






《人类在有难度调整的课程强化学习中的决策制定》
###
最近在搞教育宝,想把这玩意弄个论文写写,看了一下思路觉得强化学习是一个很不错的思路,所以读几篇关于强化学习+大模型+教育的论文看看有没有思考点。
###
老规矩,先用gpt搞个大纲
1. 问题陈述
-
传统课程强化学习(Curriculum Reinforcement Learning, RL)难以根据人类偏好调整任务难度,影响学习效果。
-
现有的自动课程学习方法缺乏可解释性和适应性,在需要人机交互的实际应用中效果有限。
-
该论文提出了一种人机互动的方法,使用户可以通过反馈动态调整任务难度,以引导强化学习智能体。
2. 挑战
-
自动课程学习的惯性问题:当任务难度突然增加时,智能体难以适应,导致性能下降。
-
稀疏奖励环境:许多强化学习任务的奖励信号较少,使得智能体难以学习有效策略。
-
泛化能力和过拟合问题:传统的自动课程学习方法往往过拟合特定的学习模式,限制了智能体对新任务或更复杂环境的适应能力。
3. 论文解决方案如何应对挑战
-
克服惯性问题:交互式课程学习允许用户动态调整任务难度,避免学习停滞。
-
应对稀疏奖励:系统采用逐步调整难度的方法,确保智能体不会过早面对极端复杂的任务,提高学习效率。
-
增强泛化能力:通过人类反馈,减少智能体对固定学习模式的依赖,帮助其构建可迁移的技能。
4. 解决方案概述
-
开发一个交互式、实时的强化学习平台,让人类用户能够引导课程难度。
-
设计一个训练循环,用户可以根据智能体的表现动态修改任务难度,防止自动课程学习中常见的过拟合问题。
-
在三个具有挑战性的强化学习环境中测试和验证该方法的有效性。
5. 系统建模
-
数学表示:
-
强化学习智能体与环境交互,以最大化累积奖励。
-
任务难度是一个可以由用户手动调整的函数。
-
课程学习按照逐步增加难度的顺序进行,用户可以基于智能体的表现调整参数。
-
-
相关图表:图 2(展示了交互式平台的整体设计)。
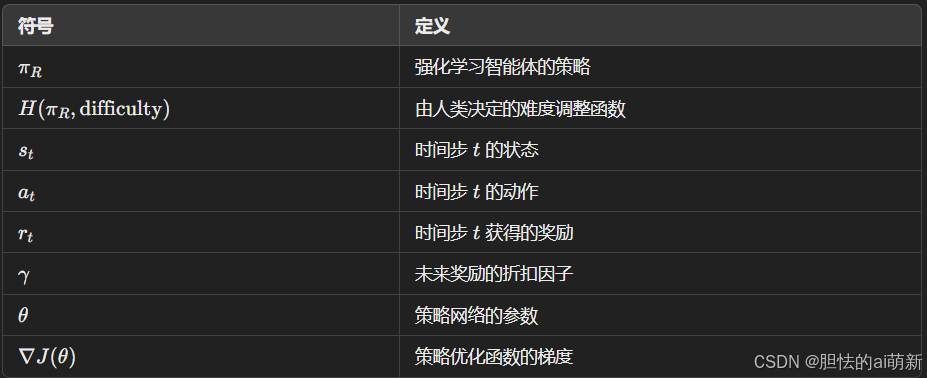
6. 论文中的符号表示
7. 设计
-
问题表述:将强化学习任务建模为具有可调整课程参数的人机交互过程。
-
决策变量:
-
训练过程中每一步的任务难度。
-
基于人类反馈的智能体策略更新方式。
-
-
相关图表:图 4(展示了交互式平台,用户可手动调整任务难度)。
8. 解决方案
-
决策变量的确定:
-
智能体使用**PPO(Proximal Policy Optimization,近端策略优化)**方法进行策略更新。
-
难度水平 由人类函数 HH 调整,并在固定的时间间隔内执行。
-
论文中的 算法 1 详细描述了交互式课程学习框架:
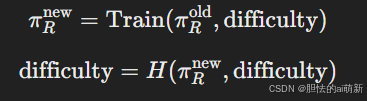
-
9. 论文中的定理
-
论文未明确提出数学定理,但通过实验分析,证明了人机互动课程学习比自动课程学习更有效。
10. 设计流程
-
初始化强化学习智能体,设定初始难度为 0。
-
训练智能体一段时间。
-
定期评估智能体的学习情况。
-
根据人类反馈调整任务难度。
-
重复上述过程,直到训练完成。
11. 仿真实验
-
验证内容:
-
交互式课程学习是否能有效帮助强化学习智能体适应复杂任务。
-
交互式课程 VS 自动课程的性能对比。
-
训练后的智能体是否具有更强的泛化能力。
-
-
关键结果:
-
交互式课程学习训练的智能体比从零开始训练的智能体表现更优。
-
交互式课程有效避免了过拟合,提高了智能体的适应能力。
-
由于并行化设计,训练时间显著减少。
-
12. 讨论(局限性与未来研究方向)
-
局限性:
-
由于用户样本量有限,研究结论的推广性可能受限。
-
在大规模部署时,环境计算资源需求较高。
-
-
未来工作:
-
开发自动化方法,从用户行为中推测人类决策过程,以减少人工干预。
-
提高系统的可扩展性,使其适用于更广泛的强化学习应用场景。
-
一. 摘要
以人为本的人工智能考虑的是人类对人工智能性能的体验。虽然已有大量研究通过全自动学习或弱监督学习帮助人工智能实现超人性能,但较少有人尝试人工智能如何在细粒度输入的情况下根据人类偏好的技能水平进行定制。在这项工作中,我们通过学习人类的决策过程,引导课程强化学习结果达到既不太难也不太容易的首选性能水平。为此,我们开发了一个便携式交互平台,用户可以通过操作任务难度、观察表现和提供课程反馈与代理进行在线交互。我们的系统具有高度可并行性,使人类在没有服务器的情况下训练需要数百万样本的大规模强化学习应用成为可能。研究结果证明了人在回路中的交互式强化学习课程的有效性。它表明,强化学习的性能可以成功地与人类期望的难度水平同步调整。我们相信,这项研究将为实现流动和个性化自适应困难打开新的大门。
二. introducion
- 课程(curriculum)通过逐步掌握更复杂的技能和知识,以螺旋上升的方式组织学习过程[1]。当与强化学习相结合时,已经证明课程可以改善收敛或性能,相比从头开始学习目标任务[2]-[4]。因此,将更快地进行更精细的调整。
- 先前的工作[1]、[5]侧重于通过自动提出课程来利用课程策略的优势,以训练表现最佳的AI代理,例如通过另一个RL代理,如教师-学生框架[6]、[7]、自我游戏[8]-[10]或目标-gan [5]
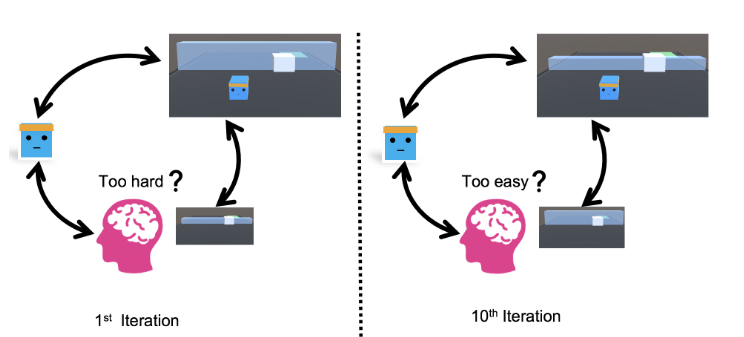
图1:在课程训练期间,给定特定场景,人类可以通过观察代理能够取得的进展来适应性地决定是“友好”还是“对抗”。在性能下降的情况下,用户可以灵活地调整策略,而不是自动辅助代理。
在图1中,用户能够直观地了解学习进度,并通过改变墙的高度来动态操纵任务难度。
给出本文的动机:
- 人类在面对不同的情景时,具有即兴发挥和适应的天赋能力, 为了设计更个性化的体验,我们必须捕捉这些人类指示,以帮助课程强化学习的可解释性和灵活性。
- 辅助代理,如自动驾驶系统、基于语言的虚拟系统和机器人伴侣。该代理应提供根据人类偏好和个人需求调整的服务[13]。
三. RELATED WORK
Curriculum Reinforcement Learning课程强化学习
N. Heess, D. TB, S. Sriram, J. Lemmon, J. Merel, G. Wayne, Y. Tassa, T. Erez, Z. Wang, S. Eslami et al., “Emergence of locomotion behaviours in rich environments,” arXiv preprint arXiv:1707.02286, 2017.从经验上展示了丰富的环境如何在没有明确奖励的情况下促进复杂行为的学习
我们:利用人类归纳偏见来设计课程,从而发展环境。
Human-in-the-Loop Reinforcement Learning人类回路强化学习
- 大量工作侧重于模仿学习 [15]–[18],其中专家的演示作为直接监督。
- 人类也可以仅通过正或负奖励信号[19]来交互式地塑造训练,或者将手动反馈与MDP的奖励相结合[20],[21]。
我们:旨在通过研究交互式课程对强化学习的影响来弥合这两个领域之间的差距。
两个领域:通过正或负奖励信号[19]来交互式地塑造训练以及手动反馈与MDP的奖励相结合
四. INTERACTIVE CURRICULUM GUIDED BY HUMAN
Interactive Platform交互式平台
三个目标:
1)实时在线交互具有灵活性;
2)可并行化用于人机交互训练
3)强化学习和人类指导课程之间无缝控制。
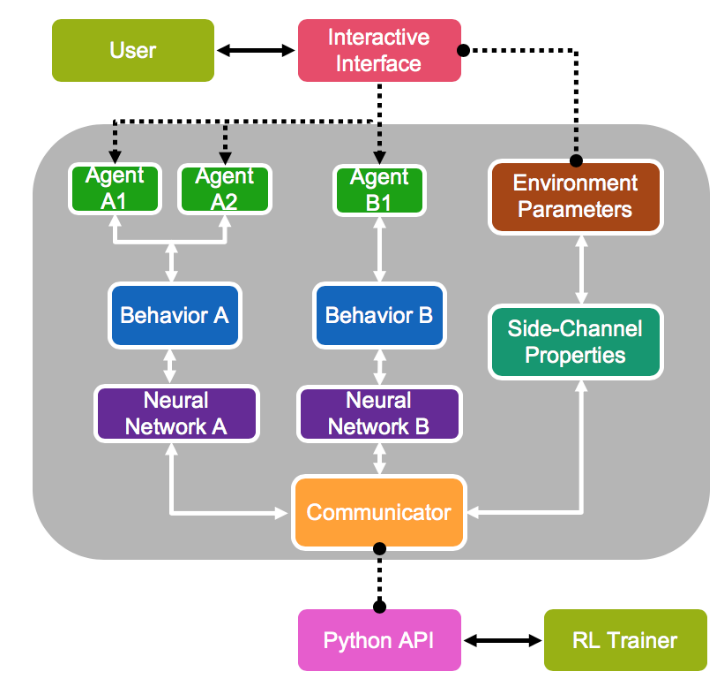
图2:我们交互平台的总体设计,以及环境容器与RL训练器和交互界面之间的关联。
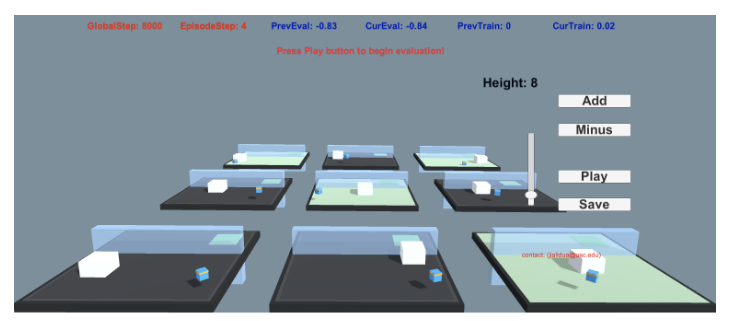 图3:我们并行交互式平台培训的示例。
图3:我们并行交互式平台培训的示例。
- 我们运行一个与训练过程分离的事件驱动环境容器来实现第一个目标,允许用户通过交互界面在训练期间向环境发送控制信号(例如,UI 控制、场景布局、任务难度)。
- 框架如图2所示,以解释用户、环境和训练算法的位置。我们将人机交互信号集成到RL并行化中,以实现与自动训练相似的效率。图3显示了并行训练的一个示例。
- 我们执行集中式 SGD 更新,同时进行分散式经验收集,因为相同类型的代理共享相同的网络策略 [24]。
- 我们还通过统一的交互界面同时控制不同实例中的环境参数,使其能够解决需要数百万次交互的任务。
- 对于第三个目标,我们在设计课程时显示实时指令,并允许用户检查学习进度。
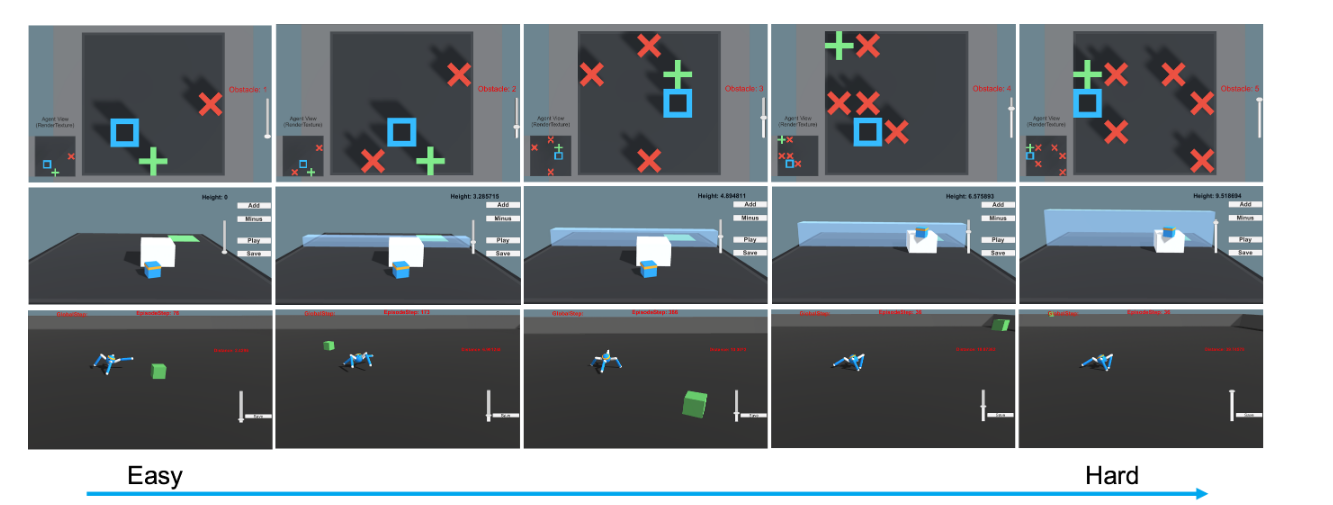
图4我们的课程强化学习交互式平台允许用户通过统一的界面(滑块和按钮)来操纵任务难度。所有三个任务都只获得稀疏奖励。这三个环境的可操作变量分别是红色障碍物的数量(GridWorld,顶部行)、墙的高度(Wall-Jumper,中间行)和目标的半径(SparseCrawler,底部行)。任务难度从左到右逐渐增加。
图4显示了我们发布的课程强化学习环境,用户可以操纵任务难度。代理将在GridWorld中到达绿色目标,在Wall-Jumper中导航到绿色垫子上着陆,并在SparseCrawler中到达动态绿色盒子。如图4所示,用户以既不太难也不太容易的方式制定了课程,以便最大化效率和质量的权衡。在交互过程中,用户可以暂停、播放或保存当前配置。竞技场中物体的位置可以通过光标自定义,墙壁的高度可以根据难度转换进行调整。
我们的交互界面与下面列出的其余环境相同(本文要解决的三项竞争性挑战任务 ):
Grid-World
代理(表示为蓝色方块)的任务是通过导航障碍物(红色十字,最多5个)到达目标位置(绿色加号)。所有对象都随机生成在二维平面上。达到目标的正奖励为1,交叉的负奖励为1,每一步的负奖励为-0.01。移动方向为主方向。
Wall-Jumper
目标是通过跳跃或(可能)利用一个方块(白色盒子)来导航一堵墙(最大高度为8)。成功降落在目标位置(绿色垫子)上获得1分的正奖励,或者跌落到外面或达到允许的最大时间则获得-1分的负奖励。每走一步都会受到-0.0005的惩罚。观察空间是74维的,对应于每个检测到4个可能对象的14个射线投射,加上代理的全局位置以及代理是否接地。允许的动作包括平移、旋转和跳跃。
Sparse-Crawler
爬行器是一个有4条手臂和4条前臂的代理。目标是到达地面上随机位置的目标(最大半径为40)。状态是一个由117个变量组成的向量,对应于每个肢体的位置、旋转、速度和角速度,以及身体的加速度和角加速度。动作空间的大小为20,对应于关节的目标旋转。只有在达到目标时才提供稀疏奖励。
A Simple Interactive Curriculum Framework
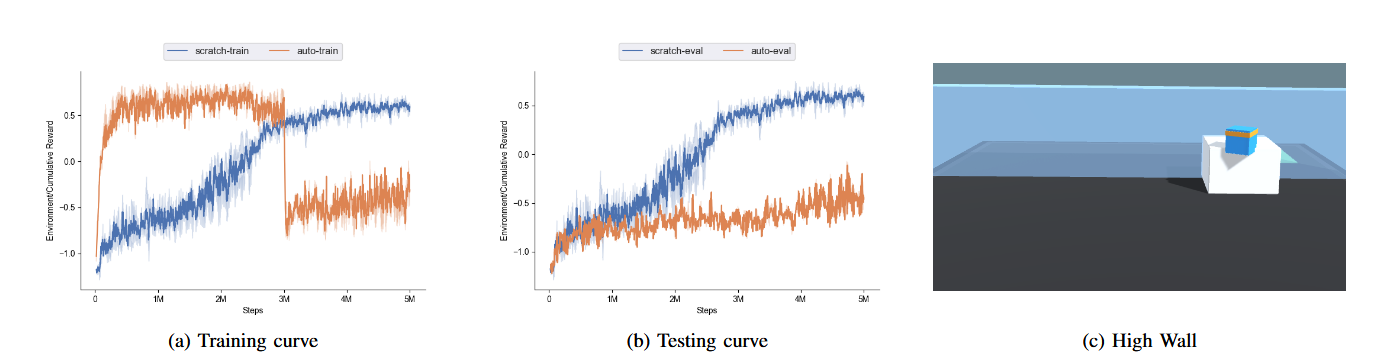
图5:“惯性”问题的自动课程在固定间隔内逐渐增加难度。当导航需要先跳过盒子时,自动课程(橙色曲线)的性能显著下降,但学习惯性阻止其适应新任务。请注意,除非另有说明,否则测试曲线是在最终任务上进行评估的。
课程强化学习是一种通过排序一组相关任务来改进RL训练的适应策略[1]。最自然的排序是逐渐增加任务难度,采用自动课程。然而,如图5a所示,当墙壁较低时,自动课程很快掌握了技能,但在需要大幅改变技能时(图5c)无法适应,导致最终任务的性能下降(图5b)。原因是代理必须使用一个盒子来导航高墙,而在低墙场景中,定位盒子的额外步骤将受到惩罚。 +

我们的结果证明了 课程应该设计为关注“有趣的”例子。在我们的案例中,前3M步处于容易水平的课程“过度拟合”了之前的技能,并阻止其适应。虽然一个全面的IF-ELSE规则是可能的,但在现实世界中,情况可能会任意复杂,需要人类指导下的可适应行为。遵循这一精神,我们使用一个简单的框架(算法1)测试人类交互式课程的能力,其中人类(函数H)通过在训练循环中以固定间隔调整任务难度来提供反馈(即,在评估代理在当前难度上的学习进度后,用户可以选择将任务调得更容易/更难或保持不变)。
五. EXPERIMENTS
我们的目标是展示一个有人参与的交互式课程可以在适应过程中利用人类先验,从而使代理能够建立在过去的经历之上。
我们固定交互间隔(例如,总步数的0、0.1、0.2、...、0.9),并允许用户在调整课程之前检查两次学习进度。 用户可以选择使其更容易、更难或不变。
我们的基线是PPO,优化参数如[25]所示
我们分别训练GridWorld、Wall-Jumper和SparseCrawler 50K、5M和10M步。
实验结果如下:
A. Effect of Interactive Curriculum
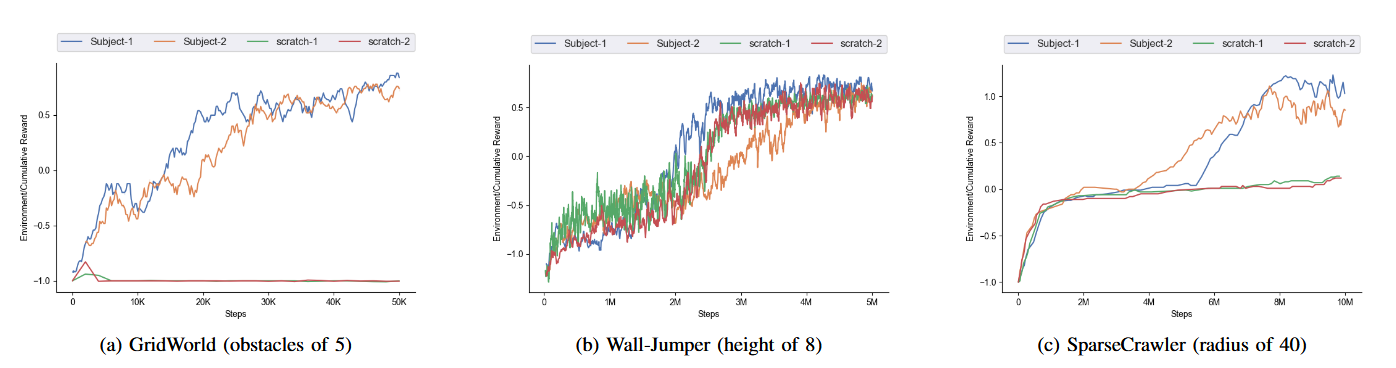
图6:交互式课程对最终任务的影响。
在图6a中,我们观察到从头开始学习的代理(绿色和红色曲线)几乎没有成功的机会,因为障碍物散布在整个网格上,因此无法强化任何所需的行为。
另一方面,用户可以通过检查学习进度来逐渐加载或删除障碍物。最终,使用我们的框架训练的模型可以解决带有5个障碍物的GridWorld。
受此启发,我们进一步在SparseCrawler任务(图6c)上测试了我们的框架,该任务需要10M步的训练。由于我们的并行设计(第III-A节),我们能够将训练时间从10小时减少到3小时,在此期间用户会进行十次交互。当使用半径逐渐增大的动态移动目标进行训练时,我们发现爬行器逐渐学会了将自己对准正确的方向
在Wall-Jumper任务(图6b)中,我们注意到不同用户的表现存在差异。一次运行(蓝色曲线)明显优于从头开始学习,而另一次运行(橙色曲线)表现较差,但仍与从头开始学习收敛。然而,这两个试验都比第III-B节所述的遭受过拟合的自动课程要好得多。
B. Generalization Ability
question:Over-fitting在强化学习中,当环境没有或轻微变化时。
思考的解决方法:
1)网格生成方式的随机性;块和跳线的布局;爬行器和目标的位置。
2)我们PPO实现中的熵正则化,使其成为一个强大的基线。
我们比较了使用我们的框架训练的模型与在三个环境中从头开始训练的模型,这些环境有一组任务。
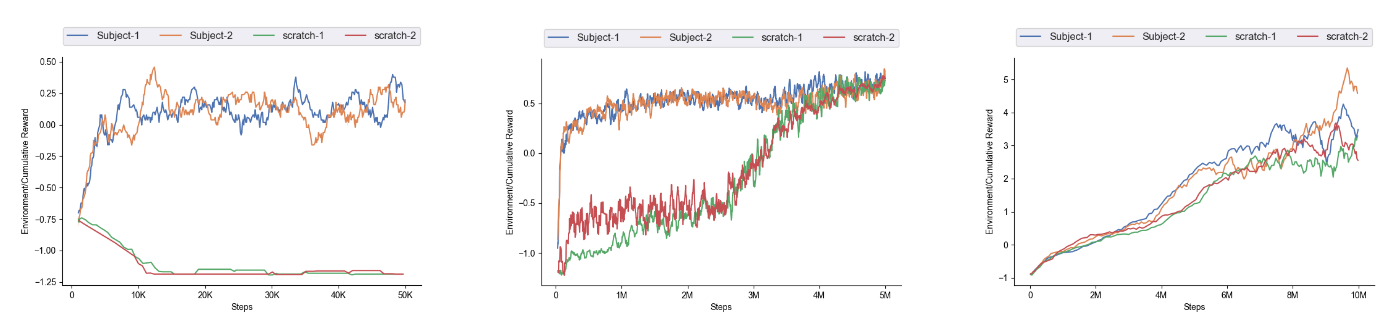
图7:在一组任务上评估交互式课程的泛化能力。这些任务的平均性能针对不同的时间步进行了绘制。
得到的结果:
- 一个常见的观察结果是,我们的模型始终优于从头开始学习。
- 其次,课程学习模型和从头开始学习的曲线之间存在很大差距(图7a),这表明它们在简单任务中“预热”得更快,而不是直接跳入困难任务。
- 最后,我们观察到我们的模型在SparseCrawler中的性能(图7c)持续上升,并且比Wall-Jumper环境多1到2次成功达到目标。只有当SparseCrawler达到单轮的最大时间步数时,我们才会重置环境。
- 在进行定性测试时,我们的模型解决了具有不同障碍的GridWorld,而从头开始学习的模型在障碍数量超过3个时失败。
- 对于Wall-Jumper,我们的模型可以用最少的步骤达到目标,而Scratch模型不可避免地会使用块,只有在高度超过6.5时才需要。
- 在SparseCrawler环境中,我们的模型具有更快的移动速度和更高的成功率,而从头开始训练的模型只能达到近端目标。
六. CONCLUSION
- 在这项研究中,我们实验并展示了人类决策如何帮助课程强化学习代理进行非常精细的难度调整。
- 我们发布了一个多平台便携式、交互式和可并行化的工具,该工具具有三个非平凡的任务,这些任务很难解决(稀疏奖励、技能之间的转移以及多达10M步的大量训练),并且具有不同的课程空间(离散/连续)。
- 我们发现了一种自动课程中的过拟合现象,这种现象会导致在技能转移过程中性能下降。
然后,我们提出了一个简单的交互式课程框架,由我们的统一用户界面促进。
实验表明,通过在其他情况下难以解决的任务中引入人机交互,可以实现更可解释和更具通用性的课程过渡。
七. LIMITATIONS
由于我们的环境需要有限的用户样本大小和时间复杂度,该项目将需要大量资源进行大规模部署。 然而,我们相信这项研究仍然可以作为人类在环强化学习研究的示例。
ps
1. 什么是Human-in-the-loop
1. 概念定义
Human-in-the-loop(HITL)是一种将人类直接引入机器学习(ML)或人工智能(AI)系统训练和决策过程的方法。这种模式强调人机协作,使得 AI 在自动化任务时可以利用人类的知识、经验和判断来优化学习过程,提高系统的性能和适应性。
在强化学习(Reinforcement Learning, RL) 或 课程学习(Curriculum Learning) 中,HITL 允许人类在训练过程中动态调整学习策略、奖励机制、任务难度或直接干预决策,从而提升智能体(agent)的学习效率和泛化能力。
2. Human-in-the-loop 的主要应用场景
HITL 可用于多个领域,包括自动驾驶、医疗诊断、游戏 AI 训练等,主要应用方式如下:
(1)数据标注与增强
-
机器学习模型通常需要大量高质量数据进行训练,而人类可以手动标注数据,或者通过主动学习(Active Learning) 选择模型最不确定的样本进行标注,优化训练数据集。
-
例如,在计算机视觉 任务中,HITL 可以用于纠正错误的目标检测或分类结果,提高模型的识别能力。
(2)强化学习中的人类反馈
-
在 RL 训练中,奖励函数(Reward Function)设计是关键,但往往难以手工设定合适的奖励信号。HITL 允许人类直接参与:
-
通过偏好学习(Preference Learning) 指导 AI 选择更符合人类意图的策略。
-
通过演示学习(Imitation Learning) 提供示范数据,加快 AI 的训练。
-
通过实时干预(Real-time Intervention) 纠正 AI 的错误决策。
-
(3)动态调整课程难度
-
在课程学习(Curriculum Learning) 中,任务的难度应随着智能体的学习进展逐步调整。
-
HITL 允许人类评估智能体的学习状态,并动态调整训练任务的复杂度,使得 AI 既不过度挑战(避免卡住),也不会学习效率低下(避免太简单)。
(4)决策系统中的人类监督
-
在涉及高风险决策的场景(如自动驾驶、金融交易、医疗诊断),完全依赖 AI 可能带来不可接受的错误率。
-
HITL 允许 AI 在做出决策前,将不确定的情况交由人类审核,或者在关键时刻由人类直接干预,确保安全性和准确性。
3. HITL 在强化学习(RL)中的作用
在 强化学习(RL) 领域,HITL 可以辅助代理更高效地探索和学习最优策略,常见方法包括:
(1)基于人类反馈的奖励塑造(Reward Shaping)
-
传统 RL 通过固定的奖励函数训练智能体,但这种方法可能导致非预期行为,如奖励欺骗(reward hacking)。
-
通过 HITL,人类可以在训练过程中动态调整奖励函数,指导智能体学习更符合人类期望的策略。
(2)基于人类示范的模仿学习(Imitation Learning)
-
人类可以直接提供操作示范(如演示如何在游戏中操控角色),让 RL 代理模仿人类的动作,快速学习基本技能,而不是完全依赖探索。
(3)人类干预(Human Intervention)
-
在 RL 训练过程中,当智能体即将做出错误决策(如撞墙、触发危险行为),人类可以介入,防止它犯错,并提供更好的行动建议。
(4)主动学习(Active Learning)
-
代理可以主动请求人类帮助,当它遇到高不确定性的情境时,让人类提供指导,从而提高学习效率。
4. HITL 的优缺点
✅ 优势
-
提高训练效率:减少 AI 盲目探索的时间,加快学习速度。
-
提升模型可靠性:在关键任务(如医疗、金融)中降低 AI 失误的风险。
-
解决复杂奖励问题:避免因奖励设计不当导致智能体学习错误行为。
-
增强泛化能力:通过人类反馈减少过拟合,提高模型在新环境下的适应性。
❌ 挑战
-
人力成本高:需要大量人类参与,可能不适用于大规模自动化任务。
-
主观性影响:人类的判断可能存在偏差,影响 AI 的学习质量。
-
延迟问题:人类干预可能导致训练变慢,特别是在大规模 RL 任务中。
-
交互复杂度:如何高效地集成人类反馈,仍是一个研究挑战。
2. Curriculum Reinforcement Learning
课程强化学习(Curriculum Reinforcement Learning, CRL) 是强化学习(Reinforcement Learning, RL)的一种训练策略,它借鉴了人类学习的方式,即从简单任务开始,逐步过渡到更复杂的任务。
课程强化学习的核心思想
像人类一样学习——先从简单任务开始,逐步增加难度,让智能体在渐进式学习中掌握复杂技能。
相比于从零开始学习(learning from scratch),CRL 允许智能体:
-
先学会基本技能,再慢慢适应更复杂的任务。
-
通过任务的难度递进,减少学习过程中的瓶颈,提高训练效率。
-
提高泛化能力,在新环境中表现更稳定
为什么需要课程强化学习?
标准的强化学习方法通常采用随机初始化环境,然后让智能体自行探索。但这种方法在许多情况下存在以下问题:
-
稀疏奖励(Sparse Reward):环境可能很复杂,智能体很难获得奖励,导致学习效率低。
-
学习曲线陡峭(Steep Learning Curve):直接让智能体从零学习困难任务,可能会导致其完全无法收敛。
-
探索效率低(Inefficient Exploration):如果任务过于复杂,智能体可能在训练早期就陷入局部最优,难以发现更好的策略。
🛠 课程强化学习的解决方案
CRL 通过设计合理的学习课程(curriculum),让智能体:
-
从简单任务开始,减少初期探索难度,加速学习过程。
-
逐步增加复杂度,避免智能体过早陷入次优策略。
-
构建更通用的策略,提高泛化能力。
课程强化学习的方法
CRL 的关键在于如何设计课程(Curriculum Design),决定任务的训练顺序。主要方法包括:
(1)手工设计课程(Manual Curriculum Design)
-
研究人员根据领域知识,手动设定一系列任务,并按照任务的复杂度安排训练顺序。
-
优点:可控性强,能够确保智能体学习正确的技能。
-
缺点:需要大量领域知识,并且不容易适应新环境。
🔹 示例:机器人控制任务
-
任务 1:先学习在平坦地面上行走
-
任务 2:然后学习在斜坡上行走
-
任务 3:最后学习在崎岖地形上行走
(2)基于规则的自动课程生成(Rule-based Automatic Curriculum)
-
通过预定义的规则,根据智能体的表现 调整任务难度。
-
任务难度通常由环境参数 决定(如障碍物数量、目标位置等)。
-
优点:相比手工设计,规则系统可以更快适应不同智能体的学习情况。
-
缺点:仍然需要专家设计规则,可能不够灵活。
🔹 示例:游戏 AI 训练
-
任务 1:玩家控制角色进行移动
-
任务 2:添加敌人 AI,要求玩家躲避
-
任务 3:增加敌人数量,提高挑战难度
(3)基于奖励信号的自动课程学习(Self-Paced Learning, SPL)
-
根据智能体的学习进度 自动调整任务难度,使其始终在“最适合学习的挑战水平”上。
-
常用策略:
-
成功率调整:如果智能体在当前任务上成功率高,则增加难度;成功率低,则降低难度。
-
奖励梯度调整:根据奖励变化趋势,自动调整任务参数。
-
🔹 示例:机器人抓取任务
-
任务 1:先让机器人抓取固定大小的方形物体
-
任务 2:随着成功率提升,逐渐增加物体的复杂性(如形状变化、材质变化)
(4)基于教师模型的课程学习(Teacher-Student Curriculum Learning)
-
通过教师模型(Teacher Model) 指导学生模型(Student Model)的学习进程。
-
教师可以是另一个 RL 代理,或者是监督学习模型,它会根据学生的学习进度提供合适的任务。
-
优点:更灵活,能够根据智能体的能力调整学习曲线。
-
缺点:需要额外训练教师模型,计算开销较大。
🔹 示例:机器人避障任务
-
教师模型 先在简单环境中训练基本技能
-
然后根据学生模型的表现,动态调整任务难度
(5)对抗式课程学习(Adversarial Curriculum Learning)
-
通过对抗训练 让课程自适应调整。
-
通常采用生成对抗网络(GAN, Generative Adversarial Networks):
-
生成器(Generator):创建新的任务环境
-
判别器(Discriminator):评估任务的难度
-
-
目标是找到能最大化智能体学习效果的课程序列。
🔹 示例:自动驾驶模拟训练
-
生成器创建不同天气和交通状况
-
判别器评估智能体的驾驶能力,并生成最有挑战性的训练场景
课程强化学习的关键组件
课程强化学习的应用
(1)机器人控制
-
逐步增加任务复杂度,如让机器人从简单的抓取任务,到复杂的机械手操作。
(2)自动驾驶
-
先在封闭道路上学习基础操作,然后在复杂城市环境中训练驾驶技能。
(3)游戏 AI
-
让游戏 AI 逐步学习不同的战术,如从基础移动,到复杂的对战策略。
(4)自然语言处理(NLP)
-
先让 AI 学习简单的语法结构,然后逐步学习复杂的文本理解任务。
课程强化学习的挑战
尽管 CRL 有很多优势,但仍然存在一些挑战:
-
如何定义任务难度?
-
任务的难度应该如何量化和评估?
-
-
如何优化任务顺序?
-
是否有通用的算法来决定任务的最佳学习顺序?
-
-
如何设计自动化课程?
-
目前大多数课程仍然依赖专家知识,如何实现完全自动化?
-
-
泛化能力问题
-
训练好的智能体能否适应新环境,而不仅仅是在训练环境中表现良好?
-
未来发展方向
-
自适应课程生成(Adaptive Curriculum Generation)
-
更智能的教师模型(Intelligent Teacher Models)
-
跨任务迁移学习(Transfer Learning Across Tasks)
-
与人类协作的课程设计(Human-in-the-Loop Curriculum Learning)
3. centralized SGD update集中式 SGD 更新
4.PPO?
5. Grid-World?
6. Wall-Jumper?
7. Sparse-Crawler?
8. human-in-the-loop reinforcement learning

















 1306
1306

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









