






 本文详细讨论了多元梯度下降算法在涉及多个变量的问题中的应用,强调了特征缩放(如均值归一化)的重要性,学习率的选择策略,以及正则方程(包括正则化)在优化模型和处理矩阵问题中的作用。还介绍了Batch梯度下降的概念以及其优缺点。
本文详细讨论了多元梯度下降算法在涉及多个变量的问题中的应用,强调了特征缩放(如均值归一化)的重要性,学习率的选择策略,以及正则方程(包括正则化)在优化模型和处理矩阵问题中的作用。还介绍了Batch梯度下降的概念以及其优缺点。
4.1 多元梯度下降
通常问题都会涉及到多个变量,例如房屋价格预测就包括,面积、房间个数、楼层、价格等
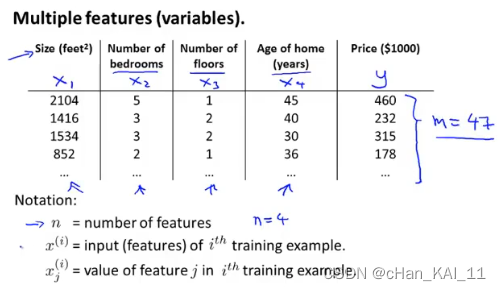
因此代价函数就不再只包含一个变量(为了统一可以对常量引入变量X0=1)

虽然参数的个数增多,但是对每个参数求偏导时和单个参数类似
Gradient Descent:梯度下降

4.3 特征缩放
多个变量的度量不同,数字之间相差的大小也不同,如果可以将所有的特征变量缩放到大致相同范围,这样会大幅度减少梯度算法的迭代。
PS 特征缩放不一定非要落到[-1,1]之间,只要数据足够接近就可以。

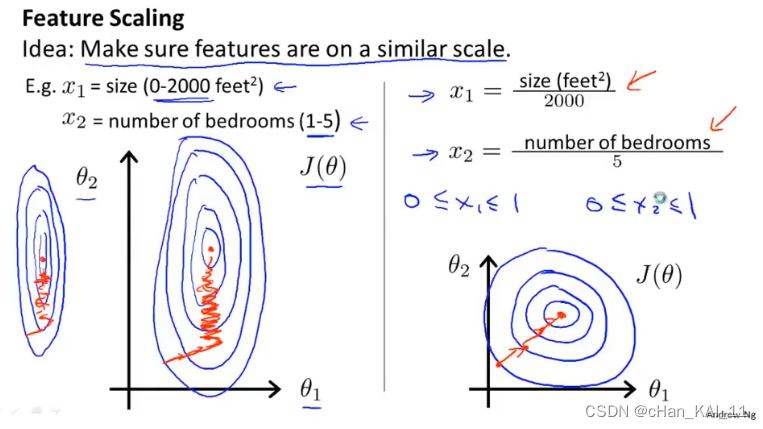

均值归一化

缩放后的还原

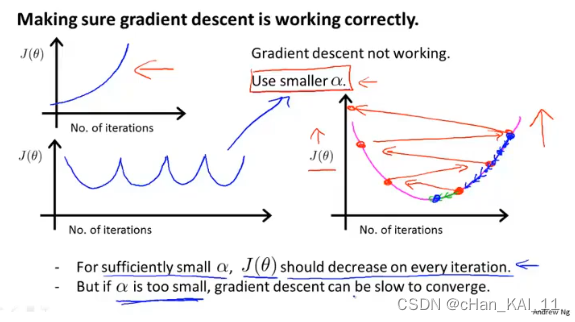
4.4 学习率
学习率𝛼的大小会影响梯度算法的执行,太大可能会导致算法不收敛,太小会增加迭代的次数。
可以画出每次迭代的𝐽(𝜃)的变化,来判断当前算法执行的情况,然后选择合适的学习率。(调参开始…)

Batch梯度下降:每一步梯度下降,都需要遍历整个训练集样本。
4.6 正则方程
偏导等于0对应线性方程的最小值:

利用线性代数的方法直接求解𝜃。
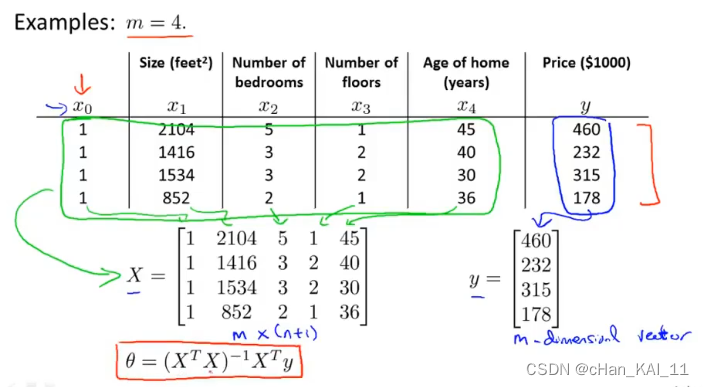
𝜃的推导可以根据等式𝑋𝜃=𝑦得到,的目的是将矩阵转化为方阵,因为求矩阵的逆的前提是方阵。
矩阵可能存在 不可逆的情况,这时可是删除一些不必要的特征,或使用正则化。
梯度下降和正则方程的优缺点:
















 231
231











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









