









前言
这是百度在2022年的一篇工作:ERNIE-Layout。该工作通过增强布局知识的预训练模型,以学习更好的表示,结合文本、布局和图像的特征。旨在利用文档布局相关信息,进行文档理解,进一步提高文档信息抽取的性能。
1、文档布局信息的挖掘与利用
问题1:以OCR识别文档将信息序列化,以从左到右、从上到下的形式排列文字。然而,对于复杂结构布局的文档,效果不够理想。
解决方法:在文本输入后的序列化过程中加入一个基于布局的文档解析器,为每个输入文档生成一个合适的阅读顺序,这么做可以比OCR出来的结果的顺序更符合人类阅读习惯,然后为每个文本、视觉token都设置位置嵌入和布局嵌入。
问题2:现有方案将布局信息作为一种特殊的位置特征,如:layoutlm、layoutlmv2等,然而,布局可以看作是一种模态信息,将布局信息编码为一种特殊的位置特征,模型将缺少布局上的语义表达。
解决方法:为了实现多模态间的互动,文章借鉴了DeBERTa的解耦注意力,并提出了一种空间感知的分解注意力机制。以此向模型引入布局语义信息。
2、模型架构概述
ERNIE-Layout基于Transformer Encode架构,并提出以下trick:
2.1 OCR工具提取信息
借助OCR工具提取图片中的文字及文字对应的坐标信息(bounding box)。例如:paddleOCR等.
2.2 复杂布局position_ids
如下图,文档中同时包含了双栏结构、图片、表格等内容,其布局结构非常复杂,如果借鉴传统的OCR识别,效果非常差,在ERNIE-Layout借鉴了 DeBERTa 的解耦注意力,依靠Layout-Parser来设计 position_ids。LayoutParser是借助于目标检测模型来提取重要的内容patch,从而避免了两列内容按行扫描的混乱结果。

Layout-Parser:
论文:https://arxiv.org/pdf/2103.15348.pdf
代码:https://github.com/Layout-Parser/layout-parser
2.3 预训练
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-bbAWxhDX-1690101172028)(/Users/junhui/Desktop/yjh/文章/ernie-layout/ernie-layout.assets/截屏2023-07-22 22.43.17.png)]](https://img-blog.csdnimg.cn/6404d36ba9ca4c69ae4cca04e7d03200.png)
模型整体架构
ERNIE-Layout通过引入序列化模块来纠正栅格扫描的顺序,视觉编码器提取相应的图像特征。通过空间感知的分解注意力机制,ERNIE-Layout提出了四个预训练任务。
-
Reading Order Prediction,阅读顺序预测
由于transformer的输入序列没有明确的文本界限(不知道每段是否结束,段与段之间的区分)。所以为了模型对布局知识和阅读顺序之间的关系有更好的理解,提出了阅读顺序预测。

-
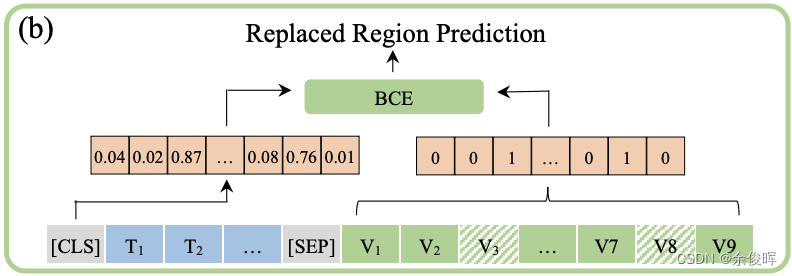
Replaced Region Prediction,替换区域预测
为了使模型能够感知到图像斑块和文本之间的细微对应关系,在布局知识的帮助下,提出了替换区域预测。具体来说,随机选择10%的斑块,用另一幅图像的斑块来替换,处理后的图像由视觉编码器编码,并输入多模态变换器中。然后,Transformer输出的[CLS]向量被用来预测哪些斑块被替换。
-
Masked Visual-Language Modeling,遮蔽视觉-语言模型
目的是根据文本上下文和多模态信息恢复被Mask的文本标记,类似MLM预训练。
-
Text-Image Alignment,文本-图像对齐
目的是帮助模型学习图像区域和边界框的坐标之间的空间对应关系,其实就随机遮蔽一些文字,通过一个线型层,判断文字是否被覆盖,这点与layoutlmv2预训练任务一致。
3、输入表示(Embedding)
ERNIE布局的输入序列包括文本部分和视觉部分,以及表示每个部分都是其模态特征的组合和布局嵌入
- Text Embedding:主要利用BERT将序列化模块后的文本进行embedding。
- Visual Embedding:提取文档特征,将文档图片转换成224×224格式后,利用Faster-RCNN作为视觉编码的backbone获得visual_embeddings,然后加入position_embeddings、token_type_embeddings 、bbox_embeddings得到最终的图像Embedding。
- Layout Embedding:主要将文本和文本对应的bounding box【x1,x2,y1,y2,h,w】、图片和图片对应的bounding box归一化到[0,1000]的范围,经过embedding得到【x1_embedding、x2_embedding、y1_embedding、y2_embedding、h_embedding和w_embedding】。
4、demo
文档信息抽取案例

code:
from paddlenlp import Taskflow
docprompt = Taskflow("document_intelligence")
print(docprompt([{"doc": "./resume.png", "prompt": ["五百丁本次想要担任的是什么职位?", "五百丁是在哪里上的大学?", "大学学的是什么专业?"]}]))
结果:
[{'prompt': '五百丁本次想要担任的是什么职位?',
'result': [{'end': 7, 'prob': 1.0, 'start': 4, 'value': '客户经理'}]},
{'prompt': '五百丁是在哪里上的大学?',
'result': [{'end': 37, 'prob': 1.0, 'start': 31, 'value': '广州五百丁学院'}]},
{'prompt': '大学学的是什么专业?',
'result': [{'end': 44, 'prob': 0.82, 'start': 38, 'value': '金融学(本科)'}]}]
更多demo开源地址:https://github.com/PaddlePaddle/PaddleNLP/tree/develop/model_zoo/ernie-layout
总结
优点:ERNIE-Layout对识别到的文档字词进行重新排列,设计了一种新的注意力机制,以帮助ERNIE-Layout在文本/图像和布局特征之间建立更好的联系。在文章中通过大量的实验证明了ERNIE-Layout的有效性,并且分析了利用不同的布局知识对文档理解的影响。
缺点:ERNIE-Layout整体依赖于paddleOCR的识别效果,然而,paddleOCR的识别精度与推理速度呈负相关。
参考文献
【1】ERNIE-Layout: Layout Knowledge Enhanced Pre-training for Visually-rich Document Understanding,https://arxiv.org/abs/2210.06155
【2】LayoutParser: A Unified Toolkit for Deep Learning Based Document Image Analysis,https://arxiv.org/pdf/2103.15348.pdf
【3】https://github.com/PaddlePaddle/PaddleNLP/tree/develop/model_zoo/ernie-layout
【4】https://github.com/Layout-Parser/layout-parser
【5】LayoutLM: Pre-training of Text and Layout for Document Image Understanding,https://arxiv.org/abs/1912.13318
【6】LayoutLMv2: Multi-modal Pre-training for Visually-Rich Document Understanding,https://arxiv.org/abs/2012.14740














 998
998











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









