






目录
一.SVM算法概念
1.SVM的的学习算法就是求解凸二次规划的最优化算法。SVM学习的基本想法是求解能够正确划分训练数据集并几何间隔最大的分离超平面。对于线性可分的数据集来说,这样的超平面有无穷多个(即感知机),但是几何间隔最大的分离超平面却是唯一的。
2.SVM 将会寻找可以区分两个类别并且能使间隔(margin)最大的划分超平面。比较好的划分超平面,样本局部扰动时对它的影响最小、产生的分类结果最鲁棒、对未见示例的泛化能力最强。
3.对于任意一个超平面,其两侧数据点都距离它有一个最小距离(垂直距离),这两个最小距离的和就是间隔。比如下图中两条虚线构成的带状区域就是 margin,虚线是由距离中央实线最近的两个点所确定出来的(也就是由支持向量决定)。但此时 margin 比较小,如果用第二种方式画,margin 明显变大也更接近我们的目标。

二.SVM算法原理

1.寻找最大间隔
点到超平面的距离公式:
既然这样的直线是存在的,那么我们怎样寻找出这样的直线呢?与二维空间类似,超平面的方程也可以写成一下形式:
有了超平面的表达式之后之后,我们就可以计算样本点到平面的距离了。假设 为样本的中的一个点,其中
为样本的中的一个点,其中 表示为第个特征变量。那么该点到超平面的距离
表示为第个特征变量。那么该点到超平面的距离 就可以用如下公式进行计算:
就可以用如下公式进行计算:
2.目标函数

3.松弛变量
实际中很多样本数据都不能够用一个超平面把数据完全分开。如果数据集中存在噪点的话,那么在求超平的时候就会出现很大问题。从图三中课看出其中一个蓝点偏差太大,如果把它作为支持向量的话所求出来的margin就会比不算入它时要小得多。更糟糕的情况是如果这个蓝点落在了红点之间那么就找不出超平面了。
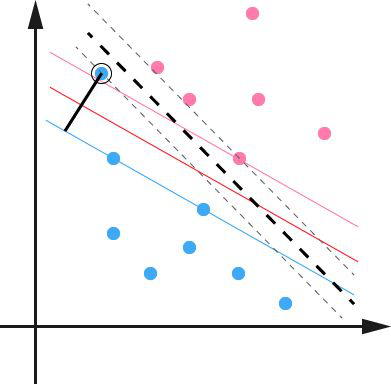
因此引入一个松弛变量ξ来允许一些数据可以处于分隔面错误的一侧。这时新的约束条件变为: 。
。
式中ξi的含义为允许第i个数据点允许偏离的间隔。如果让ξ任意大的话,那么任意的超平面都是符合条件的了。所以在原有目标的基础之上,我们也尽可能的让ξ的总量也尽可能地小。所以新的目标函数变为:


其中的C是用于控制“最大化间隔”和“保证大部分的点的函数间隔都小于1”这两个目标的权重。
三.核函数

如何选择使用哪个 kernel ?
根据先验知识,比如图像分类,通常使用 RBF(高斯径向基核函数),文字不使用 RBF。
尝试不同的 kernel,根据结果准确度而定尝试不同的 kernel,根据结果准确度而定。

1.KNN

2.SVM
















 4162
4162

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









