






1.1 监督学习
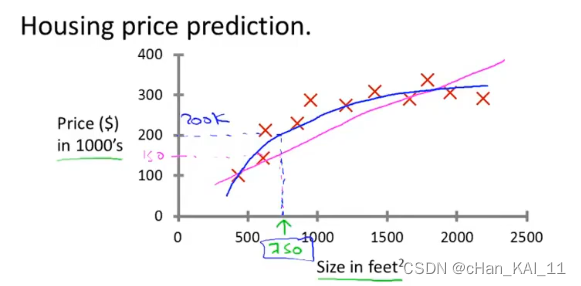
监督学习指 已知数据的label,例如预测房价问题,给出了房子的面积和价格。
回归问题是预测连续值的输出,例如预测房价。
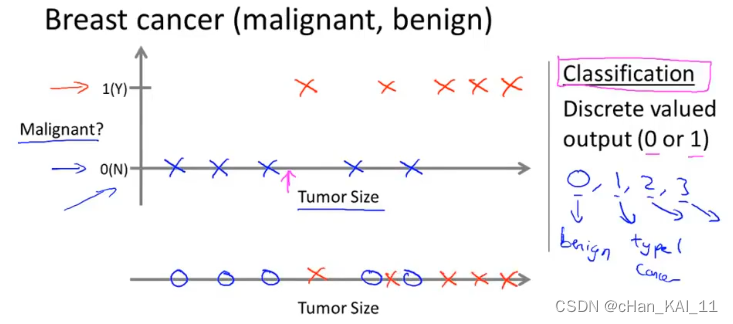
分类问题是预测离散值输出,例如判断肿瘤是良性还是恶性(0,1)。
eg
example of classification and regression problems

1.2 无监督学习
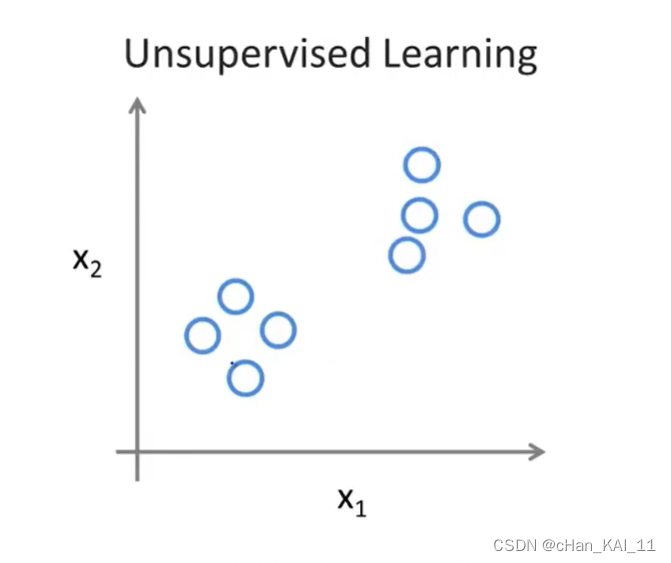
无监督学习是不知道数据具体的含义,比如给定一些数据集但不知道它们具体的信息。对于分类问题无监督学习可以得到多个不同的聚类,从而实现预测的功能。
线性回归
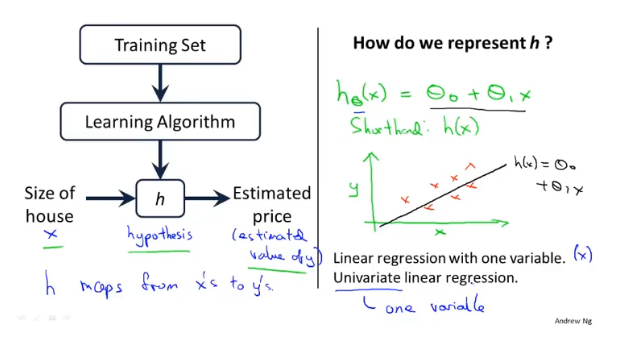
线性回归是拟合一条线,将训练数据尽可能分布到线上。另外还有多变量的线性回归称为多元线性回归。
2.2 代价函数
cost function,一般使用最小均方差来评估参数的好坏。

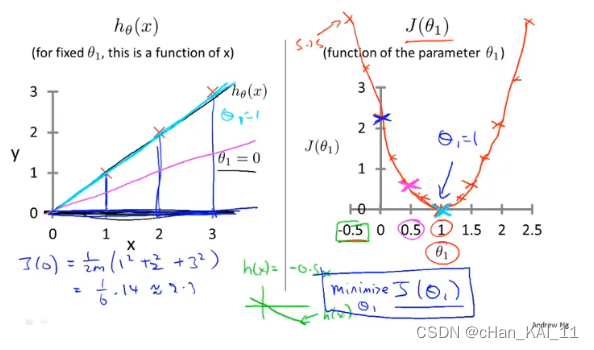
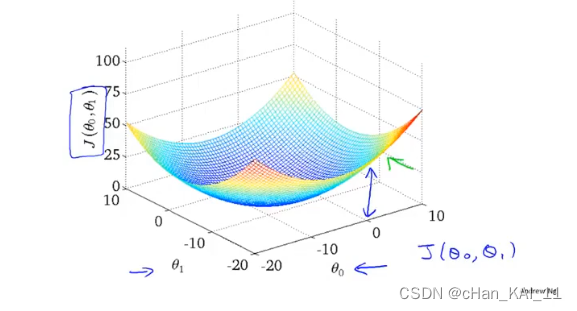
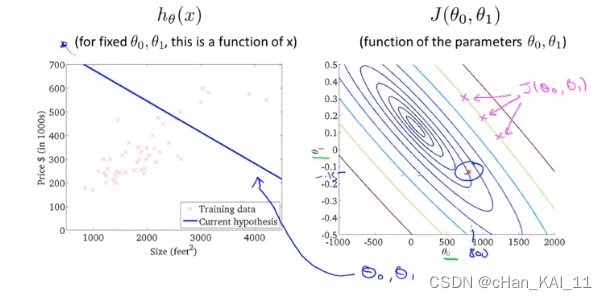
2.5 梯度下降
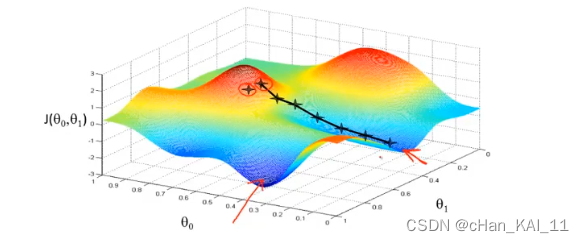
梯度下降,首先为每个参数赋一个初值,通过代价函数的梯度,然后不断地调整参数,最终得到一个局部最优解。初值的不同可能会得到两个不同的结果,即梯度下降不一定得到全局最优解。
梯度下降在具体的执行时,每一次更新需要同时更新所有的参数。

梯度下降公式中有两个部分,学习率(α)和偏导数。
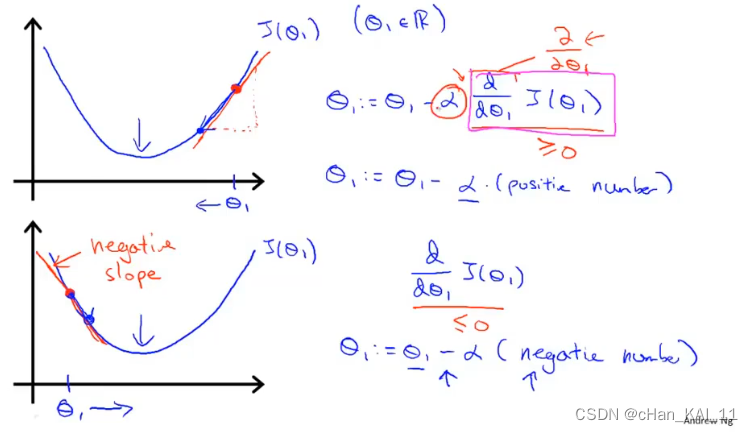
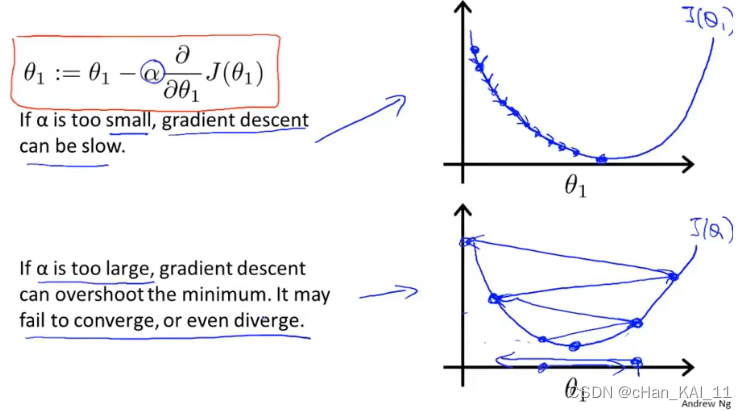
α用来描述学习率,即每次参数更新的步长。α的大小不好确定,如果太小则需要很多步才能收敛,如果太大最后可能不会收敛甚至可能发散。
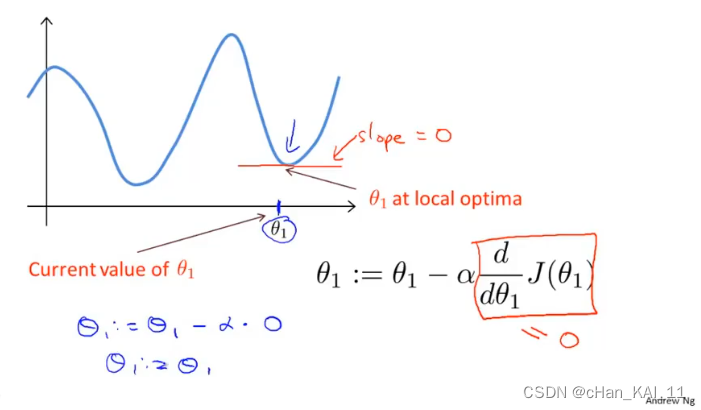
当α处于局部最优解时,α的值将不再更新,因为偏导为0
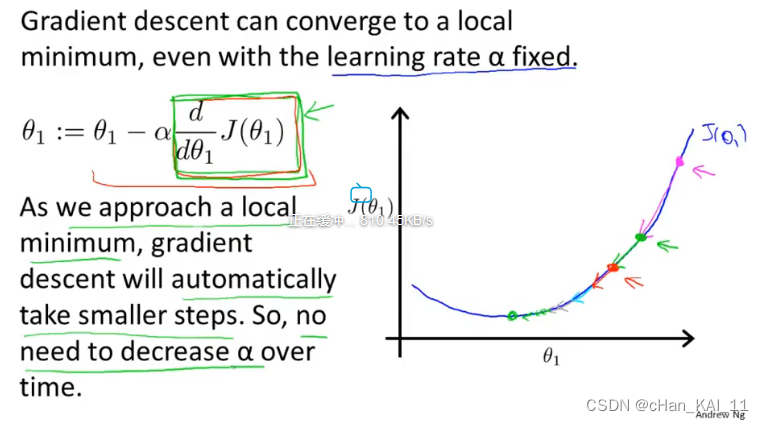
这也说明了如果学习率α不改变,参数也可能收敛,假设偏导>0,因为偏导一直在向在减小,所以每次的步长也会慢慢减小,所以α不需要额外的减小。
单元梯度下降
梯度下降每次更新的都需要进行偏导计算,这个偏导对应线性回归的代价函数。

对代价函数求导的结果为:
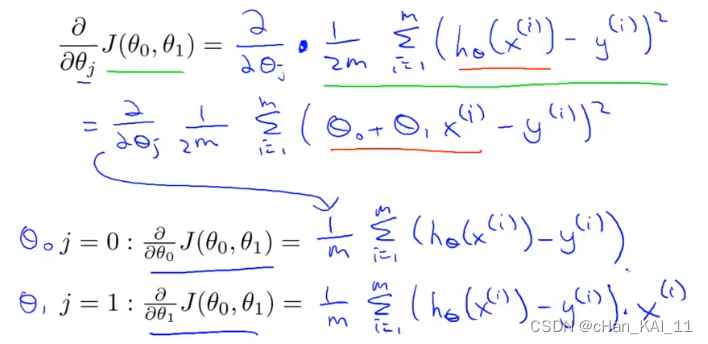
梯度下降的过程容易出现局部最优解
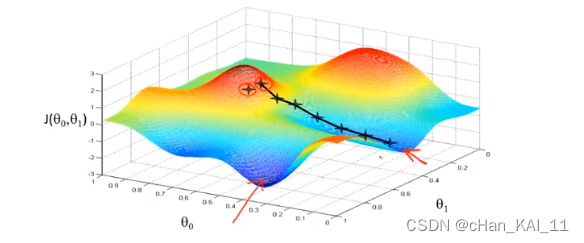
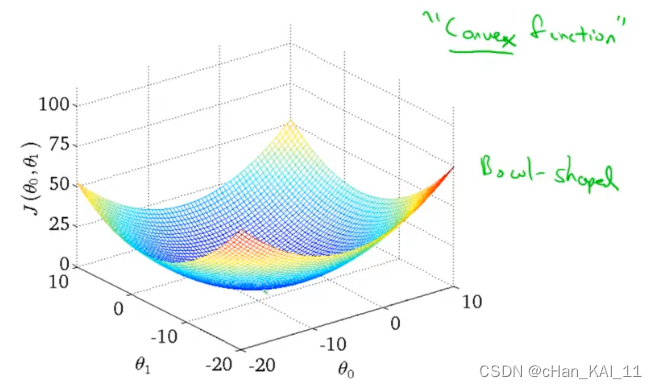
但是线性回归的代价函数,往往是一个凸函数。它总能收敛到全局最优
梯度下降过程的动图展示:
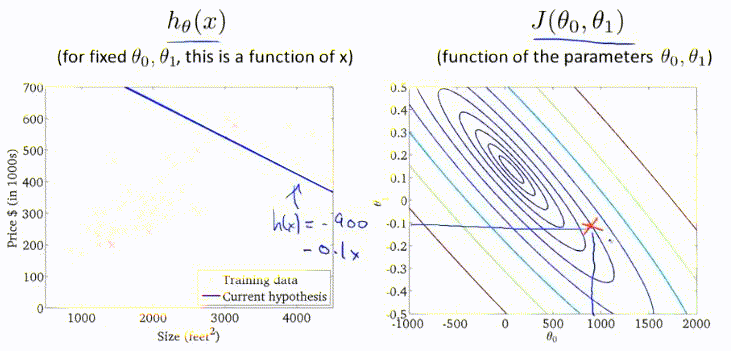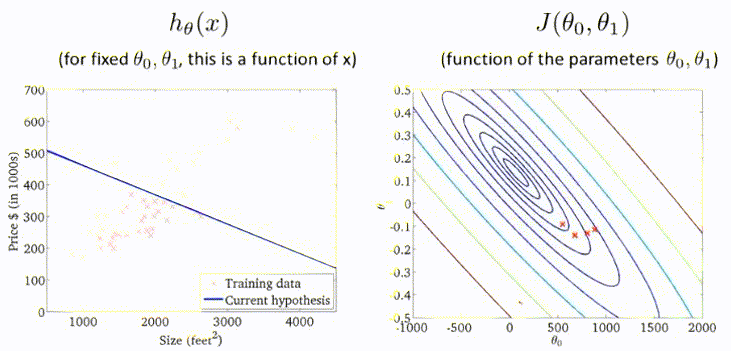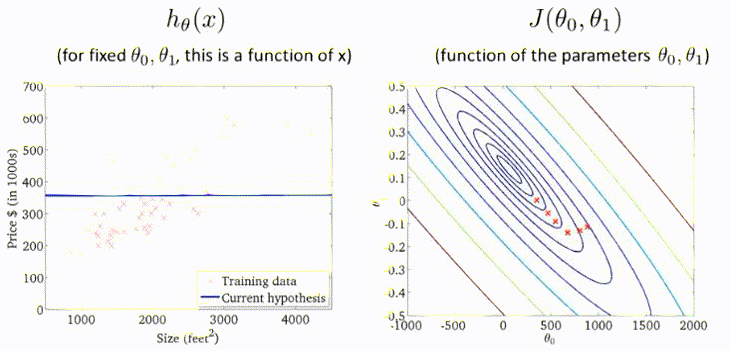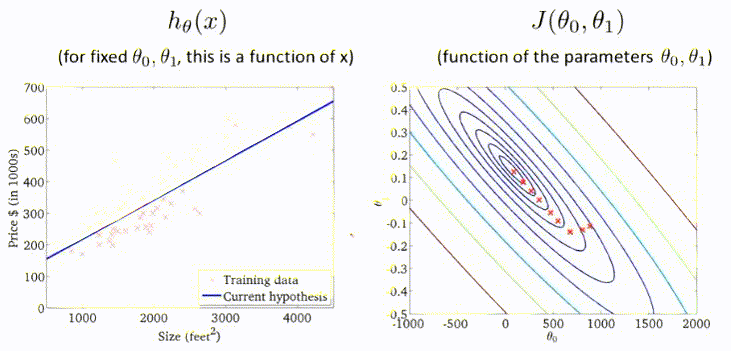















 178
178











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









