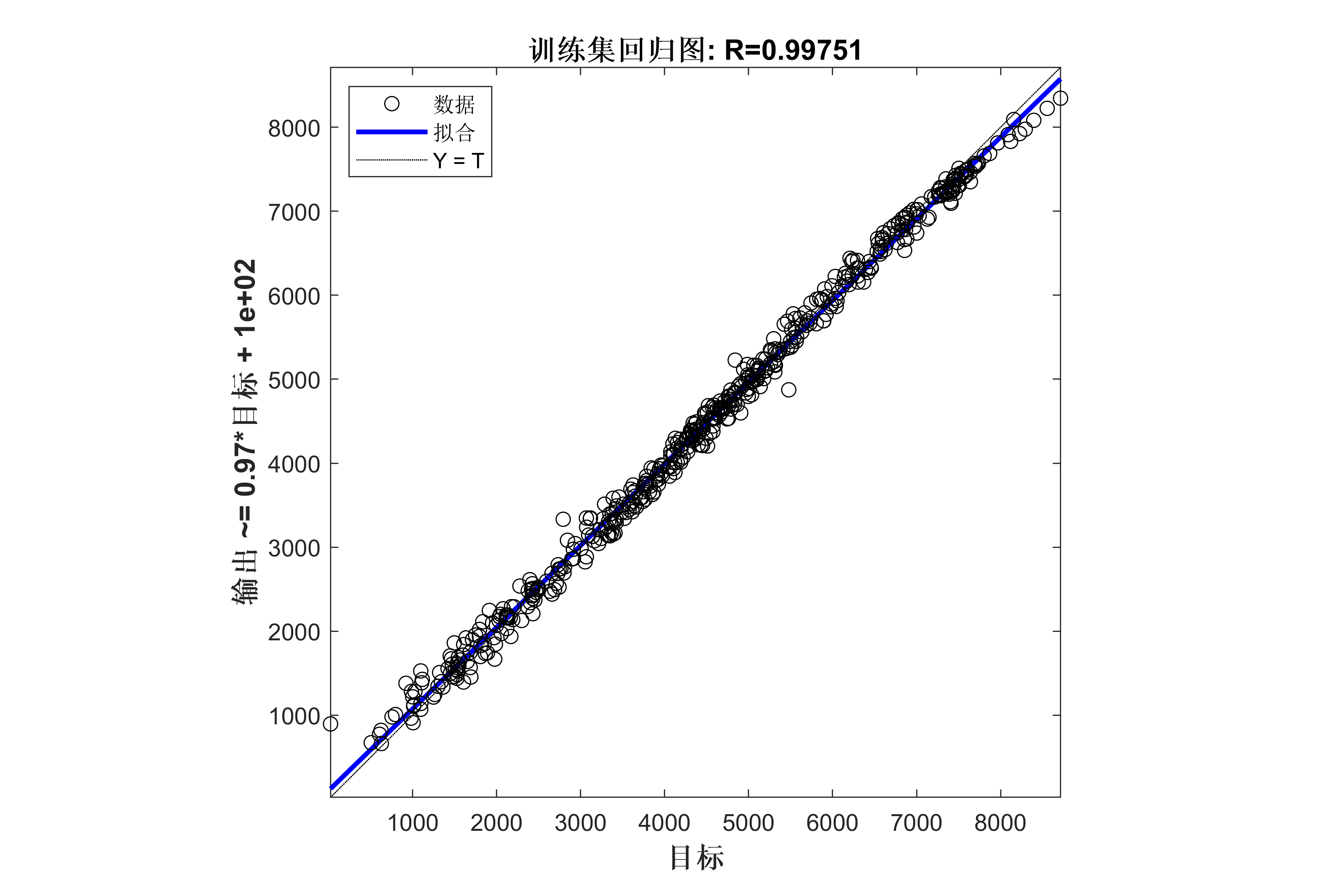
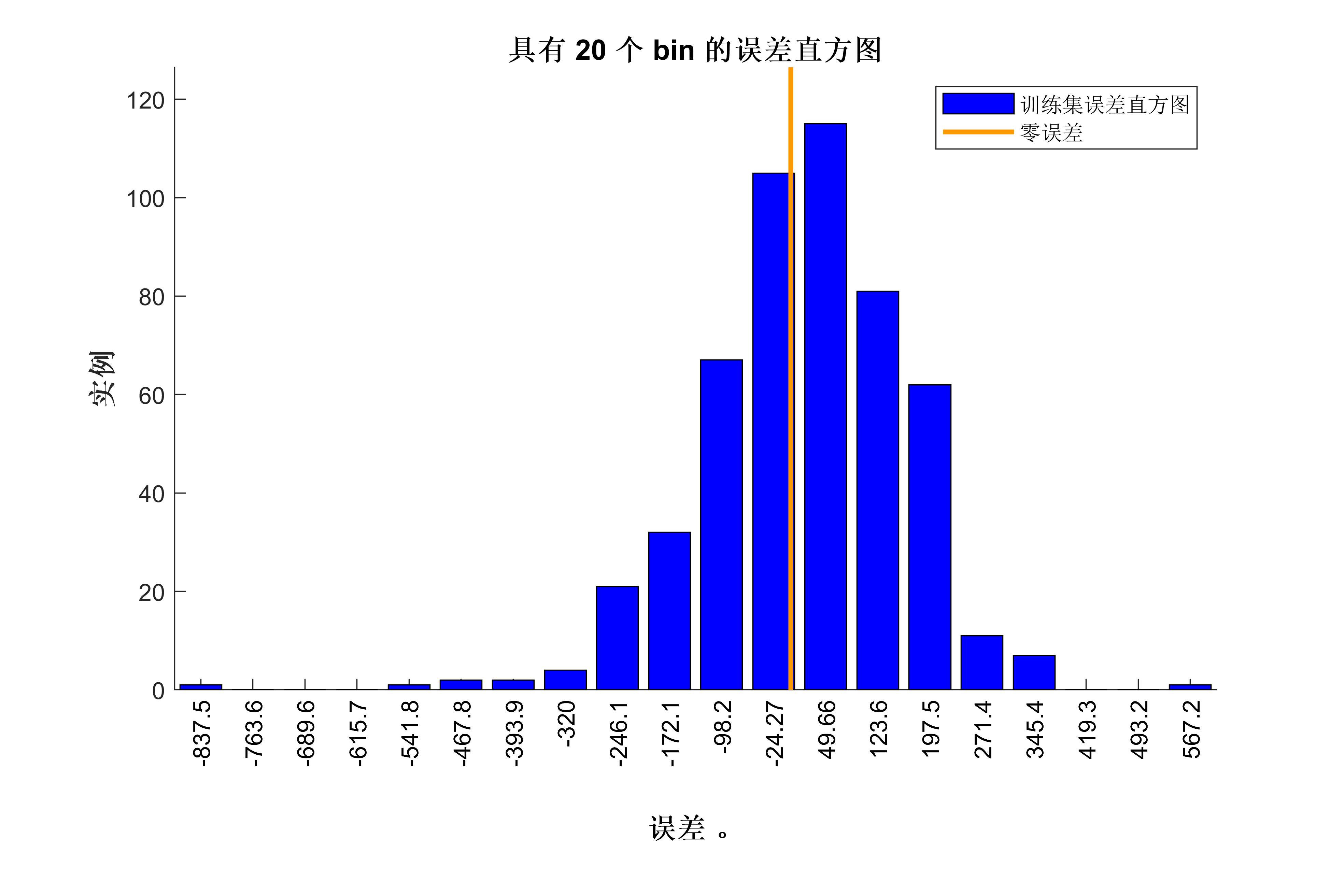
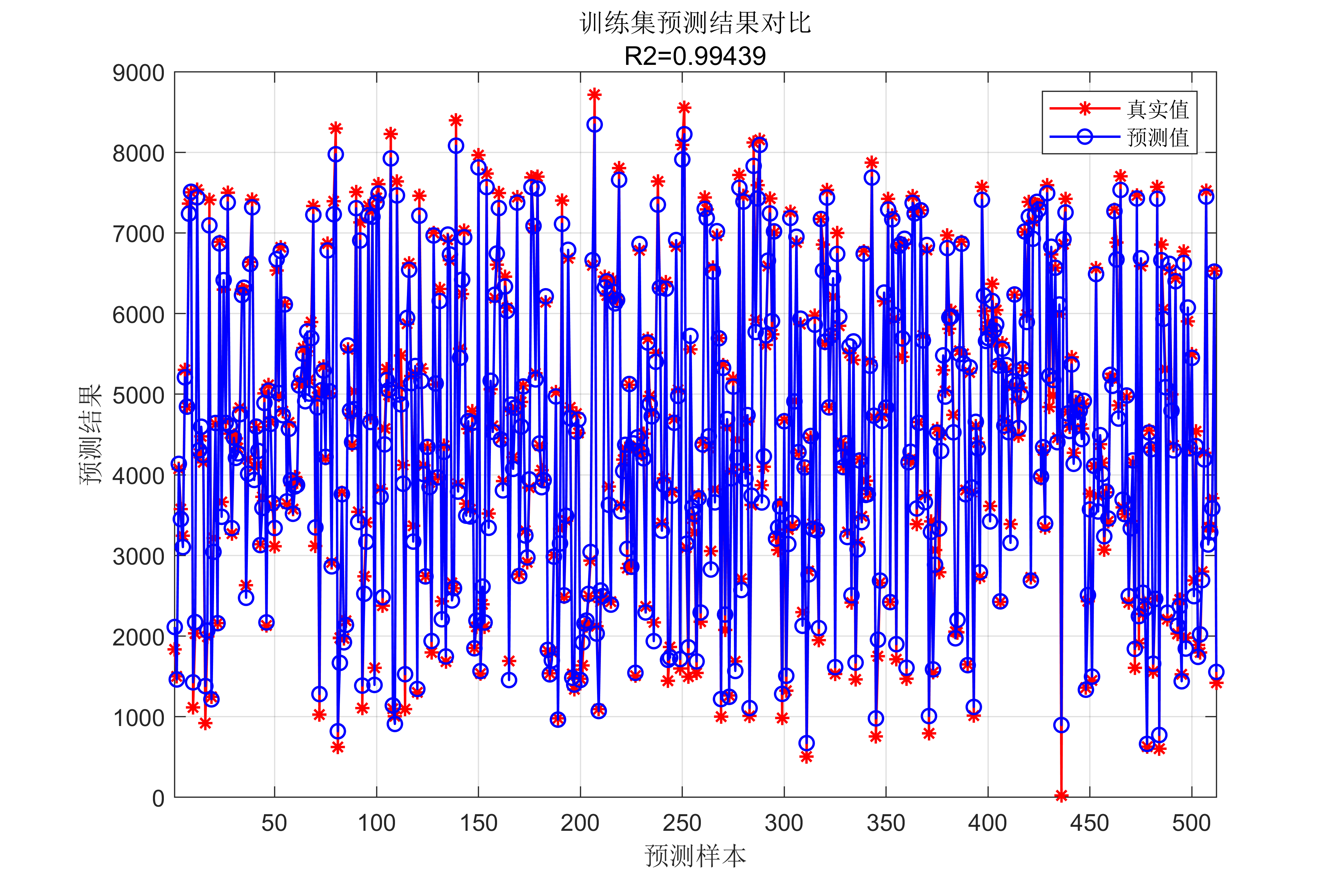
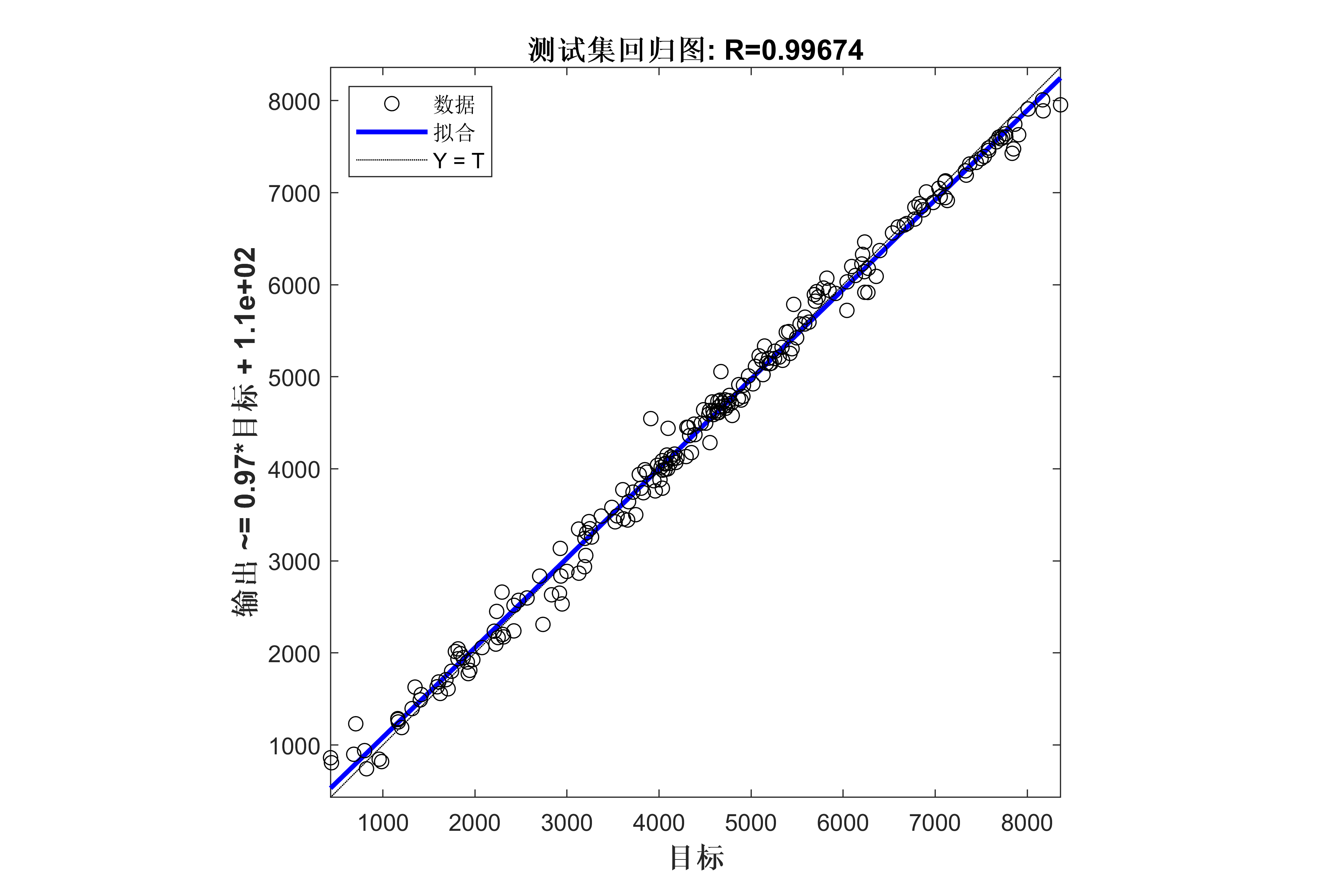
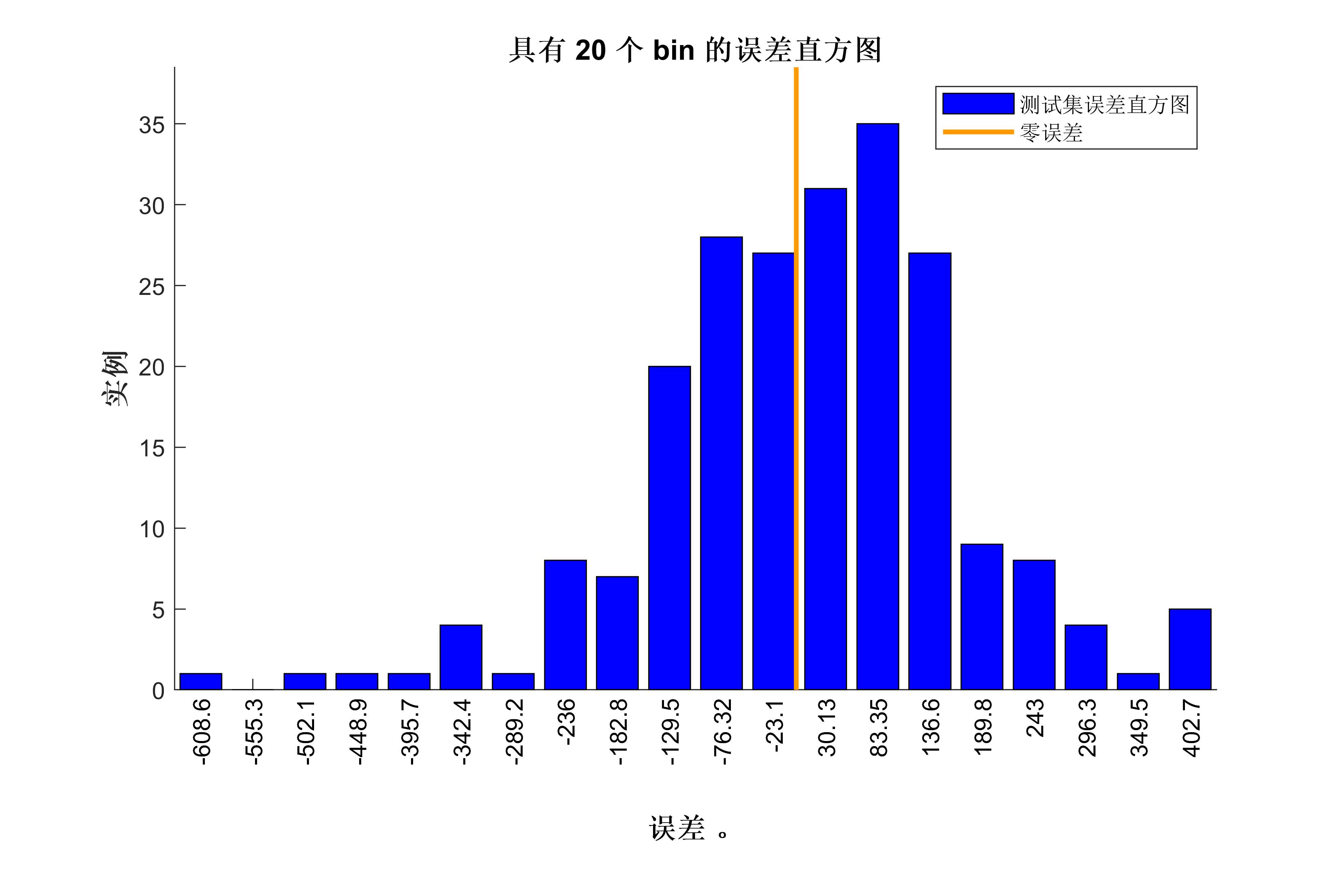


获取代码请关注MATLAB科研小白的个人公众号(即文章下方二维码),并回复数据回归预测本公众号致力于解决找代码难,写代码怵。各位有什么急需的代码,欢迎后台留言~不定时更新科研技巧类推文,可以一起探讨科研,写作,文献,代码等诸多学术问题,我们一起进步。
















 215
215











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











