






 该项目演示了如何在AIStudio上通过预训练的模型快速进行原神角色的音色合成。用户可以输入文本和角色名,生成相应的语音。代码涉及PaddleSpeech库,包括FastSpeech2和HiFiGAN模型,以及数据解压、模型加载和语音生成的过程。
该项目演示了如何在AIStudio上通过预训练的模型快速进行原神角色的音色合成。用户可以输入文本和角色名,生成相应的语音。代码涉及PaddleSpeech库,包括FastSpeech2和HiFiGAN模型,以及数据解压、模型加载和语音生成的过程。
★★★ 本文源自AI Studio社区精品项目,【点击此处】查看更多精品内容 >>>
[原神] 音色合成 快速使用版
目前支持如下人物音色
[‘阿贝多’, ‘阿娜耶’, ‘艾尔海森’, ‘安柏’, ‘奥兹’, ‘芭芭拉’, ‘八重神子’, ‘班尼特’, ‘北斗’, ‘戴因斯雷布’, ‘迪卢克’, ‘迪娜泽黛’, ‘迪希雅’, ‘菲谢尔’, ‘枫原万叶’, ‘公子’, ‘海芭夏’, ‘胡桃’, ‘荒泷一斗’, ‘久岐忍’, ‘九条镰治’, ‘九条裟罗’, ‘凯瑟琳’, ‘凯亚’, ‘坎蒂丝’, ‘柯莱’, ‘可莉’, ‘刻晴’, ‘昆钧’, ‘拉赫曼’, ‘雷电将军’, ‘雷泽’, ‘丽莎’, ‘留云借风真君’, ‘罗莎莉亚’, ‘莫娜’, ‘纳西妲’, ‘妮露’, ‘凝光’, ‘派蒙’, ‘萍姥姥’, ‘琴’, ‘赛诺’, ‘散兵’, ‘砂糖’, ‘珊瑚宫心海’, ‘申鹤’, ‘神里绫华’, ‘神里绫人’, ‘提纳里’, ‘托克’, ‘托马’, ‘温迪’, ‘香菱’, ‘魈’, ‘宵宫’, ‘辛焱’, ‘行秋’, ‘烟绯’, ‘夜兰’, ‘影’, ‘优菈’, ‘云堇’, ‘哲平’, ‘钟离’]
新手指引
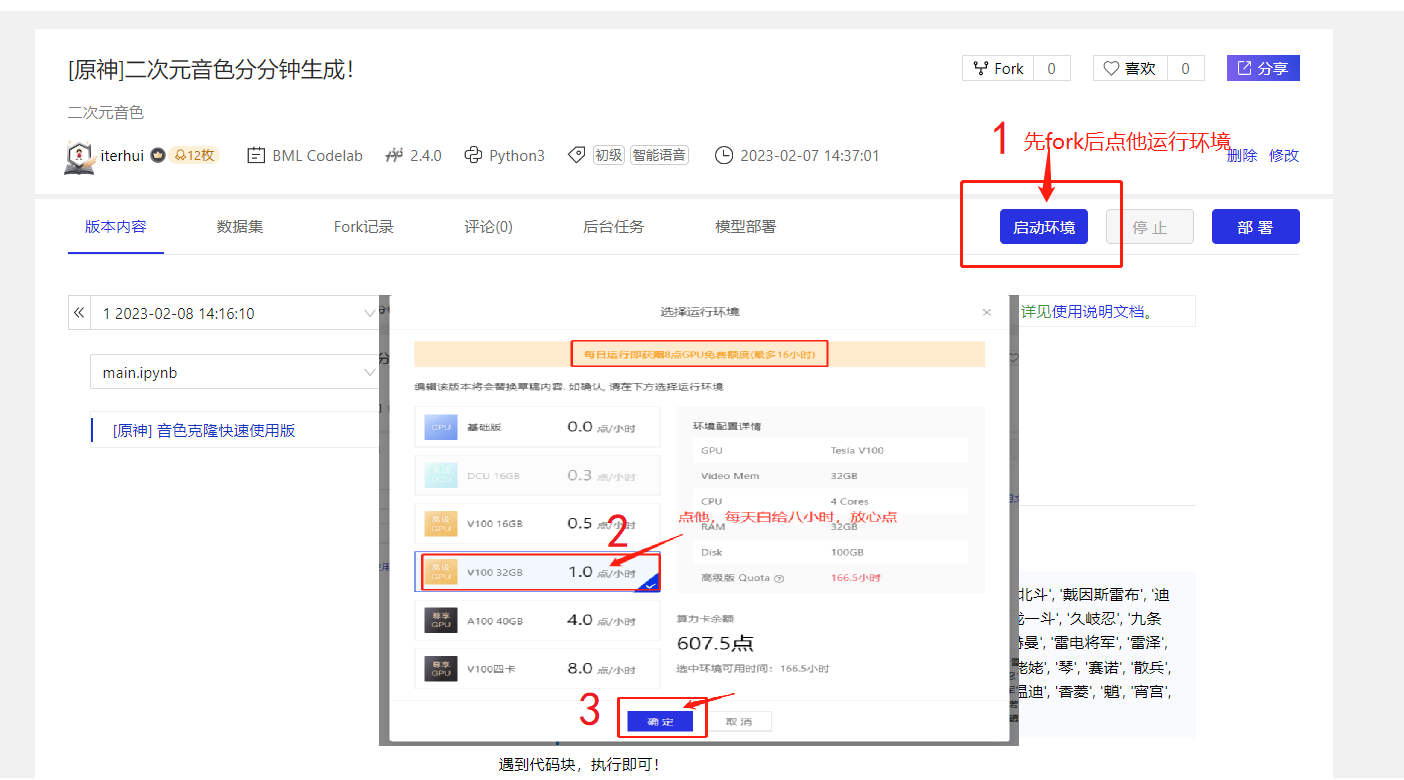
遇到代码块,执行即可!
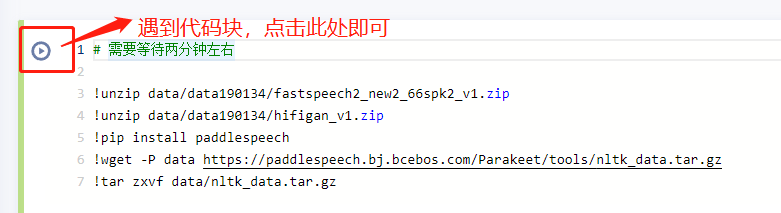
# 需要等待两分钟左右
!unzip data/data190134/fastspeech2_new2_66spk2_v1.zip
!unzip data/data190134/hifigan_v1.zip
!pip install paddlespeech
!wget -P data https://paddlespeech.bj.bcebos.com/Parakeet/tools/nltk_data.tar.gz
!tar zxvf data/nltk_data.tar.gz
import os
import paddle
import soundfile as sf
import yaml
from yacs.config import CfgNode
from paddlespeech.t2s.exps.syn_utils import get_voc_inference
from paddlespeech.t2s.exps.syn_utils import run_frontend
from paddlespeech.t2s.exps.syn_utils import get_am_inference
from paddlespeech.t2s.exps.syn_utils import get_frontend
class ERTTS():
def __init__(self, fs2_model_dir, fs2_model_name, voc_model_dir, voc_model_name):
# AM 参数初始化
self.am = "fastspeech2_aishell3"
self.am_config = os.path.join(fs2_model_dir, "default.yaml")
with open(self.am_config) as f:
self.am_config = CfgNode(yaml.safe_load(f))
self.am_ckpt = os.path.join(fs2_model_dir, fs2_model_name)
self.phones_dict = os.path.join(fs2_model_dir, "phone_id_map.txt")
self.tones_dict = None
self.am_stat = os.path.join(fs2_model_dir, "speech_stats.npy")
self.speaker_dict = os.path.join(fs2_model_dir, "speaker_id_map.txt")
# Voc 参数初始化
self.voc = 'hifigan_aishell3'
self.voc_config = os.path.join(voc_model_dir, "default.yaml")
with open(self.voc_config) as f:
self.voc_config = CfgNode(yaml.safe_load(f))
self.voc_ckpt = os.path.join(voc_model_dir, voc_model_name)
self.voc_stat = os.path.join(voc_model_dir, "feats_stats.npy")
# 加载模型
self.load_model()
# 前端参数
self.lang = "zh"
self.use_rhy = False
self.fs = 24000
self.merge_sentences = True
self.get_tone_ids = None
# 加载前端
self.frontend = get_frontend(
lang=self.lang,
phones_dict=self.phones_dict,
tones_dict=self.tones_dict,
use_rhy=self.use_rhy
)
def load_model(self):
# AM 模型
self.am_inference = get_am_inference(
am=self.am,
am_config=self.am_config,
am_ckpt=self.am_ckpt,
am_stat=self.am_stat,
phones_dict=self.phones_dict,
tones_dict=self.tones_dict,
speaker_dict=self.speaker_dict
)
# voc 模型
self.voc_inference = get_voc_inference(
voc=self.voc,
voc_config=self.voc_config,
voc_ckpt=self.voc_ckpt,
voc_stat=self.voc_stat
)
def text2speech(self, sentence, spk_id, output_path):
frontend_dict = run_frontend(
frontend=self.frontend,
text=sentence,
merge_sentences=self.merge_sentences,
get_tone_ids=self.get_tone_ids,
lang=self.lang)
phone_ids = frontend_dict['phone_ids']
with paddle.no_grad():
flags = 0
for i in range(len(phone_ids)):
part_phone_ids = phone_ids[i]
spk_id = paddle.to_tensor(spk_id)
mel = self.am_inference(part_phone_ids, spk_id)
# vocoder
wav = self.voc_inference(mel)
if flags == 0:
wav_all = wav
flags = 1
else:
wav_all = paddle.concat([wav_all, wav])
wav = wav_all.numpy()
sf.write(output_path, wav, samplerate=self.fs)
import os
out = "output"
os.makedirs(out)
tts_engine = ERTTS(
fs2_model_dir = "fastspeech2_yuanshen_new2_66spk2_v1",
fs2_model_name = "snapshot_iter_20600.pdz",
voc_model_dir = "hifigan_yuanshen_v1",
voc_model_name = "snapshot_iter_630000.pdz"
)
W0208 14:05:47.145433 266 gpu_resources.cc:61] Please NOTE: device: 0, GPU Compute Capability: 7.0, Driver API Version: 11.2, Runtime API Version: 11.2
W0208 14:05:47.150269 266 gpu_resources.cc:91] device: 0, cuDNN Version: 8.2.
100%|██████████| 575056/575056 [00:15<00:00, 36045.75it/s]
[2023-02-08 14:06:15,931] [ INFO] - Downloading https://bj.bcebos.com/paddle-hapi/models/bert/bert-base-chinese-vocab.txt and saved to /home/aistudio/.paddlenlp/models/bert-base-chinese
[2023-02-08 14:06:16,003] [ INFO] - Downloading bert-base-chinese-vocab.txt from https://bj.bcebos.com/paddle-hapi/models/bert/bert-base-chinese-vocab.txt
100%|██████████| 107k/107k [00:00<00:00, 7.37MB/s]
[2023-02-08 14:06:16,105] [ INFO] - tokenizer config file saved in /home/aistudio/.paddlenlp/models/bert-base-chinese/tokenizer_config.json
[2023-02-08 14:06:16,107] [ INFO] - Special tokens file saved in /home/aistudio/.paddlenlp/models/bert-base-chinese/special_tokens_map.json
import json
with open("spk_dict.json", "r", encoding="utf8") as f:
spk_trans_dict = json.load(f)
spkers = list(spk_trans_dict.keys())
print(spkers)
['阿贝多', '阿娜耶', '艾尔海森', '安柏', '奥兹', '芭芭拉', '八重神子', '班尼特', '北斗', '戴因斯雷布', '迪卢克', '迪娜泽黛', '迪希雅', '菲谢尔', '枫原万叶', '公子', '海芭夏', '胡桃', '荒泷一斗', '久岐忍', '九条镰治', '九条裟罗', '凯瑟琳', '凯亚', '坎蒂丝', '柯莱', '可莉', '刻晴', '昆钧', '拉赫曼', '雷电将军', '雷泽', '丽莎', '留云借风真君', '罗莎莉亚', '莫娜', '纳西妲', '妮露', '凝光', '派蒙', '萍姥姥', '琴', '赛诺', '散兵', '砂糖', '珊瑚宫心海', '申鹤', '神里绫华', '神里绫人', '提纳里', '托克', '托马', '温迪', '香菱', '魈', '宵宫', '辛焱', '行秋', '烟绯', '夜兰', '影', '优菈', '云堇', '哲平', '钟离']
替换文本为你需要的
下面是一个例子:
君不见,黄河之水天上来,奔流到海不复回。君不见,高堂明镜悲白发,朝如青丝暮成雪。
sentence = "君不见,黄河之水天上来,奔流到海不复回。君不见,高堂明镜悲白发,朝如青丝暮成雪。"
spk_id = spk_trans_dict['胡桃']
output_path = out + "/test.wav"
tts_engine.text2speech(sentence, spk_id, output_path)
import os
import IPython.display as ipd
# 测试第一句:中英文合成成功
ipd.Audio(output_path)
看到语音出现,成功!

项目总结
项目借助已经训练好的模型实现,无需训练,方便快捷。
个人总结
其他精选有趣项目:
基于PaddleClas2.2的从零到落地安卓部署的奥特曼分类实战
and 若干小白和进阶项目等你发现…
我在AI Studio上获得至尊等级,点亮10个徽章,来互关呀~
https://aistudio.baidu.com/aistudio/personalcenter/thirdview/643467

















 651
651

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









