







引言:
在正文开始之前,首先给大家介绍一个不错的人工智能学习教程:https://www.captainbed.cn/bbs。其中包含了机器学习、深度学习、强化学习等系列教程,感兴趣的读者可以自行查阅。
1. 算法介绍
支持向量机(Support Vector Machine, SVM) 是一种强大的监督学习算法,广泛应用于分类和回归问题。SVM的主要目标是找到一个最优的超平面,将不同类别的数据点分开,同时最大化类别之间的间隔。
SVM的主要特点包括:
- 高效处理高维数据
- 通过核技巧处理非线性问题
- 泛化能力强
- 对异常点具有鲁棒性
2. 算法原理
2.1 线性可分情况
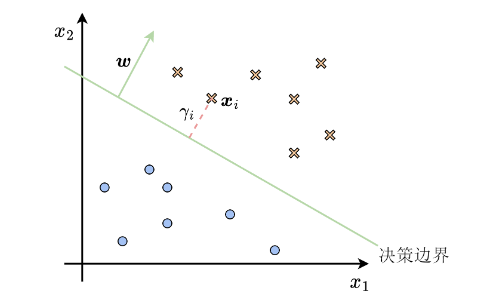
对于线性可分的数据,SVM试图找到一个最优的超平面,使得:
- 正确分类所有训练样本
- 最大化分类间隔(即支持向量到超平面的距离)
数学表达式如下:
最大化:
2
∣
∣
w
∣
∣
\frac{2}{||w||}
∣∣w∣∣2
约束条件:
y
i
(
w
T
x
i
+
b
)
≥
1
,
i
=
1
,
2
,
.
.
.
,
n
y_i(w^Tx_i + b) \geq 1, i=1,2,...,n
yi(wTxi+b)≥1,i=1,2,...,n
其中, w w w是超平面的法向量, b b b是偏置项, x i x_i xi是输入样本, y i y_i yi是类别标签。
2.2 非线性情况
对于非线性可分的数据,SVM使用核技巧将原始特征空间映射到高维空间,在高维空间中寻找线性分类边界。常用的核函数包括:
- 多项式核: K ( x i , x j ) = ( x i T x j + c ) d K(x_i, x_j) = (x_i^T x_j + c)^d K(xi,xj)=(xiTxj+c)d
- 高斯核(RBF): K ( x i , x j ) = e x p ( − γ ∣ ∣ x i − x j ∣ ∣ 2 ) K(x_i, x_j) = exp(-\gamma ||x_i - x_j||^2) K(xi,xj)=exp(−γ∣∣xi−xj∣∣2)
- Sigmoid核: K ( x i , x j ) = t a n h ( a x i T x j + r ) K(x_i, x_j) = tanh(ax_i^T x_j + r) K(xi,xj)=tanh(axiTxj+r)
3. 案例分析: 鸢尾花分类
我们将使用著名的鸢尾花(Iris)数据集来演示SVM的应用。
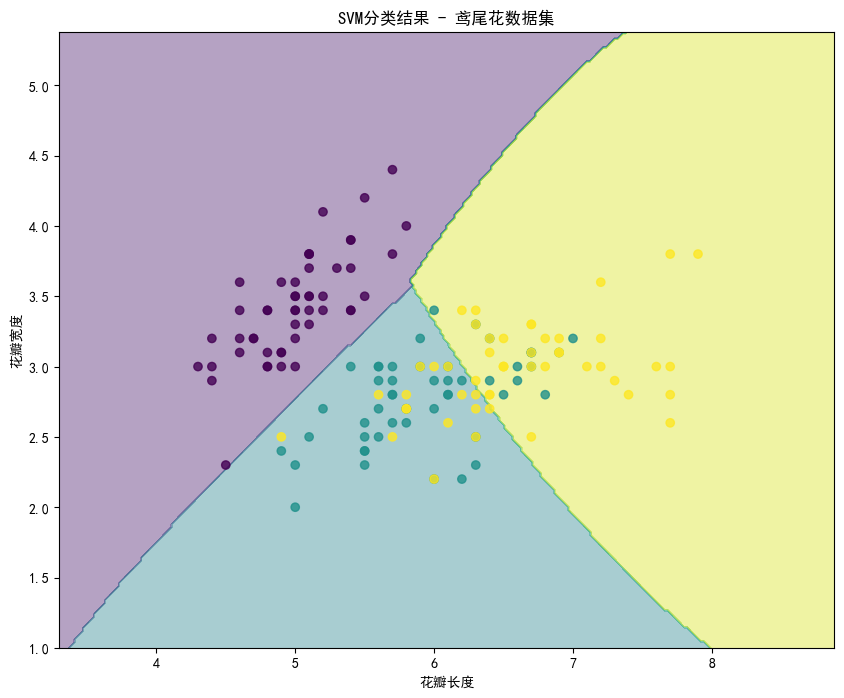
我们使用了鸢尾花数据集中的花瓣长度和宽度作为特征,训练一个SVM分类器来区分三种不同的鸢尾花品种。我们使用RBF核函数,并通过可视化展示SVM的决策边界。
import numpy as np
import matplotlib.pyplot as plt
from sklearn import datasets, svm
from sklearn.model_selection import train_test_split
from sklearn.metrics import roc_curve, auc
from sklearn.preprocessing import label_binarize
from itertools import cycle
# 设置中文字体
plt.rcParams['font.sans-serif'] = ['SimHei'] # 使用黑体
plt.rcParams['axes.unicode_minus'] = False # 解决负号显示问题
# 加载数据
iris = datasets.load_iris()
X = iris.data[:, [0, 1]] # 只使用花瓣长度和宽度
y = iris.target
# 分割训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=42)
# 创建SVM分类器
svm_classifier = svm.SVC(kernel='rbf', C=1.0, gamma='scale', probability=True)
# 训练模型
svm_classifier.fit(X_train, y_train)
# 预测
y_pred = svm_classifier.predict(X_test)
# 计算准确率
accuracy = np.mean(y_pred == y_test)
print(f"准确率: {accuracy:.2f}")
# 可视化决策边界
def plot_decision_boundary(X, y, model, ax=None):
if ax is None:
ax = plt.gca()
x1_min, x1_max = X[:, 0].min() - 1, X[:, 0].max() + 1
x2_min, x2_max = X[:, 1].min() - 1, X[:, 1].max() + 1
xx1, xx2 = np.meshgrid(np.arange(x1_min, x1_max, 0.02),
np.arange(x2_min, x2_max, 0.02))
Z = model.predict(np.c_[xx1.ravel(), xx2.ravel()])
Z = Z.reshape(xx1.shape)
ax.contourf(xx1, xx2, Z, alpha=0.4)
ax.scatter(X[:, 0], X[:, 1], c=y, alpha=0.8)
ax.set_xlabel('花瓣长度')
ax.set_ylabel('花瓣宽度')
return ax
plt.figure(figsize=(10, 8))
plot_decision_boundary(X, y, svm_classifier)
plt.title('SVM分类结果 - 鸢尾花数据集')
plt.show()
运行代码得到分类的准确率为0.8。
绘制分类结果如下:
接下来绘制分类的ROC曲线:
# 绘制ROC曲线
y_test_bin = label_binarize(y_test, classes=[0, 1, 2])
y_score = svm_classifier.predict_proba(X_test)
fpr = dict()
tpr = dict()
roc_auc = dict()
n_classes = 3
for i in range(n_classes):
fpr[i], tpr[i], _ = roc_curve(y_test_bin[:, i], y_score[:, i])
roc_auc[i] = auc(fpr[i], tpr[i])
plt.figure(figsize=(10, 8))
colors = cycle(['blue', 'red', 'green'])
for i, color in zip(range(n_classes), colors):
plt.plot(fpr[i], tpr[i], color=color, lw=2,
label='ROC曲线 (类别 {0}) (AUC = {1:0.2f})'
''.format(i, roc_auc[i]))
plt.plot([0, 1], [0, 1], 'k--', lw=2)
plt.xlim([0.0, 1.0])
plt.ylim([0.0, 1.05])
plt.xlabel('假正例率')
plt.ylabel('真正例率')
plt.title('多类别ROC曲线')
plt.legend(loc="lower right")
plt.show()
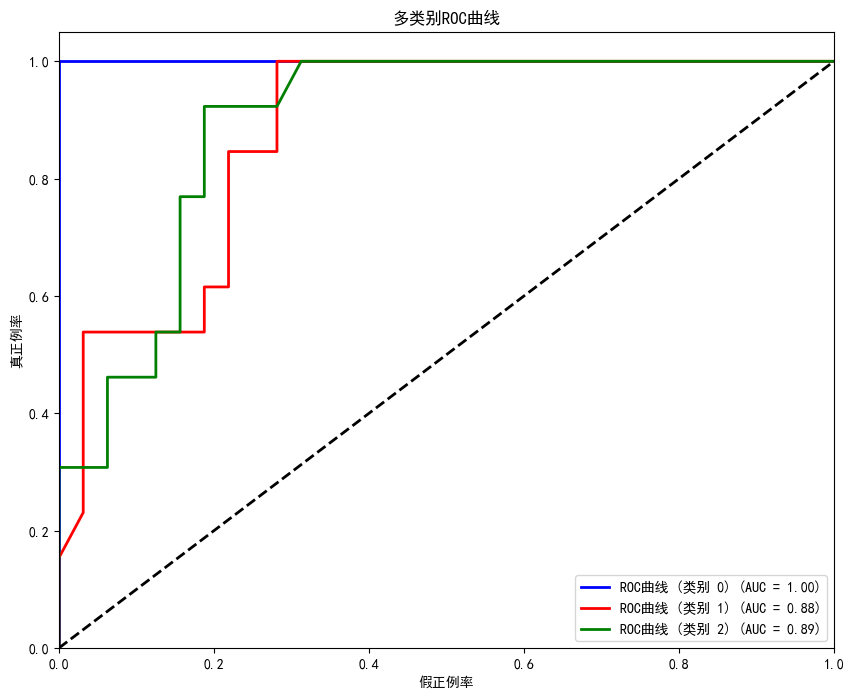
通过这个案例,我们可以看到SVM在多类别分类问题上的应用,以及它处理非线性决策边界的能力。SVM成功地将三种鸢尾花品种分开,并在测试集上取得了较高的准确率。
4. 总结
支持向量机是一种强大而灵活的机器学习算法,特别适合处理复杂的分类问题。通过核技巧,SVM可以有效地处理高维数据和非线性问题。然而,SVM也有一些局限性,如对大规模数据集的训练时间较长,以及核函数的选择和参数调优可能比较复杂。因此,在使用SVM时,需要根据具体问题和数据特点来权衡其优缺点。



















 5万+
5万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











