









目录
VAE (Variational AutoEncoder)变分自编码器
只是为了学习
EEG
脑电信号,也称脑电图(EEG,Electroencephalography)是大脑神经元活动产生的电信号。神经元通过突触连接彼此,形成复杂的神经网络。当神经元激活时,会产生生物电现象,这些电信号可以通过电极放置在头皮上或直接植入大脑来捕捉。
研一,老师方向是脑机接口,让自学EEG 我现在自学了eeglab的预处理,接下来应该学习什么? - 形宙数字的回答 - 知乎
https://www.zhihu.com/question/588041972/answer/3542835053
EEG信号的分析和处理通常会涉及以下一个或多个方面:信号的预处理(预处理也需要多个步骤)、ERP时域分析、时频分析、信号的功率谱计算、功能连接、溯源分析等等。
EEGLAB是一款基于Matlab软件的开源工具包,可用于处理连续和事件相关EEG信号。
特征和特点
EEG总结(脑电图) - 睿rhr的文章 - 知乎
https://zhuanlan.zhihu.com/p/15102370282
EEG信号采集后是由通道数(即电极数)*时间点数二维数组形式组成。
- 时域特征(time domain)—— 事件相关电位(event related potential, ERP)
- 频域特征(frequency domain)首先将原始的时域信号转换至频域获得频谱,之后将频段分解到与人的心理活动联系密切的5个子频段δ,θ,α,β,γ,再从中计算特征。通常使用傅里叶变换(Fourier transfer, FT) 进行时-频域转换。——事件相关 (去) 同步化(ERD / ERS):在一个刺激事件之后的若干毫秒内,EEG信号在某一频段上功率的快速升高。
- 时频域特征(time-frequency domain):划分出若干时间窗,各窗内的子信号近似平稳,将其变换至频域得到一组频域特征,滑动时间窗可处理不同时段,从而同时获取信号的时域和频域信息,提高对不稳定信号的处理能力,可粗略计算情绪开始和持续的时间。
| 高时间分辨率 | EEG能够捕捉大脑活动的即时反应,精确到毫秒级。这使得它在研究大脑在特定任务或刺激下的反应非常有效。 |
| 全脑活动的测量 | EEG可以反映大脑各个区域的电活动,能够揭示大脑不同区域之间的相互作用和功能网络。 |
| 非侵入性 | 相较于其他脑成像技术(如功能性磁共振成像fMRI或脑磁图MEG),EEG是一种安全、非侵入性的技术,适用于长期监测。 |
| 成本相对较低 | EEG设备的成本较低,并且维护相对简单,使其成为许多临床和研究环境中常见的选择。 |
| 空间分辨率较低 | 尽管EEG具有极高的时间分辨率,但由于信号需要通过头骨传导,EEG在空间分辨率上有限,难以精确定位大脑深层结构的活动。 |
| 噪声干扰 | EEG信号容易受到眼动、肌肉活动等生理噪声的影响,需要通过信号处理技术来去除这些伪影。 |
| 非平稳信号 | 大脑的活动状态会随着时间的推移发生变化。例如,在不同的睡眠阶段、注意力集中程度、情绪波动或不同的认知任务下,大脑的电活动会表现出不同的频率和幅度特征。 |
EEG处理方法
EEG数据增强:解决小数据集的问题
非深度学习方法:滑动窗口(增加了训练数据的数量,但也消除了long-term信息)、噪声注入、分割重组
深度学习方法(需要大量的训练数据才能实现高分类精度并避免过度拟合):生成对抗网络、变分自编码
高斯噪声
GAN 及其变体可以通过训练生成网络和判别网络来生成人工数据。生成网络接受来自特定分布(例如高斯分布)的随机噪声,并尝试生成类似于真实数据的合成数据,而判别网络则经过训练以对真实数据和合成数据进行分类。这两个网络是对抗性的,经过充分的训练,生成网络将产生相似的信号。
VAE,就像普通的自动编码器一样,编码器将原始数据转换为潜在数据,解码器将潜在数据映射回真实数据。为了生成新数据,VAE 从学习的潜在空间中随机采样点,然后将这些样本传递给解码器网络,解码器网络将它们重建为新样本。 GAN 和 VAE 都间接生成新样本。
EEG 维度降低:提高特征信号的提取效果和分类鲁棒性。
脑电图信号是多维信号。
主成分分析(PCA):分离出眼睛和肌肉的干扰等冗余成分。
独立成分分析 (ICA) :没有经过训练来学习噪声信号的特征,一些有价值的信号可能会作为噪声被去除,导致一些大脑活动信息丢失。
利用小波变换(WT):通过ICA-WT滤波,可以有效消除噪声伪影
预处理的自动编码器(AE):编码器将输入原始数据的信息提取到一个小的潜在空间中,然后解码潜在数据以重建数据集。由于潜在变量携带原始信号的信息但维度较少,使用潜在变量作为后续步骤的输入。
EEG特征提取
传统特征提取
局限性:特征提取和分类是分开进行的,在特征提取过程中需要手动添加大量经验或先验知识。
通用空间模式(CSP):用于二元分类任务的空间域过滤算法。 CSP提取多通道EEG信号每一类的空间分布分量,并寻求最佳投影方向,以最大化一类的方差并最小化另一类的方差。 由于CSP最大化了脑电信号之间的差异,因此更有能力挖掘脑电信号的特征。
傅里叶变换(FT)
自回归(AR):时间序列预测,假设时间序列的当前值与其过去值线性相关。
机器学习
SVM 可用于线性可分离数据,通过优化算法找到最佳超平面。 对于线性不可分的问题,可以使用核函数将数据变换到更高维的空间。
LDA 是一种简单的线性分类器,它将所有样本投影到一条线上,以最大化类间距离并最小化类内方差。
KNN是一种分类方法,统计与新样本距离最近的k个样本的类别数。
深度学习自动提取特征:捕获脑电图信号底层结构的有用特征,而无需显式特征提取。 多层感知器(MLP)、卷积神经网络(CNN)、循环神经网络(RNN),LSTM等
未来展望
创新的预处理方法:网络的结构有关。例如,Liu和Yang(2021)以及Bagchi和Bathula(2022)都将原始信号转换为3D张量,前者简单地表示矩阵中电极的位置,并对没有电极的细胞填充零,而后者则采用方位角等距投影(AEP,一种将地球仪投影到平面上的方法)将3D电极的分布转换为2D热图图像,并保持电极的相对距离。经过 AEP(可能是 Average Evoked Potential(平均诱发电位))和插值后,EEG 信号变成带有大量 2D 热力学图像的视频流,可以通过 ConvTransformer 进行分析。
跨被试性能问题:当将迁移学习应用于其他受试者时,准确性从受试者内任务的 99% 急剧下降到约 50%,这表明参数过度拟合给定的个体,并且不能轻易地推广到新个体。
多模型融合:很少有研究人员采用机器学习融合来关注算法有效性的解释,以及将算法与认知机制联系起来。背后的认知机制尚不完全清楚。
多样本融合:使用SVM对EEG信号进行分类,其中来自相同实验条件的多个样本被组合以提高分类准确性。
视觉内容生成
AIGC(人工智能生成内容)是指利用人工智能技术自动生成内容的生产方式。它涵盖了从文本、图像到音频、视频等多种形式的内容创作。AIGC的核心技术包括GAN、CLIP、Transformer、Diffusion、预训练模型、多模态技术等。
生成式模型
学习可观测样本的概率密度,并随机生成新样本
AIGC基础知识简介:大模型、多模态、预训练、扩散模型 - 笑书神侠的文章 - 知乎https://zhuanlan.zhihu.com/p/635574487
AutoEncoder自编码器
图像压缩算法 Encoder->latent code->Decoder,如果图像加一些扰动 Decoder变的脆弱不可控
Latent Code(隐代码)是通过机器学习模型从观测数据中推断出来的隐藏特征。在深度学习中,尤其是在生成对抗网络(GANs)中,隐代码用于生成新的数据实例。隐代码组成的空间被称为Latent Space(隐空间),在这个空间中,数据点通过某种映射关系与生成的数据相关联。
GAN
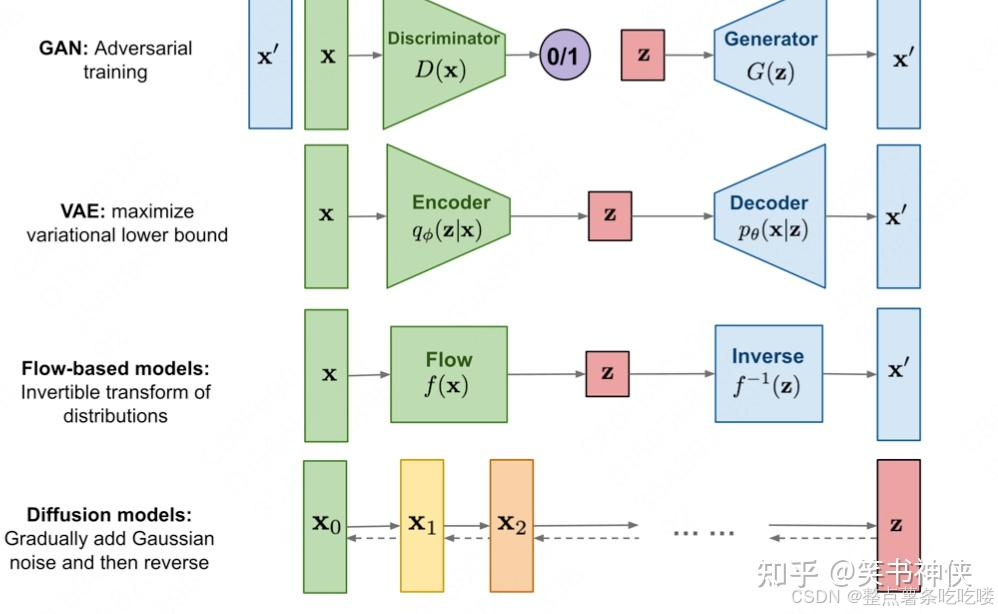
Generative adversarial network,生成对抗网络。生成网络(Generator)负责生成模拟数据;判别网络(Discriminator)负责判断输入的数据是真实的还是生成的。生成网络要不断优化自己生成的数据让判别网络判断不出来,判别网络也要优化自己让自己判断得更准确。二者关系形成对抗,因此叫对抗网络。
https://zhuanlan.zhihu.com/p/610012156
GAN由于需要同时训练生成器和判别器,比较难平衡和收敛(生成器通过某些“捷径”骗过判别器,导致效果并不好),这使得训练不稳定。并且多样性比较差
VAE (Variational AutoEncoder)变分自编码器
对多个高斯分布的特征进行采样,将真实样本通过编码器网络变换成一个理想的数据分布,然后这个数据分布再传递给一个解码器网络,得到一堆生成样本,生成样本与真实样本足够接近的话,就训练出了一个自编码器模型。VAE的优化目标为重建损失和KL散度约束。
但VAE的方法输出模糊,常会失真。在Encoder时对图像压缩比较大,导致Decoder时得到的图像质量比较差
Flow-based Model
建立训练数据和生成数据之间的概率关系,然后用可逆的神经网络来训练,这种关系是一一对应的。代价就是模型设计比较麻烦,因为要保证可逆而且逆函数可以算,还要有足够的灵活度。
Diffusion Model
DDPM是指Denoising Diffusion Probabilistic Models,即去噪扩散概率模型,利用马尔科夫假设和贝叶斯推理。
前向过程(扩散过程)和复原过程。灵感来自热力学,通过扩散过程向数据缓慢添加随机噪声,然后学习逆转扩散过程,从噪声中构建所需的样本。得到的图像质量好,不失真。只需要训练一个模型,优化更加容易一些
每一个噪声都是在前一时刻增加噪声而来的(马尔科夫过程)
为什么要加噪声?Diffusion的本质是去噪,为了推导出逆向的去噪方法,必须了解增加噪声的原理。同时,添加噪声的过程其实就是不断构建标签的过程。如果在前一时刻可以预测出来后一时刻的噪声,很方便地可以实现还原操作。
噪声的添加过程中,每一步都要保持尽量相同的噪声扩散幅度。图片前期的分布非常均匀,添加一些噪声便可以将原始分布改变,但到后期,需要添加更多的噪声,方可保证噪声扩散幅度相同(有趣的比喻,水中加糖,为了使糖的甜味增长相同,后期需要加更多的糖)

















 2319
2319

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









