







💡💡💡本文摘要:基于YOLOX的NEU-DET钢材表面缺陷检测任务,阐述了整个数据制作和训练可视化过程
博主简介
AI小怪兽,YOLO骨灰级玩家,1)YOLOv5、v7、v8、v9优化创新,轻松涨点和模型轻量化;2)目标检测、语义分割、OCR、分类等技术孵化,赋能智能制造,工业项目落地经验丰富;

原创自研系列, 2024年计算机视觉顶会创新点
23年最火系列,内涵80+优化改进篇,涨点小能手,助力科研,好评率极高
应用系列篇:
1.YOLOX介绍

论文:https://arxiv.org/pdf/2107.08430.pdf
摘要:
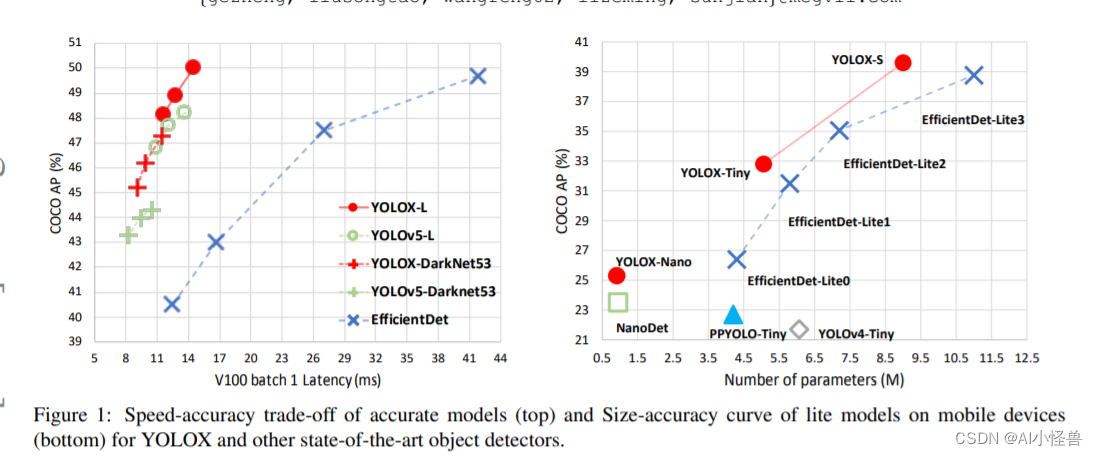
在本报告中,我们对YOLO系列进行了一些有经验的改进,形成了一种新的高性能检测器- YOLOX。我们将YOLO检测器转换为无锚点方式,并进行其他先进的检测技术,即解耦合头和领先的标签分配策略SimOTA,以在大尺度模型范围内获得最先进的结果:对于只有0.91M参数和1.08G FLOPs的YOLONano,我们在COCO上获得25.3%的AP,比NanoDet高出1.8%;对于工业中使用最广泛的探测器之一YOLOv3,我们将其在COCO上的AP提高到47.3%,比目前的最佳实践高出3.0% AP;对于参数数量与YOLOv4-CSP、yolov4 - l大致相同的YOLOX-L,我们在Tesla V100上以68.9 FPS的速度在COCO上实现了50.0%的AP,比YOLOv5-L高出1.8% AP。此外,我们使用单个YOLOX-L模型获得了流感知挑战赛(CVPR 2021自动驾驶研讨会)的第一名。我们希望这份报告能够为开发人员和研究人员在实际场景中提供有用的经验,同时我们也提供了ONNX、TensorRT、NCNN和Openvino的部署版本支持。
2.NEU-DET数据集介绍
NEU-DET钢材表面缺陷共有六大类,一共1800张,
类别分别为:'crazing','inclusion','patches','pitted_surface','rolled-in_scale','scratches'
3.YOLOX修改
修改1:修改标签类别
exps/example/yolox_voc/yolox_voc_s.py,将num_classes修改为标签类别数量,此处为6。
class Exp(MyExp):
def __init__(self):
super(Exp, self).__init__()
self.num_classes = 6
self.depth = 0.33
self.width = 0.50
self.warmup_epochs = 1修改2:修改yolox/data/datasets/voc_classes.py
#!/usr/bin/env python3
# -*- coding:utf-8 -*-
# Copyright (c) Megvii, Inc. and its affiliates.
# VOC_CLASSES = ( '__background__', # always index 0
VOC_CLASSES = (
"crazing",
"inclusion",
"patches",
"pitted_surface",
"rolled-in_scale",
"scratches",
)
修改3:修改数据集目录信息
修改exps/example/yolox_voc/yolox_voc_s.py中的VOCDection。
def get_dataset(self, cache: bool, cache_type: str = "ram"):
from yolox.data import VOCDetection, TrainTransform
return VOCDetection(
data_dir= "D:/YOLOX-main/data/NEU-DET",
image_sets=[('trainval')],
img_size=self.input_size,
preproc=TrainTransform(
max_labels=50,
flip_prob=self.flip_prob,
hsv_prob=self.hsv_prob),
cache=cache,
cache_type=cache_type,
)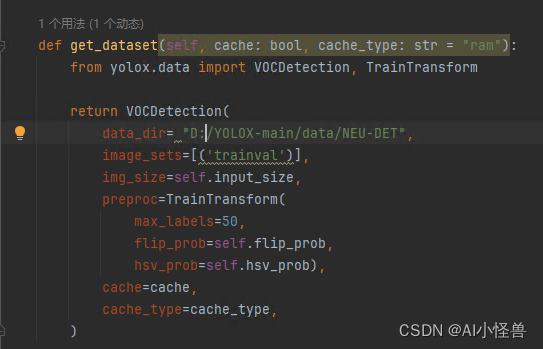
data_dir是前面product_ak的绝对路径,
images_sets修改为trainval
修改4:修改yolox/data/datasets/voc.py中,VOCDection函数中的读取txt文件。
for name in image_sets:
rootpath = self.root
for line in open(
os.path.join(rootpath, "ImageSets", "Main", name + ".txt")
):
self.ids.append((rootpath, line.strip()))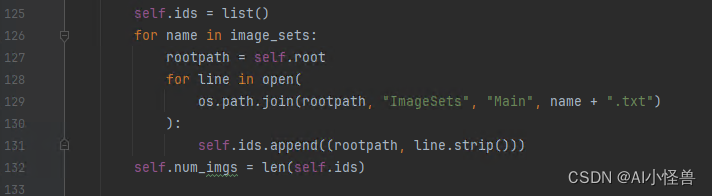
def _do_python_eval(self, output_dir="output", iou=0.5):
rootpath = self.root
name = self.image_set[0]
annopath = os.path.join(rootpath, "Annotations", "{:s}.xml")
imagesetfile = os.path.join(rootpath, "ImageSets", "Main", name + ".txt")
cachedir = os.path.join(
self.root, "annotations_cache", "VOC" + self._year, name
)
if not os.path.exists(cachedir):
os.makedirs(cachedir)
aps = []
# The PASCAL VOC metric changed in 2010
use_07_metric = True
print("Eval IoU : {:.2f}".format(iou))
if output_dir is not None and not os.path.isdir(output_dir):
os.mkdir(output_dir)
修改5:修改exps/example/yolox_voc/yolox_voc_s.py中的get_eval_loader函数。
def get_eval_dataset(self, **kwargs):
from yolox.data import VOCDetection, ValTransform
legacy = kwargs.get("legacy", False)
return VOCDetection(
data_dir="D:/YOLOX-main/data/NEU-DET",
image_sets=[('test')],
img_size=self.test_size,
preproc=ValTransform(legacy=legacy),
)
修改6:修改不同的网络结构
以YOLOX_s网络为例,比如在exps/default/yolox_s.py中,self.depth=0.33,self.width= 0.50。
修改7:报错解决
if self.cache and self.cache_type == "ram":
AttributeError: 'VOCDetection' object has no attribute 'cache'解决方案
修改yolox/data/datasets/voc.py
path_filename = [
# (self._imgpath % self.ids[i]).split(self.root + "/")[1]
(self._imgpath % self.ids[i]).split(self.root)[1]
for i in range(self.num_imgs)
]
3.1开启训练
python tools/train.py -f exps/example/yolox_voc/yolox_voc_s.py -d 0 -b 16 -c yolox_s.pth
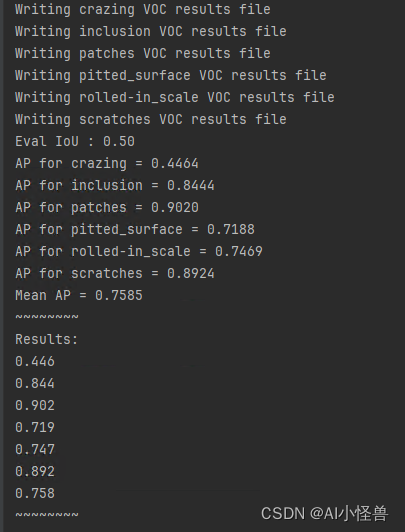
3.2 预测图片
tools/demo.py image -f exps/example/yolox_voc/yolox_voc_s.py -c ./YOLOX_outputs/yolox_voc_s/best_ckpt.pth --path data/NEU-DET/JPEGImages/inclusion_169.jpg --conf 0.3 --nms 0.65 --tsize 640 --save_result --device gpu 



















 2532
2532

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











