






#★★★本文源自AlStudio社区精品项目,
【点击此处】查看更多精品内容 >>>
(https://aistudio.baidu.com/aistudio/proiectoverview/public?ad-from=4100)
用ERNIE-Layout看图自动写报告
0 项目背景
在企业日常信息化建设中,有一类需求特别普遍。比如下面的场景:
部门A:我们每周要报送个统计报表,格式基本是固定的,上面是统计表格,下面是一段文字综述。文字内容可能会根据企业考核指标调整,但是频率不高,你们开发下。
部门B:我们每月要出个经营分析报告,现在领导说要无纸化,最好可以在线上查看,当然,导出word的功能还是需要的,文字报告得签章……
部门C:年终总结的时候我们有个报告,格式是这样……
这些报告到底长什么样呢?通常来讲,就几张图表,但是要加入一段文字描述。

相对来说,随着各种酷炫BI工具的但是,开发图表其实挺简单的,信息量也非常丰富。但是!有图有表没文字怎么行!
这个文可不能让业务人员手写,必须自动生成! 于是各单位所谓的信息化建设,特别是数据分析开发工作,就变成了“SQL满天飞”的取数大作战……
比如下面这段文字,假设是自动生成的话,红框大概就是涉及到SQL的地方了……辣么多!

一个页面,如果背后关联了上百个后台的SQL(不少还是复杂join或者大表关联计算),大家可以设想下,点开这个页面的加载时间会多么酸爽

而且,一旦因为业务需要,有的文字描述需要进行调整,还得吭哧吭哧跑到后台改SQL,跑到前端改文字……
那么,这类问题是否有更加轻量级、维护方式更加友好的解决方案?本项目就围绕这类场景,基于ERNIE-Layout提供的文档智能能力展开探索。
1 环境准备
# 安装依赖库
!pip install --upgrade paddleocr
!pip install --upgrade paddlenlp
!pip install python-docx
2 ERNIE-Layout文档智能应用
ERNIE-Layout以文心文本大模型ERNIE为底座,融合文本、图像、布局等信息进行跨模态联合建模,创新性引入布局知识增强,提出阅读顺序预测、细粒度图文匹配等自监督预训练任务,升级空间解偶注意力机制,在各数据集上效果取得大幅度提升,相关资料可以参考ERNIE-Layout: Layout-Knowledge Enhanced Multi-modal Pre-training for Document Understanding。
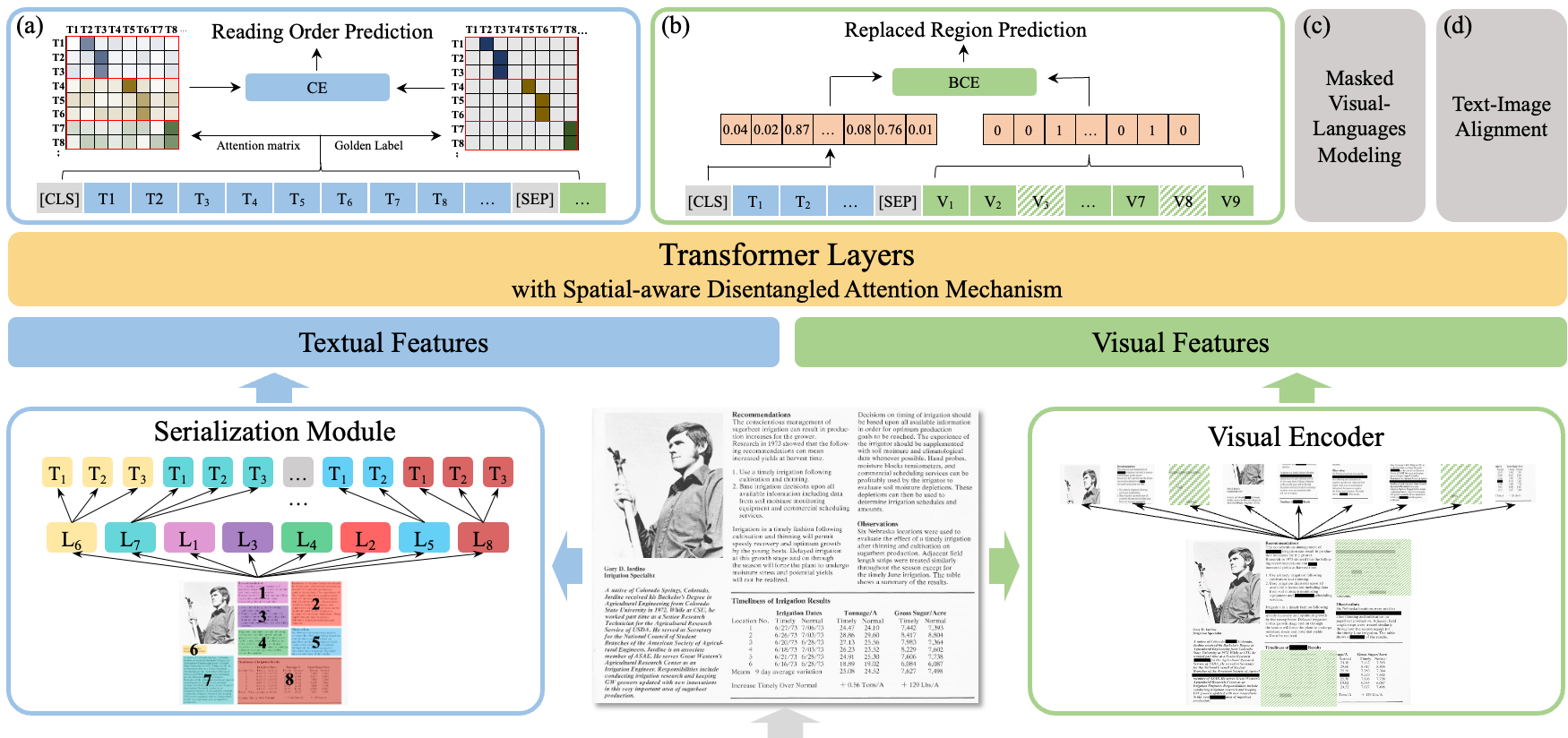
针对主流场景,ERNIE-Layout提供了开箱即用的Taskflow能力。
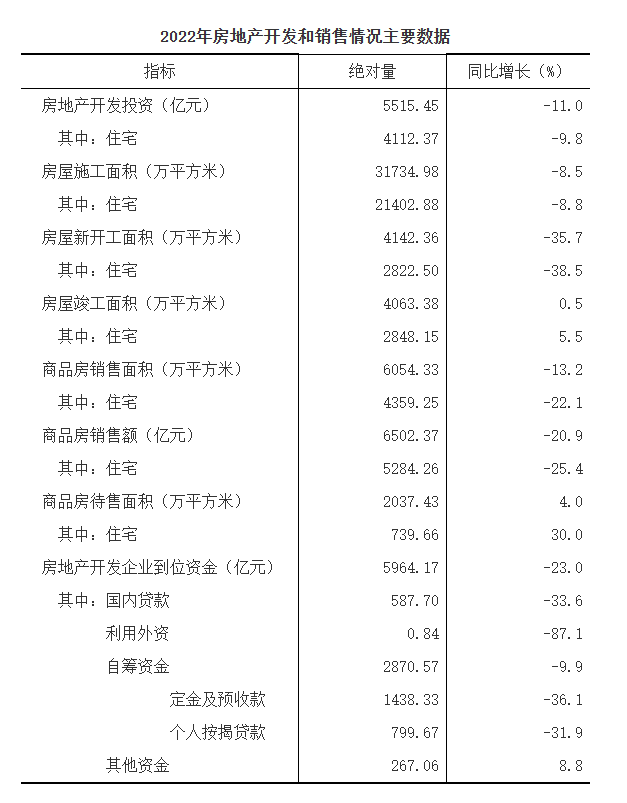
我们来看下面这张表格图片,体验下ERNIE-Layout强大的文档智能问答能力。
from pprint import pprint
from paddlenlp import Taskflow
import numpy as np
docprompt = Taskflow("document_intelligence")
pprint(docprompt([{"doc": "./test01.png", "prompt": ["2022年,全省房地产开发投资是多少?", "2022年,全省房地产开发投资比上年增长多少?", "住宅投资是多少?"]}]))
[2023-02-13 18:59:59,599] [ INFO] - We are using <class 'paddlenlp.transformers.ernie_layout.tokenizer.ErnieLayoutTokenizer'> to load 'ernie-layoutx-base-uncased'.
[2023-02-13 18:59:59,603] [ INFO] - Already cached /home/aistudio/.paddlenlp/models/ernie-layoutx-base-uncased/vocab.txt
[2023-02-13 18:59:59,605] [ INFO] - Already cached /home/aistudio/.paddlenlp/models/ernie-layoutx-base-uncased/sentencepiece.bpe.model
[2023-02-13 19:00:00,211] [ INFO] - tokenizer config file saved in /home/aistudio/.paddlenlp/models/ernie-layoutx-base-uncased/tokenizer_config.json
[2023-02-13 19:00:00,218] [ INFO] - Special tokens file saved in /home/aistudio/.paddlenlp/models/ernie-layoutx-base-uncased/special_tokens_map.json
[{'prompt': '2022年,全省房地产开发投资是多少?',
'result': [{'end': 42, 'prob': 1.0, 'start': 39, 'value': '5515. 45'}]},
{'prompt': '2022年,全省房地产开发投资比上年增长多少?',
'result': [{'end': 45, 'prob': 0.54, 'start': 43, 'value': '-11.'}]},
{'prompt': '住宅投资是多少?',
'result': [{'end': 55, 'prob': 0.95, 'start': 53, 'value': '4112.37'}]}]
可以看到,对于上面这张表格,直接用ERNIE-Layout的预训练模型,抽取结果已经比较准确,说明ERNIE-Layout的预训练模型在解读表格方面已经训练得比较到位了。
2022年,全省房地产开发投资5515.45亿元,比上年下降11.0%。其中,住宅投资4112.37亿元,下降9.8%,占房地产开发投资的比重为74.6%。
于是,上面这句话就可以拼接成:
result = docprompt([{
"doc":
"./test01.png",
"prompt": [
"2022年,全省房地产开发投资是多少?",
"2022年,全省房地产开发投资比上年增长多少?",
"住宅投资是多少?",
"住宅投资同比增长(%)是多少?"
]
}])
print("2022年,全省房地产开发投资" + result[0]['result'][0]['value'] + "亿元,比上年增长" +
result[1]['result'][0]['value'].replace(" ", "") + "%。其中,住宅投资" +
result[2]['result'][0]['value'].replace(" ", "") + "亿元,增长" +
result[3]['result'][0]['value'].replace(" ", "") + "%,占房地产开发投资的比重为" + str(
np.round(
float(result[2]['result'][0]['value'].replace(" ", "")) /
float(result[0]['result'][0]['value'].replace(" ", "")) *
100, 1)) + "%。")
2022年,全省房地产开发投资5515. 45亿元,比上年增长-11.%。其中,住宅投资4112.37亿元,增长-9.8%,占房地产开发投资的比重为74.6%。
资的比重为74.6%。
需要注意的是,尽管大部分时候能够正确识别到数字文本,但是OCR结果中总是会多出一些空格(特别是有小数点时),因此我们需要在后处理时将这些空格删除。
3 生成文档问答word报告
根据业务的需要,接下来我们得把自动读取表格的结果整理成一个word报告。具体方法当然是使用python-docx依赖库。
其实,想要直接用python-docx生成我们常用的中文报告,要趟过的坑也不少。总结起来,至少包括了:
- 中文字体的使用
- 中文字号的对应
- 标题、图片居中的处理
- 文字颜色的调整
- 文档缩进的处理
其中,WORD中字号、磅值的对应大体如下:
- 字号‘八号’对应磅值5
- 字号‘七号’对应磅值5.5
- 字号‘小六’对应磅值6.5
- 字号‘六号’对应磅值7.5
- 字号‘小五’对应磅值9
- 字号‘五号’对应磅值10.5
- 字号‘小四’对应磅值12
- 字号‘四号’对应磅值14
- 字号‘小三’对应磅值15
- 字号‘三号’对应磅值16
- 字号‘小二’对应磅值18
- 字号‘二号’对应磅值22
- 字号‘小一’对应磅值24
- 字号‘一号’对应磅值26
- 字号‘小初’对应磅值36
- 字号‘初号’对应磅值42
我们常用的报告字号,一般是二号、三号字,我们在设置时一一对照即可。
from docx import Document
from docx.shared import Inches
from docx.oxml.ns import qn
from docx.shared import RGBColor,Cm,Pt
from docx.enum.text import WD_ALIGN_PARAGRAPH,WD_PARAGRAPH_ALIGNMENT
document = Document()
# 输入标题
h = document.add_heading()
h.paragraph_format.alignment = WD_ALIGN_PARAGRAPH.CENTER
run = h.add_run('2022年福建省房地产开发和销售情况')
# 中文字体可以直接输入名字,只要自己本机上有装这个字体,下载的时候就能够识别
run.font.name = '方正小标宋简体'
run.font.element.rPr.rFonts.set(qn('w:eastAsia'), '方正小标宋简体')
run.font.color.rgb = RGBColor(0, 0, 0)
run.font.size = Pt(22)
h1 = document.add_heading(level=1)
# 注意报告需要添加缩进
run = h1.add_run(' 一、房地产开发投资完成情况')
run.font.name = '黑体'
run.font.element.rPr.rFonts.set(qn('w:eastAsia'), '黑体')
run.font.color.rgb = RGBColor(0, 0, 0)
run.font.size = Pt(16)
p1 = document.add_paragraph()
p1.paragraph_format.space_before = Pt(16)
# 注意报告需要添加缩进
run = p1.add_run(" 2022年,全省房地产开发投资" + result[0]['result'][0]['value'].replace(" ", "") + "亿元,比上年增长" +
result[1]['result'][0]['value'].replace(" ", "") + "%。其中,住宅投资" +
result[2]['result'][0]['value'].replace(" ", "") + "亿元,增长" +
result[3]['result'][0]['value'].replace(" ", "") + "%,占房地产开发投资的比重为" + str(
np.round(
float(result[2]['result'][0]['value'].replace(" ", "")) /
float(result[0]['result'][0]['value'].replace(" ", "")) *
100, 1)) + "%。")
run.font.name = '仿宋_GB2312'
run.blod = False
run.font.element.rPr.rFonts.set(qn('w:eastAsia'), '仿宋_GB2312')
run.font.color.rgb = RGBColor(0, 0, 0)
run.font.size = Pt(16)
paragraph = document.add_paragraph()
# 通过段落处理完成图片居中设置
paragraph.alignment = WD_PARAGRAPH_ALIGNMENT.CENTER
run = paragraph.add_run("")
run.add_picture('test01.png', width=Cm(10.24))
document.save('demo.docx')
我们可以把生成的word文件下载下来,效果如下:

相当智能有没有!现在不需要写SQL也能出一个报告了! 
4 应用部署
本项目的部署效果读者可以在【应用体验】中查看,相关代码保存在untitled.streamlit.py中。
由于这类文档内容场景定制性较强,读者如需要进行自定义的报表生成,可以参照项目写法,自行修改部署脚本。
5 小结
在本项目中,我们基于ERNIE-Layout提供的文档智能问答能力,实现了表格类型图片报告的撰写生成。
相比于传统信息系统需要在前后台来回奔走处理SQL逻辑的方式,显然用ERNIE-Layout这类基于多模态的文档智能问答模型更有发展前景。
当然,仅仅使用预训练模型,在实际业务中往往还是非常受限的。针对具体业务,还需要收集数据集进行针对性微调,才能让ERNIE-Layout更好地发挥作用。














 1003
1003











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









