






一.前言
DRQN来自于一篇2015年的论文,算是比较早的算法,内容浅显易懂。就是将传统的DQN与LSTM相结合,让智能体具有记忆的功能,最终也取得了不错的效果。在POMDP环境中的表现比DQN要好。
在看这篇文章之前假设已经对DQN有了解,并且可以看懂DQN的代码及其运行原理。如果还没有了解的话,可以去看一下https://aistudio.baidu.com/aistudio/projectdetail/2231135。这篇文章的代码也是直接在其基础上进行修改实现的。
下面是原论文链接,感兴趣的朋友可以看一下。
- https://readpaper.com/pdf-annotate/note?noteId=614295504096829440
二.原理
下面主要根据论文讨论一下相关内容
1.什么是POMDP
首先先要知道什么是MDP,MDP是马尔科夫决策过程的缩写。简单的讲就是智能体所观察到的observation等于与之交互的环境的enviroment,整个环境对智能体而言是没有秘密的。POMDP与之相对应,就是部分可观测马尔科夫决策过程,智能体所观察到的observation并不等于enviroment,它只能看到环境的一部分。通俗地说,MDP是站在上帝视角,POMDP是站在玩家视角。
2.为什么要考虑POMDP
MDP环境一般比较简单,比如在雅达利游戏中,DQN通过将四帧的输入作为特征来推断游戏的完整状态,这就使得环境成为了MDP。但在现实生活中,符合POMDP的环境占主流,现实生活所面对的环境通常都是复杂多变,难以预测,这时候就需要考虑智能体在POMDP中的表现了。
3.论文如何通过MDP构建POMDP
在论文中,作者将经典的乒乓球游戏加以改造,通过设置一个概率参数,每一帧都有一定的概率“被遮挡”,也就是画面变黑,使得智能体无法获取需要的信息来构建一个符合POMDP的环境——闪烁乒乓球游戏。
4.DRQN在POMDP上面的表现如何
论文主要通过闪烁乒乓球游戏来观察DRQN的表现。
通过可视化卷积层和LSTM层来查看效果。
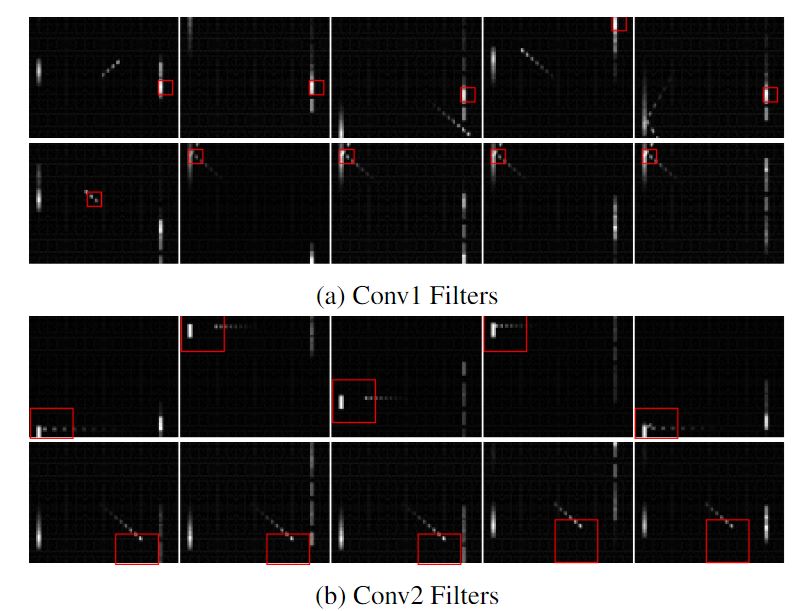

可以看到,在游戏过程中,模型也可以检测出漏球、反射等重要事件。这就表明在POMDP环境中,DRQN的性能是可以满足需求的。
即使每个时间步只输入一帧,DRQN也可以很好的完成任务,这就表明循环神经网络可以有效的整合帧与帧之间的信息,得到和多帧输入卷积层相似的结果
5.结论
不管是在MDP中训练,在POMDP中推理,还是在POMDP中训练,在MDP中推理,DRQN均可以取得良好的效果。
用DQRN训练的网络,即使在输入只有1帧的情况下也可以获得相当不俗的表现。但是不足之处是,在MDP环境中DRQN和DQN并没有太大的不同。在POMDP中也只是DQN多帧输入的一个替代。
并不具备系统性的优势。
三.网络结构与更新方式
1.网络结构
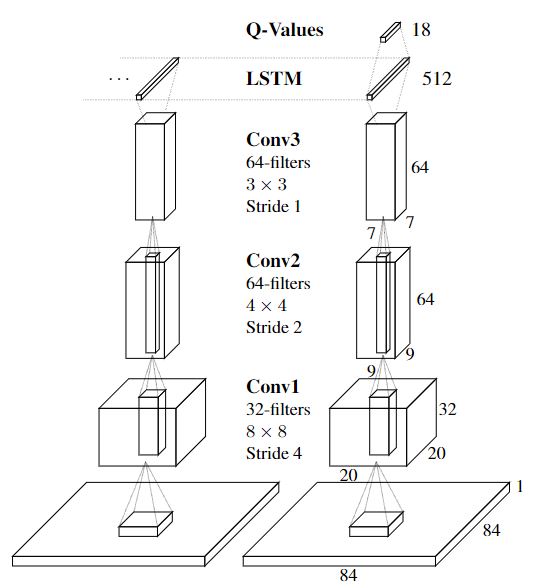
最前面是用于图像处理的卷积神经网络,经过卷积神经网络处理的图像特征输入进LSTM中,再经过LSTM处理之后输入DQN。可以看到,算法的网络结构是比较简单的。主要的就是在DQN前面加了一个LSTM层。不过在具体的代码实现和输入输出上还有一些需要注意的地方。同时,因为我们是使用第三方库进行环境的搭建,所以前面的卷积神经网络就可以省略掉,直接从LSTM层开始搭建就行。
2.更新方式
更新方式主要有两个。一个是顺序更新,在经验池中随机选择一个episode,再在该episode中随机选择一个时间点,从这个点一直运行到episode结束。顺序更新每次训练开始LSTM的状态从上一个继承。
另一个是随机更新,在经验池中随机选择一个episode,再在该episode中随机选择一个时间点,这些步骤和顺序更新一样,之后则是运行预先设定好的步长而不是到结束。乱序更新每次训练开始LSTM的隐藏层状态重置为0。
比如任选一个episode后选到了第3个步长,而该episode的一共有10步长,顺序是从第3个一直到10个。假设预先设定好了5个,那乱序就是从第3个到第8个.
论文中主要使用了乱序更新
四.代码实现
代码是直接从DQN上修改得到的。原DQN的代码在开头的链接上,可以先看一下那个,再接着往下看。
下面说一下修改的部分。
#导入会用到的第三方库
import parl
from parl.utils import logger
import paddle
import copy
import numpy as np
import os
import gym
import random
import collections
#设置会用到的超参数
learn_freq = 3 # 训练频率,不需要每一个step都learn,攒一些新增经验后再learn,提高效率
memory_warmup_size = 50 # episode_replay_memory 里需要预存一些经验数据,再开启训练
batch_size = 8 # 每次给agent learn的数据数量,从replay memory随机里sample一批数据出来
lr = 6e-4 # 学习率
gamma = 0.99 # reward 的衰减因子,一般取 0.9 到 0.999 不等
num_step=10
episode_size=500 # replay memory的大小(数据集的大小),越大越占用内存
网络开头中加了LSTM层,同时设置了一个用于初始化LSTM层的函数。因为是乱序更新,所以全部为0.
获取到的输出形状是[batch_size,num_steps,output_size],在原代码中输出形状是[batch_size,output_size],为了对齐,使用paddle.reshape将数据形状进行转换,转换并不会改变对应关系
#搭建网络
class Model(paddle.nn.Layer):
def __init__(self, obs_dim,act_dim):
super(Model,self).__init__()
self.hidden_size=64
self.first=False
self.act_dim=act_dim
# 3层全连接网络
self.fc1 = paddle.nn.Sequential(
paddle.nn.Linear(obs_dim,128),
paddle.nn.ReLU())
self.fc2 = paddle.nn.Sequential(
paddle.nn.Linear(self.hidden_size,128),
paddle.nn.ReLU())
self.fc3 = paddle.nn.Linear(128,act_dim)
self.lstm=paddle.nn.LSTM(128,self.hidden_size,1) #[input_size,hidden_size,num_layers]
def init_lstm_state(self,batch_size):
self.h=paddle.zeros(shape=[1,batch_size,self.hidden_size],dtype='float32')
self.c=paddle.zeros(shape=[1,batch_size,self.hidden_size],dtype='float32')
self.first=True
def forward(self, obs):
# 输入state,输出所有action对应的Q,[Q(s,a1), Q(s,a2), Q(s,a3)...]
obs = self.fc1(obs)
#每次训练开始前重置
if (self.first):
x,(h,c) = self.lstm(obs,(self.h,self.c)) #obs:[batch_size,num_steps,input_size]
self.first=False
else:
x,(h,c) = self.lstm(obs) #obs:[batch_size,num_steps,input_size]
x=paddle.reshape(x,shape=[-1,self.hidden_size])
h2 = self.fc2(x)
Q = self.fc3(h2)
return Q
改变了action,reward,done的形状,其他不变
#DRQN算法
class DRQN(parl.Algorithm):
def __init__(self, model, act_dim=None, gamma=None, lr=None):
self.model = model
self.target_model = copy.deepcopy(model) #复制predict网络得到target网络,实现fixed-Q-target 功能
#数据类型是否正确
assert isinstance(act_dim, int)
assert isinstance(gamma, float)
assert isinstance(lr, float)
self.act_dim = act_dim
self.gamma = gamma
self.lr = lr
self.optimizer=paddle.optimizer.Adam(learning_rate=self.lr,parameters=self.model.parameters()) # 使用Adam优化器
#预测功能
def predict(self, obs):
return self.model.forward(obs)
def learn(self, obs, action, reward, next_obs, terminal):
#将数据拉平
action=paddle.reshape(action,shape=[-1])
reward=paddle.reshape(reward,shape=[-1])
terminal=paddle.reshape(terminal,shape=[-1])
# 从target_model中获取 max Q' 的值,用于计算target_Q
next_predict_Q = self.target_model.forward(next_obs)
best_v = paddle.max(next_predict_Q, axis=-1)#next_predict_Q的每一个维度(行)都求最大值,因为每一行就对应一个St,行数就是我们输入数据的批次大小
best_v.stop_gradient = True #阻止梯度传递,因为要固定模型参数
terminal = paddle.cast(terminal, dtype='float32') #转换数据类型,转换为float32
target = reward + (1.0 - terminal) * self.gamma * best_v #Q的现实值
predict_Q = self.model.forward(obs) # 获取Q预测值
#接下来一步是获取action所对应的Q(s,a)
action_onehot = paddle.nn.functional.one_hot(action, self.act_dim) # 将action转onehot向量,比如:3 => [0,0,0,1,0]
action_onehot = paddle.cast(action_onehot, dtype='float32')
predict_action_Q = paddle.sum(
paddle.multiply(action_onehot, predict_Q) #逐元素相乘,拿到action对应的 Q(s,a)
, axis=1) #对每行进行求和运算,注意此处进行求和的真正目的其 # 比如:pred_value = [[2.3, 5.7, 1.2, 3.9, 1.4]], action_onehot = [[0,0,0,1,0]]
#实是变换维度,类似于矩阵转置。与target形式相同。 # ==> pred_action_value = [[3.9]]
# 计算 Q(s,a) 与 target_Q的均方差,得到损失。让一组的输出逼近另一组的输出,是回归问题,故用均方差损失函数
loss=paddle.nn.functional.square_error_cost(predict_action_Q, target)
cost = paddle.mean(loss)
cost.backward() #反向传播
self.optimizer.step() #更新参数
self.optimizer.clear_grad() #清除梯度
def sync_target(self):
self.target_model = copy.deepcopy(model) #复制predict网络得到target网络,实现fixed-Q-target 功能
class Agent(parl.Agent):
def __init__(self,
algorithm,
act_dim,
e_greed=0.1,
e_greed_decrement=0 ):
#判断输入数据的类型是否是int型
assert isinstance(act_dim, int)
self.act_dim = act_dim
#调用Agent父类的对象,将算法类algorithm输入进去,目的是我们可以调用algorithm中的成员
super(Agent, self).__init__(algorithm)
self.global_step = 0 #总运行步骤
self.update_target_steps = 200 # 每隔200个training steps再把model的参数复制到target_model中
self.e_greed = e_greed # 有一定概率随机选取动作,探索
self.e_greed_decrement = e_greed_decrement # 随着训练逐步收敛,探索的程度慢慢降低
#参数obs都是单条输入,与learn函数的参数不同
def sample(self, obs):
sample = np.random.rand() # 产生0~1之间的小数
if sample < self.e_greed:
act = np.random.randint(self.act_dim) # 探索:每个动作都有概率被选择
else:
act = self.predict(obs) # 选择最优动作
self.e_greed = max(
0.01, self.e_greed - self.e_greed_decrement) # 随着训练逐步收敛,探索的程度慢慢降低
return act
#通过神经网络获取输出
def predict(self, obs): # 选择最优动作
obs=paddle.to_tensor(obs,dtype='float32') #将目标数组转换为张量
predict_Q=self.alg.predict(obs).numpy() #将结果张量转换为数组
act = np.argmax(predict_Q) # 选择Q最大的下标,即对应的动作
return act
#这里的learn函数主要包括两个功能。1.同步模型参数2.更新模型。这两个功能都是通过调用algorithm算法里面的函数最终实现的。
#注意,此处输入的参数均是一批数据组成的数组
def learn(self, obs, act, reward, next_obs, terminal):
# 每隔200个training steps同步一次model和target_model的参数
if self.global_step % self.update_target_steps == 0:
self.alg.sync_target()
self.global_step += 1 #每执行一次learn函数,总次数+1
#转换为张量
obs=paddle.to_tensor(obs,dtype='float32')
act=paddle.to_tensor(act,dtype='int32')
reward=paddle.to_tensor(reward,dtype='float32')
next_obs=paddle.to_tensor(next_obs,dtype='float32')
terminal=paddle.to_tensor(terminal,dtype='float32')
#进行学习
self.alg.learn(obs, act, reward, next_obs, terminal)
因为DRQN需要的数据是从一整个episode中采样,所以数据集中的每一个数据都要是一个episode。因此对经验池类进行了改写,原类收集每一step的功能不变,同时每一step都判断是不是一个episode的最后一步,即done是否为True。再新建一个episodemomery类,将所有的episode输入进去,随机挑选一个时间步进行处理
class EpisodeMemory(object):
def __init__(self,episode_size,num_step):
self.buffer = collections.deque(maxlen=episode_size)
self.num_step=num_step #时间步长
def put(self,episode):
self.buffer.append(episode)
def sample(self,batch_size):
mini_batch = random.sample(self.buffer, batch_size) #返回值是个列表
obs_batch, action_batch, reward_batch, next_obs_batch, done_batch = [], [], [], [], []
for experience in mini_batch:
self.num_step = min(self.num_step, len(experience)) #防止序列长度小于预定义长度
for experience in mini_batch:
idx = np.random.randint(0, len(experience)-self.num_step+1) #随机选取一个时间步的id
s, a, r, s_p, done = [],[],[],[],[]
for i in range(idx,idx+self.num_step):
e1,e2,e3,e4,e5=experience[i][0]
s.append(e1[0][0]),a.append(e2),r.append(e3),s_p.append(e4),done.append(e5)
obs_batch.append(s)
action_batch.append(a)
reward_batch.append(r)
next_obs_batch.append(s_p)
done_batch.append(done)
#转换数据格式
obs_batch=np.array(obs_batch).astype('float32')
action_batch=np.array(action_batch).astype('float32')
reward_batch=np.array(reward_batch).astype('float32')
next_obs_batch=np.array(next_obs_batch).astype('float32')
done_batch=np.array(done_batch).astype('float32')
#将列表转换为数组并转换数据类型
return obs_batch,action_batch,reward_batch,next_obs_batch,done_batch
#输出队列的长度
def __len__(self):
return len(self.buffer)
class ReplayMemory(object):
def __init__(self,e_rpm):
#创建一个固定长度的队列作为缓冲区域,当队列满时,会自动删除最老的一条信息
self.e_rpm=e_rpm
self.buff=[]
# 增加一条经验到经验池中
def append(self,exp,done):
self.buff.append([exp])
#将一整个episode添加进经验池
if(done):
self.e_rpm.put(self.buff)
self.buff=[]
#输出队列的长度
def __len__(self):
return len(self.buff)
设定每间隔一定episode就训练一次同时跳出循环。每次训练之前重新初始化LSTM的隐藏层参数
# 训练一个episode
def run_episode(env, agent, rpm, e_rpm, obs_shape): #rpm就是经验池
for step in range(1,learn_freq+1):
#重置环境
obs = env.reset()
while True:
obs=obs.reshape(1,1,obs_shape)
action = agent.sample(obs) # 采样动作,所有动作都有概率被尝试到
next_obs, reward, done, _ = env.step(action)
rpm.append((obs, action, reward, next_obs, done),done) #搜集数据
obs = next_obs
if done:
break
#存储足够多的经验之后按照间隔进行训练
if (len(e_rpm) > memory_warmup_size):
#每次训练之前重置LSTM参数
model.init_lstm_state(batch_size)
(batch_obs, batch_action, batch_reward, batch_next_obs,batch_done) = e_rpm.sample(batch_size)
agent.learn(batch_obs, batch_action, batch_reward,batch_next_obs,batch_done) # s,a,r,s',done
# 评估 agent, 跑 5 个episode,总reward求平均
def evaluate(env, agent, obs_shape,render=False):
eval_reward = [] #列表存储所有episode的reward
for i in range(5):
obs = env.reset()
episode_reward = 0
while True:
obs=obs.reshape(1,1,obs_shape)
action = agent.predict(obs) # 预测动作,只选最优动作
obs, reward, done, _ = env.step(action)
episode_reward += reward
if render:
env.render()
if done:
break
eval_reward.append(episode_reward)
return np.mean(eval_reward) #求平均值
env = gym.make('CartPole-v1')
action_dim = env.action_space.n
obs_shape = env.observation_space.shape
save_path = './dqn_model.ckpt'
e_rpm=EpisodeMemory(episode_size,num_step)
rpm = ReplayMemory(e_rpm) # 实例化DQN的经验回放池
# 根据parl框架构建agent
model = Model(obs_dim=obs_shape[0],act_dim=action_dim)
algorithm = DRQN(model, act_dim=action_dim, gamma=gamma, lr=lr)
agent = Agent(
algorithm,
act_dim=action_dim,
e_greed=0.1, # 有一定概率随机选取动作,探索
e_greed_decrement=8e-7) # 随着训练逐步收敛,探索的程度慢慢降低
# 先往经验池里存一些数据,避免最开始训练的时候样本丰富度不够
while len(e_rpm) < memory_warmup_size:
run_episode(env, agent, rpm,e_rpm,obs_shape[0])
#定义训练次数
max_train_num = 2000
best_acc=377.0
agent.restore(save_path)
# 开始训练
train_num = 0
while train_num < max_train_num: # 训练max_episode个回合,test部分不计算入episode数量
# train part
#for循环的目的是每50次进行一下测试
for i in range(0, 50):
run_episode(env, agent,rpm, e_rpm,obs_shape[0])
train_num += 1
# test part
eval_reward = evaluate(env, agent,obs_shape[0], render=False) #render=True 查看显示效果
if eval_reward>best_acc:
best_acc=eval_reward
agent.save(save_path)
#将信息写入日志文件
logger.info('train_num:{} e_greed:{} test_reward:{}'.format(
train_num, agent.e_greed, eval_reward))
e(env, agent,obs_shape[0], render=False) #render=True 查看显示效果
if eval_reward>best_acc:
best_acc=eval_reward
agent.save(save_path)
#将信息写入日志文件
logger.info('train_num:{} e_greed:{} test_reward:{}'.format(
train_num, agent.e_greed, eval_reward))
[32m[10-30 21:27:56 MainThread @machine_info.py:88][0m nvidia-smi -L found gpu count: 1
/opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages/paddle/fluid/dygraph/layers.py:1301: UserWarning: Skip loading for fc1.0.weight. fc1.0.weight receives a shape [64, 128], but the expected shape is [4, 128].
warnings.warn(("Skip loading for {}. ".format(key) + str(err)))
/opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages/paddle/fluid/dygraph/layers.py:1301: UserWarning: Skip loading for fc2.0.weight. fc2.0.weight receives a shape [128, 128], but the expected shape is [64, 128].
warnings.warn(("Skip loading for {}. ".format(key) + str(err)))
/opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages/paddle/fluid/dygraph/layers.py:1301: UserWarning: Skip loading for lstm.weight_ih_l0. lstm.weight_ih_l0 receives a shape [256, 4], but the expected shape is [256, 128].
warnings.warn(("Skip loading for {}. ".format(key) + str(err)))
/opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages/paddle/fluid/dygraph/layers.py:1301: UserWarning: Skip loading for lstm.0.cell.weight_ih. lstm.0.cell.weight_ih receives a shape [256, 4], but the expected shape is [256, 128].
warnings.warn(("Skip loading for {}. ".format(key) + str(err)))
[32m[10-30 21:27:59 MainThread @<ipython-input-9-4c51392c320d>:45][0m train_num:50 e_greed:0.09840000000000951 test_reward:10.0
[32m[10-30 21:28:01 MainThread @<ipython-input-9-4c51392c320d>:45][0m train_num:100 e_greed:0.09717920000001676 test_reward:9.8
[32m[10-30 21:28:04 MainThread @<ipython-input-9-4c51392c320d>:45][0m train_num:150 e_greed:0.09591920000002424 test_reward:10.2
[32m[10-30 21:28:07 MainThread @<ipython-input-9-4c51392c320d>:45][0m train_num:200 e_greed:0.0944768000000328 test_reward:11.0
[32m[10-30 21:28:09 MainThread @<ipython-input-9-4c51392c320d>:45][0m train_num:250 e_greed:0.09330160000003979 test_reward:9.0
[32m[10-30 21:28:12 MainThread @<ipython-input-9-4c51392c320d>:45][0m train_num:300 e_greed:0.09211440000004684 test_reward:9.0
[32m[10-30 21:28:14 MainThread @<ipython-input-9-4c51392c320d>:45][0m train_num:350 e_greed:0.09093200000005386 test_reward:9.6
[32m[10-30 21:28:17 MainThread @<ipython-input-9-4c51392c320d>:45][0m train_num:400 e_greed:0.08976000000006082 test_reward:9.2
[32m[10-30 21:28:19 MainThread @<ipython-input-9-4c51392c320d>:45][0m train_num:450 e_greed:0.0885680000000679 test_reward:9.8
[32m[10-30 21:28:22 MainThread @<ipython-input-9-4c51392c320d>:45][0m train_num:500 e_greed:0.087371200000075 test_reward:9.2
[32m[10-30 21:28:24 MainThread @<ipython-input-9-4c51392c320d>:45][0m train_num:550 e_greed:0.08620640000008192 test_reward:9.6
[32m[10-30 21:28:27 MainThread @<ipython-input-9-4c51392c320d>:45][0m train_num:600 e_greed:0.0850312000000889 test_reward:9.4
[32m[10-30 21:28:29 MainThread @<ipython-input-9-4c51392c320d>:45][0m train_num:650 e_greed:0.08388160000009573 test_reward:9.4
[32m[10-30 21:28:32 MainThread @<ipython-input-9-4c51392c320d>:45][0m train_num:700 e_greed:0.08273040000010257 test_reward:9.6
[32m[10-30 21:28:34 MainThread @<ipython-input-9-4c51392c320d>:45][0m train_num:750 e_greed:0.0815128000001098 test_reward:9.8
[32m[10-30 21:28:37 MainThread @<ipython-input-9-4c51392c320d>:45][0m train_num:800 e_greed:0.08027520000011715 test_reward:9.8
[32m[10-30 21:28:40 MainThread @<ipython-input-9-4c51392c320d>:45][0m train_num:850 e_greed:0.07881680000012581 test_reward:10.6
[32m[10-30 21:28:44 MainThread @<ipython-input-9-4c51392c320d>:45][0m train_num:900 e_greed:0.07678400000013788 test_reward:13.0
[32m[10-30 21:28:48 MainThread @<ipython-input-9-4c51392c320d>:45][0m train_num:950 e_greed:0.07478480000014975 test_reward:9.0
[32m[10-30 21:28:53 MainThread @<ipython-input-9-4c51392c320d>:45][0m train_num:1000 e_greed:0.07232720000016435 test_reward:12.0
[32m[10-30 21:28:57 MainThread @<ipython-input-9-4c51392c320d>:45][0m train_num:1050 e_greed:0.07040160000017578 test_reward:9.4
[32m[10-30 21:29:03 MainThread @<ipython-input-9-4c51392c320d>:45][0m train_num:1100 e_greed:0.06750000000019302 test_reward:105.2
[32m[10-30 21:29:23 MainThread @<ipython-input-9-4c51392c320d>:45][0m train_num:1150 e_greed:0.057448000000208894 test_reward:86.2
[32m[10-30 21:29:38 MainThread @<ipython-input-9-4c51392c320d>:45][0m train_num:1200 e_greed:0.04959200000018741 test_reward:53.2
[32m[10-30 21:30:08 MainThread @<ipython-input-9-4c51392c320d>:45][0m train_num:1250 e_greed:0.03536800000014851 test_reward:376.2
[32m[10-30 21:30:53 MainThread @<ipython-input-9-4c51392c320d>:45][0m train_num:1300 e_greed:0.012563200000160545 test_reward:142.4
[32m[10-30 21:31:24 MainThread @<ipython-input-9-4c51392c320d>:45][0m train_num:1350 e_greed:0.01 test_reward:16.2
[32m[10-30 21:31:53 MainThread @<ipython-input-9-4c51392c320d>:45][0m train_num:1400 e_greed:0.01 test_reward:189.2
[32m[10-30 21:32:20 MainThread @<ipython-input-9-4c51392c320d>:45][0m train_num:1450 e_greed:0.01 test_reward:177.8
[32m[10-30 21:32:58 MainThread @<ipython-input-9-4c51392c320d>:45][0m train_num:1500 e_greed:0.01 test_reward:119.8
[32m[10-30 21:33:36 MainThread @<ipython-input-9-4c51392c320d>:45][0m train_num:1550 e_greed:0.01 test_reward:192.8
[32m[10-30 21:34:37 MainThread @<ipython-input-9-4c51392c320d>:45][0m train_num:1600 e_greed:0.01 test_reward:200.6
[32m[10-30 21:35:13 MainThread @<ipython-input-9-4c51392c320d>:45][0m train_num:1650 e_greed:0.01 test_reward:19.4
[32m[10-30 21:36:00 MainThread @<ipython-input-9-4c51392c320d>:45][0m train_num:1700 e_greed:0.01 test_reward:181.8
[32m[10-30 21:36:47 MainThread @<ipython-input-9-4c51392c320d>:45][0m train_num:1750 e_greed:0.01 test_reward:139.2
[32m[10-30 21:37:43 MainThread @<ipython-input-9-4c51392c320d>:45][0m train_num:1800 e_greed:0.01 test_reward:193.8
[32m[10-30 21:38:50 MainThread @<ipython-input-9-4c51392c320d>:45][0m train_num:1850 e_greed:0.01 test_reward:322.4
[32m[10-30 21:40:11 MainThread @<ipython-input-9-4c51392c320d>:45][0m train_num:1900 e_greed:0.01 test_reward:500.0
[32m[10-30 21:41:29 MainThread @<ipython-input-9-4c51392c320d>:45][0m train_num:1950 e_greed:0.01 test_reward:438.4
[32m[10-30 21:42:43 MainThread @<ipython-input-9-4c51392c320d>:45][0m train_num:2000 e_greed:0.01 test_reward:500.0
效果还算不错,但看得出来,目前的参数还不是最优参数,仍然有可以改进的空间,可以尝试调整一下给出的超参数。模型可以在更少的时间里得到更好的效果
空间中已经有训练好的模型,不想训练可以直接加载使用。
个人简介
作者:王祯皓
东北大学秦皇岛分校2020级计算机科学与技术本科生
感兴趣方向:CV、RL
我在AI Studio上获得白银等级,点亮2个徽章,来














 5872
5872











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









