






★★★ 本文源自AI Studio社区精品项目,【点击此处】查看更多精品内容 >>>
摘要
最近,信道注意机制被证明在提高深度卷积神经网络(CNN)的性能方面具有巨大潜力。然而,大多数现有方法都致力于开发更复杂的注意力模块以实现更好的性能,这不可避免地增加了模型的复杂性。为了克服性能和复杂性权衡的矛盾,本文提出了一种高效信道注意力(ECA)模块,该模块只涉及少数参数,同时带来了明显的性能增益。通过剖析SENet中的通道注意模块,我们从经验上表明,避免降维对于学习通道注意很重要,适当的跨通道交互可以在显著降低模型复杂性的同时保持性能。因此,我们提出了一种无降维的局部跨信道交互策略,该策略可以通过1D卷积有效地实现。此外,我们开发了一种自适应地选择1D卷积的核大小的方法,以确定本地跨信道交互的覆盖范围。所提出的ECA模块是高效而有效的,例如,我们的模块对ResNet50主干的参数和计算分别为80对24.37M和4.7e-4 GFLOP对3.86 GFLOP,并且在Top-1精度方面性能提升超过2%。我们使用ResNets和MobileNetV2的主干对我们的ECA模块在图像分类、对象检测和实例分割方面进行了广泛的评估。实验结果表明,我们的模块效率更高,性能优于同类模块。
1 Introduction
这一部分我并没有进行简单的概述,旨在让小白对注意力机制的发展有一定的了解
深度卷积神经网络(CNN)已广泛应用于计算机视觉领域,在图像分类、对象检测和语义分割等广泛的任务中取得了巨大进展。从开创性的AlexNet开始,许多研究正在持续进行,以进一步提高深度神经网络的性能。最近,将信道注意力纳入卷积块引起了很多兴趣,在性能改进方面显示出巨大潜力。代表性方法之一是挤压和激励网络(SENet),它学习每个卷积块的信道注意力,为各种深度CNN架构带来明显的性能增益。
作者想在计算精度和需要的计算量之间做一个更好的兼容,提出了以下思路
首先回顾SENet中的频道关注模块。具体而言,给定输入特征,SE块首先独立地为每个信道使用全局平均池,然后使用两个具有非线性的完全连接(FC)层,然后使用Sigmoid函数生成信道权重。两个FC层被设计为捕获非线性跨信道交互,这涉及降维以控制模型复杂性。尽管该策略在随后的渠道注意力模块中被广泛使用,但我们的实证研究表明,降维会对渠道注意力预测产生副作用,而且捕获所有渠道的依赖性是低效的,也是不必要的。
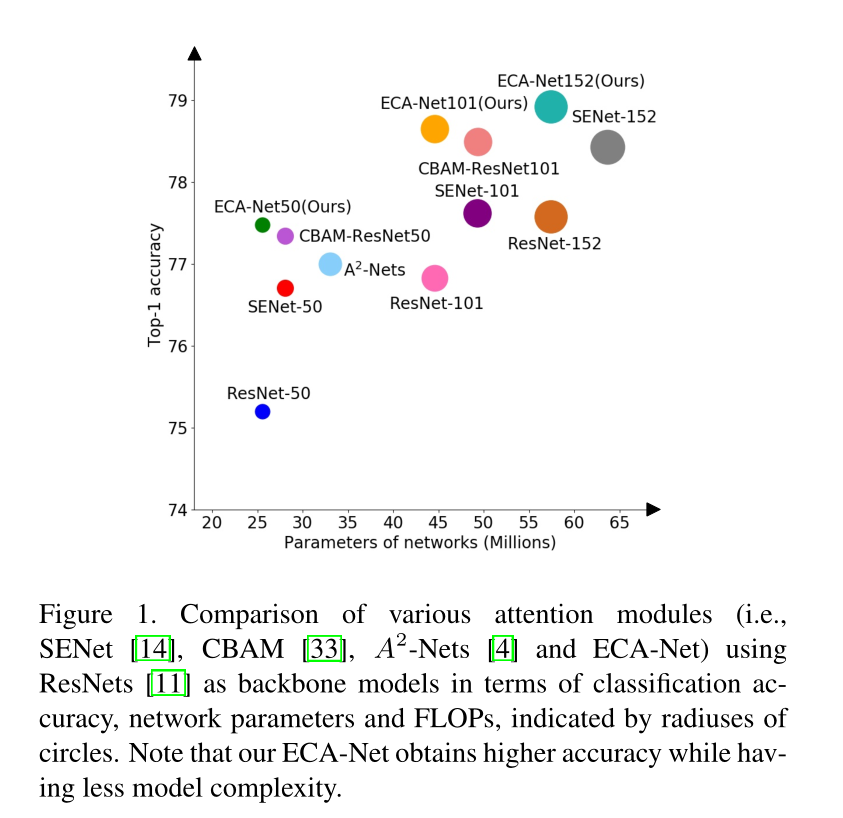
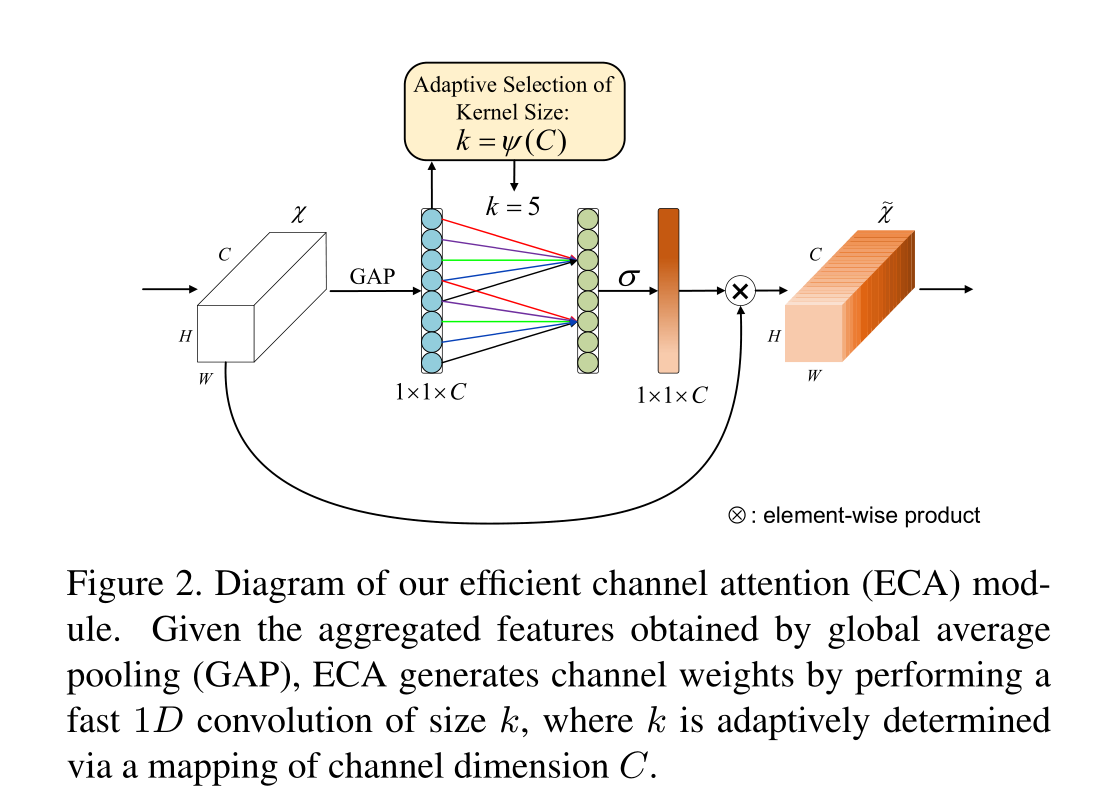
因此,本文提出了一种用于深度神经网络的高效通道注意(ECA)模块,该模块避免了维度降低,并以有效的方式捕获跨通道交互。如图2所示,在没有降维的信道化全局平均池之后,我们的ECA通过考虑每个信道及其k个邻居来捕获局部跨信道交互。这种方法被证明既保证了效率又保证了有效性。注意,我们的ECA可以通过大小为k的快速1D卷积来有效地实现,其中内核大小k表示本地跨信道交互的覆盖范围,即有多少邻居参与了一个信道的注意力预测。为了避免通过交叉验证手动调整k,我们开发了一种自适应确定k的方法,其中交互覆盖(即内核大小k)与信道维度成比例。如图1和表3所示,ECA的深度卷积模块(称为ECA Net)引入了很少的附加参数和可忽略的计算,同时带来了显著的性能增益。例如,对于具有24.37M参数和3.86 GFLOP的ResNet-50,ECA-Net50的附加参数和计算分别为80和4.7e4GFLOP;同时,ECA-Net50在Top-1精度方面优于ResNet-50 2.28%。表1总结了现有的注意力模块,包括渠道维度降低(DR)、跨渠道互动和轻量级模型,其中我们可以看到,我们的ECA模块通过避免渠道维度降低,同时以极其轻量级的方式捕获跨渠道互动,来学习有效的渠道注意力。为了评估我们的方法,我们使用不同的深度CNN架构在多种任务中对ImageNet-1K和MS COCO进行了实验。
本文的创新点
(1) 从经验上证明了避免维度降低和适当的跨渠道互动对于学习有效和高效的渠道注意力分别很重要。
(2) 提出一种高效的渠道关注(ECA)来开发一种用于深度CNNs的极其轻量级的渠道关注模块,该模块在带来明显改进的同时,几乎不增加模型复杂性。
(3) 在ImageNet-1K和MS COCO上的实验结果表明,我们的方法具有比现有技术更低的模型复杂度,同时实现了非常有竞争力的性能。
2 Related Work
注意力机制已被证明是增强深度神经网络的潜在手段。SE Net首次提出了一种学习渠道注意力的有效机制,并取得了令人满意的性能。随后,注意力模块的发展大致可以分为两个方向:
(1)增强特征聚合;
(2) 渠道和空间关注的结合。
介绍了一些注意力机制的方法,但要么存在精度高但是模型复杂,参数量大,轻量化的效果反而不理想,本文的方法刚好做出了两者的兼容
我们的方法研究了具有自适应核大小的1D卷积来替换信道关注模块中的FC层。与组和深度可分离卷积相比,我们的方法以较低的模型复杂度获得了更好的性能。
3 Proposed Method
这个部分应当是论文的重点了
1.回顾SENet中的通道注意模块(即SE块)。
2.提出ECA模块。
3.开发了一种自适应确定ECA参数的方法,并最终展示了如何将其用于深度神经网络。
3.1 Revisiting Channel Attention in SE Block
这部分回顾了SE block并指出了其缺点:
虽然方程中的降维可以降低模型复杂性,但它破坏了信道与其权重之间的直接对应关系。例如,一个FC层使用所有信道的线性组合来预测每个信道的权重。但等式(2)首先将通道特征投影到低维空间中,然后将其映射回去,使通道与其权重之间的对应是间接的。
3.2 Eficient Channel Attention (ECA) Module
在重新回顾SE块之后,进行了实证比较,以分析渠道维度降低和跨渠道互动对渠道注意力学习的影响。最后提出了我们的有效渠道关注(ECA)模块。
3.2.1 A voiding Dimensionality Reduction
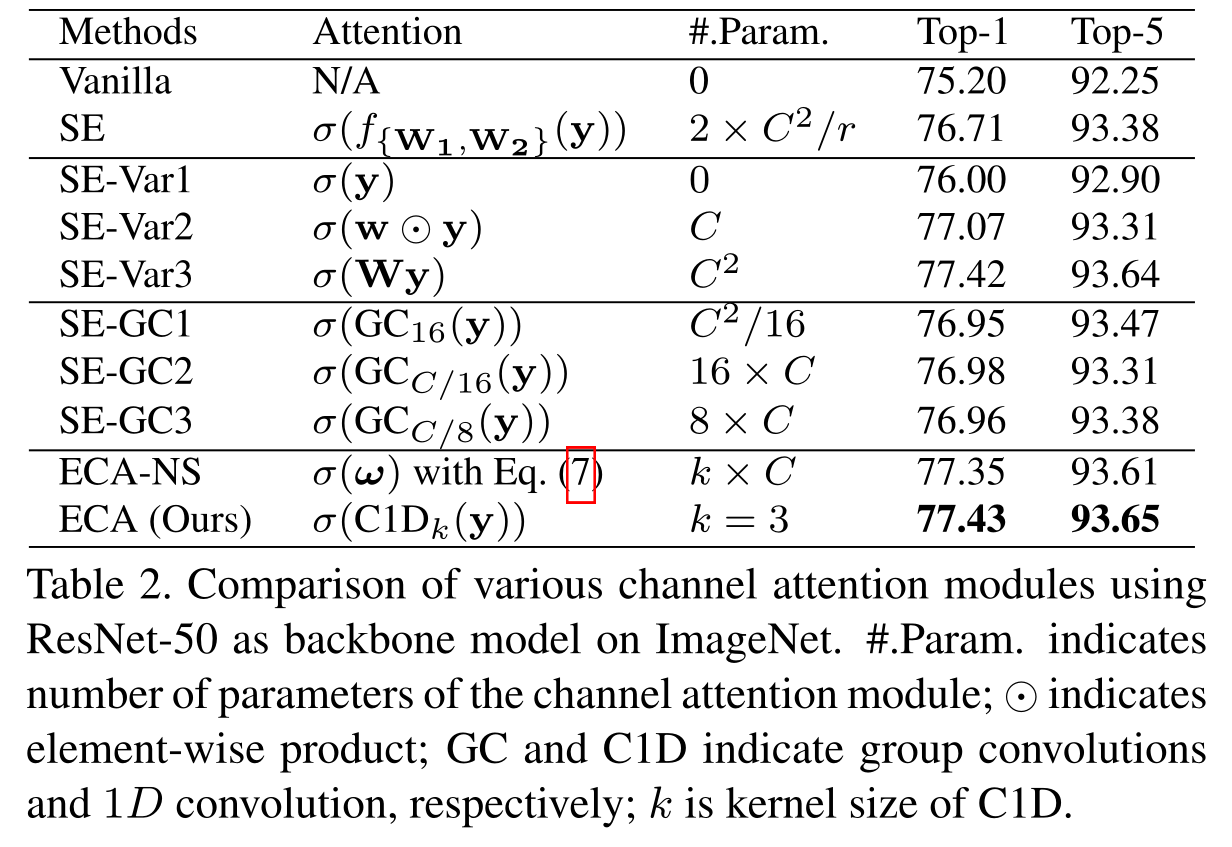
将原始SE块与其三个变体(即SE-Var1、SE-Var2和SEV-ar3)进行了比较,这三个变体都不执行降维。实验结果说明没有参数的SE-V ar1仍然优于原始网络,表明信道关注有能力提高深度CNN的性能
通过将SE-Var2独立地学习每个信道的权重,这在涉及较少参数的情况下略优于SE块。这个说明信道及其权重需要直接对应,而避免降维比考虑非线性信道相关性更重要
通过实验结果清楚地表明,避免降维,信道权重直接对应都是很中国要的
3.2.2 Local Cross-Channel Interaction
实验表明,跨信道交互有利于学习信道注意力,实现更好的网络性能,而以往的方法会出现参数量大,模型复杂度高,增加存储器访问成本,降低计算效率的问题,作者就提出了自己的方法
在本文中,我们探索了另一种捕获本地跨信道交互的方法,旨在确保效率和有效性。特别地,我们使用频带矩阵Wk来学习信道注意力在本文中,我们探索了另一种捕获本地跨信道交互的方法,旨在确保效率和有效性。特别地,我们使用频带矩阵Wk来学习信道注意力
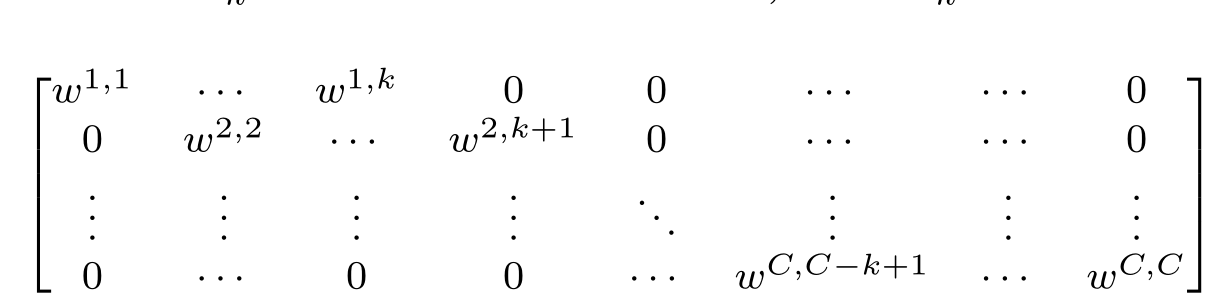
方程(6)中的Wk涉及k×C参数,通常小于方程(5)中的参数。此外,等式(6)避免了等式(5)中不同组之间的完全独立性。如表2所示,等式(6)中的方法(即ECA-NS)优于等式(5)中的SE-GC。对于等式(6),通过仅考虑yi与其k个邻居之间的相互作用来计算yi的权重
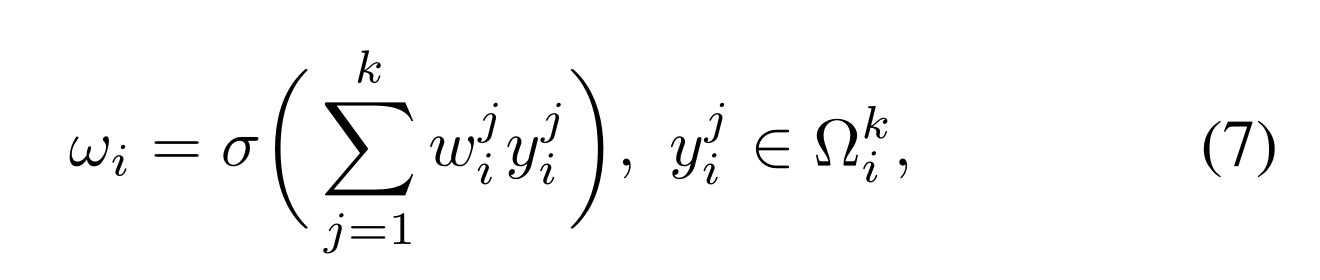
Ωki表示yi的k个相邻信道的集合
更有效的方法是使所有通道共享相同的学习参数更有效的方法是使所有通道共享相同的学习参数
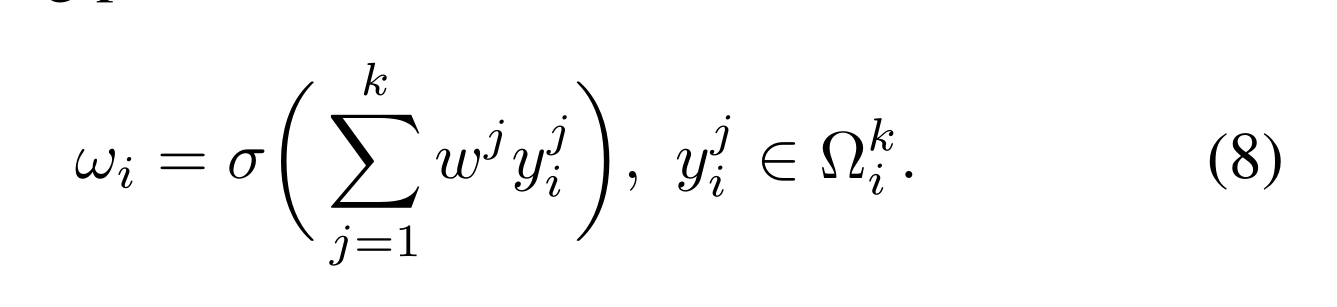
注意,这种策略可以很容易地通过核大小为k的快速1D卷积来实现
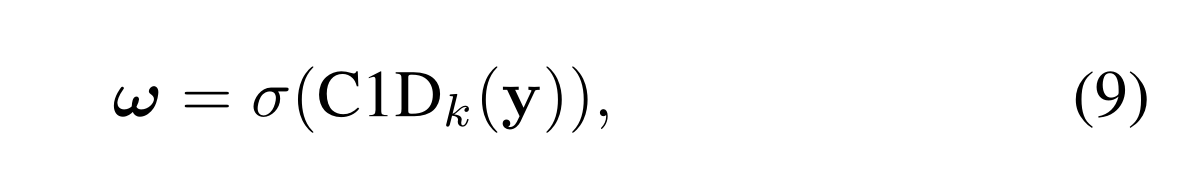
上图是对本文提出的种捕获本地跨信道交互的方法的介绍,使用了频带矩阵Wk来学习信道注意力,使所有信道共享相同的学习参数,结果表明ECA模块(k=3)实现了与SE-var3相似的结果,同时具有更低的模型复杂性,这通过适当地捕获本地跨信道交互来保证效率和有效性。论文发现了1D卷积的核大小k与信道维度C成比例。
3.2.3 Coverage of Local Cross-Channel Interaction
对于不同CNN架构中具有不同信道号的卷积块,可以手动调整交互的优化覆盖范围。然而,通过交叉验证进行手动调整将耗费大量计算资源,作者提出了自动计算内核大小k(也就是1D卷积核的大小)方法公式
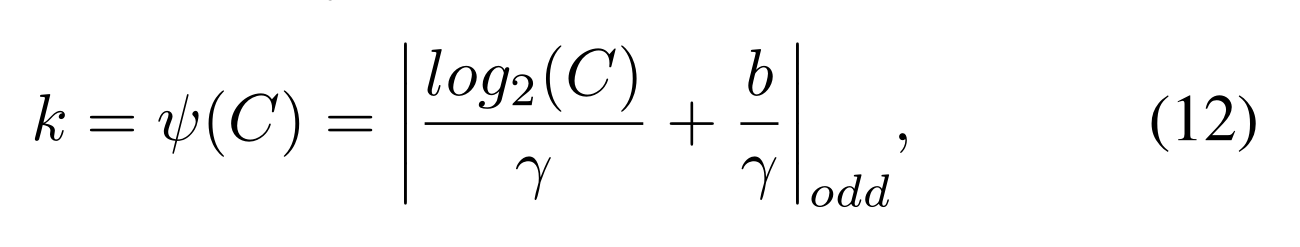
其中|t|odd表示t的最近奇数。将γ和b分别设置为2和1。
3.3 ECA Module for Deep CNNs
介绍了一下ECA模块的代码逻辑
在使用没有降维的GAP聚合卷积特征之后,ECA模块首先自适应地确定内核大小k,然后执行1D卷积,然后执行Sigmoid函数以学习信道注意力。为了将我们的ECA应用于深度神经网络,我们按照中的相同配置将SE模块替换为ECA模块。由此产生的网络由ECA Net命名。Figure3给出了ECA的PyTorch代码

class eca_layer(nn.Layer):
"""Constructs a ECA module.
Args:
channel: Number of channels of the input feature map
k_size: Adaptive selection of kernel size
"""
def __init__(self, channel=1, k_size=3):
super(eca_layer, self).__init__()
self.avg_pool = nn.AdaptiveAvgPool2D(1)
self.conv = nn.Conv1D(1, 1, kernel_size=k_size, padding=(k_size - 1) // 2, bias_attr=False)
self.sigmoid = nn.Sigmoid()
def forward(self, x):
# feature descriptor on the global spatial information
y = self.avg_pool(x)
# Two different branches of ECA module
y = self.conv(y.squeeze(-1).transpose([0,2,1])).transpose([0,2,1]).unsqueeze(-1)
# Multi-scale information fusion
y = self.sigmoid(y)
return x * y.expand_as(x)
model=paddle.Model(eca_layer())
model.summary((1, 3, 224, 224))
--------------------------------------------------------------------------------
Layer (type) Input Shape Output Shape Param #
================================================================================
AdaptiveAvgPool2D-24 [[1, 3, 224, 224]] [1, 3, 1, 1] 0
Conv1D-23 [[1, 1, 3]] [1, 1, 3] 3
Sigmoid-23 [[1, 3, 1, 1]] [1, 3, 1, 1] 0
================================================================================
Total params: 3
Trainable params: 3
Non-trainable params: 0
--------------------------------------------------------------------------------
Input size (MB): 0.57
Forward/backward pass size (MB): 0.00
Params size (MB): 0.00
Estimated Total Size (MB): 0.57
--------------------------------------------------------------------------------
{'total_params': 3, 'trainable_params': 3}
4. Experiments
本文的实验部分是论文的第二种要部分,详细介绍了论文的实验求证细节
4.1. Implementation Details
理解难度不大,就不再赘述
4.2. Image Classification on ImageNet-1K
首先评估了内核大小对ECA模块的影响,并验证了自适应确定内核大小的方法的有效性,然后我们使用ResNet-50、ResNet-101、ResNet-152和MobileNetV2与现有技术的同行和CNN模型进行了比较
4.2.1 Effect of Kernel Size (k) on ECA Module
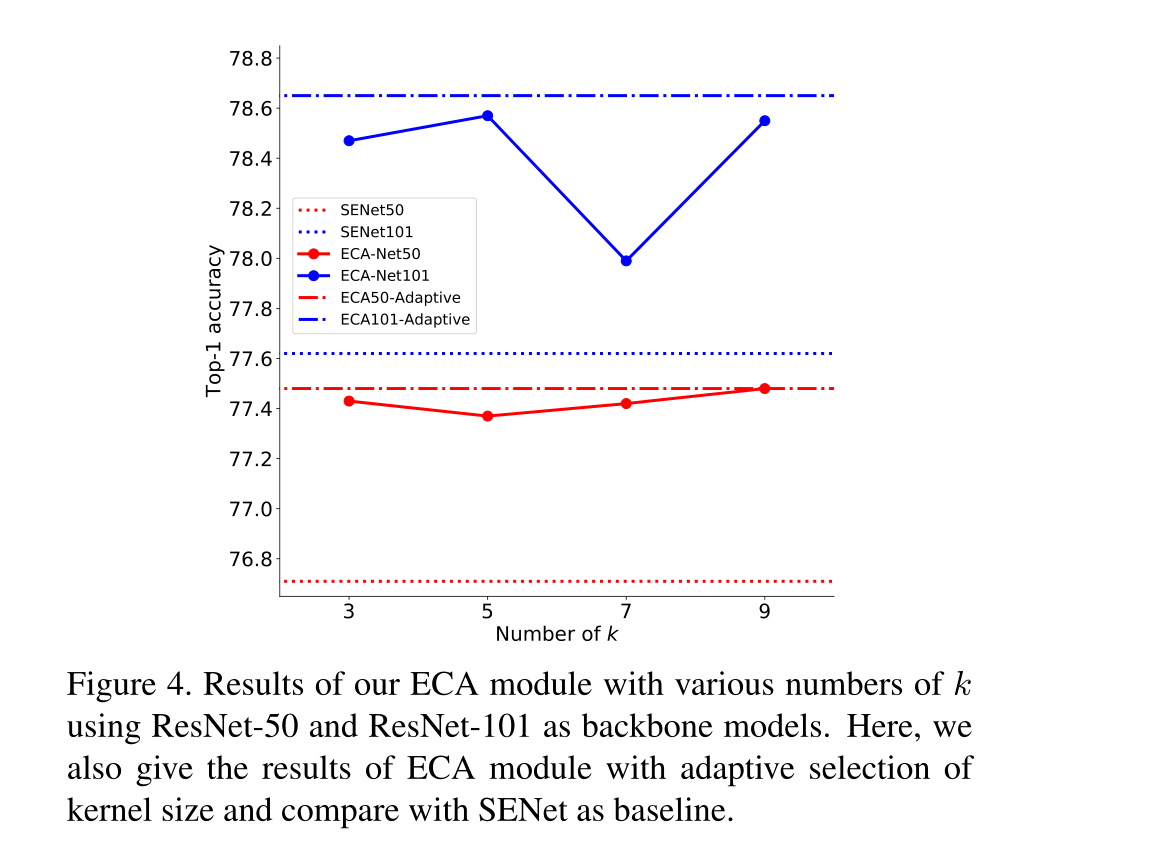
结果表明,不同的深度神经网络具有不同的最优k,并且k对ECA网络的性能有明显的影响。
自适应核大小选择在获得更好和稳定的结果方面的有效性
4.2.2 Comparisons Using Different Deep CNNs
使用不同的主干网络将ECA-Net同其他网络进行对比,比较参数有:网络参数、每秒浮点运算(FLOP)和训练/推理速度)和有效性(即Top-1/Top5精度)
ECA_Mobilev2 网络结构输出
#eca_layer
import paddle
import paddle.nn as nn
class eca_layer(paddle.nn.Layer):
"""
构建ECA模块
参数:
channel :输入特征图的通道数
k_size :自适应卷积核的大小
"""
def __init__(self,channel=1,k_size=3):
super(eca_layer,self).__init__()
self.avg_pool = nn.AdaptiveAvgPool2D(1)
self.conv = nn.Conv1D(1,1,kernel_size=k_size,padding=(k_size-1)//2,bias_attr=False)
self.sigmoid = nn.Sigmoid()
def forward(self,x):
# 全局空间信息的特征提取
y = self.avg_pool(x)
# ECA模块的两个不同分支
# shape = [64,64,1,1]
y = y.squeeze(-1).transpose([0,2,1])
# print("infront: ",y.shape)
y = self.conv(y)
# print("conv out : ",y.shape)
y = y.transpose([0,2,1]).unsqueeze(-1)
# print("conv finish: ",y.shape)
# 多尺度特征融合
y = self.sigmoid(y)
# y变成x一样的形状
y = y.expand_as(x)
#y相当于权重,也就是注意力
result = x*y
return result
import paddle.nn as nn
import numpy as np
import paddle
from paddle.utils.download import get_weights_path_from_url
__all__ = ['ECA_MobileNetV2', 'eca_mobilenet_v2']
model_urls = {
'mobilenet_v2': 'https://download.pytorch.org/models/mobilenet_v2-b0353104.pth',
}
class ConvBNReLU(nn.Sequential):
def __init__(self, in_planes, out_planes, kernel_size=3, stride=1, groups=1):
padding = (kernel_size - 1) // 2
super(ConvBNReLU, self).__init__(
nn.Conv2D(in_planes, out_planes, kernel_size, stride, padding, groups=groups,bias_attr=False),
nn.BatchNorm2D(out_planes),
nn.ReLU6(True)
)
class InvertedResidual(nn.Layer):
def __init__(self, inp, oup, stride, expand_ratio, k_size):
super(InvertedResidual, self).__init__()
self.stride = stride
assert stride in [1, 2]
hidden_dim = int(round(inp * expand_ratio))
self.use_res_connect = self.stride == 1 and inp == oup
layers = []
if expand_ratio != 1:
# pw
layers.append(ConvBNReLU(inp, hidden_dim, kernel_size=1))
layers.extend([
# dw
ConvBNReLU(hidden_dim, hidden_dim, stride=stride, groups=hidden_dim),
# pw-linear
nn.Conv2D(hidden_dim, oup, 1, 1, 0, bias_attr=False),
nn.BatchNorm2D(oup,momentum=0.1),
])
layers.append(eca_layer(oup, k_size))
self.conv = nn.Sequential(*layers)
def forward(self, x):
if self.use_res_connect:
return x + self.conv(x)
else:
return self.conv(x)
class ECA_MobileNetV2(nn.Layer):
def __init__(self, num_classes=1000, width_mult=1.0):
super(ECA_MobileNetV2, self).__init__()
block = InvertedResidual
input_channel = 32
last_channel = 1280
inverted_residual_setting = [
# t, c, n, s
[1, 16, 1, 1],
[6, 24, 2, 2],
[6, 32, 3, 2],
[6, 64, 4, 2],
[6, 96, 3, 1],
[6, 160, 3, 2],
[6, 320, 1, 1],
]
# building first layer
input_channel = int(input_channel * width_mult)
self.last_channel = int(last_channel * max(1.0, width_mult))
features = [ConvBNReLU(3, input_channel, stride=2)]
# building inverted residual blocks
for t, c, n, s in inverted_residual_setting:
output_channel = int(c * width_mult)
for i in range(n):
if c < 96:
ksize = 1
else:
ksize = 3
stride = s if i == 0 else 1
features.append(block(input_channel, output_channel, stride, expand_ratio=t, k_size=ksize))
input_channel = output_channel
# building last several layers
features.append(ConvBNReLU(input_channel, self.last_channel, kernel_size=1))
# make it nn.Sequential
self.features = nn.Sequential(*features)
# building classifier
self.classifier = nn.Sequential(
nn.Dropout(0.25),
nn.Linear(self.last_channel, num_classes),
)
# weight initialization
for m in self.sublayers():
if isinstance(m, nn.Conv2D):
m.weight_attr = paddle.framework.ParamAttr(initializer=paddle.nn.initializer.KaimingNormal)
if m.bias is not None:
m.bias.set_value(np.zeros(m.bias.shape).astype('float32'))
elif isinstance(m, nn.BatchNorm2D):
m.weight.set_value(np.ones(m.weight.shape).astype('float32'))
m.bias.set_value(np.zeros(m.bias.shape).astype('float32'))
elif isinstance(m, nn.Linear):
v = np.random.normal(loc=0,scale=0.01,size=m.weight.shape).astype('float32')
m.weight.set_value(v)
if m.bias is not None:
m.bias.set_value(np.zeros(m.bias.shape).astype('float32'))
def forward(self, x):
x = self.features(x)
x = x.mean(-1).mean(-1)
x = self.classifier(x)
return x
def eca_mobilenet_v2(pretrained=False, progress=True, **kwargs):
"""
Constructs a ECA_MobileNetV2 architecture from
Args:
pretrained (bool): If True, returns a model pre-trained on ImageNet
progress (bool): If True, displays a progress bar of the download to stderr
"""
model = ECA_MobileNetV2(**kwargs)
if pretrained:
weight_path = get_weights_path_from_url(model_urls["mobilenet_v2"][0], model_urls["mobilenet_v2"][1])
param = paddle.load(weight_path)
model.set_dict(param)
return model
model=paddle.Model(ECA_MobileNetV2())
model.summary((1, 3, 224, 224))
--------------------------------------------------------------------------------
Layer (type) Input Shape Output Shape Param #
================================================================================
Conv2D-1 [[1, 3, 224, 224]] [1, 32, 112, 112] 864
BatchNorm2D-1 [[1, 32, 112, 112]] [1, 32, 112, 112] 128
ReLU6-1 [[1, 32, 112, 112]] [1, 32, 112, 112] 0
Conv2D-2 [[1, 32, 112, 112]] [1, 32, 112, 112] 288
BatchNorm2D-2 [[1, 32, 112, 112]] [1, 32, 112, 112] 128
ReLU6-2 [[1, 32, 112, 112]] [1, 32, 112, 112] 0
Conv2D-3 [[1, 32, 112, 112]] [1, 16, 112, 112] 512
BatchNorm2D-3 [[1, 16, 112, 112]] [1, 16, 112, 112] 64
AdaptiveAvgPool2D-1 [[1, 16, 112, 112]] [1, 16, 1, 1] 0
Conv1D-1 [[1, 1, 16]] [1, 1, 16] 1
Sigmoid-1 [[1, 16, 1, 1]] [1, 16, 1, 1] 0
eca_layer-1 [[1, 16, 112, 112]] [1, 16, 112, 112] 0
InvertedResidual-1 [[1, 32, 112, 112]] [1, 16, 112, 112] 0
Conv2D-4 [[1, 16, 112, 112]] [1, 96, 112, 112] 1,536
BatchNorm2D-4 [[1, 96, 112, 112]] [1, 96, 112, 112] 384
ReLU6-3 [[1, 96, 112, 112]] [1, 96, 112, 112] 0
Conv2D-5 [[1, 96, 112, 112]] [1, 96, 56, 56] 864
BatchNorm2D-5 [[1, 96, 56, 56]] [1, 96, 56, 56] 384
ReLU6-4 [[1, 96, 56, 56]] [1, 96, 56, 56] 0
Conv2D-6 [[1, 96, 56, 56]] [1, 24, 56, 56] 2,304
BatchNorm2D-6 [[1, 24, 56, 56]] [1, 24, 56, 56] 96
AdaptiveAvgPool2D-2 [[1, 24, 56, 56]] [1, 24, 1, 1] 0
Conv1D-2 [[1, 1, 24]] [1, 1, 24] 1
Sigmoid-2 [[1, 24, 1, 1]] [1, 24, 1, 1] 0
eca_layer-2 [[1, 24, 56, 56]] [1, 24, 56, 56] 0
InvertedResidual-2 [[1, 16, 112, 112]] [1, 24, 56, 56] 0
Conv2D-7 [[1, 24, 56, 56]] [1, 144, 56, 56] 3,456
BatchNorm2D-7 [[1, 144, 56, 56]] [1, 144, 56, 56] 576
ReLU6-5 [[1, 144, 56, 56]] [1, 144, 56, 56] 0
Conv2D-8 [[1, 144, 56, 56]] [1, 144, 56, 56] 1,296
BatchNorm2D-8 [[1, 144, 56, 56]] [1, 144, 56, 56] 576
ReLU6-6 [[1, 144, 56, 56]] [1, 144, 56, 56] 0
Conv2D-9 [[1, 144, 56, 56]] [1, 24, 56, 56] 3,456
BatchNorm2D-9 [[1, 24, 56, 56]] [1, 24, 56, 56] 96
AdaptiveAvgPool2D-3 [[1, 24, 56, 56]] [1, 24, 1, 1] 0
Conv1D-3 [[1, 1, 24]] [1, 1, 24] 1
Sigmoid-3 [[1, 24, 1, 1]] [1, 24, 1, 1] 0
eca_layer-3 [[1, 24, 56, 56]] [1, 24, 56, 56] 0
InvertedResidual-3 [[1, 24, 56, 56]] [1, 24, 56, 56] 0
Conv2D-10 [[1, 24, 56, 56]] [1, 144, 56, 56] 3,456
BatchNorm2D-10 [[1, 144, 56, 56]] [1, 144, 56, 56] 576
ReLU6-7 [[1, 144, 56, 56]] [1, 144, 56, 56] 0
Conv2D-11 [[1, 144, 56, 56]] [1, 144, 28, 28] 1,296
BatchNorm2D-11 [[1, 144, 28, 28]] [1, 144, 28, 28] 576
ReLU6-8 [[1, 144, 28, 28]] [1, 144, 28, 28] 0
Conv2D-12 [[1, 144, 28, 28]] [1, 32, 28, 28] 4,608
BatchNorm2D-12 [[1, 32, 28, 28]] [1, 32, 28, 28] 128
AdaptiveAvgPool2D-4 [[1, 32, 28, 28]] [1, 32, 1, 1] 0
Conv1D-4 [[1, 1, 32]] [1, 1, 32] 1
Sigmoid-4 [[1, 32, 1, 1]] [1, 32, 1, 1] 0
eca_layer-4 [[1, 32, 28, 28]] [1, 32, 28, 28] 0
InvertedResidual-4 [[1, 24, 56, 56]] [1, 32, 28, 28] 0
Conv2D-13 [[1, 32, 28, 28]] [1, 192, 28, 28] 6,144
BatchNorm2D-13 [[1, 192, 28, 28]] [1, 192, 28, 28] 768
ReLU6-9 [[1, 192, 28, 28]] [1, 192, 28, 28] 0
Conv2D-14 [[1, 192, 28, 28]] [1, 192, 28, 28] 1,728
BatchNorm2D-14 [[1, 192, 28, 28]] [1, 192, 28, 28] 768
ReLU6-10 [[1, 192, 28, 28]] [1, 192, 28, 28] 0
Conv2D-15 [[1, 192, 28, 28]] [1, 32, 28, 28] 6,144
BatchNorm2D-15 [[1, 32, 28, 28]] [1, 32, 28, 28] 128
AdaptiveAvgPool2D-5 [[1, 32, 28, 28]] [1, 32, 1, 1] 0
Conv1D-5 [[1, 1, 32]] [1, 1, 32] 1
Sigmoid-5 [[1, 32, 1, 1]] [1, 32, 1, 1] 0
eca_layer-5 [[1, 32, 28, 28]] [1, 32, 28, 28] 0
InvertedResidual-5 [[1, 32, 28, 28]] [1, 32, 28, 28] 0
Conv2D-16 [[1, 32, 28, 28]] [1, 192, 28, 28] 6,144
BatchNorm2D-16 [[1, 192, 28, 28]] [1, 192, 28, 28] 768
ReLU6-11 [[1, 192, 28, 28]] [1, 192, 28, 28] 0
Conv2D-17 [[1, 192, 28, 28]] [1, 192, 28, 28] 1,728
BatchNorm2D-17 [[1, 192, 28, 28]] [1, 192, 28, 28] 768
ReLU6-12 [[1, 192, 28, 28]] [1, 192, 28, 28] 0
Conv2D-18 [[1, 192, 28, 28]] [1, 32, 28, 28] 6,144
BatchNorm2D-18 [[1, 32, 28, 28]] [1, 32, 28, 28] 128
AdaptiveAvgPool2D-6 [[1, 32, 28, 28]] [1, 32, 1, 1] 0
Conv1D-6 [[1, 1, 32]] [1, 1, 32] 1
Sigmoid-6 [[1, 32, 1, 1]] [1, 32, 1, 1] 0
eca_layer-6 [[1, 32, 28, 28]] [1, 32, 28, 28] 0
InvertedResidual-6 [[1, 32, 28, 28]] [1, 32, 28, 28] 0
Conv2D-19 [[1, 32, 28, 28]] [1, 192, 28, 28] 6,144
BatchNorm2D-19 [[1, 192, 28, 28]] [1, 192, 28, 28] 768
ReLU6-13 [[1, 192, 28, 28]] [1, 192, 28, 28] 0
Conv2D-20 [[1, 192, 28, 28]] [1, 192, 14, 14] 1,728
BatchNorm2D-20 [[1, 192, 14, 14]] [1, 192, 14, 14] 768
ReLU6-14 [[1, 192, 14, 14]] [1, 192, 14, 14] 0
Conv2D-21 [[1, 192, 14, 14]] [1, 64, 14, 14] 12,288
BatchNorm2D-21 [[1, 64, 14, 14]] [1, 64, 14, 14] 256
AdaptiveAvgPool2D-7 [[1, 64, 14, 14]] [1, 64, 1, 1] 0
Conv1D-7 [[1, 1, 64]] [1, 1, 64] 1
Sigmoid-7 [[1, 64, 1, 1]] [1, 64, 1, 1] 0
eca_layer-7 [[1, 64, 14, 14]] [1, 64, 14, 14] 0
InvertedResidual-7 [[1, 32, 28, 28]] [1, 64, 14, 14] 0
Conv2D-22 [[1, 64, 14, 14]] [1, 384, 14, 14] 24,576
BatchNorm2D-22 [[1, 384, 14, 14]] [1, 384, 14, 14] 1,536
ReLU6-15 [[1, 384, 14, 14]] [1, 384, 14, 14] 0
Conv2D-23 [[1, 384, 14, 14]] [1, 384, 14, 14] 3,456
BatchNorm2D-23 [[1, 384, 14, 14]] [1, 384, 14, 14] 1,536
ReLU6-16 [[1, 384, 14, 14]] [1, 384, 14, 14] 0
Conv2D-24 [[1, 384, 14, 14]] [1, 64, 14, 14] 24,576
BatchNorm2D-24 [[1, 64, 14, 14]] [1, 64, 14, 14] 256
AdaptiveAvgPool2D-8 [[1, 64, 14, 14]] [1, 64, 1, 1] 0
Conv1D-8 [[1, 1, 64]] [1, 1, 64] 1
Sigmoid-8 [[1, 64, 1, 1]] [1, 64, 1, 1] 0
eca_layer-8 [[1, 64, 14, 14]] [1, 64, 14, 14] 0
InvertedResidual-8 [[1, 64, 14, 14]] [1, 64, 14, 14] 0
Conv2D-25 [[1, 64, 14, 14]] [1, 384, 14, 14] 24,576
BatchNorm2D-25 [[1, 384, 14, 14]] [1, 384, 14, 14] 1,536
ReLU6-17 [[1, 384, 14, 14]] [1, 384, 14, 14] 0
Conv2D-26 [[1, 384, 14, 14]] [1, 384, 14, 14] 3,456
BatchNorm2D-26 [[1, 384, 14, 14]] [1, 384, 14, 14] 1,536
ReLU6-18 [[1, 384, 14, 14]] [1, 384, 14, 14] 0
Conv2D-27 [[1, 384, 14, 14]] [1, 64, 14, 14] 24,576
BatchNorm2D-27 [[1, 64, 14, 14]] [1, 64, 14, 14] 256
AdaptiveAvgPool2D-9 [[1, 64, 14, 14]] [1, 64, 1, 1] 0
Conv1D-9 [[1, 1, 64]] [1, 1, 64] 1
Sigmoid-9 [[1, 64, 1, 1]] [1, 64, 1, 1] 0
eca_layer-9 [[1, 64, 14, 14]] [1, 64, 14, 14] 0
InvertedResidual-9 [[1, 64, 14, 14]] [1, 64, 14, 14] 0
Conv2D-28 [[1, 64, 14, 14]] [1, 384, 14, 14] 24,576
BatchNorm2D-28 [[1, 384, 14, 14]] [1, 384, 14, 14] 1,536
ReLU6-19 [[1, 384, 14, 14]] [1, 384, 14, 14] 0
Conv2D-29 [[1, 384, 14, 14]] [1, 384, 14, 14] 3,456
BatchNorm2D-29 [[1, 384, 14, 14]] [1, 384, 14, 14] 1,536
ReLU6-20 [[1, 384, 14, 14]] [1, 384, 14, 14] 0
Conv2D-30 [[1, 384, 14, 14]] [1, 64, 14, 14] 24,576
BatchNorm2D-30 [[1, 64, 14, 14]] [1, 64, 14, 14] 256
AdaptiveAvgPool2D-10 [[1, 64, 14, 14]] [1, 64, 1, 1] 0
Conv1D-10 [[1, 1, 64]] [1, 1, 64] 1
Sigmoid-10 [[1, 64, 1, 1]] [1, 64, 1, 1] 0
eca_layer-10 [[1, 64, 14, 14]] [1, 64, 14, 14] 0
InvertedResidual-10 [[1, 64, 14, 14]] [1, 64, 14, 14] 0
Conv2D-31 [[1, 64, 14, 14]] [1, 384, 14, 14] 24,576
BatchNorm2D-31 [[1, 384, 14, 14]] [1, 384, 14, 14] 1,536
ReLU6-21 [[1, 384, 14, 14]] [1, 384, 14, 14] 0
Conv2D-32 [[1, 384, 14, 14]] [1, 384, 14, 14] 3,456
BatchNorm2D-32 [[1, 384, 14, 14]] [1, 384, 14, 14] 1,536
ReLU6-22 [[1, 384, 14, 14]] [1, 384, 14, 14] 0
Conv2D-33 [[1, 384, 14, 14]] [1, 96, 14, 14] 36,864
BatchNorm2D-33 [[1, 96, 14, 14]] [1, 96, 14, 14] 384
AdaptiveAvgPool2D-11 [[1, 96, 14, 14]] [1, 96, 1, 1] 0
Conv1D-11 [[1, 1, 96]] [1, 1, 96] 3
Sigmoid-11 [[1, 96, 1, 1]] [1, 96, 1, 1] 0
eca_layer-11 [[1, 96, 14, 14]] [1, 96, 14, 14] 0
InvertedResidual-11 [[1, 64, 14, 14]] [1, 96, 14, 14] 0
Conv2D-34 [[1, 96, 14, 14]] [1, 576, 14, 14] 55,296
BatchNorm2D-34 [[1, 576, 14, 14]] [1, 576, 14, 14] 2,304
ReLU6-23 [[1, 576, 14, 14]] [1, 576, 14, 14] 0
Conv2D-35 [[1, 576, 14, 14]] [1, 576, 14, 14] 5,184
BatchNorm2D-35 [[1, 576, 14, 14]] [1, 576, 14, 14] 2,304
ReLU6-24 [[1, 576, 14, 14]] [1, 576, 14, 14] 0
Conv2D-36 [[1, 576, 14, 14]] [1, 96, 14, 14] 55,296
BatchNorm2D-36 [[1, 96, 14, 14]] [1, 96, 14, 14] 384
AdaptiveAvgPool2D-12 [[1, 96, 14, 14]] [1, 96, 1, 1] 0
Conv1D-12 [[1, 1, 96]] [1, 1, 96] 3
Sigmoid-12 [[1, 96, 1, 1]] [1, 96, 1, 1] 0
eca_layer-12 [[1, 96, 14, 14]] [1, 96, 14, 14] 0
InvertedResidual-12 [[1, 96, 14, 14]] [1, 96, 14, 14] 0
Conv2D-37 [[1, 96, 14, 14]] [1, 576, 14, 14] 55,296
BatchNorm2D-37 [[1, 576, 14, 14]] [1, 576, 14, 14] 2,304
ReLU6-25 [[1, 576, 14, 14]] [1, 576, 14, 14] 0
Conv2D-38 [[1, 576, 14, 14]] [1, 576, 14, 14] 5,184
BatchNorm2D-38 [[1, 576, 14, 14]] [1, 576, 14, 14] 2,304
ReLU6-26 [[1, 576, 14, 14]] [1, 576, 14, 14] 0
Conv2D-39 [[1, 576, 14, 14]] [1, 96, 14, 14] 55,296
BatchNorm2D-39 [[1, 96, 14, 14]] [1, 96, 14, 14] 384
AdaptiveAvgPool2D-13 [[1, 96, 14, 14]] [1, 96, 1, 1] 0
Conv1D-13 [[1, 1, 96]] [1, 1, 96] 3
Sigmoid-13 [[1, 96, 1, 1]] [1, 96, 1, 1] 0
eca_layer-13 [[1, 96, 14, 14]] [1, 96, 14, 14] 0
InvertedResidual-13 [[1, 96, 14, 14]] [1, 96, 14, 14] 0
Conv2D-40 [[1, 96, 14, 14]] [1, 576, 14, 14] 55,296
BatchNorm2D-40 [[1, 576, 14, 14]] [1, 576, 14, 14] 2,304
ReLU6-27 [[1, 576, 14, 14]] [1, 576, 14, 14] 0
Conv2D-41 [[1, 576, 14, 14]] [1, 576, 7, 7] 5,184
BatchNorm2D-41 [[1, 576, 7, 7]] [1, 576, 7, 7] 2,304
ReLU6-28 [[1, 576, 7, 7]] [1, 576, 7, 7] 0
Conv2D-42 [[1, 576, 7, 7]] [1, 160, 7, 7] 92,160
BatchNorm2D-42 [[1, 160, 7, 7]] [1, 160, 7, 7] 640
AdaptiveAvgPool2D-14 [[1, 160, 7, 7]] [1, 160, 1, 1] 0
Conv1D-14 [[1, 1, 160]] [1, 1, 160] 3
Sigmoid-14 [[1, 160, 1, 1]] [1, 160, 1, 1] 0
eca_layer-14 [[1, 160, 7, 7]] [1, 160, 7, 7] 0
InvertedResidual-14 [[1, 96, 14, 14]] [1, 160, 7, 7] 0
Conv2D-43 [[1, 160, 7, 7]] [1, 960, 7, 7] 153,600
BatchNorm2D-43 [[1, 960, 7, 7]] [1, 960, 7, 7] 3,840
ReLU6-29 [[1, 960, 7, 7]] [1, 960, 7, 7] 0
Conv2D-44 [[1, 960, 7, 7]] [1, 960, 7, 7] 8,640
BatchNorm2D-44 [[1, 960, 7, 7]] [1, 960, 7, 7] 3,840
ReLU6-30 [[1, 960, 7, 7]] [1, 960, 7, 7] 0
Conv2D-45 [[1, 960, 7, 7]] [1, 160, 7, 7] 153,600
BatchNorm2D-45 [[1, 160, 7, 7]] [1, 160, 7, 7] 640
AdaptiveAvgPool2D-15 [[1, 160, 7, 7]] [1, 160, 1, 1] 0
Conv1D-15 [[1, 1, 160]] [1, 1, 160] 3
Sigmoid-15 [[1, 160, 1, 1]] [1, 160, 1, 1] 0
eca_layer-15 [[1, 160, 7, 7]] [1, 160, 7, 7] 0
InvertedResidual-15 [[1, 160, 7, 7]] [1, 160, 7, 7] 0
Conv2D-46 [[1, 160, 7, 7]] [1, 960, 7, 7] 153,600
BatchNorm2D-46 [[1, 960, 7, 7]] [1, 960, 7, 7] 3,840
ReLU6-31 [[1, 960, 7, 7]] [1, 960, 7, 7] 0
Conv2D-47 [[1, 960, 7, 7]] [1, 960, 7, 7] 8,640
BatchNorm2D-47 [[1, 960, 7, 7]] [1, 960, 7, 7] 3,840
ReLU6-32 [[1, 960, 7, 7]] [1, 960, 7, 7] 0
Conv2D-48 [[1, 960, 7, 7]] [1, 160, 7, 7] 153,600
BatchNorm2D-48 [[1, 160, 7, 7]] [1, 160, 7, 7] 640
AdaptiveAvgPool2D-16 [[1, 160, 7, 7]] [1, 160, 1, 1] 0
Conv1D-16 [[1, 1, 160]] [1, 1, 160] 3
Sigmoid-16 [[1, 160, 1, 1]] [1, 160, 1, 1] 0
eca_layer-16 [[1, 160, 7, 7]] [1, 160, 7, 7] 0
InvertedResidual-16 [[1, 160, 7, 7]] [1, 160, 7, 7] 0
Conv2D-49 [[1, 160, 7, 7]] [1, 960, 7, 7] 153,600
BatchNorm2D-49 [[1, 960, 7, 7]] [1, 960, 7, 7] 3,840
ReLU6-33 [[1, 960, 7, 7]] [1, 960, 7, 7] 0
Conv2D-50 [[1, 960, 7, 7]] [1, 960, 7, 7] 8,640
BatchNorm2D-50 [[1, 960, 7, 7]] [1, 960, 7, 7] 3,840
ReLU6-34 [[1, 960, 7, 7]] [1, 960, 7, 7] 0
Conv2D-51 [[1, 960, 7, 7]] [1, 320, 7, 7] 307,200
BatchNorm2D-51 [[1, 320, 7, 7]] [1, 320, 7, 7] 1,280
AdaptiveAvgPool2D-17 [[1, 320, 7, 7]] [1, 320, 1, 1] 0
Conv1D-17 [[1, 1, 320]] [1, 1, 320] 3
Sigmoid-17 [[1, 320, 1, 1]] [1, 320, 1, 1] 0
eca_layer-17 [[1, 320, 7, 7]] [1, 320, 7, 7] 0
InvertedResidual-17 [[1, 160, 7, 7]] [1, 320, 7, 7] 0
Conv2D-52 [[1, 320, 7, 7]] [1, 1280, 7, 7] 409,600
BatchNorm2D-52 [[1, 1280, 7, 7]] [1, 1280, 7, 7] 5,120
ReLU6-35 [[1, 1280, 7, 7]] [1, 1280, 7, 7] 0
Dropout-1 [[1, 1280]] [1, 1280] 0
Linear-1 [[1, 1280]] [1, 1000] 1,281,000
================================================================================
Total params: 3,539,015
Trainable params: 3,504,903
Non-trainable params: 34,112
--------------------------------------------------------------------------------
Input size (MB): 0.57
Forward/backward pass size (MB): 157.27
Params size (MB): 13.50
Estimated Total Size (MB): 171.34
--------------------------------------------------------------------------------
{'total_params': 3539015, 'trainable_params': 3504903}
ECA_restNet 网络结构输出
#网络
import paddle
import paddle.nn as nn
import paddle.nn.functional as F
class ResidualBasicBlock(nn.Layer):
expansion = 1
def __init__(self, in_channels, out_channels, stride=1):
super(ResidualBasicBlock, self).__init__()
self.stride =stride
self.conv1 = nn.Conv2D(in_channels=in_channels, out_channels=out_channels, kernel_size=3,
stride=stride, padding=1)
self.bn1 = nn.BatchNorm2D(out_channels)
self.conv2 = nn.Conv2D(in_channels=out_channels, out_channels=out_channels, kernel_size=3,
stride=1, padding=1)
self.bn2 = nn.BatchNorm2D(out_channels)
# in_channels == out_channels时,处理同一卷积层内的数据流动
# 此时,右边的shortcut 直接使用恒等实现,即输入的x
self.conv3 = None
# 当in_channels != out_channels时, 处理卷积层之间的数据流动, 即 conv_2 -> conv_3 -> conv_4 -> conv_5 之间的转换
# 此时,feature map缩小一倍, channel数放大两倍
# 右边的shortcut通过conv3 层的 1*1卷积实现shape的改变 (映射方式)
if in_channels != out_channels:
self.conv3 = nn.Conv2D(in_channels=in_channels, out_channels=out_channels, kernel_size=1, stride=2)
self.bn3 = nn.BatchNorm2D(out_channels)
def forward(self, x):
identity = x
x = self.conv1(x)
x = F.relu(self.bn1(x))
x = self.conv2(x)
x = F.relu(self.bn2(x))
if self.conv3:
identity = self.conv3(identity)
identity = self.bn3(identity)
out = F.relu(x + identity)
return out
class ResidualBottleneckBlock(nn.Layer):
expansion = 4
def __init__(self, in_channels, out_channels, stride=1):
super(ResidualBottleneckBlock, self).__init__()
mid_channel_num = int(in_channels if stride == 2 else out_channels / 4)
self.stride = stride
self.conv1 = nn.Conv2D(in_channels=in_channels, out_channels=mid_channel_num, kernel_size=1)
self.bn1 = nn.BatchNorm2D(mid_channel_num)
self.conv2 = nn.Conv2D(in_channels=mid_channel_num, out_channels=mid_channel_num, kernel_size=3,
stride=stride, padding=1)
self.bn2 = nn.BatchNorm2D(mid_channel_num)
self.conv3 = nn.Conv2D(in_channels=mid_channel_num, out_channels=out_channels, kernel_size=1,
stride=1)
self.bn3 = nn.BatchNorm2D(out_channels)
self.conv4 = None
# in_channels == out_channels时,处理同一卷积层内的数据流动
# 此时,右边的shortcut 直接使用恒等实现,即输入的x
# 当 in_channels != out_channels 时, 处理卷积层之间的数据流动, 即 conv_2 -> conv_3 -> conv_4 -> conv_5 之间的转换
# 此时,feature map缩小一倍, channel数放大两倍
# 右边的shortcut通过conv4 层的 1*1卷积实现shape的改变 (映射方式)
if in_channels != out_channels:
self.conv4 = nn.Conv2D(in_channels=in_channels, out_channels=out_channels, kernel_size=1, stride=stride)
self.bn4 = nn.BatchNorm2D(out_channels)
def forward(self, x):
identity = x
x = self.conv1(x)
x = F.relu(self.bn1(x))
x = self.conv2(x)
x = F.relu(self.bn2(x))
x = self.conv3(x)
x = F.relu(self.bn3(x))
if self.conv4:
identity = self.conv4(identity)
identity = self.bn4(identity)
out = F.relu(x + identity)
return out
class MyResNet(nn.Layer):
def __init__(self, residual_block, depth, class_num):
"""
input shape (1, 3, 224, 224)
:param residual_block:
:param depth:
:param class_num:
"""
super(MyResNet, self).__init__()
self.inplanes = 64
self.block = residual_block
self.is_bottleneck_block = isinstance(self.block, ResidualBottleneckBlock)
layer_cfg = {
18: [2, 2, 2, 2],
34: [3, 4, 6, 3],
50: [3, 4, 6, 3],
101: [3, 4, 23, 3],
152: [3, 8, 36, 3]
}
self.layers = layer_cfg[depth]
self.conv1 = nn.Conv2D(in_channels=3, out_channels=64, kernel_size=7, stride=2, padding=3)
self.bn1 = nn.BatchNorm2D(64)
self.relu1 = nn.ReLU()
self.max_pool = nn.MaxPool2D(kernel_size=3, stride=2, padding=1)
self.conv2_layer = self._make_layer(64, 0, False)
self.conv3_layer = self._make_layer(128, 1)
self.conv4_layer = self._make_layer(256, 2)
self.conv5_layer = self._make_layer(512, 3)
self.avg_pool = nn.AdaptiveAvgPool2D((1, 1))
self.fc = nn.Linear(in_features=512 * self.block.expansion, out_features=class_num)
def forward(self, x):
x = self.conv1(x)
x = self.bn1(x)
x = self.relu1(x)
x = self.max_pool(x)
x = self.conv2_layer(x)
x = self.conv3_layer(x)
x = self.conv4_layer(x)
x = self.conv5_layer(x)
x = self.avg_pool(x)
x = paddle.flatten(x, 1)
x = self.fc(x)
return x
def _make_layer(self, out_channel, layer_index, need_down_sample=True):
out_channel *= self.block.expansion
tmp = int(self.inplanes / 2) if need_down_sample and self.is_bottleneck_block else out_channel
layer_list = [self.block(self.inplanes, tmp,
stride=2 if need_down_sample else 1)]
for i in range(1, self.layers[layer_index]):
layer_list.append(self.block(tmp, out_channel, stride=1))
tmp = out_channel
self.inplanes = out_channel
return nn.Sequential(*layer_list)
def eca_resnet18(ECABlock,depth):
"""Constructs a ResNet-18 model.
Args:
k_size: Adaptive selection of kernel size
pretrained (bool): If True, returns a model pre-trained on ImageNet
num_classes:The classes of classification
"""
model = MyResNet(ECABlock, depth,class_num)
model.avgpool = nn.AdaptiveAvgPool2D(1)
return model
eca_resnet18=MyResNet(ResidualBottleneckBlock, 18,10)
model=paddle.Model(eca_resnet18)
model.summary((1, 3, 224, 224))
-------------------------------------------------------------------------------------
Layer (type) Input Shape Output Shape Param #
=====================================================================================
Conv2D-53 [[1, 3, 224, 224]] [1, 64, 112, 112] 9,472
BatchNorm2D-53 [[1, 64, 112, 112]] [1, 64, 112, 112] 256
ReLU-1 [[1, 64, 112, 112]] [1, 64, 112, 112] 0
MaxPool2D-1 [[1, 64, 112, 112]] [1, 64, 56, 56] 0
Conv2D-54 [[1, 64, 56, 56]] [1, 64, 56, 56] 4,160
BatchNorm2D-54 [[1, 64, 56, 56]] [1, 64, 56, 56] 256
Conv2D-55 [[1, 64, 56, 56]] [1, 64, 56, 56] 36,928
BatchNorm2D-55 [[1, 64, 56, 56]] [1, 64, 56, 56] 256
Conv2D-56 [[1, 64, 56, 56]] [1, 256, 56, 56] 16,640
BatchNorm2D-56 [[1, 256, 56, 56]] [1, 256, 56, 56] 1,024
Conv2D-57 [[1, 64, 56, 56]] [1, 256, 56, 56] 16,640
BatchNorm2D-57 [[1, 256, 56, 56]] [1, 256, 56, 56] 1,024
ResidualBottleneckBlock-1 [[1, 64, 56, 56]] [1, 256, 56, 56] 0
Conv2D-58 [[1, 256, 56, 56]] [1, 64, 56, 56] 16,448
BatchNorm2D-58 [[1, 64, 56, 56]] [1, 64, 56, 56] 256
Conv2D-59 [[1, 64, 56, 56]] [1, 64, 56, 56] 36,928
BatchNorm2D-59 [[1, 64, 56, 56]] [1, 64, 56, 56] 256
Conv2D-60 [[1, 64, 56, 56]] [1, 256, 56, 56] 16,640
BatchNorm2D-60 [[1, 256, 56, 56]] [1, 256, 56, 56] 1,024
ResidualBottleneckBlock-2 [[1, 256, 56, 56]] [1, 256, 56, 56] 0
Conv2D-61 [[1, 256, 56, 56]] [1, 256, 56, 56] 65,792
BatchNorm2D-61 [[1, 256, 56, 56]] [1, 256, 56, 56] 1,024
Conv2D-62 [[1, 256, 56, 56]] [1, 256, 28, 28] 590,080
BatchNorm2D-62 [[1, 256, 28, 28]] [1, 256, 28, 28] 1,024
Conv2D-63 [[1, 256, 28, 28]] [1, 512, 28, 28] 131,584
BatchNorm2D-63 [[1, 512, 28, 28]] [1, 512, 28, 28] 2,048
Conv2D-64 [[1, 256, 56, 56]] [1, 512, 28, 28] 131,584
BatchNorm2D-64 [[1, 512, 28, 28]] [1, 512, 28, 28] 2,048
ResidualBottleneckBlock-3 [[1, 256, 56, 56]] [1, 512, 28, 28] 0
Conv2D-65 [[1, 512, 28, 28]] [1, 128, 28, 28] 65,664
BatchNorm2D-65 [[1, 128, 28, 28]] [1, 128, 28, 28] 512
Conv2D-66 [[1, 128, 28, 28]] [1, 128, 28, 28] 147,584
BatchNorm2D-66 [[1, 128, 28, 28]] [1, 128, 28, 28] 512
Conv2D-67 [[1, 128, 28, 28]] [1, 512, 28, 28] 66,048
BatchNorm2D-67 [[1, 512, 28, 28]] [1, 512, 28, 28] 2,048
ResidualBottleneckBlock-4 [[1, 512, 28, 28]] [1, 512, 28, 28] 0
Conv2D-68 [[1, 512, 28, 28]] [1, 512, 28, 28] 262,656
BatchNorm2D-68 [[1, 512, 28, 28]] [1, 512, 28, 28] 2,048
Conv2D-69 [[1, 512, 28, 28]] [1, 512, 14, 14] 2,359,808
BatchNorm2D-69 [[1, 512, 14, 14]] [1, 512, 14, 14] 2,048
Conv2D-70 [[1, 512, 14, 14]] [1, 1024, 14, 14] 525,312
BatchNorm2D-70 [[1, 1024, 14, 14]] [1, 1024, 14, 14] 4,096
Conv2D-71 [[1, 512, 28, 28]] [1, 1024, 14, 14] 525,312
BatchNorm2D-71 [[1, 1024, 14, 14]] [1, 1024, 14, 14] 4,096
ResidualBottleneckBlock-5 [[1, 512, 28, 28]] [1, 1024, 14, 14] 0
Conv2D-72 [[1, 1024, 14, 14]] [1, 256, 14, 14] 262,400
BatchNorm2D-72 [[1, 256, 14, 14]] [1, 256, 14, 14] 1,024
Conv2D-73 [[1, 256, 14, 14]] [1, 256, 14, 14] 590,080
BatchNorm2D-73 [[1, 256, 14, 14]] [1, 256, 14, 14] 1,024
Conv2D-74 [[1, 256, 14, 14]] [1, 1024, 14, 14] 263,168
BatchNorm2D-74 [[1, 1024, 14, 14]] [1, 1024, 14, 14] 4,096
ResidualBottleneckBlock-6 [[1, 1024, 14, 14]] [1, 1024, 14, 14] 0
Conv2D-75 [[1, 1024, 14, 14]] [1, 1024, 14, 14] 1,049,600
BatchNorm2D-75 [[1, 1024, 14, 14]] [1, 1024, 14, 14] 4,096
Conv2D-76 [[1, 1024, 14, 14]] [1, 1024, 7, 7] 9,438,208
BatchNorm2D-76 [[1, 1024, 7, 7]] [1, 1024, 7, 7] 4,096
Conv2D-77 [[1, 1024, 7, 7]] [1, 2048, 7, 7] 2,099,200
BatchNorm2D-77 [[1, 2048, 7, 7]] [1, 2048, 7, 7] 8,192
Conv2D-78 [[1, 1024, 14, 14]] [1, 2048, 7, 7] 2,099,200
BatchNorm2D-78 [[1, 2048, 7, 7]] [1, 2048, 7, 7] 8,192
ResidualBottleneckBlock-7 [[1, 1024, 14, 14]] [1, 2048, 7, 7] 0
Conv2D-79 [[1, 2048, 7, 7]] [1, 512, 7, 7] 1,049,088
BatchNorm2D-79 [[1, 512, 7, 7]] [1, 512, 7, 7] 2,048
Conv2D-80 [[1, 512, 7, 7]] [1, 512, 7, 7] 2,359,808
BatchNorm2D-80 [[1, 512, 7, 7]] [1, 512, 7, 7] 2,048
Conv2D-81 [[1, 512, 7, 7]] [1, 2048, 7, 7] 1,050,624
BatchNorm2D-81 [[1, 2048, 7, 7]] [1, 2048, 7, 7] 8,192
ResidualBottleneckBlock-8 [[1, 2048, 7, 7]] [1, 2048, 7, 7] 0
AdaptiveAvgPool2D-18 [[1, 2048, 7, 7]] [1, 2048, 1, 1] 0
Linear-2 [[1, 2048]] [1, 10] 20,490
=====================================================================================
Total params: 25,376,010
Trainable params: 25,341,578
Non-trainable params: 34,432
-------------------------------------------------------------------------------------
Input size (MB): 0.57
Forward/backward pass size (MB): 156.20
Params size (MB): 96.80
Estimated Total Size (MB): 253.58
-------------------------------------------------------------------------------------
rams: 34,432
-------------------------------------------------------------------------------------
Input size (MB): 0.57
Forward/backward pass size (MB): 156.20
Params size (MB): 96.80
Estimated Total Size (MB): 253.58
-------------------------------------------------------------------------------------
{'total_params': 25376010, 'trainable_params': 25341578}
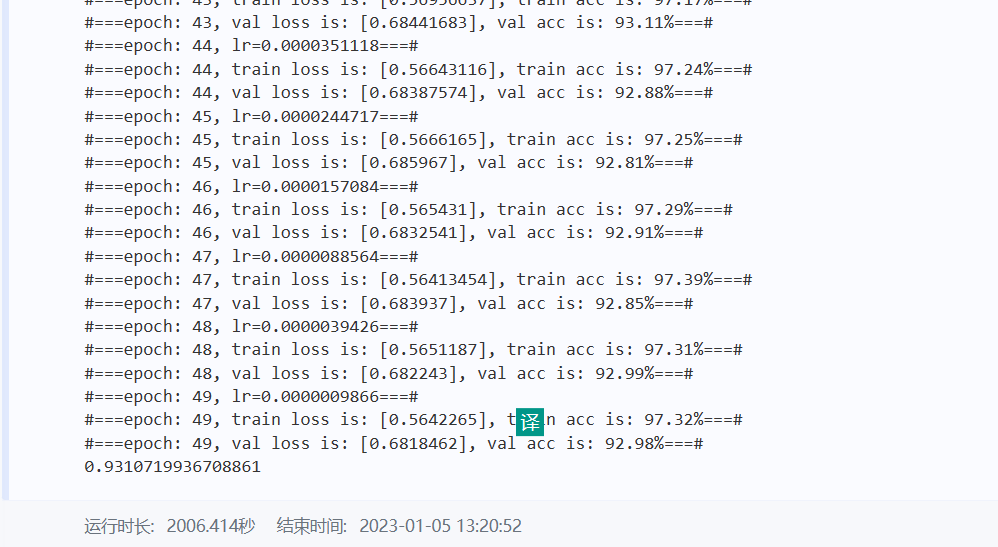
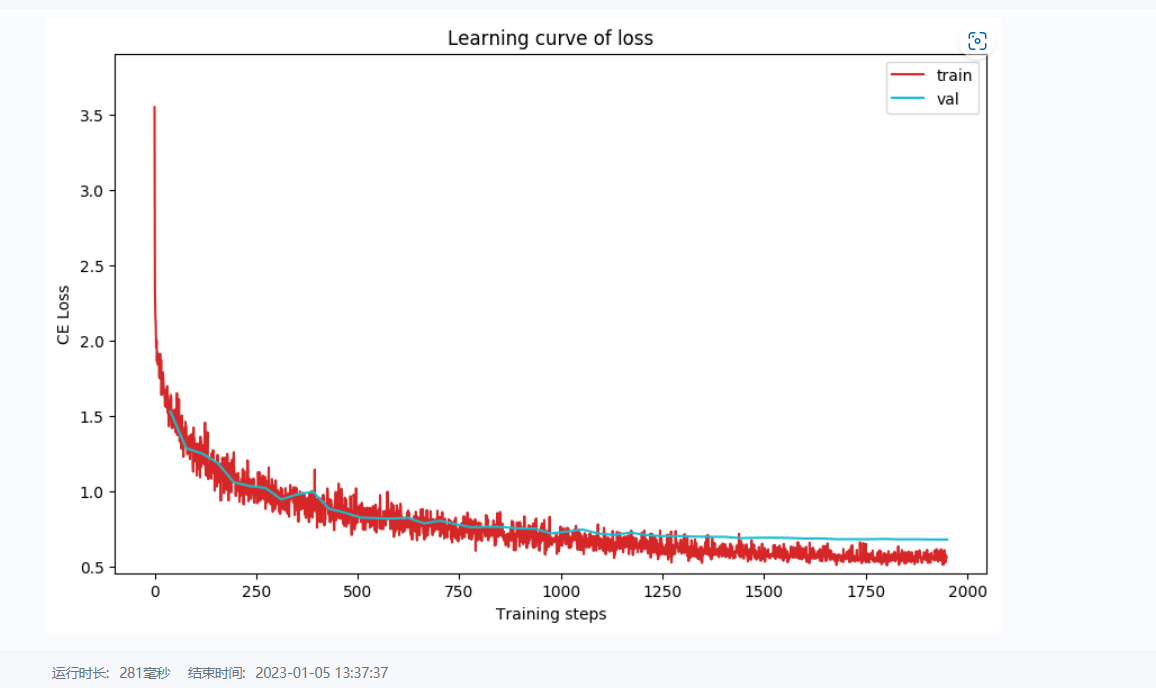
# 网络训练结果展示,详细代码在trainmynet.ipynb文件
#训练
learning_rate = 0.001
n_epochs = 50
paddle.seed(42)
np.random.seed(42)
work_path = 'work/model'
model = eca_resnet18(ResidualBasicBlock,depth=18,class_num=10)
criterion = LabelSmoothingCrossEntropy()
scheduler = paddle.optimizer.lr.CosineAnnealingDecay(learning_rate=learning_rate, T_max=50000 // batch_size * n_epochs, verbose=False)
optimizer = paddle.optimizer.Adam(parameters=model.parameters(), learning_rate=scheduler, weight_decay=1e-5)
gate = 0.0
threshold = 0.0
best_acc = 0.0
val_acc = 0.0
loss_record = {'train': {'loss': [], 'iter': []}, 'val': {'loss': [], 'iter': []}} # for recording loss
acc_record = {'train': {'acc': [], 'iter': []}, 'val': {'acc': [], 'iter': []}} # for recording accuracy
loss_iter = 0
acc_iter = 0
for epoch in range(n_epochs):
# ---------- Training ----------
model.train()
train_num = 0.0
train_loss = 0.0
val_num = 0.0
val_loss = 0.0
accuracy_manager = paddle.metric.Accuracy()
val_accuracy_manager = paddle.metric.Accuracy()
print("#===epoch: {}, lr={:.10f}===#".format(epoch, optimizer.get_lr()))
for batch_id, data in enumerate(train_loader):
x_data, y_data = data
labels = paddle.unsqueeze(y_data, axis=1)
logits = model(x_data)
loss = criterion(logits, y_data)
acc = paddle.metric.accuracy(logits, labels)
accuracy_manager.update(acc)
if batch_id % 10 == 0:
loss_record['train']['loss'].append(loss.numpy())
loss_record['train']['iter'].append(loss_iter)
loss_iter += 1
loss.backward()
optimizer.step()
scheduler.step()
optimizer.clear_grad()
train_loss += loss
train_num += len(y_data)
total_train_loss = (train_loss / train_num) * batch_size
train_acc = accuracy_manager.accumulate()
acc_record['train']['acc'].append(train_acc)
acc_record['train']['iter'].append(acc_iter)
acc_iter += 1
# Print the information.
print("#===epoch: {}, train loss is: {}, train acc is: {:2.2f}%===#".format(epoch, total_train_loss.numpy(), train_acc*100))
# ---------- Validation ----------
model.eval()
for batch_id, data in enumerate(val_loader):
x_data, y_data = data
labels = paddle.unsqueeze(y_data, axis=1)
with paddle.no_grad():
logits = model(x_data)
loss = criterion(logits, y_data)
acc = paddle.metric.accuracy(logits, labels)
val_accuracy_manager.update(acc)
val_loss += loss
val_num += len(y_data)
total_val_loss = (val_loss / val_num) * batch_size
loss_record['val']['loss'].append(total_val_loss.numpy())
loss_record['val']['iter'].append(loss_iter)
val_acc = val_accuracy_manager.accumulate()
acc_record['val']['acc'].append(val_acc)
acc_record['val']['iter'].append(acc_iter)
print("#===epoch: {}, val loss is: {}, val acc is: {:2.2f}%===#".format(epoch, total_val_loss.numpy(), val_acc*100))
# ===================save====================
if val_acc > best_acc:
best_acc = val_acc
paddle.save(model.state_dict(), os.path.join(work_path, 'best_model.pdparams'))
paddle.save(optimizer.state_dict(), os.path.join(work_path, 'best_optimizer.pdopt'))
print(best_acc)
paddle.save(model.state_dict(), os.path.join(work_path, 'final_model.pdparams'))
paddle.save(optimizer.state_dict(), os.path.join(work_path, 'final_optimizer.pdopt'))
训练结果展示
总结
1.关于论文还是要花时间读透,而不是浅尝辄止要细扣
2.关于代码,没有捷径,即使花时间多写多改,当然我也参照了别人搭建网络的代码,对于第一次接触paddle的这样的效率无疑是最高的,代码很磨人,但我并不想放弃
3.其实无论是代码,还是论文,都需要脚踏实地















 2万+
2万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









