







★★★ 本文源自AlStudio社区精品项目,【点击此处】查看更多精品内容 >>>
Skeletonization: 基于UNet的骨架提取网络
本项目为ICCV 2021:the Deep Learning for Geometric Computing中Pixel SkelNetOn比赛的亚军方案
论文地址:U-Net based skeletonization and bag of tricks
原项目地址:https://github.com/namdvt/skeletonization
主要贡献
- 向UNet网络中加入 Multi-head Attention 机制
- 在Decoder中引入CBAM(Convolutional Block Attention Module)
- 建立Auxiliary task learning,将模型前向传递过程中的结果加入Loss的计算中
网络整体结构

UNet网络因为其机构酷似“U”而得名,在本项目中,输入图像大小为(256 * 256),Loss的计算中需要最终结果图(256 * 256)和推理过程中的三张图,除了label以外,对label进行三次resize,从而得到另外三张图的label
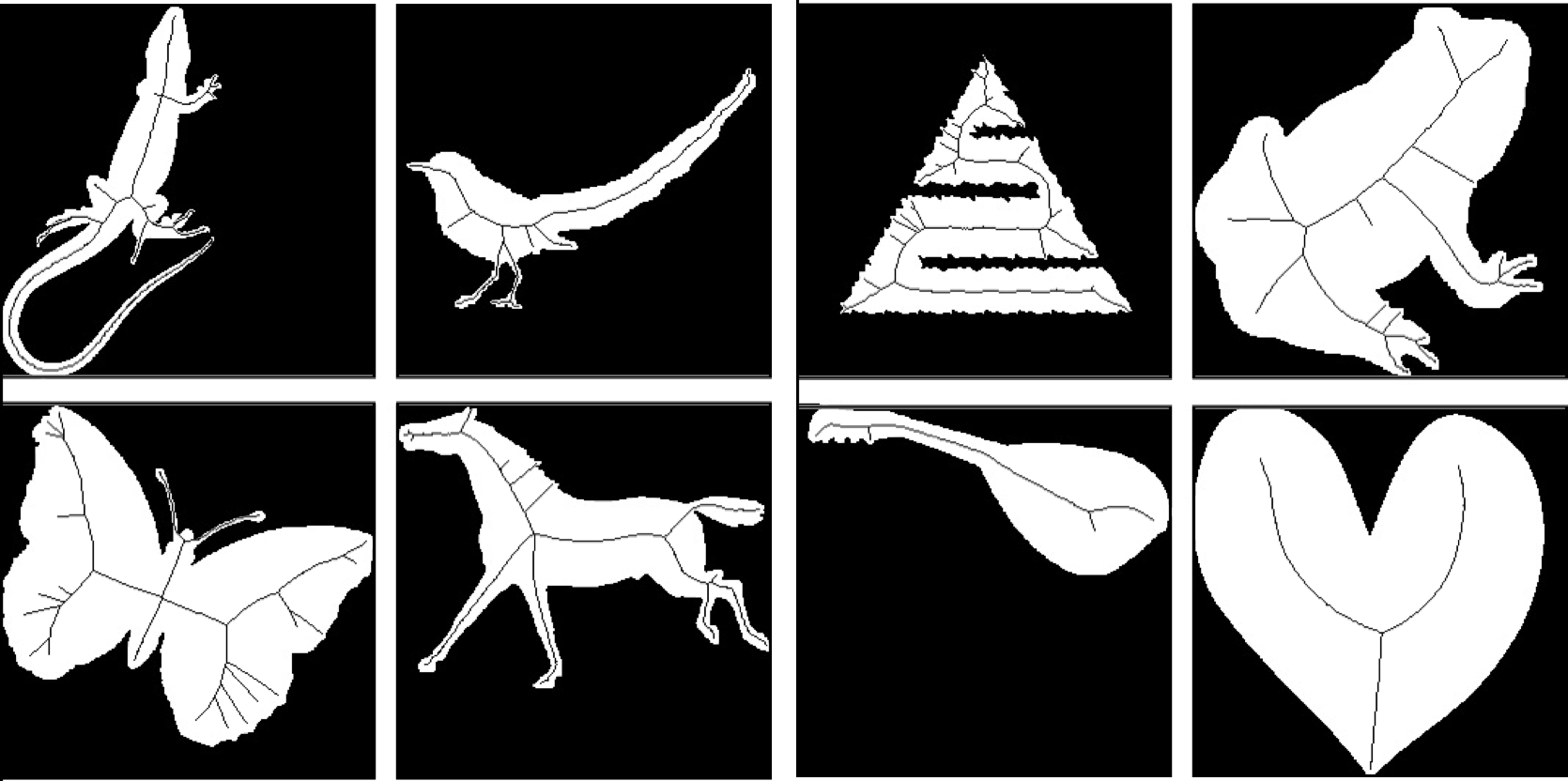
预测效果
左图为待预测图,中间为真值图,右侧为预测图

数据集介绍
图像数据集由1725幅黑白图像组成,这些图像以256×256像素的便携式网络图形格式提供,分为1218幅训练图像、241幅验证图像和266幅测试图像。我们提供测试集和验证集中每个类的样本。有两种类型的图像:表示数据集中形状的形状图像和表示与形状图像对应的骨架的骨架图像。
Pixel SkelNetOn 竞赛:像素骨架提取分析能对不同目标的二值化掩码进行细化,克服传统方法人工设置参数的不便。如何从少量样本中准确提取不同形状的的骨架,存在一定的挑战性。
1.解压数据集
该数据集为CVPR 2022官方提供
!unzip data/data190494/Pixel_SkelNet.zip -d ./Pixel_SkelNet
2.自定义数据集加载
通过paddle提供的paddle.io.Dataset接口自定义数据加载方式
输入图片已是二值化之后的,因此可以将像素值整理至[0,1]中,将label三次resize之后作为标签
import paddle
import cv2
import numpy as np
class Normalize(object):
def __call__(self, sample):
image, label = sample
image = image / 255.
image = np.expand_dims(image, axis=0)
label = label / 255.
# 二值化
label[label >= 0.5] = 1
label[label < 0.5] = 0
label_128 = cv2.resize(label, (128, 128), interpolation=cv2.INTER_AREA)
label_64 = cv2.resize(label, (64, 64), interpolation=cv2.INTER_AREA)
label_32 = cv2.resize(label, (32, 32), interpolation=cv2.INTER_AREA)
return image, label, label_128, label_64, label_32
class MyDataset(paddle.io.Dataset):
def __init__(self, ann_path):
super(MyDataset,self).__init__()
self.normalize = Normalize()
self.dataset = []
self.indexes = []
with open(ann_path, 'r') as f:
ann_file = f.readlines()
for i in ann_file:
i = i.replace('\n', '').split(' ')
self.indexes.append([i[0], i[1]])
img = cv2.imread(i[0])
label = cv2.imread(i[1])
self.dataset.append([img, label])
def __getitem__(self,index):
image, label = self.dataset[index]
image = cv2.resize(image, (256, 256))
image = (image[:,:,0])
label = cv2.resize(label, (256, 256))
label = (label[:,:,0])
image, label, label_128, label_64, label_32 = self.normalize((image, label))
return [image.astype("float32")], [label, label_128, label_64, label_32]
def __len__(self):
return len(self.indexes)
3.定义Loss
本方案中的Loss需要根据四幅输出图像和四个label计算结果,这种计算方式称为Auxiliary task learning.
四个Loss的加权公式为:
L
f
i
n
a
l
=
0.5
L
256
+
0.3
L
128
+
0.2
L
64
+
0.1
L
32
L_{final}=0.5L_{256}+0.3L_{128}+0.2L_{64}+0.1L_{32}
Lfinal=0.5L256+0.3L128+0.2L64+0.1L32
import paddle.nn as nn
import paddle
import math
import paddle.nn.functional as F
class DiceLoss(nn.Layer):
def __init__(self, smooth=1.):
super(DiceLoss, self).__init__()
self.smooth = smooth
def forward(self, preds, targets):
numerator = 2 * paddle.sum(preds * targets) + self.smooth
denominator = paddle.sum(preds ** 2) + paddle.sum(targets ** 2) + self.smooth
soft_dice_loss = 1 - numerator / denominator
return soft_dice_loss
class WeightedFocalLoss(nn.Layer):
"Non weighted version of Focal Loss"
def __init__(self, alpha=.01, gamma=2):
super(WeightedFocalLoss, self).__init__()
self.alpha = paddle.to_tensor([alpha, 1-alpha])
self.gamma = gamma
def forward(self, preds, targets):
BCE_loss = F.binary_cross_entropy(paddle.flatten(preds), paddle.flatten(targets).astype("float32"), reduction='none')
targets = targets.astype(paddle.compat.long_type)
# self.alpha = self.alpha.to(preds.device)
at = self.alpha.gather(paddle.flatten(targets))
pt = paddle.exp(-BCE_loss)
F_loss = at*(1-pt)**self.gamma * BCE_loss
F_loss = F_loss.mean()
if math.isnan(F_loss) or math.isinf(F_loss):
F_loss = paddle.zeros(1).to(preds.device)
return F_loss
class Loss(nn.Layer):
def __init__(self):
super(Loss, self).__init__()
self.alpha = 0.4
self.dice_loss = DiceLoss()
self.focal_loss = WeightedFocalLoss()
self.w_dice = 1.
self.w_focal = 100.
self.S_dice = []
self.S_focal = []
self.sigmoid = paddle.nn.Sigmoid()
def forward(self, pred, pred_128, pred_64, pred_32, target, target_128, target_64, target_32):
pred = self.sigmoid(pred.squeeze())
pred_128 = self.sigmoid(pred_128.squeeze())
pred_64 = self.sigmoid(pred_64.squeeze())
pred_32 = self.sigmoid(pred_32.squeeze())
soft_dice_loss = self.dice_loss(pred, target) * self.w_dice
bce_loss = self.focal_loss(pred, target) * self.w_focal
soft_dice_loss_128 = self.dice_loss(pred_128, target_128) * self.w_dice
bce_loss_128 = self.focal_loss(pred_128, target_128) * self.w_focal
soft_dice_loss_64 = self.dice_loss(pred_64, target_64) * self.w_dice
bce_loss_64 = self.focal_loss(pred_64, target_64) * self.w_focal
soft_dice_loss_32 = self.dice_loss(pred_32, target_32) * self.w_dice
bce_loss_32 = self.focal_loss(pred_32, target_32) * self.w_focal
loss = 0.5*(soft_dice_loss+bce_loss) \
+ 0.3*(soft_dice_loss_128+bce_loss_128) \
+ 0.2*(soft_dice_loss_64+bce_loss_64) \
+ 0.1*(soft_dice_loss_32+bce_loss_32)
return loss
4.定义优化器
原项目使用的优化器为CosineAnnealingWarmRestarts,在Paddle中并未提供
这里使用项目中复现的CosineAnnealingWarmRestarts优化器
from paddle.optimizer.lr import LinearWarmup
from paddle.optimizer.lr import CosineAnnealingDecay
class Cosine(CosineAnnealingDecay):
"""
Cosine learning rate decay
lr = 0.05 * (math.cos(epoch * (math.pi / epochs)) + 1)
Args:
lr(float): initial learning rate
step_each_epoch(int): steps each epoch
epochs(int): total training epochs
"""
def __init__(self, lr, step_each_epoch, epochs, **kwargs):
super(Cosine, self).__init__(
learning_rate=lr,
T_max=step_each_epoch * epochs, )
self.update_specified = False
class CosineWarmup(LinearWarmup):
"""
Cosine learning rate decay with warmup
[0, warmup_epoch): linear warmup
[warmup_epoch, epochs): cosine decay
Args:
lr(float): initial learning rate
step_each_epoch(int): steps each epoch
epochs(int): total training epochs
warmup_epoch(int): epoch num of warmup
"""
def __init__(self, lr, step_each_epoch, epochs, warmup_epoch=5, **kwargs):
assert epochs > warmup_epoch, "total epoch({}) should be larger than warmup_epoch({}) in CosineWarmup.".format(
epochs, warmup_epoch)
warmup_step = warmup_epoch * step_each_epoch
start_lr = 0.0
end_lr = lr
lr_sch = Cosine(lr, step_each_epoch, epochs - warmup_epoch)
super(CosineWarmup, self).__init__(
learning_rate=lr_sch,
warmup_steps=warmup_step,
start_lr=start_lr,
end_lr=end_lr)
self.update_specified = False
5.定义UNet模型
论文中描述的模型结构很直观
The multi-head attention
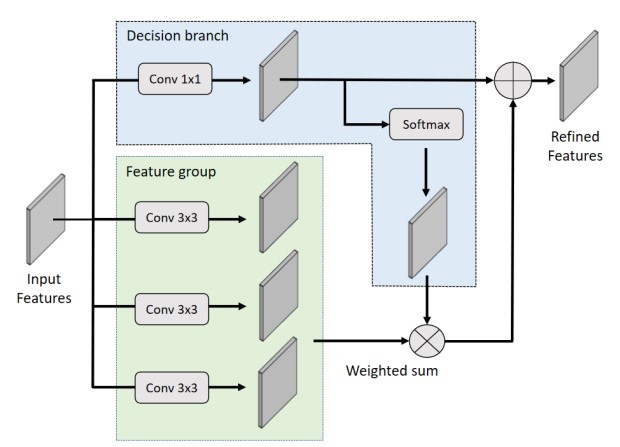
The CBAM architecture
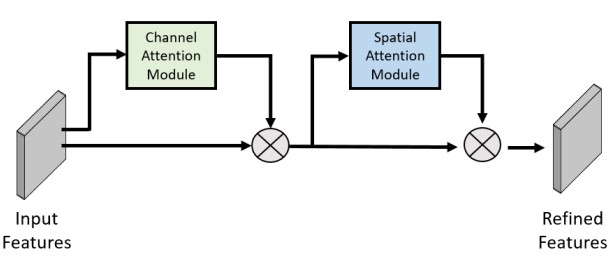
将上述两个网络完成后,即可根据总体网络结构图加入UNet网络,完成对UNet网络的修改
import paddle
import paddle.nn as nn
import paddle.nn.functional as F
class Conv2d(nn.Layer):
def __init__(self, in_channels, out_channels, kernel_size, stride=1, padding=0):
super(Conv2d, self).__init__()
self.conv = nn.Conv2D(in_channels, out_channels, kernel_size, stride=stride, padding=padding)
self.bn = nn.BatchNorm2D(out_channels)
self.relu = nn.ReLU()
def forward(self, x):
x = self.conv(x)
x = self.bn(x)
x = self.relu(x)
return x
class DoubleConv2d(nn.Layer):
def __init__(self, in_channels, out_channels, kernel_size, stride=1, padding=0, bias=True):
super(DoubleConv2d, self).__init__()
self.conv1 = Conv2d(in_channels, out_channels, kernel_size, stride, padding)
self.conv2 = Conv2d(out_channels, out_channels, kernel_size, stride, padding)
def forward(self, x):
x = self.conv1(x)
x = self.conv2(x)
return x
class AttentionGroup(nn.Layer):
def __init__(self, num_channels):
super(AttentionGroup, self).__init__()
self.conv1 = Conv2d(num_channels, num_channels, kernel_size=3, padding=1)
self.conv2 = Conv2d(num_channels, num_channels, kernel_size=3, padding=1)
self.conv3 = Conv2d(num_channels, num_channels, kernel_size=3, padding=1)
self.conv_1x1 = nn.Conv2D(num_channels, 3, kernel_size=1)
self.softmax = nn.Softmax(axis=1)
def forward(self, x):
x1 = self.conv1(x)
x2 = self.conv2(x)
x3 = self.conv3(x)
# s = paddle.nn.Softmax(self.conv_1x1(x), axis=1)
s = self.softmax(self.conv_1x1(x))
att = s[:,0,:,:].unsqueeze(1) * x1 + s[:,1,:,:].unsqueeze(1) * x2 \
+ s[:,2,:,:].unsqueeze(1) * x3
return x + att
class UNet(nn.Layer):
def __init__(self,):
super().__init__()
self.encode = Encoder()
self.decode = Decoder()
def forward(self, x):
out1, out2, out3, out4, x = self.encode(x)
x, aux_128, aux_64, aux_32 = self.decode(out1, out2, out3, out4, x)
return x.squeeze(), aux_128.squeeze(), aux_64.squeeze(), aux_32.squeeze()
class UpConv2d(nn.Layer):
def __init__(self, in_channels, out_channels, kernel_size, stride=1, padding=0, bias=True):
super(UpConv2d, self).__init__()
self.conv = nn.Conv2DTranspose(in_channels, out_channels, kernel_size, stride=stride, padding=padding)
self.bn = nn.BatchNorm2D(out_channels)
self.relu = nn.ReLU()
def forward(self, x):
x = self.conv(x)
x = self.bn(x)
x = self.relu(x)
return x
class ChannelAttention(nn.Layer):
def __init__(self, in_planes, ratio=16):
super(ChannelAttention, self).__init__()
self.avg_pool = nn.AdaptiveAvgPool2D(1)
self.max_pool = nn.AdaptiveAvgPool2D(1)
self.fc = nn.Sequential(nn.Conv2D(in_planes, in_planes // 16, 1),
nn.ReLU(),
nn.Conv2D(in_planes // 16, in_planes, 1))
self.sigmoid = nn.Sigmoid()
def forward(self, x):
avg_out = self.fc(self.avg_pool(x))
max_out = self.fc(self.max_pool(x))
out = avg_out + max_out
return self.sigmoid(out)
class SpatialAttention(nn.Layer):
def __init__(self, kernel_size=7):
super(SpatialAttention, self).__init__()
self.conv1 = nn.Conv2D(2, 1, kernel_size, padding=kernel_size // 2)
self.sigmoid = nn.Sigmoid()
def forward(self, x):
avg_out = paddle.mean(x, axis=1, keepdim=True)
max_out = paddle.max(x, axis=1, keepdim=True)
x = paddle.concat([avg_out, max_out], axis=1)
x = self.conv1(x)
return self.sigmoid(x)
class Encoder(nn.Layer):
def __init__(self, in_channels=3):
super().__init__()
self.conv1 = DoubleConv2d(1, 64, kernel_size=3, padding=1)
self.conv2 = DoubleConv2d(64, 128, kernel_size=3, padding=1)
self.conv3 = DoubleConv2d(128, 256, kernel_size=3, padding=1)
self.conv4 = DoubleConv2d(256, 512, kernel_size=3, padding=1)
self.conv5 = DoubleConv2d(512, 1024, kernel_size=3, padding=1)
self.pooling = nn.MaxPool2D(kernel_size=2)
self.att1 = AttentionGroup(64)
self.att2 = AttentionGroup(128)
self.att3 = AttentionGroup(256)
self.att4 = AttentionGroup(512)
self.att5 = AttentionGroup(1024)
def forward(self, x):
out1 = self.conv1(x)
out1 = self.att1(out1)
out2 = self.conv2(self.pooling(out1))
out2 = self.att2(out2)
out3 = self.conv3(self.pooling(out2))
out3 = self.att3(out3)
out4 = self.conv4(self.pooling(out3))
out4 = self.att4(out4)
out5 = self.conv5(self.pooling(out4))
out5 = self.att5(out5)
return out1, out2, out3, out4, out5
class Decoder(nn.Layer):
def __init__(self):
super().__init__()
self.upconv1 = UpConv2d(1024, 512, kernel_size=2, stride=2)
self.upconv2 = UpConv2d(512, 256, kernel_size=2, stride=2)
self.upconv3 = UpConv2d(256, 128, kernel_size=2, stride=2)
self.upconv4 = UpConv2d(128, 64, kernel_size=2, stride=2)
self.conv1 = DoubleConv2d(1024, 512, kernel_size=3, padding=1)
self.conv2 = DoubleConv2d(512, 256, kernel_size=3, padding=1)
self.conv3 = DoubleConv2d(256, 128, kernel_size=3, padding=1)
self.conv4 = DoubleConv2d(128, 64, kernel_size=3, padding=1)
self.conv1x1 = nn.Conv2D(64, 1, kernel_size=1, stride=1, padding=0)
self.aux_conv_128 = nn.Conv2D(128, 1, kernel_size=1, stride=1, padding=0)
self.aux_conv_64 = nn.Conv2D(256, 1, kernel_size=1, stride=1, padding=0)
self.aux_conv_32 = nn.Conv2D(512, 1, kernel_size=1, stride=1, padding=0)
self.ca1 = ChannelAttention(512)
self.sa1 = SpatialAttention()
self.ca2 = ChannelAttention(256)
self.sa2 = SpatialAttention()
self.ca3 = ChannelAttention(128)
self.sa3 = SpatialAttention()
self.ca4 = ChannelAttention(64)
self.sa4 = SpatialAttention()
def forward(self, out1, out2, out3, out4, x):
x = self.upconv1(x)
x = paddle.concat([x, out4], axis=1)
x = self.conv1(x)
x = self.ca1(x) * x
x = self.sa1(x) * x
aux_32 = self.aux_conv_32(x)
x = self.upconv2(x)
x = paddle.concat([x, out3], axis=1)
x = self.conv2(x)
x = self.ca2(x) * x
x = self.sa2(x) * x
aux_64 = self.aux_conv_64(x)
x = self.upconv3(x)
x = paddle.concat([x, out2], axis=1)
x = self.conv3(x)
x = self.ca3(x) * x
x = self.sa3(x) * x
aux_128 = self.aux_conv_128(x)
x = self.upconv4(x)
x = paddle.concat([x, out1], axis=1)
x = self.conv4(x)
x = self.ca4(x) * x
x = self.sa4(x) * x
x = self.conv1x1(x)
return x, aux_128, aux_64, aux_32
6.查看网络结构
使用padd.Model()集成网络,进而实现使用model.fit()等高阶接口完成模型训练
model = paddle.Model(UNet())
model.summary((1,1,256,256))
7.训练网络
已将下列代码放入train.py中
根据论文的描述,训练200个epoch
import paddle
from core.model import UNet
from solver.dateset_ import MyDataset
from solver.loss import Loss
from solver.coswarmup import CosineWarmup
train_dataset = MyDataset('Pixel_SkelNet/train/train_pair.lst')
test_dataset = MyDataset('Pixel_SkelNet/test/test_pair.lst')
model = paddle.Model(UNet())
# model.summary((1,3,256,256))
scheduler = CosineWarmup(
lr=0.02, step_each_epoch=10, epochs=200, warmup_steps=10, start_lr=0, end_lr=0.02, verbose=True)
optim = paddle.optimizer.SGD(learning_rate=scheduler, parameters=model.parameters())
model.prepare(optimizer=optim,
loss=Loss())
callback = paddle.callbacks.VisualDL(log_dir='visualdl_log_dir')
model.fit(train_dataset,
eval_data=test_dataset,
eval_freq=10,
epochs=200,
batch_size=20,
save_dir='model',
log_freq=100,
save_freq=10,
callbacks=callback,
verbose=1)
# 这个save命令可以直接保存推理模型
model.save('inference_model/Model', training=False)
!python train.py
训练结果:

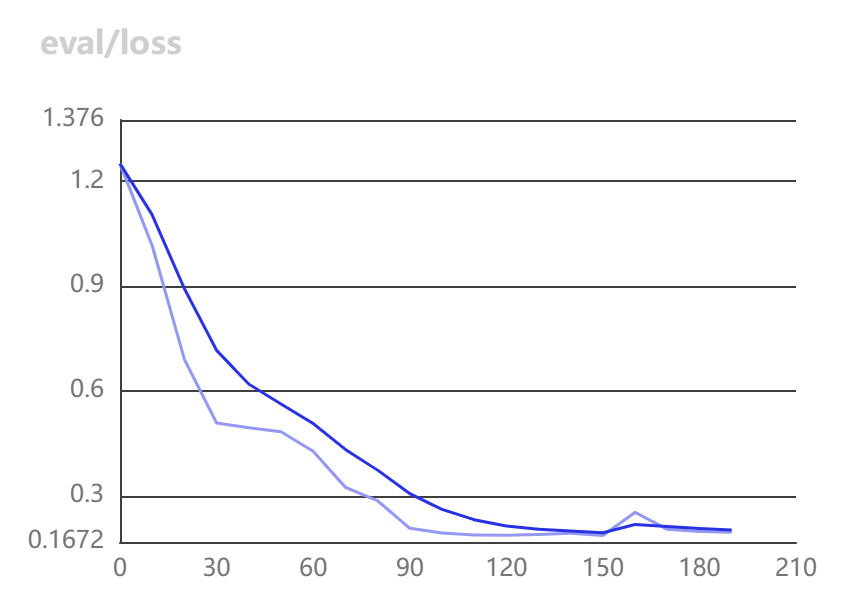
训练过程中的Loss呈阶梯状下降,这是由于采用了CosineAnnealingWarmRestarts优化器的原因
推理测试
使用下述代码进行推理
import paddle
import cv2
import numpy as np
from core.model import UNet
model = paddle.Model(UNet())
model.load('model/final')
model.prepare()
image = cv2.imread('Pixel_SkelNet/train/im/apple-1.png')
image = cv2.resize(image, (256, 256))
image = (image[:,:,0])
image = image / 255.
image = np.expand_dims(image, axis=0)
image = image.astype("float32")
data = paddle.to_tensor([[image]])
sigmoid = paddle.nn.Sigmoid()
result = model.predict(data)
result = paddle.to_tensor(result[0])
result = sigmoid(result)
threshold = 0.4
pred = result[0]
pred[pred >= threshold] = 255
pred[pred < threshold] = 0
cv2.imwrite('test.png', np.array(pred))
!python test.py
推理结果:
左图为原图,中间为真值,右侧为推理结果



发展前景:
本项目可以用于矢量图形的识别和提取,可以实现像素宽度为1的形状识别。














 255
255











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









