







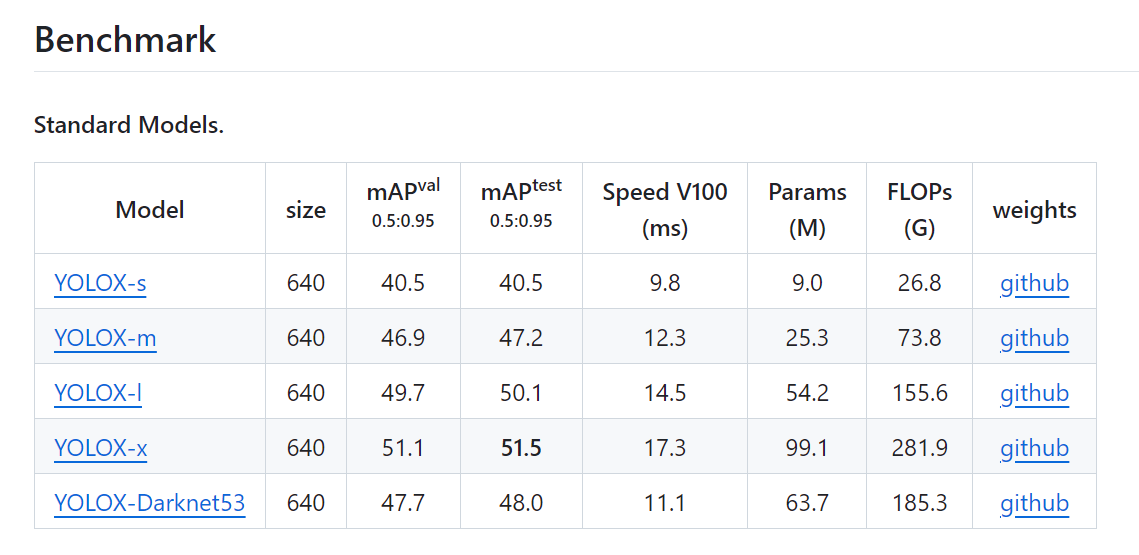
YOLOX运行环境要求
参考这篇的环境配置:从深度学习目标检测新手视角安装MMDetection到使用公开数据集进行模型测试
GitHub克隆YOLOX仓库源代码
git clone git@github.com:Megvii-BaseDetection/YOLOX.git
cd YOLOX
pip3 install -v -e . # or python3 setup.py develop
下载预训练权重
在这https://github.com/Megvii-BaseDetection/YOLOX下载预训练权重并整理放入YOLOX/checkpoints/yolox_x.pth
下载好预训练权重后,终端运行如下代码
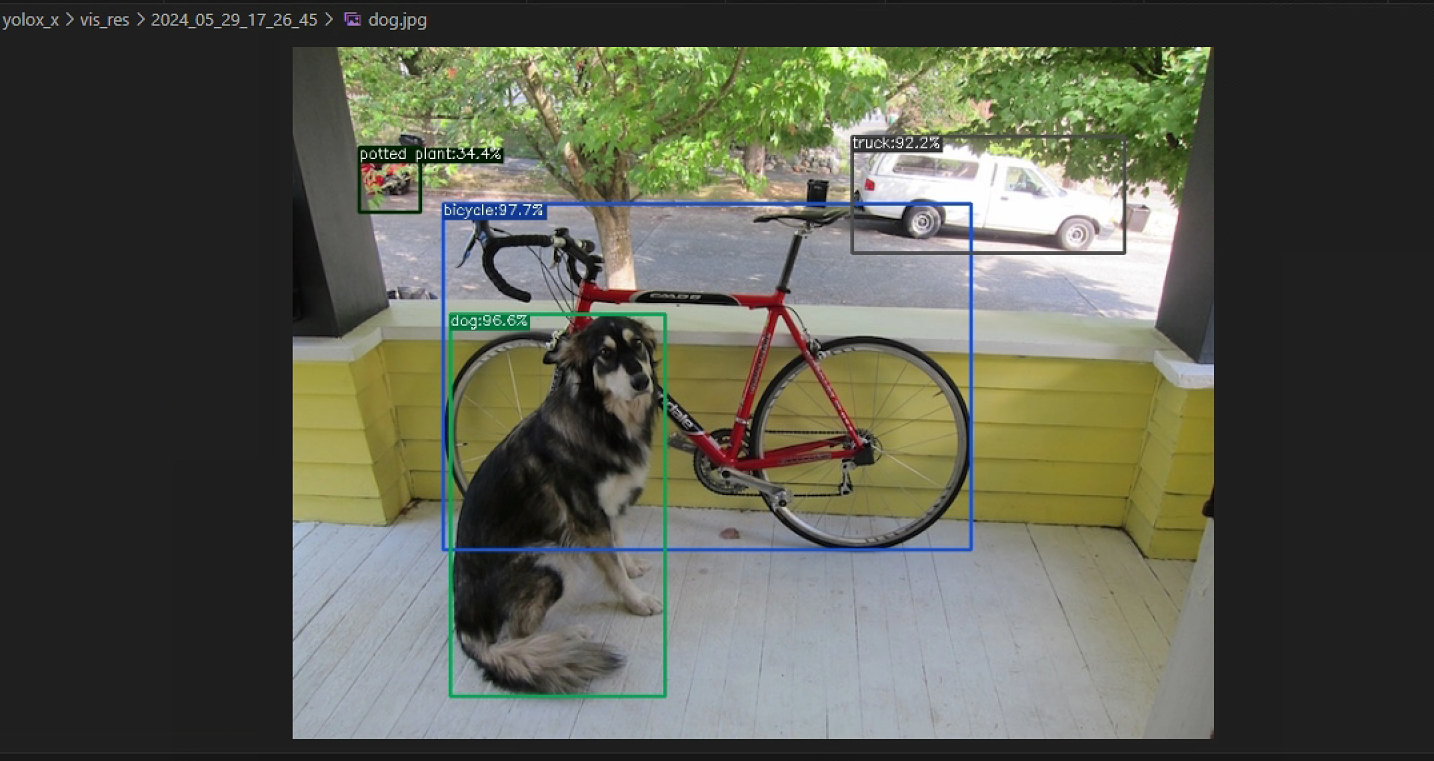
python tools/demo.py image -n yolox-s -c YOLOX/checkpoints/yolox_x.pth_s.pth --path assets/dog.jpg --conf 0.25 --nms 0.45 --tsize 640 --save_result --device cpu
倘若YOLOX的运行环境无任何问题,可在YOLOX/YOLOX_outputs/yolox_x/vis_res/2024_05_29_17_26_45/dog.jpg看见预测好的样本图片
阅读数据集内README文档
根据YOLOX/datasets/README.md可知
这段指导文本说明了如何为YOLOX对象检测模型准备数据集,特别是针对COCO数据集的结构要求。YOLOX是一个高性能的目标检测模型框架。下面是逐步解析:
-
设置数据集目录: YOLOX允许用户通过环境变量
YOLOX_DATADIR指定数据集的根目录。这意味着,如果你想让YOLOX自动识别你的数据集位置,你应该设置这个环境变量指向包含数据集的文件夹。export YOLOX_DATADIR=/path/to/your/datasets如果没有设置
YOLOX_DATADIR,YOLOX会默认在当前工作目录下的./datasets寻找数据集。 -
COCO数据集结构: 对于COCO数据集,需要遵循特定的文件夹和文件命名规则。COCO数据集主要由两部分组成:标注文件和图像文件。
-
标注文件位于
COCO/annotations/目录下,包括instances_train2017.json和instances_val2017.json(或者相应年份的版本,如2014年版)。这些JSON文件包含了训练集和验证集每张图片的对象标注信息。 -
图像文件则应放在
COCO/{train,val}2017/目录下,其中{train,val}是占位符,实际应替换为train或val,对应训练集和验证集的图像文件。确保这些图像文件在JSON标注文件中有对应的引用。
-
简而言之,要准备COCO数据集以供YOLOX使用,你需要正确地组织数据集结构,并可选地设置YOLOX_DATADIR环境变量指向该数据集的根目录。这样,YOLOX就能根据这些指示找到并加载所需的训练和验证数据。
准备自定义数据集
在这个页面下载一个简易的车辆损坏COCO格式数据集https://www.kaggle.com/datasets/lplenka/coco-car-damage-detection-dataset
将其如下列形式整理放入YOLOX/datasets文件夹中
需要将图片文件夹改为
train2017和val2017(目前不知道为什么)
└─datasets
└─Car
├─annotations
| ├─COCO_train_annos.json
| └─COCO_val_annos.json
├─train2017
| ├─001.jpg
| └─....jpg
└─val2017
├─002.jpg
└─....jpg
接下来,根据实际数据集自定义路径,在终端利用export设置数据集根路径
export YOLOX_DATADIR=/home/miqi/YOLOX/datasets/Car
修改相关配置文件代码
在YOLOX/exps/example/custom/yolox_s.py文件中,可对应自定义数据集修改annotations文件的路径,并修改数据集类别数num_classes,再根据需要修改epoch次数max_epoch
# Define yourself dataset path
self.data_dir = "/home/miqi/YOLOX/datasets/Car/"
self.train_ann = "COCO_train_annos.json" # 你的训练集标签文件
self.val_ann = "COCO_val_annos.json" # 你的验证集标签文件
self.num_classes = 1 # 你的数据集类别数
self.max_epoch = 10
self.data_num_workers = 4
self.eval_interval = 1
在YOLOX/datasets/Car/annotations/COCO_val_annos.json查找categories,获取数据集具体类别名称
"categories": [
{
"id": 1,
"name": "damage",
"supercategory": "part"
}
在YOLOX/yolox/data/datasets/coco_classes.py修改对应的具体类别名称。如上所示,我的简易数据集只有一个类别
COCO_CLASSES = (
"damage",
)
修改训练文件代码
参考该博主帖子,在YOLOX/tools/train.py训练文件中修改
# 设置 default="Car", 训练后结果就会保存在 YOLOX/tools/YOLOX_outputs/Car下
parser.add_argument("-expn", "--experiment-name", type=str, default=None)
# 设置 model_name,如果--exp_file参数为None,则通过此参数加载exps/default/中的默认的实验配置
parser.add_argument("-n", "--name", type=str, default="yolox-s", help="model name")
# 设置batch_size,注意这里的batchsize数应大于gpu数量,不然会报错batch=0的error
parser.add_argument("-b", "--batch-size", type=int, default=3, help="batch size")
# 设置gpu数量
parser.add_argument(
"-d", "--devices", default=3, type=int, help="device for training"
)
# 设置你的数据配置的路径,default="../exps/example/custom/yolox_s.py"
parser.add_argument(
"-f",
"--exp_file",
default="../exps/example/custom/yolox_s.py", # 如果出现报错 doesn't contains class named 'Exp', 将此处改为绝对路径即可。
type=str,
help="plz input your expriment description file",
)
# 设置预训练权重路径, default="../weights/yolox_s.pth"
parser.add_argument("-c", "--ckpt", default="../weights/yolox_s.pth", type=str, help="checkpoint file")
终端运行
python tools/train.py
注意:由于我没有放预训练权重文件,并且数据集非常简单,所以精度几乎为零!
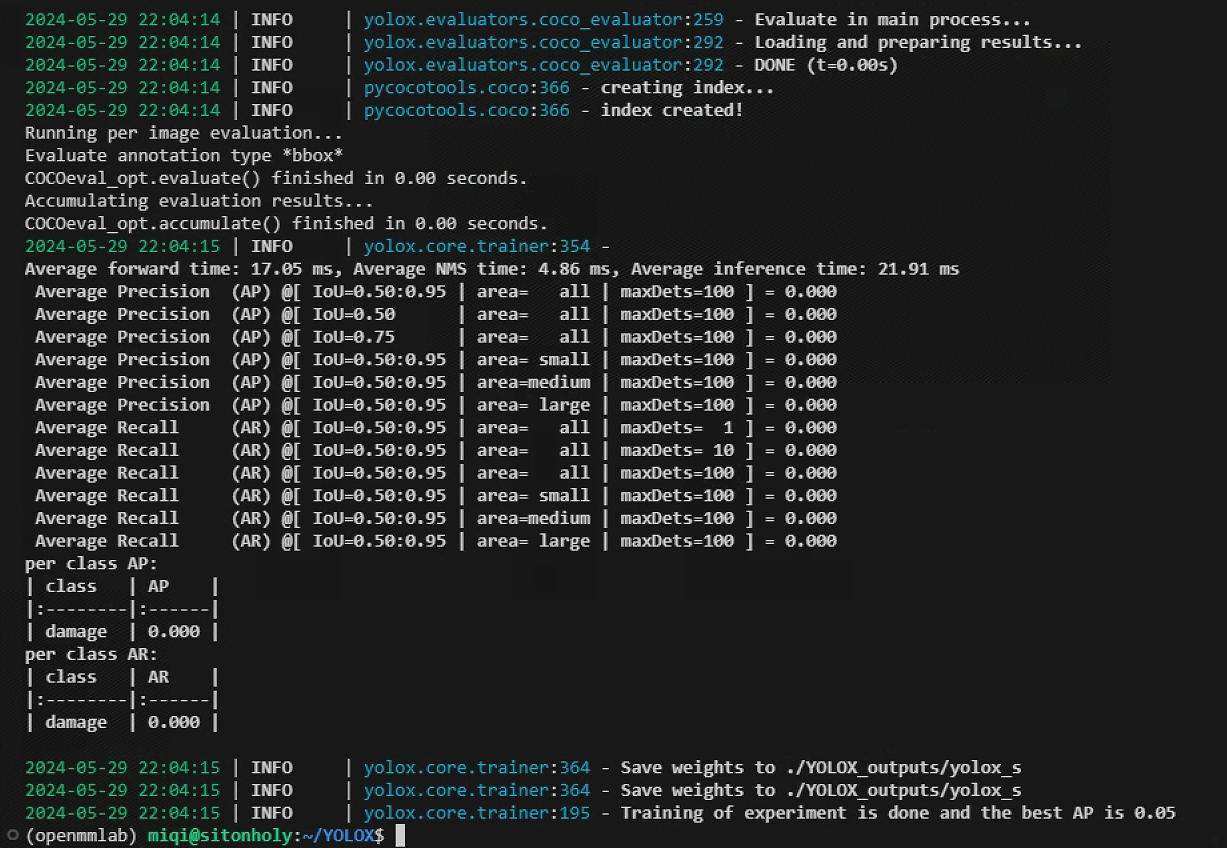
训练得到的权重信息记录在YOLOX/YOLOX_outputs/yolox_s文件夹中
一个值得注意的数据集错误
倘如数据集annotations的图片id包含字母,YOLOX会报错KeyError,建议更换数据集
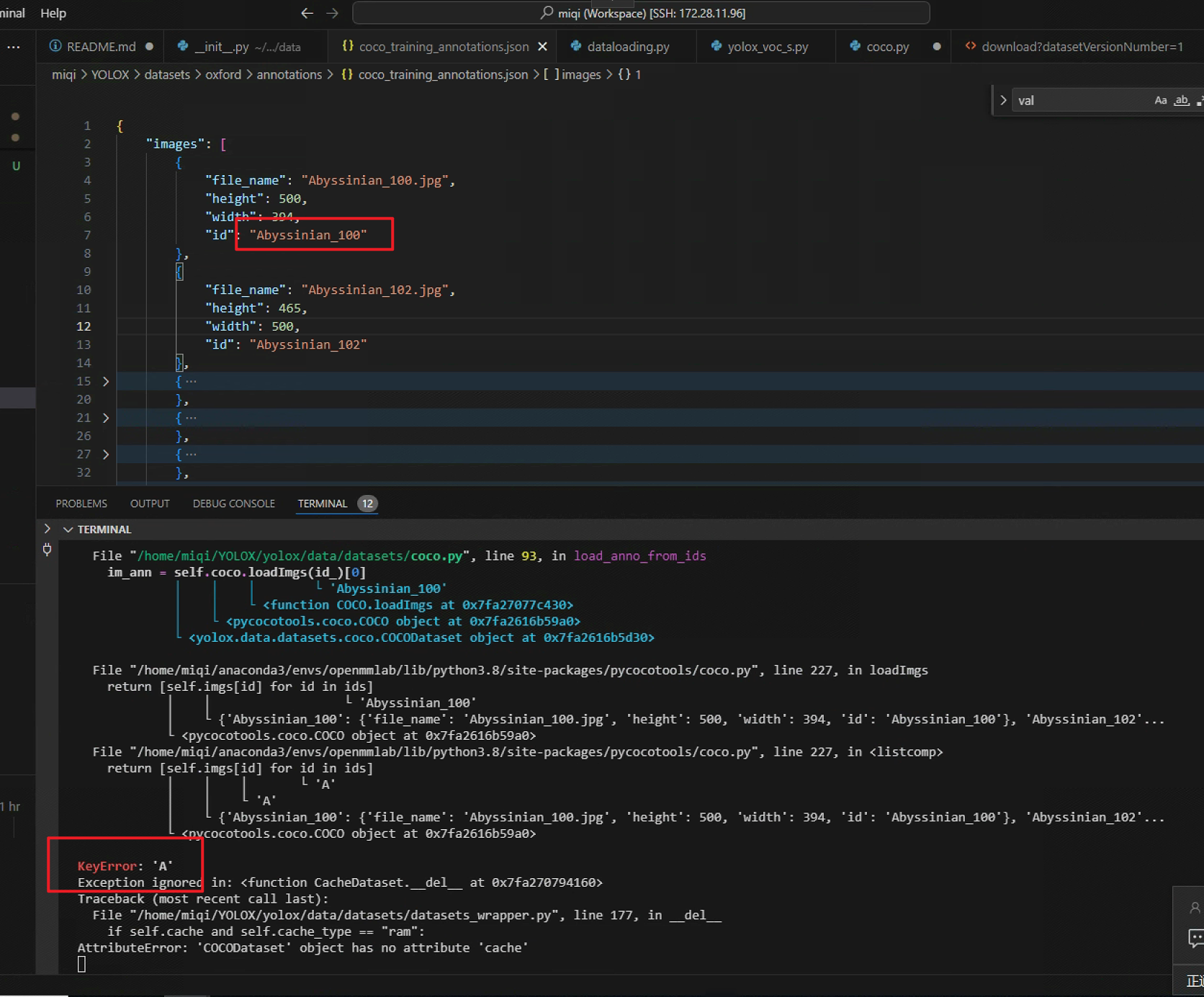
id含有字母的数据集:
{
"file_name": "Abyssinian_100.jpg",
"height": 500,
"width": 394,
"id": "Abyssinian_100"
}
id不含有字母的数据集:
{
"coco_url": "",
"date_captured": "2020-07-14 09:59:34.190485",
"file_name": "75.jpg",
"flickr_url": "",
"height": 1024,
"id": 54,
"license": 1,
"width": 1024
}















 1570
1570











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









