







作者名片
🤵♂️ 个人主页:@抱抱宝
😄微信公众号:宝宝数模AI
✍🏻作者简介:阿里云专家博主 | 持续分享机器学习、数学建模、数据分析、AI人工智能领域相关知识,和大家一起进步!
🐋 如果文章对你有帮助的话,
欢迎👍🏻点赞📂收藏 +关注
一、引言
强化学习(Reinforcement Learning, RL)是机器学习的一个重要分支,强调通过与环境的交互来学习行为策略。在强化学习中,智能体通过执行动作获得奖励或惩罚,并不断调整策略以最大化累计奖励。课程学习(Curriculum Learning)作为一种方法,旨在通过逐步增加任务的难度,帮助智能体更有效地学习。
本文将详细介绍强化学习中的课程学习算法原理,并结合具体案例进行分析,帮助读者理解课程学习的应用和实现方法。
二、课程学习算法介绍
课程学习是一种有计划的学习方法,模拟人类学习的过程。它通过设置逐步增加难度的任务序列,让学习系统从简单的任务开始,逐渐过渡到复杂任务。这一方法可以显著提高训练效率,避免智能体一开始就面临过于复杂的任务,从而导致学习过程困难。
课程学习可以分为两种基本策略:
- 逐步难度增加:从简单的任务开始,逐步增加任务的难度,直到智能体能够解决最复杂的任务。
- 动态调整:根据智能体的学习进展,动态调整任务的难度,保证学习的过程始终处于一个适当的挑战性范围。
课程学习可以在多个领域得到应用,尤其是在强化学习中,智能体在学习复杂任务时,常常面临训练难度过大的问题。通过课程学习,可以有效缓解这一问题。
三、算法原理
课程学习的核心思想是通过设置一个合适的任务难度序列,使得智能体能够逐步积累经验,从而更容易地学习到有效的策略。在强化学习中,通常需要解决的任务包括以下几个要素:
- 状态空间:表示智能体所处的所有可能状态。
- 动作空间:表示智能体可以采取的所有动作。
- 奖励函数:表示智能体在每个状态下采取某一动作后,所获得的即时奖励。
- 策略:表示智能体在不同状态下采取的行动规则。
在课程学习中,任务难度的增加通常体现在状态空间、动作空间的复杂度上。例如,最初可能让智能体在简单环境中训练,逐步过渡到更复杂的环境,直到智能体能够处理高维度的状态空间和动作空间。
假设我们有一个强化学习问题,其中智能体的行为策略为 π \pi π,状态为 s s s,动作为 a a a,奖励为 r r r。智能体的目标是通过学习最优策略 π ∗ \pi^* π∗,最大化从初始状态开始的期望累积奖励。强化学习的核心目标是通过更新策略来最大化累计奖励,通常使用Q-learning算法。
四、案例分析:迷宫寻路任务
让我们通过一个迷宫寻路的实例来说明课程学习的应用。
3.1 任务设计
我们设计一个渐进式的训练课程:
- 简单迷宫:2×2格子,无障碍物
- 中等迷宫:4×4格子,少量障碍物
- 复杂迷宫:8×8格子,多个障碍物
通过这种设计,智能体可以从最简单的环境开始,逐步适应更复杂的任务,从而提高学习效率和最终的策略表现。在本案例中,我们使用DQN算法实现。
3.2 部分代码
class Visualization:
def __init__(self):
plt.style.use('default')
# 设置中文字体
try:
# Windows系统
plt.rcParams['font.sans-serif'] = ['SimHei'] # 黑体
plt.rcParams['axes.unicode_minus'] = False # 解决负号显示问题
except:
# Linux/MacOS系统
plt.rcParams['font.sans-serif'] = ['Arial Unicode MS']
def plot_rewards(self, rewards_history, level):
plt.figure(figsize=(10, 5))
window_size = 50
moving_avg = np.convolve(
rewards_history,
np.ones(window_size)/window_size,
mode='valid'
)
episodes = range(len(rewards_history))
plt.plot(episodes, rewards_history, 'b-', alpha=0.3, label='原始奖励')
plt.plot(
range(window_size-1, len(rewards_history)),
moving_avg,
'r-',
label='移动平均'
)
plt.title(f'第{level+1}级难度训练奖励曲线')
plt.xlabel('回合数')
plt.ylabel('奖励')
plt.legend()
plt.grid(True, linestyle='--', alpha=0.7)
plt.show()
def visualize_path(self, env, agent, level):
state = env.reset()
done = False
path = [env.agent_pos.copy()]
while not done:
flat_state = state.flatten()
action = agent.select_action(flat_state)
state, _, done, _ = env.step(action)
path.append(env.agent_pos.copy())
plt.figure(figsize=(8, 8))
maze_map = env.maze.copy()
plt.imshow(maze_map, cmap='Greys')
path = np.array(path)
plt.plot(path[:, 1], path[:, 0], 'r-', linewidth=2, label='智能体路径')
plt.plot(path[:, 1], path[:, 0], 'r.', markersize=10)
plt.plot(0, 0, 'go', markersize=15, label='起点')
plt.plot(env.size-1, env.size-1, 'ro', markersize=15, label='终点')
plt.grid(True, linestyle='--', alpha=0.7)
plt.title(f'第{level+1}级难度迷宫路径')
plt.legend()
plt.show()
3.3训练结果
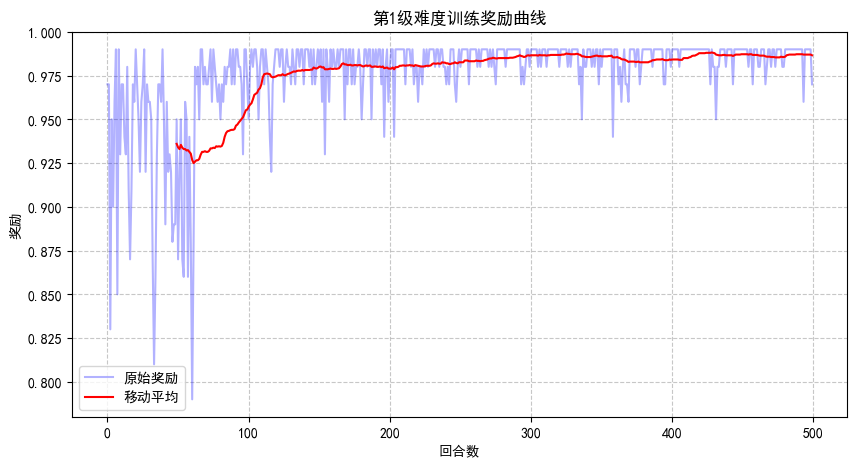
开始训练第1级难度...
Episode 50, 平均奖励: 0.94, Epsilon: 0.74
Episode 100, 平均奖励: 0.96, Epsilon: 0.56
Episode 150, 平均奖励: 0.98, Epsilon: 0.48
Episode 200, 平均奖励: 0.98, Epsilon: 0.41
Episode 250, 平均奖励: 0.98, Epsilon: 0.36
Episode 300, 平均奖励: 0.99, Epsilon: 0.32
Episode 350, 平均奖励: 0.99, Epsilon: 0.28
Episode 400, 平均奖励: 0.98, Epsilon: 0.25
Episode 450, 平均奖励: 0.99, Epsilon: 0.22
Episode 500, 平均奖励: 0.99, Epsilon: 0.20
第1级难度训练完成!正在生成可视化...
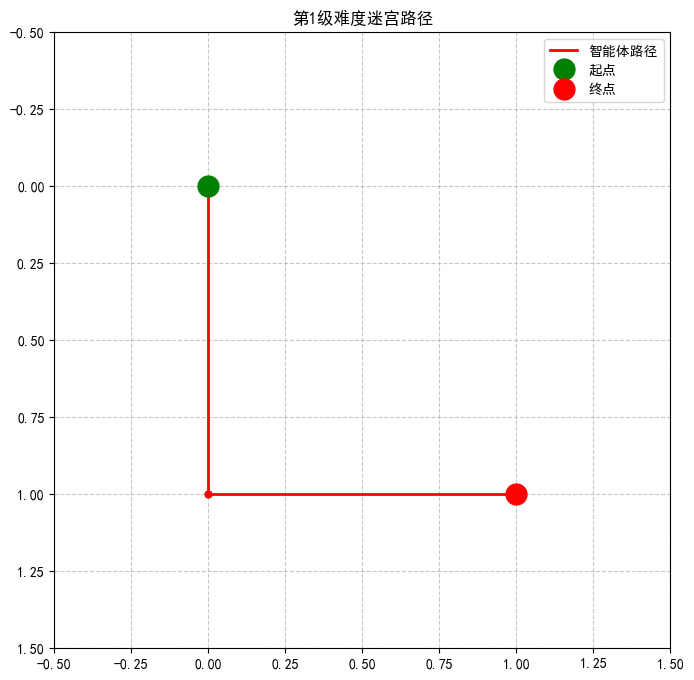
开始训练第2级难度...
Episode 50, 平均奖励: 0.41, Epsilon: 0.13
Episode 100, 平均奖励: -0.01, Epsilon: 0.01
Episode 150, 平均奖励: 0.40, Epsilon: 0.01
Episode 200, 平均奖励: 0.59, Epsilon: 0.01
Episode 250, 平均奖励: 0.93, Epsilon: 0.01
Episode 300, 平均奖励: 0.94, Epsilon: 0.01
Episode 350, 平均奖励: 0.95, Epsilon: 0.01
Episode 400, 平均奖励: 0.95, Epsilon: 0.01
Episode 450, 平均奖励: 0.95, Epsilon: 0.01
Episode 500, 平均奖励: 0.95, Epsilon: 0.01
第2级难度训练完成!正在生成可视化...

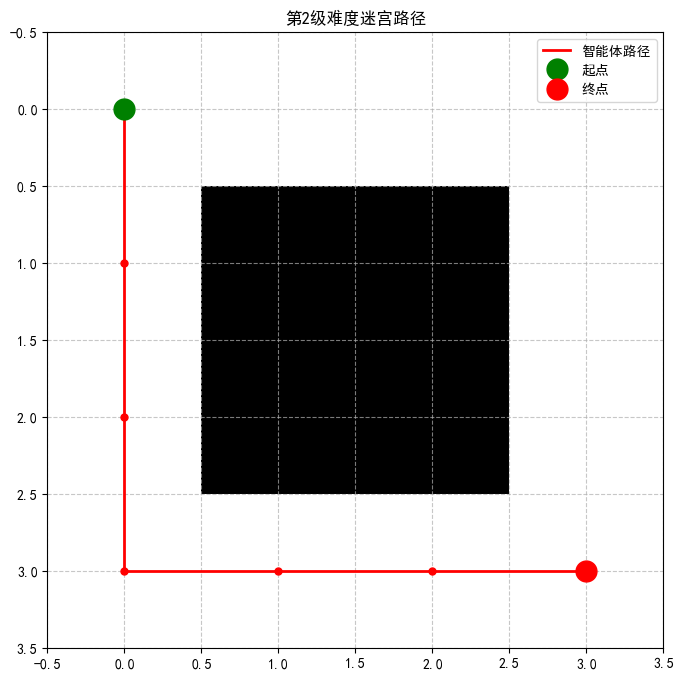
开始训练第3级难度...
Episode 50, 平均奖励: -0.50, Epsilon: 0.02
Episode 100, 平均奖励: -0.81, Epsilon: 0.01
Episode 150, 平均奖励: -0.92, Epsilon: 0.01
Episode 200, 平均奖励: -0.97, Epsilon: 0.01
Episode 250, 平均奖励: -0.69, Epsilon: 0.01
Episode 300, 平均奖励: -0.47, Epsilon: 0.01
Episode 350, 平均奖励: -0.24, Epsilon: 0.01
Episode 400, 平均奖励: -0.20, Epsilon: 0.01
Episode 450, 平均奖励: 0.48, Epsilon: 0.01
Episode 500, 平均奖励: 0.53, Epsilon: 0.01
第3级难度训练完成!正在生成可视化...

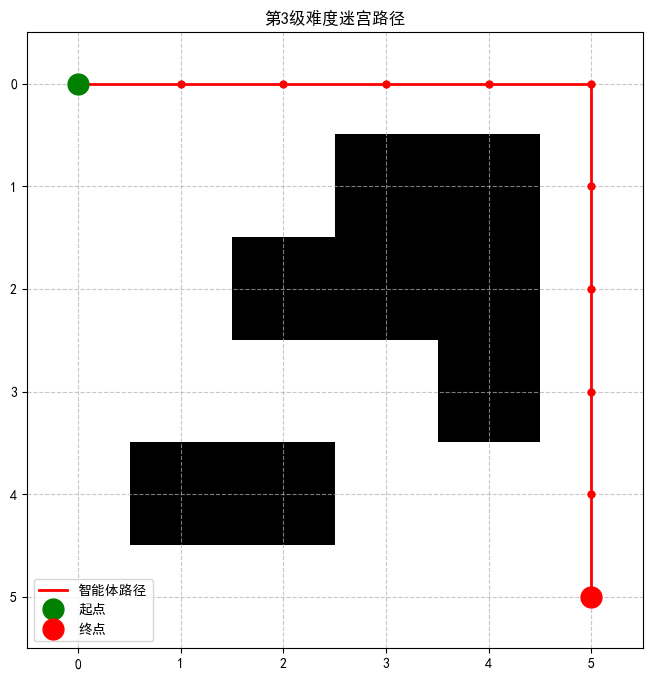
五、结论
通过上述案例分析,我们展示了如何在强化学习中应用课程学习策略。通过逐步增加任务的难度,我们能够帮助智能体更有效地学习和解决问题。课程学习不仅能够加速训练过程,还能提升智能体在复杂任务中的表现。
最后
更多人工智能相关内容可参考:https://www.captainbed.cn/bbs。其中包含了机器学习、深度学习、强化学习等系列教程,感兴趣的读者可以自行查阅。


















 1579
1579

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











