






语言模型
(参考宗成庆的课程及文档)
1 基本概念
大规模语料库的出现为自然语言统计处理方法的实现提供了可能,统计方法的成功使用推动了语料库语言学的发展。基于大规模语料库和统计方法,可以:发现语言使用的普遍规律,进行机器学习、自动获取语言知识以及对未知语言现象进行推测。
如何计算一段文字(句子)的概率?以一段文字(句子)为单位统计相对频率?根据句子构成单位的概率计算联合概率?
语句s=w1w2…wm的先验概率:
当i=1,p(w1|w0)=p(w1)
说明:(1)wi可以是字、词、短语或词类等等,称之为统计基元。通常以词代之。(2)wi的概率由w1,…,wi-1 决定,由特定的一组w1,…,wi-1 构成的一个序列,称为wi的历史。
问题:随着历史基元数量的增加,不同历史(路径)按照指数级增长。对于第i个统计单元,历史基元的个数为i-1,如果共有L个不同的基元,理论上每个单词都有可能出现在到i-1的每个位置,则i基元有中不同的历史情况。必须考虑在所有不同历史情况下产生第i个基元的概率。则模型中有
个自由参数。 (自有参数过多)
问题解决办法:设法减少历史基元的个数,将w1,w2,...,wi-1映射到等价类S(w1 w2 ... wi-1),使等价类的数目远远小于原来不同历史基元的数目。则有:
如何划分等价类:将两个历史映射到同一个等价类,当仅当这两个历史中最近n-1个基元相同,即:
这种情况下 的语言模型称为n元文法(n-gram)模型。
- 当n=1时,即出现在第i位上的基元wi独立于历史,一元文法也被写为uni-gram或monogram;
- 当n=2时,2-gram(bi-gram)被称为1阶马尔可夫链;
- 当n=3时,3-gram(bi-gram)被称为2阶马尔可夫链……
为了保证条件概率在i=1时有意义,同时为了保证句子内所有字符串的概率和为1.即,可以在句子首尾两端增加两个标志:<BOS>w1w2...wm<EOS>。不失一般性,对于n>2的n-gram,p(s)可以分解为:
其中,表示次序列
,
从
开始,
为<BOS>,
为<EOS>。
举例:


应用-1:音字转换问题
给定拼音串:ta shi yan jiu sheng wu de
可能的汉字串: 踏实研究生物的
他实验救生物的
他使烟酒生物的
他是研究生物的
计算公式:

其中,CString是可能的汉字串。
使用n元文法模型 :通过考虑n个连续单元(字)之间的概率关系来计算整个串的概率。
以二元文法为例:P(CString1) = P(踏实 | <BOS>) * P(研究 | 踏实) * P(生物 | 研究) * P(的 | 生物) * P(<EOS> | 的)
P(CString2) = P(他 | <BOS>) * P(实验 | 他) * P(救 | 实验) * P(生物 | 救) * P(的 | 生物) * P(<EOS> | 的)
如果汉字的总数为N,一元语法(样本空间为N,只选择使用频率最高的汉字),二元语法(样本空间为N^2,效果比一元语法明显提高)。估计对汉字而言四元语法效果会更好。
应用-2:汉语分词问题
给定的汉字串:他是研究生物的。
可能的切分结果:1. 他|是|研究生|物|的 2. 他|是|研究|生物|的
计算公式:
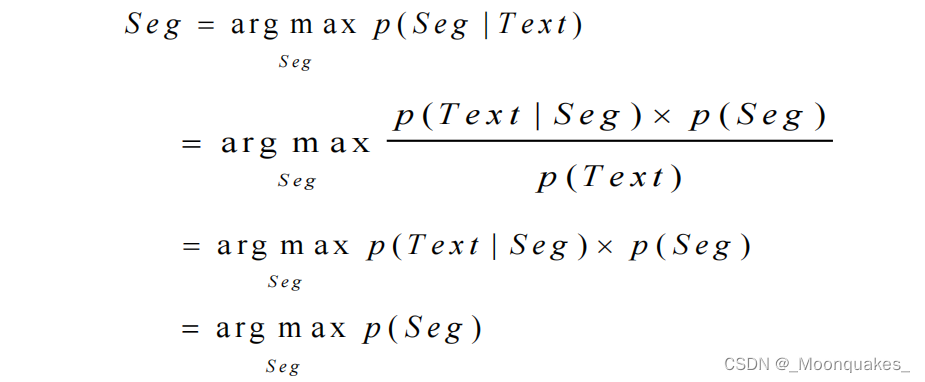
训练集是标注好的,所以必须后验转先验,即利用Seq来计算生成Text的概率。
以二元文法为例:P(Seg1) = P(他 | <BOS>) * P(是 | 他) * P(研究生 | 是) * P(物 | 研究生) * P(的 | 物) * P(<EOS> | 的)
P(Seg2) = P(他 | <BOS>) * P(是 | 他) * P(研究 | 是) * P(生物 | 研究) * P(的 | 生物) * P(<EOS> | 的)
2 参数估计
重要概念:
- 训练语料:用于建立模型,确定模型参数的已知语料。
- 最大似然估计:用相对频率计算概率的方法。
对于n-gram,参数可由最大似然求得:
其中,是历史串
在给定预料中出现的次数,即
,不管wi是什么。
是在给定
的条件下wi出现的相对频度,分子为
和wi同时出现的次数。
例如,给定训练预料:
根据2元文法求句子概率?
(先在句子首尾添加<BOS>和<EOS>再进行计算)

但也会发生下面的情况,某些词组并未出现,会导致概率为0。

数据匮乏(稀疏)引起零概率问题,如何解决?数据平滑
3 数据平滑
数据平滑的基本思想:调整最大似然估计的概率值,使零概率增值,使非零概率下调,“劫富济贫”,消除零概率,改进模型的整体正确率。
基本目标:测试样本的语言模型困惑度越小越好。
基本约束:
困惑度的定义:
对于一个平滑的n-gram,其概率为,可以计算句子的概率为:
假定测试语料T有个句子构成,则整个测试集的概率为:
模型对于测试语料的交叉熵:
其中,是测试文本T是词数。模型p的困惑度
数据平滑的方法:
(1)加1法:
- 基本思想:每一种情况出现的次数加1。例如对于uni-gram,设w1,w2,w3三个词,概率分别为1/3,0,2/3,加1后情况?2/6,1/6,3/6。
- 对于2-gram有:
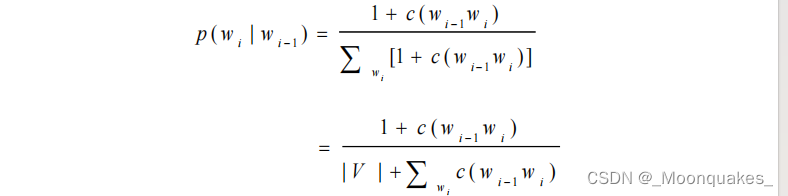 其中V是被考虑语料的词汇量(全部可能的基元数)。
其中V是被考虑语料的词汇量(全部可能的基元数)。 


(2)减值法/折扣法
- 基本思想:修改训练样本中事件的实际计数,使样本中(实际出现的)不同时间的概率之和小于1,剩余的概率分配给未见概率。
Good-Turing估计:
假设N是原来训练样本数据的大小,nr是在样本中正好出现r次的事件的数目(此处事件为n-gram),即出现1次的n-gram有n1个,2次的n-gram有n2个……
那么,。
设:原先出现r次的n-gram在平滑后出现r*次,则,则
。
所以,。
那么,Good-Turing估计在样本中出现r次的事件平滑后的概率为:
实际应用中,一般直接用代替
,用
代替
。这样,原训练样本中所有事件的概率之和为:
因此,有的剩余的概率量就可以均分给所有的未见事件(r=0).
Good-Turing估计适用于大词汇集产生的符合多项式分布的大量观察数据。
举例:

统计不同2-gram分别出现的次数
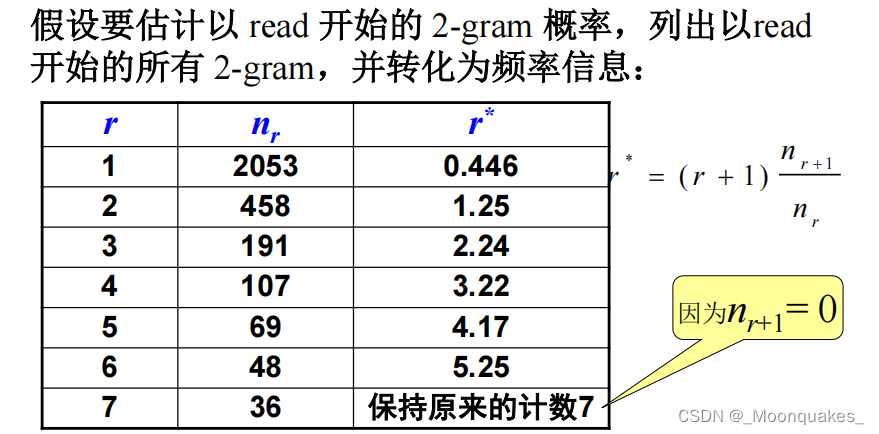
列出所有以read开始的2-gram概率

计算剩余没有出现过以read开始的2-gram的概率平均,并进行归一化

Back-off(后备/后退)方法,也称Katz后退法:
基本思想:当某一事件在样本中出现的频率大于阈值K(通常为1或0)时,运用最大似然估计的减值法来估计其概率,否则,使用低阶的,即(n-1)gram的概率替代n-gram概率,而这种替代需受归一化因子的作用。
另一种解释:对于每个计数r>0的n元文法的出现次数减值,把因减值而节省下的剩余概率根据低阶的(n-1)gram分配给未见事件。
以2-gram为例,说明Katz平滑方法:


绝对减值法:
基本思想:从每个计数r中减去同样的量,剩余的概率量由未见事件均分。
设R为所有可能事件的数目(当事件为n-gram时,如果统计基元为词,且词汇集的大小为L,则R=L^n)。
那么样本出现了r次的事件概率可以有如下公式估计:
 其中,n0为样本中未出现的事件的数目。b为减去的常量,b<=1。
其中,n0为样本中未出现的事件的数目。b为减去的常量,b<=1。
b(R-n0)/N是由于减值而产生的剩余概率量。
b是自由参数,可以通过留存数据法求得b的上限为:
线性减值法:
基本思想:从每个计数r中减去与该计数成正比的量(减值函数为线性的),剩余概率量被n0个未见事件均分。
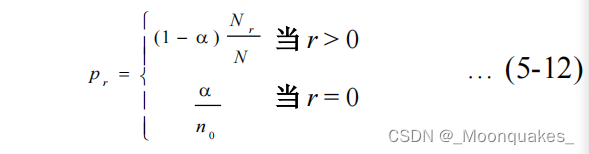
自由参数的优化值为:
绝对减值法产生的n-gram通常优于线性减值法。
四种减值法的比较:
- Good-Turing法:对非零事件按公式削减出现的次数,节留出来的概率均分给0概率事件。
- Katz后退法:对非零事件按Good-Turing法计算减值,节留出来的概率按低阶分布分给0概率事件。
- 绝对减值法:对非零事件无条件削减某一固定出现次数值,节留出来的概率均分给0概率事件。
- 线性减值法:对非零事件根据出现次数按比例削减次数值,节留出来的概率均分给0概率事件。
(3)删除插值法:
基本思想:用低阶语法估计高阶语法,即当3-gram的值不能从训练数据中准确估计时,用2-gram来代替,同样,当2-gram的值不能从训练语料中准确估计时,可以用1-gram的值来代替。
插值公式:
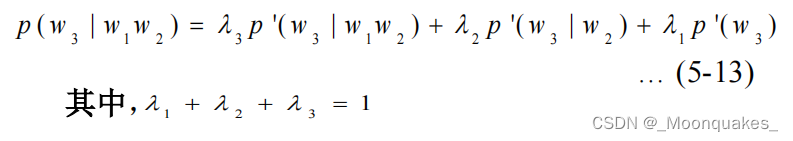
将训练语料分为两部分,即从原始语料中删除一部分作为留存数据。第一部分用于估计。第二部分用于计算
:使语言模型对留存数据的困惑度最小。
4 语言模型自适应
问题:
-
在训练语言模型时所采用的语料往往来自多种不同的领域,这些综合性语料难以反映不同领域之 间在语言使用规律上的差异,而语言模型恰恰对于训练文本的类型、主题和风格等都十分敏感。
-
n 元语言模型的独立性假设的前提是一个文本中的当前词出现的概率只与它前面相邻的 n-1 个词相关,但这种假设在很多情况下是明显不成立的。
方法:
(1)基于缓存的语言模型
该方法针对的问题是:在文本中刚刚出现过的一些词在后边的句子中再次出现的可能性往往较大,比标准的n-gram模型预测的概率要大。
针对这种现象,cache-based自适应方法的基本思路是:语言模型通过n-gram线性插值求得:

通常的处理方法是:在缓存中保存前面K个单词,每个词的概率用其在缓存中出现的相对频率计算得出:

这种方法的缺陷是,缓存中一个词的重要性独立于该词与当前词的距离。
研究表明,缓存中每个词对当前词的影响随着与该词距离的增大呈指数级衰减。

(2)基于混合方法的语言模型
针对的问题是:由于大规模训练语料本身是异源的,来自不同领域的语料在主题或者风格方面都有一定差异,而测试语料一般是同源的,因此为了获得最佳性能,语言模型必须适应各种不同类型的语料对其性能的影响。
处理方法:将语言模型划分为n个子模型,M1,M2,……,Mn整个语言模型通过下面线性插值公式得到:
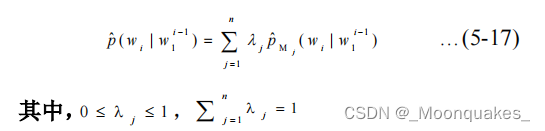
可以通过EM算法计算出来。
基本方法:
- 对训练语料按来源、主题或类型等聚类;
- 在模型运行时识别测试语料的主题或主题的集合;
- 确定适当的训练语料子集,并利用这些语料建立特定的语言模型;
- 利用针对各个语料子集的特定语言模型和线性插值公式,获得整个语言模型。
EM迭代计算插值系数:
- 对于n个类,随机初始化插值系数
;
- 根据公式计算新的概率和期望;
- 第r次迭代,第j个语言模型在第i类上的系数:

-
不断迭代,重复第2步和第3步。
(3)基于最大熵的语言模型
基本思想:通过结合不同信息源的信息构建一个语言模型。每个信息源提供一组关于模型参数的约束条件,在所有满足约束的模型中,选择熵最大的模型。
例如,两个语言模型M1和M2。
假设M1是标准的2元模型,表示为f函数:
M2是距离为2的2元模型,定义为g函数:
用线性插值的方法通过取这两个概率估计的平均值,并采用后备平滑技术来解决这个问题。
最大熵原则将所有信息源组合成一个模型,对于该模型的约束并不是让上述两个公式对于所有可能的历史都成立,而是更宽松的限制,即在训练数据上平均成立即可。因此,公式可改写为:
如果约束条件是一致的,那么总有模型满足这些条件,余下即利用通用迭代算法选择使熵最大的模型。
5 语言模型应用举例
汉语分词问题

采用基于语言模型的分词方法:
设对于待切分的句子S=z1z2...zm,W=w1w2...wk是一种可能的切分。那么
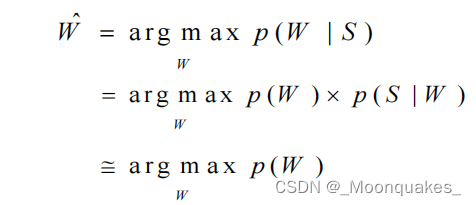
最基本的做法是以词为独立的统计基元,但效果不佳。
具体实现时,可以对汉语词汇进行分类:
(1)词表词:分词词典中规定的词;(2)派生词:由词法规则派生出来的词或短语;(3)与数字相关的实体;(4)专用名词,如人名、地名、组织机构名。
进一步做如下约定,把一个可能的词序列W转换成词类序列C=c1c2...cn,即:
- 专有名词:人名PN、地名LN、机构名ON分别为一类
- 实体名词中的日期dat、时间tim、百分数per、货币mon等作为一类
- 对词法派生词MW和词表词LW,每个词单独作一类
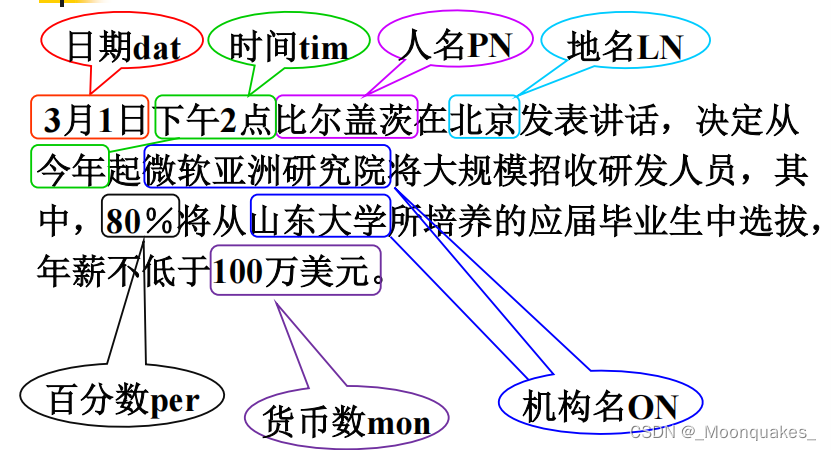
词序列变为类序列:


生成模型在满足独立性假设的条件下,可近似为:
即任意一个词类ci生成汉字串si的概率只与自身有关,而与其上下文无关。

模型训练分三步:
- 在词表和派生词表的基础上,用一个基本的分词工具切分训练语料,专有名词通过一个专门模块标注,实体名词通过相应规则和有限状态自动机标注,由此产生一个带词类标记的初始语料;
- 用带词类别标记的初始语料,采用最大似然估计方法估计语言模型的概率参数;
- 用得到的模型对训练语料重新节分和标注,得到新的训练语料。
分词与词性标注一体化方法

假设句子S是由单词串组成:W=w1w2...wn
单词wi的词性标注为ti,即句子S的词性标注符号序列表达为T=t1t2...tn
那么分词与词性标注的任务就是要在S所对应的各种切分和标注形式中,寻找T和W的联合概率p(W,T)为最优的词切分和标注组合。




















 784
784











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









