






Word Embedding
机器在没有监督的情况下,通过阅读大量文档来学习单词含义。
1-of-N Encoding WordEmbedding WordClass三种不同形式如下:
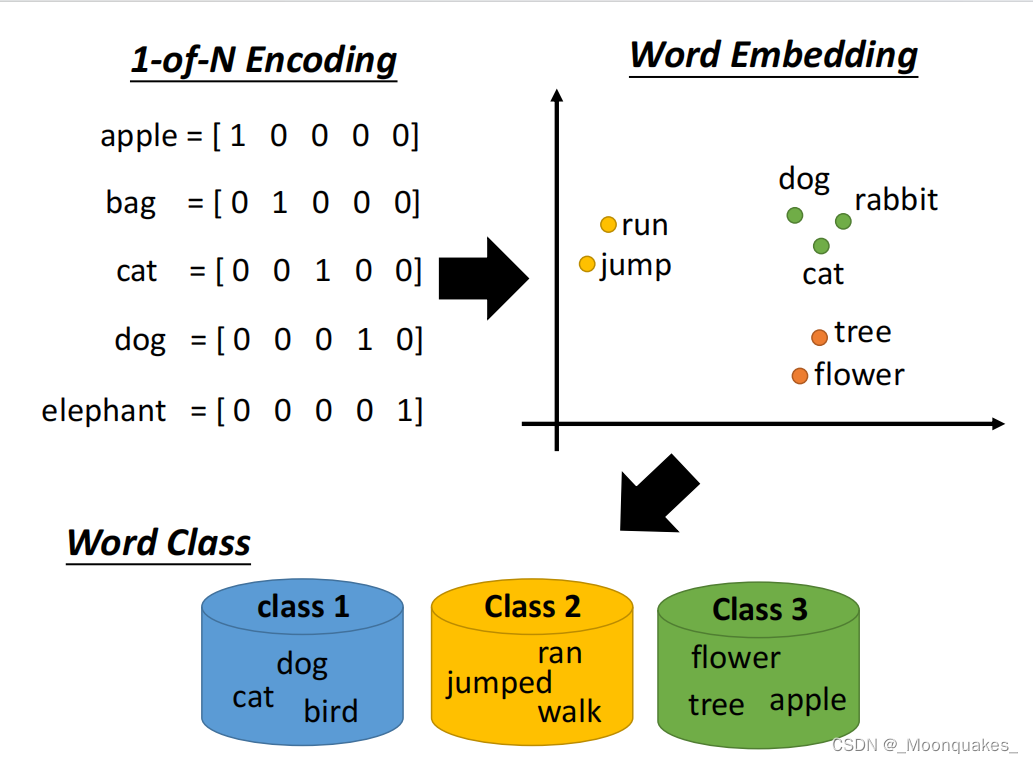
一个词可以用它的上下文来解释。
如何利用上下文?
1.基于计数
如果单词wi和wj经常同时出现,则V(wi)和V(wj)会距离很近。用V(wi)·V(wj)计算Nij(wi和wj在同一个文档中的次数)
2.基于预测
建立语言模型
P(“wreck a nice beach”)
=P(wreck|START)P(a|wreck)P(nice|a)P(beach|nice)
上述句子中,P(b|a)是神经网络预测下一个单词的概率。
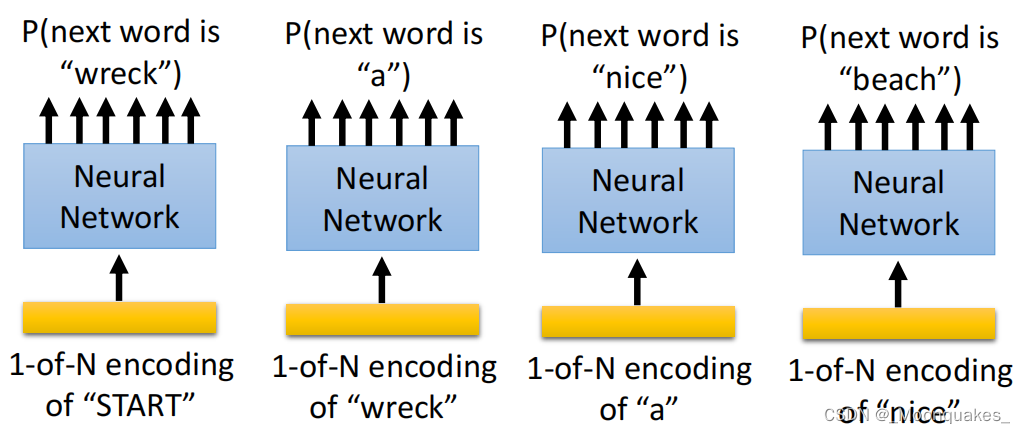
上图中,通过输入每个单词的1-of-N编码进入神经网络,从而输出下一个单词的概率。
取出第一层神经元的输入,用它来代表一个单词w,则词向量,单词嵌入特征则为V(w)。
共享参数
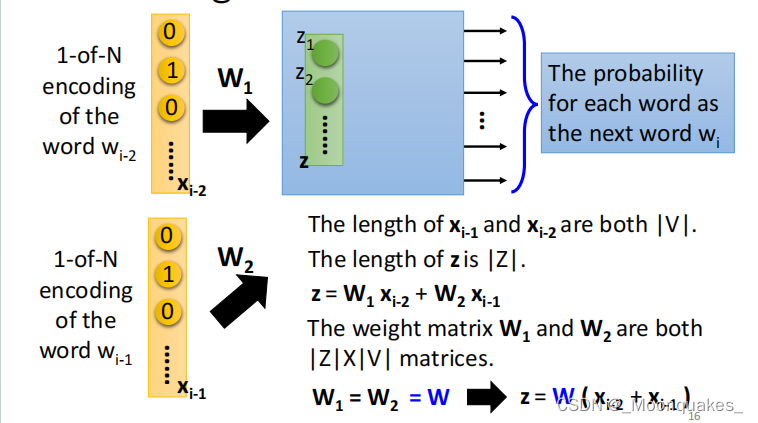
输入单词w(i-2)的编码x(i-2),其权重为W1,输入单词w(i-1)的编码x(i-1),其权重为W2。
经过神经网络后,得出每个单词作为下一个单词wi的概率。
x(i-2)和x(i-1)的长度均为|V|,z的长度为|Z|,z=W1*x(i-2)+W2*x(i-1)。
权重W1和W2均为|Z|*|V|的矩阵。
当W1=W2=W时,z=W*(x(i-2)+x(i-1))。
x(i-2)和x(i-1)中对应行输入到z中同一行的权重应当相同,否则一个词将会有两个词向量。
多样化架构
连续字袋(CBOW)模型:
将w(i-1)和w(i+1)均作为输入得出wi,即根据单词的上下文来预测单词
Skip-gram:
将wi作为输入的w(i-1)和w(i+1),即基于给定的单词预测上下文
Beyond Bag of word:
具有不同长度的词序列->具有相同长度的向量。
(表示单词序列含义的向量,单词序列可以是文档或者段落)
要理解单词序列的意思,就不能忽略单词的顺序。















 1027
1027











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









