






Natural Language Pretraining
Transformer
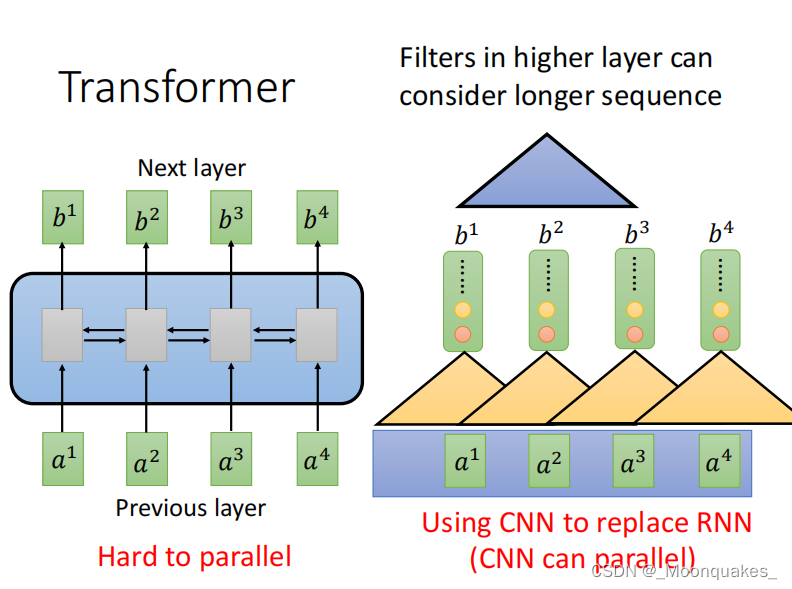
传统模型在并行化方面是困难的,引入Transformer允许并行计算。同时使用CNN代替RNN以处理更长的序列。
Self-Attention
自注意力机制通过计算输入序列中每个位置对其他位置的重要性,实现信息的有效提取和传递。
自注意力机制计算公式
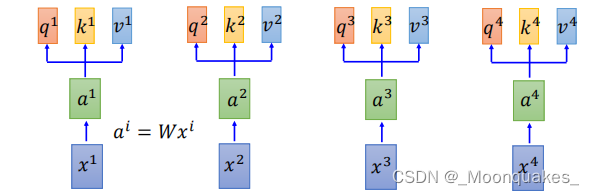
1.输入表示:每个输入表示为一个向量。
2.线性变换:输入向量通过线性变换生成查询(Q)、键(K)和值(V)。
3.注意力得分:计算Q与K的点积得到注意力得分。
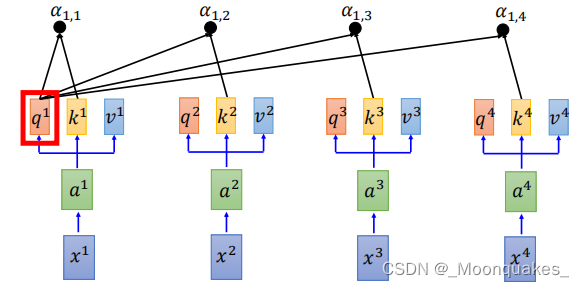
拿每个q对每个k做attention,其中d是键向量的维度,用于缩放。
4.归一化:对注意力得分进行softmax归一化,得到权重。
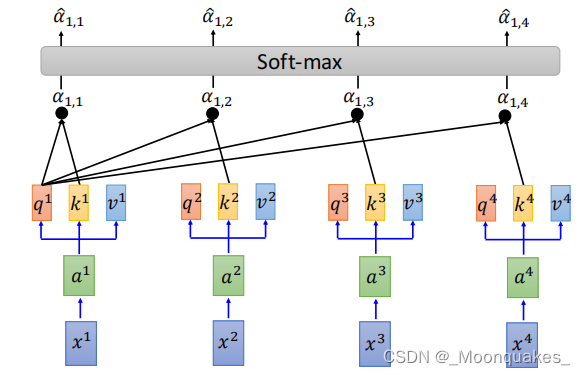
4.加权求和:使用归一化后的权重对值进行加权求和,得到最终输出。
b1,b2,b3,b4可以进行并行计算
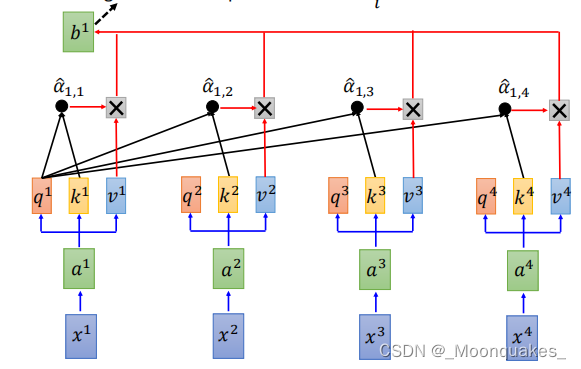
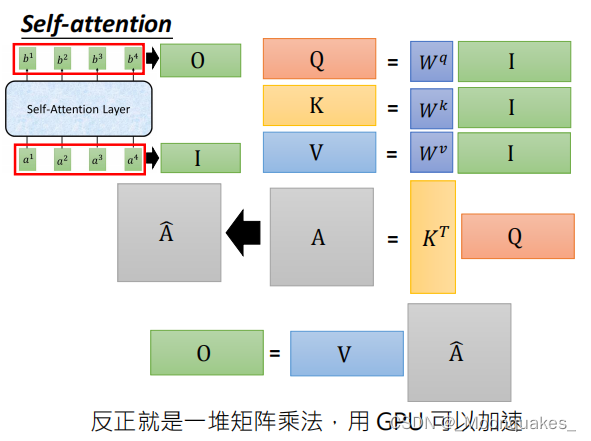
矩阵表示
查询矩阵Q、键矩阵K和值矩阵V分别由所输入向量通过线性变换得到。
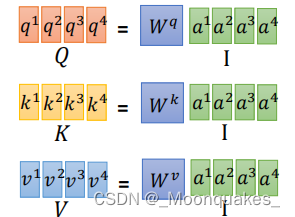
注意力得分矩阵通过查询矩阵Q和键矩阵K的转置相乘计算。
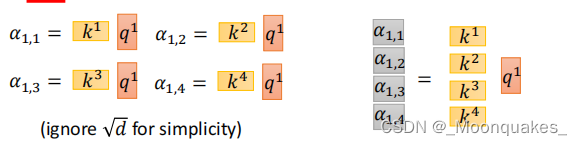

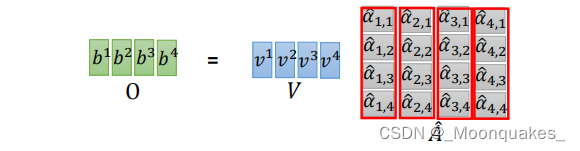
最终的输出通过注意力得分矩阵与值矩阵V相乘得到。
综合矩阵表达形式如下:
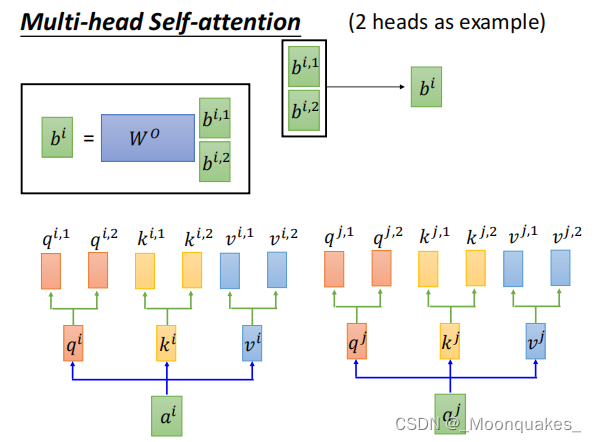
Multi-head Self-Attention
多头自注意力机制通过并行计算多个注意力头,捕捉不同的上下文信息。
(每个头独立计算自己的Q、K和V矩阵,然后进行自注意力计算。最终将各个头的输出拼接在一起,再通过线性变换得到最终结果。)
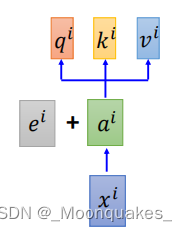
Position Encoding(位置编码)
自注意力机制本身没有位置信息,为了让模型识别输入序列的位置顺序,加入了位置编码。
(位置编码是预先定义的向量,表示每个位置的相对或绝对位置。位置编码和输入向量相加,提供位置信息。)
相关计算公式:
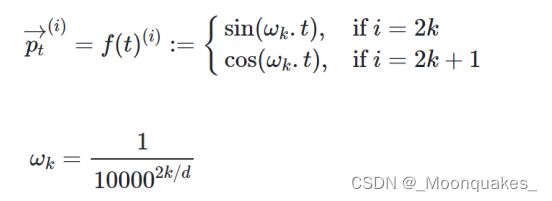
Seq2seq with Attention
是一种用于处理序列到序列任务的模型架构,常用于机器翻译、文本摘要和对话生成等应用。其主要组成部分包括编码器(Encoder)、解码器(Decoder)和注意力机制。
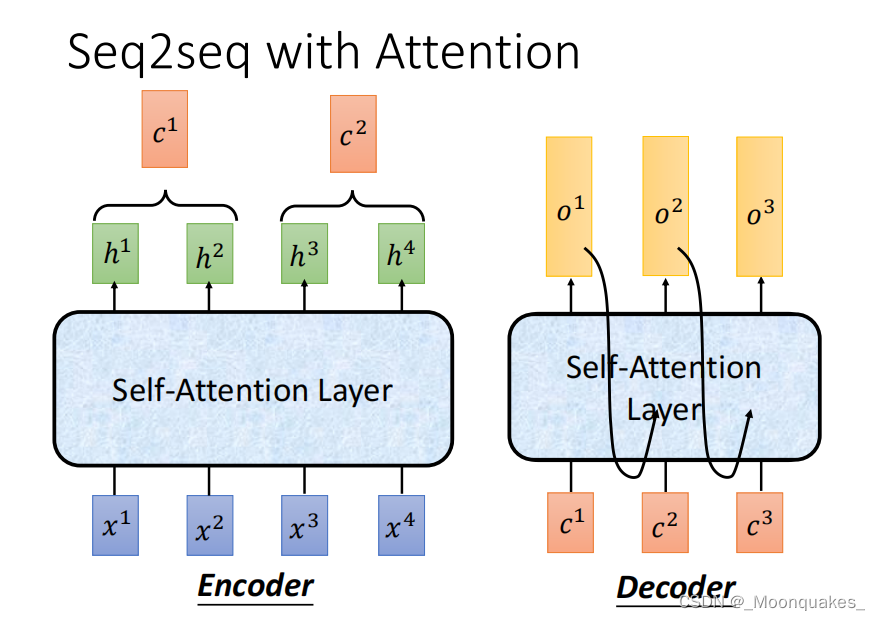
1.编码器:将输入序列转换为一个固定大小的上下文向量。通常由一系列RNN或CNN组成。
2.解码器:将上下文向量转换为目标序列。也是由一系列RNN或CNN组成,在生成序列的每一步会参考上下文向量。
3.注意力机制:允许解码器在生成目标序列的每个步骤时,根据输入序列的不同部分动态地选择信息。具体而言,计算解码器当前隐藏状态和编码器输出之间的相似度(注意力权重),根据这些权重对编码器输出进行加权求和,得到上下文向量。
编码器将输入序列𝑥1,𝑥2,𝑥3,𝑥4编码为隐藏状态ℎ1,ℎ2,ℎ3,ℎ4。
解码器在每个时间步结合注意力机制,通过计算与编码器隐藏状态的注意力权重,生成输出𝑜1,𝑜2,𝑜3。
Subword建模(子词建模)
词结构和Subword模型:Subword建模对于处理复杂的语言很重要,这些语言中的单词具有许多不同的变体和形式。使用固定的全词词汇是不够的,尤其对于形态丰富的语言。
字节对编码(BPE):BPE是一种简单而有效的定义子词词汇的方法。该方法从仅包含字符和“单词结束”符号的词汇开始。通过迭代地找到最常见的相邻字符并将他们合并成新的子词。这种方法有效地减少词汇表的大小,同时捕捉单词的不同形态。
优势:能够更好的处理未见过的单词,提高模型对语言的泛化能力。能够减少OOV(超出词汇表)问题,因为子词模型能够将单词分解成已知的子词进行处理。
从词嵌入中激发模型预训练
(预训练通过大量文本进行语言模型训练,保存网络参数,然后在特定任务上微调这些参数。微调通过适应特定任务的数据,利用预训练中学到的一般知识,提高NLP应用的表现。)
早期时,开始时使用预训练的词嵌入(没有上下文),在训练任务时学习如何结合上下文。下游任务的训练数据必须足够教会模型所有语言的上下文方面。网络中大部分参数都是随机初始化的。
现代NLP中几乎所有参数都是通过预训练初始化的。预训练方法会隐藏输入的一部分,并训练模型重构这部分。这种方法在构建强大的语言表示、参数初始化以及生成语言的概率分布方面非常有效。
模型预训练的三种方式
解码器预训练:
- 语言模型(Language Models):解码器通常用作语言模型来进行预训练。这些模型的任务是预测序列中下一个单词,给定之前的单词序列。这种预训练方式非常适合生成任务,例如对话生成和文本摘要,因为它们能够在生成过程中逐步预测下一个单词。
- 生成能力:解码器适合生成文本,因为它们可以根据输入的文本连续生成后续内容。
- 限制:解码器不能考虑未来的词,限制了在需要全局上下文理解的任务中使用。
- 训练目标:主要目标是最大化给定前面词的情况下下个词的可能性。
- 微调:微调过程中,在解码器最终隐藏状态上训练分类器,以适应具体的下游任务。
编码器预训练:
- 双向上下文:能够使用句子的完整上下文,使其适合需要深刻理解文本的任务。
- 掩码语言模型(Masked Language Models, MLM):由于编码器需要双向上下文,无法像解码器那样简单地进行语言建模。相反,编码器通过掩码语言模型进行预训练,即在输入序列中随机掩盖部分单词,然后让模型预测这些掩盖的单词。这个方法使编码器能够理解并利用上下文信息,从而更适合需要理解整个输入序列的任务,如文本分类和序列标注。
编码器-解码器预训练:
- 结合解码器和编码器的优势:这种架构结合了解码器和编码器的优点,适用于既需要生成又需要理解输入的任务。例如,机器翻译就是一个典型的应用场景,预训练方法需要同时考虑编码和解码的目标。这类模型的预训练方式通常结合了上述两种方法,既可以使用掩码语言模型来预训练编码器,也可以使用语言模型来预训练解码器。
预训练模型中学习的类型
- 琐事:模型能够填补地理位置或待定事实的空白。
- 语法:模型能够掌握基本的语法结构。
- 共指消解:模型能够识别句子中不同部分指代的是同一个对象。
- 词汇语义/主题:模型能够根据上下文预测词汇。
- 情感:模型能够推理出句子的情感倾向。
- 推理:模型在特定上下文中进行简单推理。
- 基本算术:模型能够处理简单的算术序列,但不一定能完整掌握复杂数学概念。
大模型和上下文学习
目前为止,已经通过两种方式与预训练模型进行交互:
- 它们定义的分布中的示例(可能提供提示)
- 根据我们所关心的任务来调整他们,并做出他们的预测。
非常大的语言模型似乎执行一些没有梯度步骤的学习,只是从其中上下文提供的示例。GPT-3是一个很典型的例子,有1750亿个参数。
上下文示例似乎指定了要执行的任务,而条件分布模拟在一定程度上执行了任务。
开放挑战
1.减少不良偏见
预训练模型容易学习训练数据中的不良偏见,并在下游任务中传播这些偏见。例如,Bolukbasi等人发现,预训练的word2vec词嵌入可以学习到性别刻板印象。通过类比完成任务(找出余弦距离最近的向量),他们发现词向量可以产生带有性别偏见的类比,如“男人是计算机程序员,就像女人是家庭主妇”。类似地,“父亲是医生,就像母亲是护士”。解决这一挑战的潜在方法包括:
- 通过数据集解决偏见:构建更为仔细和要求数据集文档化的数据集。
- 在测试时解决偏见:修改解码时的下一个词概率以减少偏见预测的概率 。
2.捕捉事实性知识
预训练模型需要有效捕捉和存储事实性知识。这是一个持续的挑战,因为大规模语言模型虽然能够生成流畅的文本,但它们在保持事实一致性和正确性方面表现不佳。捕捉事实性知识需要模型能够:
- 准确地从大量数据中学习事实。
- 在生成文本时保持这些事实的一致性。
- 更新事实知识库,以反映最新的信息 。
3.学习符号推理
符号推理涉及对更高层次逻辑关系和规则的理解与应用,这对预训练模型来说是一个重要的难题。大多数现有模型在处理复杂的推理任务时表现有限,主要挑战包括:
- 理解和应用符号逻辑规则。
- 在不同上下文中保持逻辑一致性。
- 有效地处理涉及多步骤推理的问题。
这些挑战反映了当前预训练模型在实现全面智能化上的一些限制,并指引了未来研究的方向 。















 4895
4895

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









