






 本文介绍了如何使用无监督学习,特别是变分自编码器(VAE),从噪声中提取由偏微分方程(PDE)控制的系统的可解释物理参数。通过训练和测试,模型能够从时空数据中准确识别相关参数,并构建系统的可转移模型。这种方法适用于处理有未知和不受控制变量的真实世界数据集。
本文介绍了如何使用无监督学习,特别是变分自编码器(VAE),从噪声中提取由偏微分方程(PDE)控制的系统的可解释物理参数。通过训练和测试,模型能够从时空数据中准确识别相关参数,并构建系统的可转移模型。这种方法适用于处理有未知和不受控制变量的真实世界数据集。
★★★ 本文源自AlStudio社区精品项目,【点击此处】查看更多精品内容 >>>
【论文复现】无监督学习——使用VAE提取PDE控制的系统中的可解释的物理参数
Extracting Interpretable Physical Parameters from Spatiotemporal Systems using Unsupervised Learning
一、任务解读
引言:实验数据经常受到不受控制的变量的影响,这使得分析和解释变得困难。对于时空系统,其复杂的动力学进一步加剧了这一问题。现代机器学习方法特别适合于分析和建模复杂的数据集,但要在科学上有效,结果需要是可解释的。本篇文章演示了一种无监督学习技术,用于从有噪声的时空数据中提取可解释的物理参数,并构建系统的可转移模型。特别是实现了基于变分自动编码器的物理嵌入神经网络架构,该架构设计用于分析由偏微分方程(PDE)控制的系统。该体系结构被端到端训练,并提取潜在参数,这些参数将系统的学习预测模型的动态参数化。
为了测试该方法的效果,在来自各种PDE的模拟数据上训练模型,这些PDE具有作为不受控变量的变化的动态参数。数值实验表明,该方法可以准确地识别相关参数,并从原始甚至有噪声的时空数据中提取它们(用大约10%的附加噪声进行测试)。这些提取的参数与用于生成数据集的地面真实物理参数有很好的相关性(线性度
R
2
>
0.95
R^2>0.95
R2>0.95)。时空系统中可解释的潜在参数的方法将能够更好地分析和理解真实世界的现象和数据集,这些现象和数据往往具有未知和不受控制的变量,这些变量会改变系统动力学,并导致难以分辨的变化行为。
二、数据集和数据获取
本文中的数据是由PDE产生的时间序列数据,数据结构一对为时间序列
(
{
x
t
}
t
=
0
T
x
,
{
y
t
}
t
=
0
T
y
)
(\{x_t\}_{t=0}^{T_x}, \{y_t\}_{t=0}^{T_y})
({xt}t=0Tx,{yt}t=0Ty),其中
{
x
t
}
t
=
0
T
x
\{x_t\}_{t=0}^{T_x}
{xt}t=0Tx为编码器的输入序列,
{
y
t
}
t
=
0
T
y
\{y_t\}_{t=0}^{T_y}
{yt}t=0Ty为提供初始条件的目标序列。本文中共使用两个一维和一个二维PDE产生的时间序列,分别是:
(1)1D-Kurmoto–Sivashinsky equation
∂
u
∂
t
=
−
γ
∂
x
4
u
−
∂
x
2
u
−
u
∂
x
u
\frac{\partial u}{\partial t}=-\gamma \partial_x^4u-\partial_x^2u-u\partial_xu
∂t∂u=−γ∂x4u−∂x2u−u∂xu
其中
γ
\gamma
γ是粘度阻尼参数;数据集可由运行下方代码或者**脚本(推荐)**获取
#!/usr/bin/env python
"""
generate_KS.py
Script for generating the 1D Kuramoto-Sivashinsky dataset.
"""
import os
import numpy as np
from scipy.fftpack import fft, ifft
from scipy.stats import truncnorm
from scipy.signal import resample
from joblib import Parallel, delayed
import multiprocessing
import warnings
import argparse
def generateData(i, data_size, batch_size, l, out_mesh, tmax, out_tmesh, shift, numean, nustd):
### Generate data
### Uses ETDRK4 method for integrating stiff PDEs
### https://epubs.siam.org/doi/pdf/10.1137/S1064827502410633
# np.random.seed()
# print(np.random.rand())
print('Batch ' + str(i+1) + ' of ' + str(int(data_size/batch_size)))
nu = truncnorm.rvs((0.5 - numean) / nustd, (1.5 - numean) / nustd,
loc=numean, scale=nustd, size=(batch_size, 1),
random_state=np.random.RandomState())
print(nu)
lamb = 1.0
pool = max(int(10 * l/(out_mesh * np.amin(nu))), 1)
print('Pooling: ' + str(pool))
tpool = 2 * pool
mesh = out_mesh * pool
tmesh = out_tmesh * tpool
dt = tmax/tmesh # time step
k = 2*np.pi * np.fft.fftfreq(mesh, d=l/mesh)
## initial condition
krange = ((out_mesh/8)*np.pi/l - 4 * np.pi/l) * np.random.rand(batch_size, 1) + 4 * np.pi/l
envelope = np.exp(-1/(2*krange**2) * k**2)
v0 = envelope * (np.random.normal(loc=0, scale=1.0, size=(batch_size, mesh))
+ 1j*np.random.normal(loc=0, scale=1.0, size=(batch_size, mesh)))
u0 = np.real(ifft(v0))
u0 = np.sqrt(mesh) * u0/np.expand_dims(np.linalg.norm(u0, axis=-1), axis=-1) # normalize
v0 = fft(u0)
## differential equation
L = lamb * k**2 - nu * k**4
N = lambda v: -0.5j * k * fft(np.real(ifft(v))**2)
## ETDRK4 method
E = np.exp(dt * L)
E2 = np.exp(dt * L / 2.0)
contour_radius = 1
M = 16
r = contour_radius*np.exp(1j * np.pi * (np.arange(1, M + 1) - 0.5) / M)
r = r.reshape(1, -1)
r_contour = np.repeat(r, mesh, axis=0)
LR = dt * L
LR = np.expand_dims(LR, axis=-1)
LR = np.repeat(LR, M, axis=-1)
LR = LR + r_contour
Q = dt*np.real(np.mean( (np.exp(LR/2.0)-1)/LR, axis=-1 ))
f1 = dt*np.real(np.mean( (-4.0-LR + np.exp(LR)*(4.0-3.0*LR+LR**2))/LR**3, axis=-1 ))
f2 = dt*np.real(np.mean( (2.0+LR + np.exp(LR)*(-2.0 + LR))/LR**3, axis=-1 ))
f3 = dt*np.real(np.mean( (-4.0-3.0*LR - LR**2 + np.exp(LR)*(4.0 - LR))/LR**3, axis=-1 ))
t = 0.0
u = []
v = v0
tpool_num = 0
# catch overflow warnings and rerun the data generation
with warnings.catch_warnings(record=True) as w:
warnings.simplefilter(action='ignore', category=FutureWarning)
while t < tmax + dt + shift:
if t >= shift and len(u) < out_tmesh and tpool_num % tpool == 0: # exclude first 'shift' time
u.append(resample(np.real(ifft(v)), out_mesh, axis=-1))
Nv = N(v)
a = E2 * v + Q * Nv
Na = N(a)
b = E2 * v + Q * Na
Nb = N(b)
c = E2 * a + Q * (2.0*Nb - Nv)
Nc = N(c)
v = E*v + Nv*f1 + 2.0*(Na + Nb)*f2 + Nc*f3
t = t + dt
tpool_num += 1
if w:
print('Rerunning...')
return generateData(i, data_size, batch_size, l, out_mesh, tmax, out_tmesh, shift, numean, nustd)
assert len(u) == out_tmesh
return np.expand_dims(np.stack(u, axis=-2), axis=1).astype(np.float32), nu.astype(np.float32)
if __name__ == "__main__":
parser = argparse.ArgumentParser(description="Generate Kuramoto-Sivashinsky dataset.")
parser.add_argument('-d', '--datasize', type=int, default=5000,
help="Size of generated dataset--should be a multiple of batch_size. Default: 5000")
parser.add_argument('-b', '--batchsize', type=int, default=1,
help="Batch size for generating dataset in parallel--should divide data_size. Default: 1")
parser.add_argument('-f', '--filename', type=str, default='KS_dataset_size5000.npz',
help="Path with file name ending in .npz where dataset is saved. Default: KS_dataset.npz")
args = parser.parse_args()
data_size = args.datasize
batch_size = args.batchsize
FILENAME = args.filename
l = 64*np.pi # system size
out_mesh = 256 # mesh
tmax = 32*np.pi # max time
out_tmesh = 256 # time mesh
shift = 0 * tmax/out_mesh # shift time to exclude initial conditions, set to 0 to keep t = 0
numean = 1.0
nustd = 0.125
num_cores = multiprocessing.cpu_count()
print('Using ' + str(num_cores) + ' cores...')
out_list = Parallel(n_jobs=num_cores)(delayed(generateData)
(i, data_size, batch_size, l, out_mesh, tmax, out_tmesh, shift, numean, nustd)
for i in range(int(data_size/batch_size)))
u_list, nu_list = [[data[i] for data in out_list] for i in range(2)]
u_list = np.concatenate(u_list)
nu_list = np.concatenate(nu_list)
## shape of u_list = (data_size, 1, out_tmesh, out_mesh)
print(u_list.shape)
print(u_list.dtype)
## shape of nu_list = (data_size, 1)
print(nu_list.shape)
print(nu_list.dtype)
print('Exporting to: ' + FILENAME)
np.savez(FILENAME, x=u_list, params=np.stack([nu_list.flatten()], axis=1))
# 获取1D Kuramoto-Sivashinsky dataset的脚本
# 1D Kuramoto-Sivashinsky dataset
!python VAE/data/generate_KS.py
!mv KS_dataset_size5000.npz VAE/data
(2)1D-nonlinear Schrödinger equation
i
∂
ψ
∂
t
=
−
1
2
∂
x
2
ψ
+
κ
∣
ψ
∣
2
ψ
i\frac{\partial \psi}{\partial t}=-\frac{1}{2}\partial_x^2\psi+\kappa|\psi|^2\psi
i∂t∂ψ=−21∂x2ψ+κ∣ψ∣2ψ
其中
κ
\kappa
κ是能量系数;数据集可由运行下方代码或者**脚本(推荐)**获取
#!/usr/bin/env python
"""
generate_NLSE.py
Script for generating the 1D nonlinear Schrödinger dataset.
"""
import os
import numpy as np
from scipy.fftpack import fft, ifft
from scipy.stats import truncnorm
from scipy.signal import resample
from joblib import Parallel, delayed
import multiprocessing
import warnings
import argparse
def generateData(i, data_size, batch_size, l, out_mesh, tmax, out_tmesh, shift, kappa_mean, kappa_std):
### Generate data
### Uses ETDRK4 method for integrating stiff PDEs
### https://epubs.siam.org/doi/pdf/10.1137/S1064827502410633
# np.random.seed()
# print(np.random.rand())
print('Batch ' + str(i+1) + ' of ' + str(int(data_size/batch_size)))
kappa = truncnorm.rvs((-2 - kappa_mean) / kappa_std, (0 - kappa_mean) / kappa_std,
loc=kappa_mean, scale=kappa_std, size=(batch_size, 1),
random_state=np.random.RandomState())
pool = 10
print('Pooling: ' + str(pool))
tpool = 20
mesh = out_mesh * pool
tmesh = out_tmesh * tpool
dt = tmax/tmesh # time step
k = 2*np.pi * np.fft.fftfreq(mesh, d=l/mesh)
## initial condition
krange = ((out_mesh/8)*np.pi/l - 4 * np.pi/l) * np.random.rand(batch_size, 1) + 4 * np.pi/l
envelope = np.exp(-1/(2*krange**2) * k**2)
v0 = envelope * (np.random.normal(loc=0, scale=1.0, size=(batch_size, mesh))
+ 1j*np.random.normal(loc=0, scale=1.0, size=(batch_size, mesh)))
u0 = ifft(v0)
u0 = np.sqrt(2 * mesh) * u0/np.expand_dims(np.linalg.norm(u0, axis=-1), axis=-1) # normalize
v0 = fft(u0)
## differential equation
L = -0.5j * k**2
def N(v):
u = ifft(v)
return -1j * kappa * fft(np.abs(u)**2 * u)
## ETDRK4 method
E = np.exp(dt * L)
E2 = np.exp(dt * L / 2.0)
contour_radius = 1
M = 32
r = contour_radius*np.exp(2j * np.pi * (np.arange(1, M + 1) - 0.5) / M)
r = r.reshape(1, -1)
r_contour = np.repeat(r, mesh, axis=0)
LR = dt * L
LR = np.expand_dims(LR, axis=-1)
LR = np.repeat(LR, M, axis=-1)
LR = LR + r_contour
Q = dt*np.mean( (np.exp(LR/2.0)-1)/LR, axis=-1 )
f1 = dt*np.mean( (-4.0-LR + np.exp(LR)*(4.0-3.0*LR+LR**2))/LR**3, axis=-1 )
f2 = dt*np.mean( (2.0+LR + np.exp(LR)*(-2.0 + LR))/LR**3, axis=-1 )
f3 = dt*np.mean( (-4.0-3.0*LR - LR**2 + np.exp(LR)*(4.0 - LR))/LR**3, axis=-1 )
t = 0.0
u = []
v = v0
tpool_num = 0
# catch overflow warnings and rerun the data generation
with warnings.catch_warnings(record=True) as w:
warnings.simplefilter(action='ignore', category=FutureWarning)
while t < tmax + shift - 1e-8:
if t >= shift and tpool_num % tpool == 0: # exclude first 'shift' time
up = resample(ifft(v), out_mesh, axis=-1)
u.append(np.stack([np.real(up), np.imag(up)], axis=-2))
Nv = N(v)
a = E2 * v + Q * Nv
Na = N(a)
b = E2 * v + Q * Na
Nb = N(b)
c = E2 * a + Q * (2.0*Nb - Nv)
Nc = N(c)
v = E*v + Nv*f1 + 2.0*(Na + Nb)*f2 + Nc*f3
t = t + dt
tpool_num += 1
if w:
print('Rerunning...')
print(w[-1])
return generateData(i, data_size, batch_size, l, out_mesh, tmax, out_tmesh, shift, kappa_mean, kappa_std)
return np.stack(u, axis=-2).astype(np.float32), kappa.astype(np.float32)
if __name__ == "__main__":
parser = argparse.ArgumentParser(description="Generate nonlinear Schrödinger dataset.")
parser.add_argument('-d', '--datasize', type=int, default=5000,
help="Size of generated dataset--should be a multiple of batch_size. Default: 5000")
parser.add_argument('-b', '--batchsize', type=int, default=50,
help="Batch size for generating dataset in parallel--should divide data_size. Default: 50")
parser.add_argument('-f', '--filename', type=str, default='NLSE_dataset_size5000.npz',
help="Path with file name ending in .npz where dataset is saved. Default: NLSE_dataset.npz")
args = parser.parse_args()
data_size = args.datasize
batch_size = args.batchsize
FILENAME = args.filename
l = 8*np.pi # system size
out_mesh = 256 # mesh
tmax = 1*np.pi # max time
out_tmesh = 256 # time mesh
shift = 0 # shift time to exclude initial conditions, set to 0 to keep t = 0
kappa_mean = -1
kappa_std = 0.25
num_cores = multiprocessing.cpu_count()
print('Using ' + str(num_cores) + ' cores...')
out_list = Parallel(n_jobs=num_cores)(delayed(generateData)
(i, data_size, batch_size, l, out_mesh, tmax, out_tmesh, shift, kappa_mean, kappa_std)
for i in range(int(data_size/batch_size)))
u_list, kappa_list = [[data[i] for data in out_list] for i in range(2)]
u_list = np.concatenate(u_list)
kappa_list = np.concatenate(kappa_list)
## shape of u_list = (data_size, data_channels, out_tmesh, out_mesh)
print(u_list.shape)
print(u_list.dtype)
## shape of kappa_list = (data_size, 1)
print(kappa_list.shape)
print(kappa_list.dtype)
print('Exporting to: ' + FILENAME)
np.savez(FILENAME, x=u_list, params=np.stack([kappa_list.flatten()], axis=1))
# 获取1D Nonlinear Schrödinger dataset的脚本
# 1D Nonlinear Schrödinger dataset
!python VAE/data/generate_NLSE.py
!mv NLSE_dataset_size5000.npz VAE/data
(3)2D convection–diffusion equation
∂
u
∂
t
=
D
∇
2
u
−
v
⋅
∇
u
\frac{\partial u}{\partial t}=D\nabla^2u-v\cdot \nabla u
∂t∂u=D∇2u−v⋅∇u
其中
D
D
D是常数,
v
v
v是速度场的相关对流项;数据集可由运行下方代码或者**脚本(推荐)**获取
#!/usr/bin/env python
"""
generate_CD.py
Script for generating the 2D convection-diffusion dataset.
"""
import os
import numpy as np
from scipy.fftpack import fft2, ifft2
from scipy.stats import truncnorm
import argparse
parser = argparse.ArgumentParser(description="Generate convection-diffusion dataset.")
parser.add_argument('-d', '--datasize', type=int, default=1000,
help="Size of generated dataset--should be a multiple of batch_size. Default: 1000")
parser.add_argument('-b', '--batchsize', type=int, default=50,
help="Batch size for generating dataset in parallel--should divide data_size. Default: 50")
parser.add_argument('-f', '--filename', type=str, default='CD_dataset_size1000.npz',
help="Path with file name ending in .npz where dataset is saved. Default: CD_dataset.npz")
args = parser.parse_args()
data_size = args.datasize
batch_size = args.batchsize
FILENAME = args.filename
l = 16*np.pi # system size
mesh = 256 # mesh
tmax = 4*np.pi # max time
tmesh = 64
dt = tmax/tmesh # time step
shift = 0 # shift time to exclude initial conditions, set to 0 to keep t = 0
dmean = 0.1 # diffusion constant
dstd = dmean/4
velstd = 0.5 # standard deviation of velocity
kx = np.expand_dims(2*np.pi * np.fft.fftfreq(mesh, d=l/mesh), axis=-1)
ky = np.expand_dims(2*np.pi * np.fft.fftfreq(mesh, d=l/mesh), axis=0)
# for use in 1st derivative
kx_1 = kx.copy()
kx_1[int(mesh/2)] = 0
ky_1 = ky.copy()
ky_1[:, int(mesh/2)] = 0
### Generate data
u_list = []
d_list = []
velx_list = []
vely_list = []
for i in range(int(data_size/batch_size)):
print('Batch ' + str(i+1) + ' of ' + str(int(data_size/batch_size)))
d = truncnorm.rvs((0 - dmean) / dstd, (2 * dmean - dmean) / dstd,
loc=dmean, scale=dstd, size=(batch_size, 1, 1, 1))
d_list.append(d.astype(np.float32))
velx = np.random.normal(loc=0, scale=velstd, size=(batch_size, 1, 1, 1))
vely = np.random.normal(loc=0, scale=velstd, size=(batch_size, 1, 1, 1))
velx_list.append(velx.astype(np.float32))
vely_list.append(vely.astype(np.float32))
## initial condition
krange = (0.25 * mesh*np.pi/l - 8 * np.pi/l) * np.random.rand(batch_size, 1, 1, 1) + 8 * np.pi/l
envelope = np.exp(-1/(2*krange**2) * (kx**2 + ky**2) )
v0 = envelope * (np.random.normal(loc=0, scale=1.0, size=(batch_size, 1, mesh, mesh))
+ 1j*np.random.normal(loc=0, scale=1.0, size=(batch_size, 1, mesh, mesh)))
u0 = np.real(ifft2(v0))
u0 = mesh * u0/np.linalg.norm(u0, axis=(-2,-1), keepdims=True) # normalize
v0 = fft2(u0)
## Differential equation
L = -d * (kx**2 + ky**2) - 1j * (kx_1 * velx + ky_1 * vely)
t = np.linspace(shift, tmax + shift, tmesh, endpoint=False)
v = np.exp(np.expand_dims(np.expand_dims(t, -1), -1) * L) * v0
u = np.real(ifft2(v))
u_list.append(np.expand_dims(u, axis=1).astype(np.float32))
u_list = np.concatenate(u_list)
d_list = np.concatenate(d_list)
velx_list = np.concatenate(velx_list)
vely_list = np.concatenate(vely_list)
## shape of u_list = (data_size, 1, tmesh, mesh, mesh)
print(u_list.shape)
print(u_list.dtype)
## shape of d_list = (data_size, 1, 1, 1)
print(d_list.shape)
print(d_list.dtype)
print('Exporting to: ' + FILENAME)
np.savez(FILENAME, x=u_list,
params=np.stack([d_list.flatten(), velx_list.flatten(), vely_list.flatten()], axis=1))
# 2D Convection-diffusion dataset
!python VAE/data/generate_CD.py
!mv CD_dataset_size1000.npz VAE/data
数据集加载的代码如下(以Numpy实现)
"""
npz_dataset.py
Dataset class (for PyTorch DataLoader) for data saved in *.npz or *.npy format.
If using a *.npz file, it must contain an array 'x' that stores all the data and
can contain an optional array 'params' of known parameters for comparison.
"""
import paddle
import numpy as np
class PDEDataset(paddle.io.Dataset):
"""PDE dataset with inputs x and targets also x."""
def __init__(self, data_file=None, transform=None, data_size=None):
"""
Args:
data_file (numpy save): file with all data
transform (callable, optional): Optional transform to be applied
on a sample.
"""
data = np.load(data_file)
if type(data) is np.ndarray:
self.data_x = data
self.params = None
elif 'x' in data.files:
self.data_x = data['x']
self.params = data['params'] if 'params' in data.files else None
else:
raise ValueError("Dataset import failed. NPZ files must include 'x' array containing data.")
self.transform = transform
def __len__(self):
return len(self.data_x)
def __getitem__(self, idx):
x = paddle.to_tensor(self.data_x[idx])
if self.params is None:
sample = [x, x, paddle.to_tensor(float('nan'))]
else:
sample = [x, x, paddle.to_tensor(self.params[idx])]
if self.transform:
sample = self.transform(sample)
return sample
三、模型介绍
使用无监督方法来提取模型关键参数,使用变分自编码器模型(VAE)作为本次实验的模型。VAE由编码器和解码器构成,往往用来提取关键参数信息并进行预测,是无监督学习方法的一个常用的方法。有关VAE的相关知识,可以去学习北京邮电大学鲁鹏老师的课程。
本次实验中,编码器用来提取关键参数(以正态分布的期望和方差形式给出),本次实验中编码器由卷积神经网络搭建;解码器利用编码器提取的参数(其网络的部分权重是由提取的参数所决定的)进行解码,来模拟给定初值条件和边界条件的系统。使用解码器的预测结果与实际结果构建损失函数,以达到解码器推动编码器提取有用参数的目的。
论文中VAE的动态编码器(dynamics encoder)是用空洞卷积(dilated conblution)实现的,输入经过一系列卷积后的结果分别经过两个并列的卷积层分别生成待提取参数均值和对数方差(VAE假定待提取参数服从标准正态分布);传递解码器(propagating decoder)是由动态卷积组成,其权重和偏置是由关键参数经过隐藏层生成的,与传统VAE不同本文中的解码器的输入不仅有提取出的关键参数,而且还有初值条件,解码器的输出为预测结果。整个模型的结果如下图所示
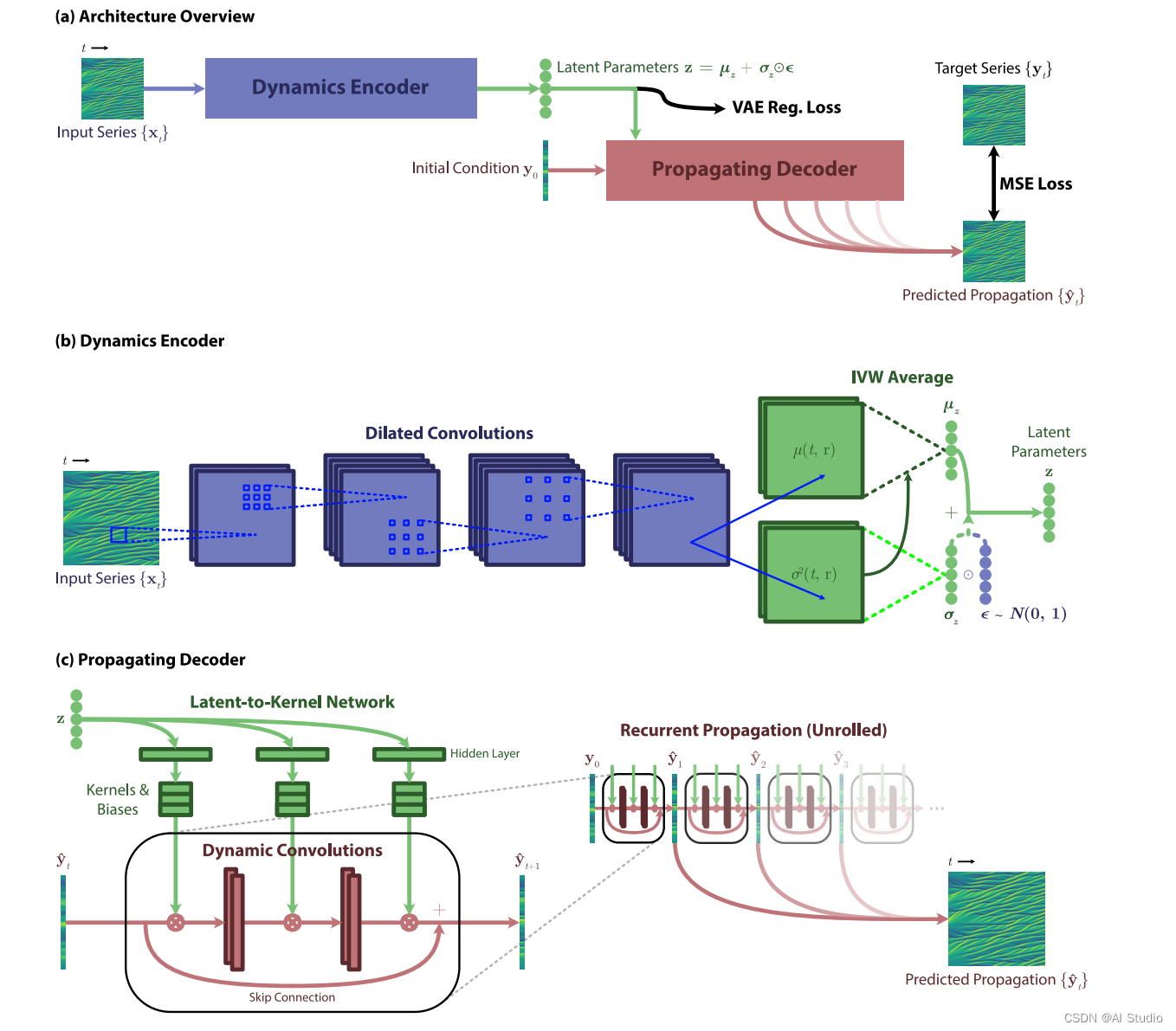
一维模型代码如下:
四、模型代码实现
经过上述讨论,已经对整个VAE有了基本的了解,以一维模型为例详细阐述模型的各个模块,具体实现细节由下面代码给出。
"""
pde1d.py
PDE VAE model (PDEAutoEncoder module) for fitting data with 1 spatial dimension.
"""
# 导入库
import collections
from itertools import repeat
import paddle
import paddle.nn as nn
import paddle.nn.functional as F
# pad模块
def _ntuple(n, name="parse"):
def parse(x):
if isinstance(x, collections.abc.Iterable):
return tuple(x)
return tuple(repeat(x, n))
parse.__name__ = name
return parse
_single = _ntuple(1, "_single")
class PeriodicPad1d(nn.Layer):
def __init__(self, pad, dim=-1):
super().__init__()
self.pad = pad
self.dim = dim
def forward(self, x):
if self.pad > 0:
front_padding = x.slice([self.dim], [x.shape[self.dim]-self.pad], [x.shape[self.dim]])
back_padding = x.slice([self.dim], [0], [self.pad])
x = paddle.concat([front_padding, x, back_padding], axis=self.dim)
return x
class AntiReflectionPad1d(nn.Layer):
def __init__(self, pad, dim=-1):
super().__init__()
self.pad = pad
self.dim = dim
def forward(self, x):
if self.pad > 0:
front_padding = -x.slice([self.dim], [0], [self.pad]).flip([self.dim])
back_padding = -x.slice([self.dim], [x.shape[self.dim]-self.pad], [x.shape[self.dim]]).flip([self.dim])
x = paddle.concat([front_padding, x, back_padding], axis=self.dim)
return x
动态卷积的实现代码如下所示,其难点在于torch.Tensor中的unfold方法paddle.Tensor没有对应,需要自己实现,下面的unfold函数是针对三维和四维张量实现的对应torch.Tensor.unfold算子
# 动态卷积实现
def unfold(x, axis=-2, kernel_size=3, strides=1):
# print(x.shape)
if len(x.shape) == 3:
N = None
C, H, W = x.shape
x = x.reshape([1, C, H, W])
else:
N, C, H, W = x.shape
kernel_size = [1, kernel_size] if axis==-1 else [kernel_size, 1]
if N is None:
x = F.unfold(x, kernel_sizes=kernel_size, strides=strides).squeeze_()
x = x.reshape([C, max(kernel_size), -1])
x = x.transpose([0, 2, 1])
x = x.reshape([C, (H-kernel_size[0])//strides+1, (W-kernel_size[1])//strides+1, max(kernel_size)])
else:
x = F.unfold(x, kernel_sizes=kernel_size, strides=strides)
x = x.reshape([N, C, max(kernel_size), -1])
x = x.transpose([0, 1, 3, 2])
x = x.reshape([N, C, (H-kernel_size[0])//strides+1, (W-kernel_size[1])//strides+1, max(kernel_size)])
return x
class DynamicConv1d(nn.Layer):
def __init__(self, in_channels, out_channels, kernel_size, stride=1,
padding=0, dilation=1, groups=1, boundary_cond='periodic'):
super().__init__()
self.kernel_size = _single(kernel_size) # x
# x
self.stride = _single(stride) # not implemented
self.padding = _single(padding)
self.dilation = _single(dilation) # not implemented
self.in_channels = in_channels
self.out_channels = out_channels
self.boundary_cond = boundary_cond
if self.padding[0] > 0 and boundary_cond == 'periodic':
assert self.padding[0] == int((self.kernel_size[0]-1)/2)
self.pad = PeriodicPad1d(self.padding[0], dim=-2)
else:
self.pad = None
def forward(self, input, weight, bias):
# x
# print(input.shape)
y = input.transpose([0, 2, 1])
if self.pad is not None:
output_size = input.shape[-1]
y = self.pad(y)
else:
output_size = input.shape[-1] - (self.kernel_size[0]-1)
# print(y.shape)
image_patches = unfold(y, axis=-2, kernel_size=self.kernel_size[0], strides=self.stride[0])
image_patches = image_patches.transpose([0, 1, 3, 2]) # x
y = paddle.matmul(image_patches.reshape([-1, output_size, self.in_channels * self.kernel_size[0]]),
weight.reshape([-1, self.in_channels * self.kernel_size[0], self.out_channels])
)
if bias is not None:
y = y + bias.reshape([-1, 1, self.out_channels])
return y.transpose([0, 2, 1])
# 解码器
class ConvPropagator(nn.Layer):
def __init__(self, hidden_channels, linear_kernel_size, nonlin_kernel_size, data_channels, stride=1,
linear_padding=0, nonlin_padding=0, dilation=1, groups=1, prop_layers=1, prop_noise=0., boundary_cond='periodic'):
self.data_channels = data_channels
self.prop_layers = prop_layers
self.prop_noise = prop_noise
self.boundary_cond = boundary_cond
assert nonlin_padding == int((nonlin_kernel_size-1)/2)
if boundary_cond == 'crop' or boundary_cond == 'dirichlet0':
self.padding = int((2+prop_layers)*nonlin_padding)
super(ConvPropagator, self).__init__()
self.conv_linear = DynamicConv1d(data_channels, data_channels, linear_kernel_size, stride,
linear_padding, dilation, groups, boundary_cond) if linear_kernel_size > 0 else None
self.conv_in = DynamicConv1d(data_channels, hidden_channels, nonlin_kernel_size, stride,
nonlin_padding, dilation, groups, boundary_cond)
self.conv_out = DynamicConv1d(hidden_channels, data_channels, nonlin_kernel_size, stride,
nonlin_padding, dilation, groups, boundary_cond)
if prop_layers > 0:
self.conv_prop = nn.LayerList([DynamicConv1d(hidden_channels, hidden_channels, nonlin_kernel_size, stride,
nonlin_padding, dilation, groups, boundary_cond)
for i in range(prop_layers)])
# self.cutoff = Parameter(torch.Tensor([1]))
cutoff = paddle.to_tensor([1.])
self.cutoff = paddle.create_parameter(shape=cutoff.shape,
dtype=str(cutoff.numpy().dtype),
default_initializer=paddle.nn.initializer.Assign(cutoff))
def _target_pad_1d(self, y, y0):
return paddle.concat([y0[:,:,:self.padding], y, y0[:,:,-self.padding:]], axis=-1)
def _antireflection_pad_1d(self, y, dim):
front_padding = -y.slice([dim], [0], [self.padding]).flip([dim])
back_padding = -y.slice([dim], [y.shape[dim]-self.padding], [y.shape[dim]]).flip([dim])
return paddle.concat([front_padding, y, back_padding], axis=dim)
def _f(self, y, linear_weight, linear_bias, in_weight, in_bias,
out_weight, out_bias, prop_weight, prop_bias):
y_lin = self.conv_linear(y, linear_weight, linear_bias) if self.conv_linear is not None else 0
y = self.conv_in(y, in_weight, in_bias)
y = F.relu(y)
for j in range(self.prop_layers):
y = self.conv_prop[j](y, prop_weight[:,j], prop_bias[:,j])
y = F.relu(y)
y = self.conv_out(y, out_weight, out_bias)
return y + y_lin
def forward(self, y0, linear_weight, linear_bias,
in_weight, in_bias, out_weight, out_bias, prop_weight, prop_bias, depth):
if self.boundary_cond == 'crop':
# requires entire target solution as y0 for padding purposes
assert len(y0.shape) == 4
assert y0.shape[1] == self.data_channels
assert y0.shape[2] == depth
y_pad = y0[:,:,0]
y = y0[:,:,0, self.padding:-self.padding]
elif self.boundary_cond == 'periodic' or self.boundary_cond == 'dirichlet0':
assert len(y0.shape) == 3
assert y0.shape[1] == self.data_channels
y = y0
else:
raise ValueError("Invalid boundary condition.")
f = lambda y: self._f(y, linear_weight, linear_bias, in_weight, in_bias,
out_weight, out_bias, prop_weight, prop_bias)
y_list = []
for i in range(depth):
if self.boundary_cond == 'crop':
if i > 0:
y_pad = self._target_pad_1d(y, y0[:,:,i])
elif self.boundary_cond == 'dirichlet0':
y_pad = self._antireflection_pad_1d(y, -1)
elif self.boundary_cond == 'periodic':
y_pad = y
### Euler integrator
dt = 1e-6 # NOT REAL TIME STEP, JUST HYPERPARAMETER
noise = self.prop_noise * paddle.randn(y.shape) if (self.training and self.prop_noise > 0) else 0 # x
y = y + self.cutoff * paddle.tanh((dt * f(y_pad)) / self.cutoff) + noise
y_list.append(y)
return paddle.stack(y_list, axis=-2)
# 模型总览
class PDEAutoEncoder(nn.Layer):
def __init__(self, param_size=1, data_channels=1, data_dimension=1, hidden_channels=16,
linear_kernel_size=0, nonlin_kernel_size=5, prop_layers=1, prop_noise=0.,
boundary_cond='periodic', param_dropout_prob=0.1, debug=False):
assert data_dimension == 1
super(PDEAutoEncoder, self).__init__()
self.param_size = param_size
self.data_channels = data_channels
self.hidden_channels = hidden_channels
self.linear_kernel_size = linear_kernel_size
self.nonlin_kernel_size = nonlin_kernel_size
self.prop_layers = prop_layers
self.boundary_cond = boundary_cond
self.param_dropout_prob = param_dropout_prob
self.debug = debug
if param_size > 0:
### 2D Convolutional Encoder
if boundary_cond =='crop' or boundary_cond == 'dirichlet0':
pad_input = [0, 0, 0, 0]
pad_func = PeriodicPad1d # can be anything since no padding is added
elif boundary_cond == 'periodic':
pad_input = [1, 2, 4, 8]
pad_func = PeriodicPad1d
else:
raise ValueError("Invalid boundary condition.")
self.encoder = nn.Sequential( pad_func(pad_input[0]),
nn.Conv2D(data_channels, 4, kernel_size=3, dilation=1),
nn.ReLU(),
pad_func(pad_input[1]),
nn.Conv2D(4, 16, kernel_size=3, dilation=2),
nn.ReLU(),
pad_func(pad_input[2]),
nn.Conv2D(16, 64, kernel_size=3, dilation=4),
nn.ReLU(),
pad_func(pad_input[3]),
nn.Conv2D(64, 64, kernel_size=3, dilation=8),
nn.ReLU(),
)
self.encoder_to_param = nn.Sequential(nn.Conv2D(64, param_size, kernel_size=1, stride=1))
self.encoder_to_logvar = nn.Sequential(nn.Conv2D(64, param_size, kernel_size=1, stride=1))
### Parameter to weight/bias for dynamic convolutions
if linear_kernel_size > 0:
self.param_to_linear_weight = nn.Sequential( nn.Linear(param_size, 4 * data_channels * data_channels),
nn.ReLU(),
nn.Linear(4 * data_channels * data_channels,
data_channels * data_channels * linear_kernel_size)
)
self.param_to_in_weight = nn.Sequential( nn.Linear(param_size, 4 * data_channels * hidden_channels),
nn.ReLU(),
nn.Linear(4 * data_channels * hidden_channels,
data_channels * hidden_channels * nonlin_kernel_size)
)
self.param_to_in_bias = nn.Sequential( nn.Linear(param_size, 4 * hidden_channels),
nn.ReLU(),
nn.Linear(4 * hidden_channels, hidden_channels)
)
self.param_to_out_weight = nn.Sequential( nn.Linear(param_size, 4 * data_channels * hidden_channels),
nn.ReLU(),
nn.Linear(4 * data_channels * hidden_channels,
data_channels * hidden_channels * nonlin_kernel_size)
)
self.param_to_out_bias = nn.Sequential( nn.Linear(param_size, 4 * data_channels),
nn.ReLU(),
nn.Linear(4 * data_channels, data_channels)
)
if prop_layers > 0:
self.param_to_prop_weight = nn.Sequential( nn.Linear(param_size, 4 * prop_layers * hidden_channels * hidden_channels),
nn.ReLU(),
nn.Linear(4 * prop_layers * hidden_channels * hidden_channels,
prop_layers * hidden_channels * hidden_channels * nonlin_kernel_size)
)
self.param_to_prop_bias = nn.Sequential( nn.Linear(param_size, 4 * prop_layers * hidden_channels),
nn.ReLU(),
nn.Linear(4 * prop_layers * hidden_channels, prop_layers * hidden_channels)
)
### Decoder/PDE simulator
self.decoder = ConvPropagator(hidden_channels, linear_kernel_size, nonlin_kernel_size, data_channels,
linear_padding=int((linear_kernel_size-1)/2),
nonlin_padding=int((nonlin_kernel_size-1)/2),
prop_layers=prop_layers, prop_noise=prop_noise, boundary_cond=boundary_cond)
def forward(self, x, y0, depth):
if self.param_size > 0:
assert len(x.shape) == 4
assert x.shape[1] == self.data_channels
### 2D Convolutional Encoder
encoder_out = self.encoder(x)
logvar = self.encoder_to_logvar(encoder_out)
logvar_size = logvar.shape
logvar = logvar.reshape([logvar_size[0], logvar_size[1], -1])
params = self.encoder_to_param(encoder_out).reshape([logvar_size[0], logvar_size[1], -1])
if self.debug:
raw_params = params
# Parameter Spatial Averaging Dropout
if self.training and self.param_dropout_prob > 0:
mask = paddle.bernoulli(paddle.full_like(logvar, self.param_dropout_prob))
mask[mask > 0] = float("inf")
logvar = logvar + mask
# Inverse variance weighted average of params
weights = F.softmax(-logvar, axis=-1)
params = (params * weights).sum(axis=-1)
# Compute logvar for inverse variance weighted average with a correlation length correction
correlation_length = 31 # estimated as receptive field of the convolutional encoder
logvar = -paddle.logsumexp(-logvar, axis=-1) \
+ paddle.log(paddle.to_tensor(
max(1, (1 - self.param_dropout_prob)
* min(correlation_length, logvar_size[-2])
* min(correlation_length, logvar_size[-1])),
dtype=logvar.dtype))
### Variational autoencoder reparameterization trick
if self.training:
stdv = (0.5 * logvar).exp()
# Sample from unit normal
z = params + stdv * paddle.randn(stdv.shape)
else:
z = params
### Parameter to weight/bias for dynamic convolutions
if self.linear_kernel_size > 0:
linear_weight = self.param_to_linear_weight(z)
linear_bias = None
else:
linear_weight = None
linear_bias = None
in_weight = self.param_to_in_weight(z)
in_bias = self.param_to_in_bias(z)
out_weight = self.param_to_out_weight(z)
out_bias = self.param_to_out_bias(z)
if self.prop_layers > 0:
prop_weight = self.param_to_prop_weight(z).reshape([-1, self.prop_layers,
self.hidden_channels * self.hidden_channels * self.nonlin_kernel_size])
prop_bias = self.param_to_prop_bias(z).reshape([-1, self.prop_layers, self.hidden_channels])
else:
prop_weight = None
prop_bias = None
else: # if no parameter used
linear_weight = None
linear_bias = None
in_weight = None
in_bias = None
out_weight = None
out_bias = None
prop_weight = None
prop_bias = None
params = None
logvar = None
### Decoder/PDE simulator
y = self.decoder(y0, linear_weight, linear_bias, in_weight, in_bias, out_weight, out_bias,
prop_weight, prop_bias, depth)
if self.debug:
return y, params, logvar, [in_weight, in_bias, out_weight, out_bias, prop_weight, prop_bias], \
weights.reshape([logvar_size]), raw_params.reshape([logvar_size])
return y, params, logvar
五、训练和测试
训练和测试的代码如下,实际操作中仍然推荐使用下方脚本对每个数据集分别进行训练和测试。
import os
import sys
from shutil import copy2
import json
from types import SimpleNamespace
import warnings
import numpy as np
import paddle
import paddle.nn as nn
import paddle.nn.functional as F
def setup(in_file):
# Load configuration from json
with open(in_file) as f:
s = json.load(f, object_hook=lambda d: SimpleNamespace(**d))
# Some defaults
if not hasattr(s, 'train'):
raise NameError("'train' must be set to True for training or False for evaluation.")
elif s.train == False and not hasattr(s, 'MODELLOAD'):
raise NameError("'MODELLOAD' file name required for evaluation.")
if not hasattr(s, 'restart'):
s.restart = not s.train
warnings.warn("Automatically setting 'restart' to " + str(s.restart))
if s.restart and not hasattr(s, 'MODELLOAD'):
raise NameError("'MODELLOAD' file name required for restart.")
if not hasattr(s, 'freeze_encoder'):
s.freeze_encoder = False
elif s.freeze_encoder and not s.restart:
raise ValueError("Freeezing encoder weights requires 'restart' set to True with encoder weights loaded from file.")
if not hasattr(s, 'data_parallel'):
s.data_parallel = False
if not hasattr(s, 'debug'):
s.debug = False
if not hasattr(s, 'discount_rate'):
s.discount_rate = 0.
if not hasattr(s, 'rate_decay'):
s.rate_decay = 0.
if not hasattr(s, 'param_dropout_prob'):
s.param_dropout_prob = 0.
if not hasattr(s, 'prop_noise'):
s.prop_noise = 0.
if not hasattr(s, 'boundary_cond'):
raise NameError("Boundary conditions 'boundary_cond' not set. Options include: 'crop', 'periodic', 'dirichlet0'")
elif s.boundary_cond == 'crop' and (not hasattr(s, 'input_size') or not hasattr(s, 'training_size')):
raise NameError("'input_size' or 'training_size' not set for crop boundary conditions.")
# Create output folder
if not os.path.exists(s.OUTFOLDER):
print("Creating output folder: " + s.OUTFOLDER)
os.makedirs(s.OUTFOLDER)
elif s.train and len(os.listdir(s.OUTFOLDER))>3:
raise FileExistsError("Output folder " + s.OUTFOLDER + " is not empty.")
# Make a copy of the configuration file in the output folder
copy2(in_file, s.OUTFOLDER)
# Print configuration
print(s)
# Import class for dataset type
dataset = __import__(s.dataset_type, globals(), locals(), ['PDEDataset'])
s.PDEDataset = dataset.PDEDataset
# Import selected model from models as PDEModel
models = __import__('models.' + s.model, globals(), locals(), ['PDEAutoEncoder'])
PDEModel = models.PDEAutoEncoder
# Initialize model
model = PDEModel(param_size=s.param_size, data_channels=s.data_channels, data_dimension=s.data_dimension,
hidden_channels=s.hidden_channels, linear_kernel_size=s.linear_kernel_size,
nonlin_kernel_size=s.nonlin_kernel_size, prop_layers=s.prop_layers, prop_noise=s.prop_noise,
boundary_cond=s.boundary_cond, param_dropout_prob=s.param_dropout_prob, debug=s.debug)
# Set CUDA device
paddle.set_device('gpu')
# s.use_cuda = torch.cuda.is_available()
# if s.use_cuda:
# paddle.set_device('gpu')
# else:
# warnings.warn("Warning: Using CPU only. This is untested.")
print("\nModel parameters:")
for name, param in model.named_parameters():
if not param.stop_gradient:
print("\t{:<40}{}".format(name + ":", param.shape))
return model, s
def _periodic_pad_1d(x, dim, pad):
back_padding = x.slice([dim], [0], [pad])
return paddle.concat([x, back_padding], axis=dim)
def _random_crop_1d(sample, depth, crop_size):
sample_size = sample[0].shape
crop_t = [np.random.randint(sample_size[-2]-depth[0]+1), np.random.randint(sample_size[-2]-depth[1]+1)]
crop_x = [np.random.randint(sample_size[-1]), np.random.randint(sample_size[-1])]
if crop_size[0] > 1:
sample[0] = _periodic_pad_1d(sample[0], -1, crop_size[0]-1)
if crop_size[1] > 1:
sample[1] = _periodic_pad_1d(sample[1], -1, crop_size[1]-1)
if len(sample_size) == 3:
sample[0] = sample[0][:, crop_t[0]:(crop_t[0]+depth[0]), crop_x[0]:(crop_x[0]+crop_size[0])]
sample[1] = sample[1][:, crop_t[1]:(crop_t[1]+depth[1]), crop_x[1]:(crop_x[1]+crop_size[1])]
elif len(sample_size) == 2:
sample[0] = sample[0][crop_t[0]:(crop_t[0]+depth[0]), crop_x[0]:(crop_x[0]+crop_size[0])]
sample[1] = sample[1][crop_t[1]:(crop_t[1]+depth[1]), crop_x[1]:(crop_x[1]+crop_size[1])]
else:
raise ValueError('Sample is the wrong shape.')
return sample
def _random_crop_2d(sample, depth, crop_size):
sample_size = sample[0].shape
crop_t = [np.random.randint(sample_size[-3]-depth[0]+1), np.random.randint(sample_size[-3]-depth[1]+1)]
crop_x = [np.random.randint(sample_size[-2]), np.random.randint(sample_size[-2])]
crop_y = [np.random.randint(sample_size[-1]), np.random.randint(sample_size[-1])]
if crop_size[0] > 1:
sample[0] = _periodic_pad_1d(_periodic_pad_1d(sample[0], -1, crop_size[0]-1), -2, crop_size[0]-1)
if crop_size[1] > 1:
sample[1] = _periodic_pad_1d(_periodic_pad_1d(sample[1], -1, crop_size[1]-1), -2, crop_size[1]-1)
if len(sample_size) == 4:
sample[0] = sample[0][:, crop_t[0]:(crop_t[0]+depth[0]), crop_x[0]:(crop_x[0]+crop_size[0]), crop_y[0]:(crop_y[0]+crop_size[0])]
sample[1] = sample[1][:, crop_t[1]:(crop_t[1]+depth[1]), crop_x[1]:(crop_x[1]+crop_size[1]), crop_y[1]:(crop_y[1]+crop_size[1])]
elif len(sample_size) == 3:
sample[0] = sample[0][crop_t[0]:(crop_t[0]+depth[0]), crop_x[0]:(crop_x[0]+crop_size[0]), crop_y[0]:(crop_y[0]+crop_size[0])]
sample[1] = sample[1][crop_t[1]:(crop_t[1]+depth[1]), crop_x[1]:(crop_x[1]+crop_size[1]), crop_y[1]:(crop_y[1]+crop_size[1])]
else:
raise ValueError('Sample is the wrong shape.')
return sample
def train(model, s):
### Train model on training set
print("\nTraining...")
if s.restart: # load model to restart training
print("Loading model from: " + s.MODELLOAD)
strict_load = not s.freeze_encoder
if s.use_cuda:
state_dict = paddle.load(s.MODELLOAD)
else:
state_dict = paddle.load(s.MODELLOAD)
model.load_state_dict(state_dict)
if s.freeze_encoder: # freeze encoder weights
print("Freezing weights:")
for name, param in model.encoder.named_parameters():
param.stop_gradient = True
print("\t{:<40}{}".format("encoder." + name + ":", param.shape))
for name, param in model.encoder_to_param.named_parameters():
param.stop_gradient = True
print("\t{:<40}{}".format("encoder_to_param." + name + ":", param.shape))
for name, param in model.encoder_to_logvar.named_parameters():
param.stop_gradient = True
print("\t{:<40}{}".format("encoder_to_logvar." + name + ":", param.shape))
# if s.data_parallel:
# model = nn.DataParallel(model, device_ids=s.cuda_device)
if s.boundary_cond == 'crop':
if s.data_dimension == 1:
transform = lambda x: _random_crop_1d(x, (s.input_depth, s.training_depth+1), (s.input_size, s.training_size))
elif s.data_dimension == 2:
transform = lambda x: _random_crop_2d(x, (s.input_depth, s.training_depth+1), (s.input_size, s.training_size))
pad = int((2+s.prop_layers)*(s.nonlin_kernel_size-1)/2) #for cropping targets
elif s.boundary_cond == 'periodic' or s.boundary_cond == 'dirichlet0':
transform = None
else:
raise ValueError("Invalid boundary condition.")
train_loader = paddle.io.DataLoader(
s.PDEDataset(data_file=s.DATAFILE, transform=transform),
batch_size=s.batch_size, shuffle=True, num_workers=s.num_workers,
worker_init_fn=lambda _: np.random.seed())
optimizer = paddle.optimizer.Adam(learning_rate=s.learning_rate, parameters=model.parameters(), epsilon=s.eps)
model.train()
# writer = SummaryWriter(log_dir=os.path.join(s.OUTFOLDER, 'data'))
# Initialize training variables
loss_list = []
recon_loss_list = []
mse_list = []
acc_loss = 0
acc_recon_loss = 0
acc_latent_loss = 0
acc_mse = 0
best_mse = None
step = 0
current_discount_rate = s.discount_rate
### Training loop
for epoch in range(1, s.max_epochs+1):
print('\nEpoch: ' + str(epoch))
# Introduce a discount rate to favor predicting better in the near future
current_discount_rate = s.discount_rate * np.exp(-s.rate_decay * (epoch-1)) # discount rate decay every epoch
print('discount rate = ' + str(current_discount_rate))
if current_discount_rate > 0:
w = paddle.to_tensor(np.exp(-current_discount_rate * np.arange(s.training_depth)).reshape(
[s.training_depth] + s.data_dimension * [1]), dtype=paddle.float32)
w = w * s.training_depth/w.sum(axis=0, keepdim=True)
else:
w = None
# Load batch and train
for data, target, data_params in train_loader:
step += 1
# if s.use_cuda:
# data, target = data.cuda(non_blocking=True), target.cuda(non_blocking=True)
data = data[:,:,:s.input_depth]
if s.boundary_cond == 'crop':
target0 = target[:,:,:s.training_depth]
if s.data_dimension == 1:
target = target[:,:,1:s.training_depth+1, pad:-pad]
elif s.data_dimension == 2:
target = target[:,:,1:s.training_depth+1, pad:-pad, pad:-pad]
elif s.boundary_cond == 'periodic' or s.boundary_cond == 'dirichlet0':
target0 = target[:,:,0]
target = target[:,:,1:s.training_depth+1]
else:
raise ValueError("Invalid boundary condition.")
# Run model
output, params, logvar = model(data, target0, depth=s.training_depth)
# Reset gradients
optimizer.clear_grad()
# Calculate loss
if s.data_parallel:
output = output.cpu()
recon_loss = F.mse_loss(output * w, target * w) if w is not None else F.mse_loss(output, target)
if s.param_size > 0:
latent_loss = s.beta * 0.5 * paddle.mean(paddle.sum(params * params + logvar.exp() - logvar - 1, axis=-1))
else:
latent_loss = 0
loss = recon_loss + latent_loss
mse = F.mse_loss(output.detach(), target.detach()).item() if w is not None else recon_loss.item()
loss_list.append(loss.item())
recon_loss_list.append(recon_loss.item())
mse_list.append(mse)
acc_loss += loss.item()
acc_recon_loss += recon_loss.item()
acc_latent_loss += latent_loss.item()
acc_mse += mse
# Calculate gradients
loss.backward()
# Clip gradients
# grad_norm = nn.utils.clip_grad_norm_(model.parameters(), 1e0)
# Update gradients
optimizer.step()
# Output every 100 steps
if step % 100 == 0:
# Check every 500 steps and save checkpoint if new model is at least 2% better than previous best
if (step > 1 and step % 500 == 0) and ((best_mse is None) or (acc_mse/100 < 0.98*best_mse)):
best_mse = acc_mse/100
paddle.save(model.state_dict(), os.path.join(s.OUTFOLDER, "best.tar"))
print('New Best MSE at Step {}: {:.4f}'.format(step, best_mse))
# Output losses and weights
if s.param_size > 0:
if step > 1:
# Write losses to summary
# writer.add_scalars('losses', {'loss': acc_loss/100,
# 'recon_loss': acc_recon_loss/100,
# 'latent_loss': acc_latent_loss/100,
# 'mse': acc_mse/100}, step)
acc_loss = 0
acc_recon_loss = 0
acc_latent_loss = 0
acc_mse = 0
# Write mean model weights to summary
weight_dict = {}
for name, param in model.named_parameters():
if not param.stop_gradient:
weight_dict[name] = param.detach().abs().mean().item()
# writer.add_scalars('weight_avg', weight_dict, step)
print('Train Step: {}\tTotal Loss: {:.4f}\tRecon. Loss: {:.4f}\tRecon./Latent: {:.1f}\tMSE: {:.4f}'
.format(step, loss.item(), recon_loss.item(), recon_loss.item()/latent_loss.item(), mse))
# Save current set of extracted latent parameters
np.savez(os.path.join(s.OUTFOLDER, "training_params.npz"), data_params=data_params.numpy(),
params=params.detach().cpu().numpy())
else:
print('Train Step: {}\tTotal Loss: {:.4f}\tRecon. Loss: {:.4f}\tMSE: {:.4f}'
.format(step, loss.item(), recon_loss.item(), mse))
# Export checkpoints and loss history after every s.save_epochs epochs
if s.save_epochs > 0 and epoch % s.save_epochs == 0:
paddle.save(model.state_dict(), os.path.join(s.OUTFOLDER, "epoch{:06d}.tar".format(epoch)))
np.savez(os.path.join(s.OUTFOLDER, "loss.npz"), loss=np.array(loss_list),
recon_loss=np.array(recon_loss_list),
mse=np.array(mse_list))
return model
def evaluate(model, s, params_filename="params.npz", rmse_filename="rmse_with_depth.npy"):
### Evaluate model on test set
print("\nEvaluating...")
if rmse_filename is not None and os.path.exists(os.path.join(s.OUTFOLDER, rmse_filename)):
raise FileExistsError(rmse_filename + " already exists.")
if os.path.exists(os.path.join(s.OUTFOLDER, params_filename)):
raise FileExistsError(params_filename + " already exists.")
if not s.train:
print("Loading model from: " + s.MODELLOAD)
if s.use_cuda:
state_dict = paddle.load(s.MODELLOAD)
else:
state_dict = paddle.load(s.MODELLOAD)
model.set_state_dict(state_dict)
pad = int((2+s.prop_layers)*(s.nonlin_kernel_size-1)/2) #for cropping targets (if necessary)
# from npz_dataset import PDEDataset
# dataset = PDEDataset('data/CD_dataset_size1000.npz', transform=None)
# test_loader = paddle.io.DataLoader(dataset, batch_size=,num_workers=0)
test_loader = paddle.io.DataLoader(
s.PDEDataset(data_file=s.DATAFILE, transform=None),
batch_size=s.batch_size, num_workers=s.num_workers)
model.eval()
paddle.set_grad_enabled(False)
### Evaluation loop
loss = 0
if rmse_filename is not None:
rmse_with_depth = paddle.zeros([s.evaluation_depth])
params_list = []
logvar_list = []
data_params_list = []
step = 0
for data, target, data_params in test_loader:
step += 1
if s.use_cuda:
pass
# data, target = data.cuda(non_blocking=True), target.cuda(non_blocking=True)
if s.boundary_cond == 'crop':
target0 = target[:,:,:s.evaluation_depth]
if s.data_dimension == 1:
target = target[:,:,1:s.evaluation_depth+1, pad:-pad]
elif s.data_dimension == 2:
target = target[:,:,1:s.evaluation_depth+1, pad:-pad, pad:-pad]
elif s.boundary_cond == 'periodic' or s.boundary_cond == 'dirichlet0':
target0 = target[:,:,0]
target = target[:,:,1:s.evaluation_depth+1]
else:
raise ValueError("Invalid boundary condition.")
# Run model
if s.debug:
with paddle.no_grad():
output, params, logvar, _, weights, raw_params = model(data, target0, depth=s.evaluation_depth)
else:
with paddle.no_grad():
output, params, logvar = model(data, target0, depth=s.evaluation_depth)
data_params = data_params.numpy()
data_params_list.append(data_params)
if s.param_size > 0:
params = params.detach().numpy()
params_list.append(params)
logvar_list.append(logvar.detach().numpy())
assert output.shape[2] == s.evaluation_depth
loss += F.mse_loss(output, target).item()
if rmse_filename is not None:
rmse_with_depth += paddle.sqrt(paddle.mean((output - target).transpose([0, 2, 1, 3])
.reshape([target.shape[0], s.evaluation_depth, -1]) ** 2,
axis=-1)).mean(0)
rmse_with_depth = rmse_with_depth.numpy()/step
print('\nTest Set: Recon. Loss: {:.4f}'.format(loss/step))
if rmse_filename is not None:
np.save(os.path.join(s.OUTFOLDER, rmse_filename), rmse_with_depth)
np.savez(os.path.join(s.OUTFOLDER, params_filename), params=np.concatenate(params_list),
logvar=np.concatenate(logvar_list),
data_params=np.concatenate(data_params_list))
if __name__ == "__main__":
in_file = sys.argv[1]
if not os.path.exists(in_file):
raise FileNotFoundError("Input file " + in_file + " not found.")
model, s = setup(in_file)
if s.train:
model = train(model, s)
else:
evaluate(model, s)
(1)1D-Kurmoto–Sivashinsky方程产生的数据集训练和测试
%cd VAE
# 训练
!python run.py input_files/KS_train.json
#测试
!python run.py input_files/KS_test.json
(2)1D-nonlinear Schrödinger方程产生的数据集训练和测试
%cd VAE
# 训练
!python run.py input_files/NLSE_train.json
# 测试
!python run.py input_files/NLSE_test.json
(3)2D convection–diffusion方程产生的数据集训练和测试
%cd VAE
# 训练
!python run.py input_files/CD_train.json
# 测试
!python run.py input_files/CD_test.json
六、 结果分析与可视化
本文中VAE模型进行训练,会产生5个隐藏参数,这个隐藏参数并不一定都是我们想要的可解释的物理参数。可解释的物理参数应该具备如下特点:
(1)参数的均值的方差应该足够大;
(2)参数方差的均值应该足够小;
(1)表明获取的参数应该是可以随着输入不同而变化的;(2)表明参数对自己的取值有足够的信心,波动范围不会很大;反过来如果获取的参数均值的方差很小,而其方差的均值很大,这就像是对任意的输入,该参数都是取一个差不多的均值,然后用很大的波动范围糊弄过去,这显然是没有可解释的物理意义的。以非线性薛定谔方程数据集获得的各参数均值和方差为例,可视化的代码如下:
%cd VAE
import numpy as np
import matplotlib.pyplot as plt
data = np.load('results/NLSE_params.npz')
plt.style.use('seaborn-ticks')
params = data['params']
logvar = data['logvar']
y1 = np.var(params, axis=0)
y2 = np.mean(np.exp(logvar),axis=0)
x = np.arange(params.shape[1])
fig = plt.figure(dpi=120)
ax1 = fig.add_subplot(111)
ax1.bar(x, y1, color='b')
ax2 = ax1.twinx() # this is the important function
ax2.bar(x, -y2*10, color='r')
ax1.set_ylabel('var(μ)',color='b')
ax2.set_ylabel('Mean(σ2)', color='r')
ax1.set_ylim(-0.4,1)
ax2.set_ylim(-0.4,1)
ax2.set_xlabel('Latent Parameters')
ax1.set_yticklabels(['', '', '0.0','0.2', '0.4', '0.6', '0.8', '1.0'],color='b')
ax2.set_yticklabels(['0.04','0.02', '0.0', '', '','', '', '', '', ''],color='r')
plt.show()
[Errno 2] No such file or directory: 'VAE'
/home/aistudio/VAE
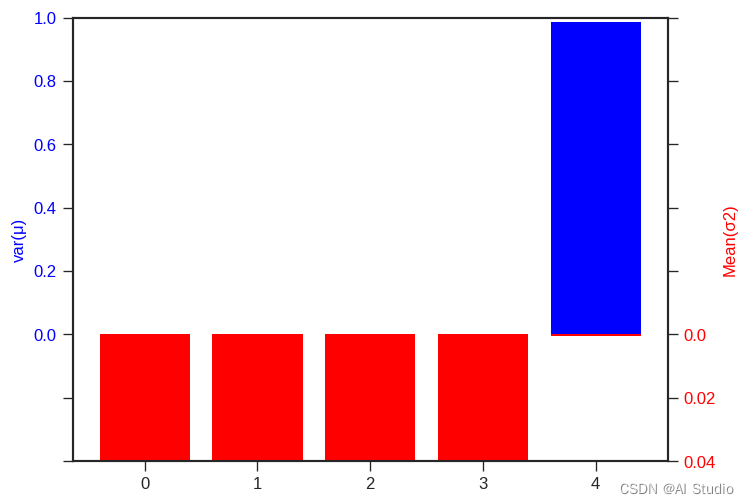
上图结果与原文对应的很好,可以解释的参数都是一个,其他方程获得的结果也可以对应的可视化出来,都可以和原文有着很好的对应。原文所有结果如下:
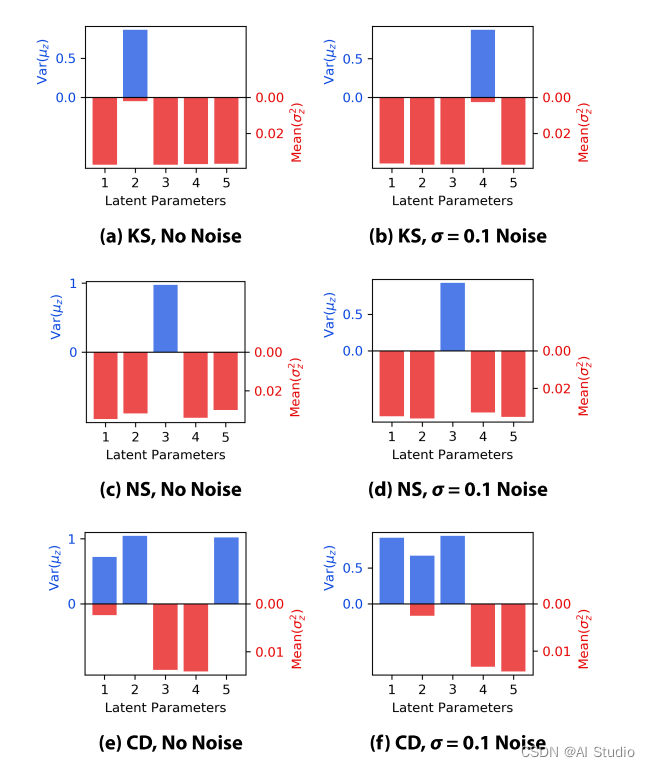
七、 致谢
感谢百度飞桨科学计算团队给予这次论文复现营的机会,感谢负责老师认真教导,感谢飞桨腹黑花花提供的算力卡。下次继续努力!

















 349
349

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









