









博主介绍:
✌我是阿龙,一名专注于Java技术领域的程序员,全网拥有10W+粉丝。作为CSDN特邀作者、博客专家、新星计划导师,我在计算机毕业设计开发方面积累了丰富的经验。同时,我也是掘金、华为云、阿里云、InfoQ等平台的优质作者。通过长期分享和实战指导,我致力于帮助更多学生完成毕业项目和技术提升。技术范围:
我熟悉的技术领域涵盖SpringBoot、Vue、SSM、HLMT、Jsp、PHP、Nodejs、Python、爬虫、数据可视化、小程序、安卓app、大数据、物联网、机器学习等方面的设计与开发。如果你有任何技术难题,我都乐意与你分享解决方案。主要内容:
我的服务内容包括:免费功能设计、开题报告、任务书、中期检查PPT、系统功能实现、代码编写、论文撰写与辅导、论文降重、长期答辩答疑辅导。我还提供腾讯会议一对一的专业讲解和模拟答辩演练,帮助你全面掌握答辩技巧与代码逻辑。🍅获取源码请在文末联系我🍅
 目录:
目录:
1. 爬虫框架:Python爬虫(Scrapy/BeautifulSoup)
6. 数据分析与可视化:Python数据分析库(Pandas、Matplotlib、Seaborn)
7. 数据清洗与预处理:Python数据处理库(NumPy、OpenPyXL)
为什么选择我(我可以给你的定制项目推荐核心功能,一对一推荐)实现定制!!!
文章下方名片联系我即可~大家点赞、收藏、关注、评论啦 、查看👇🏻获取联系方式👇🏻精彩专栏推荐订阅:在下方专栏
一、详细操作演示视频
在文章的尾声,您会发现一张电子名片👤,欢迎通过名片上的联系方式与我取得联系,以获取更多关于项目演示的详尽视频内容。视频将帮助您全面理解项目的关键点和操作流程。期待与您的进一步交流!

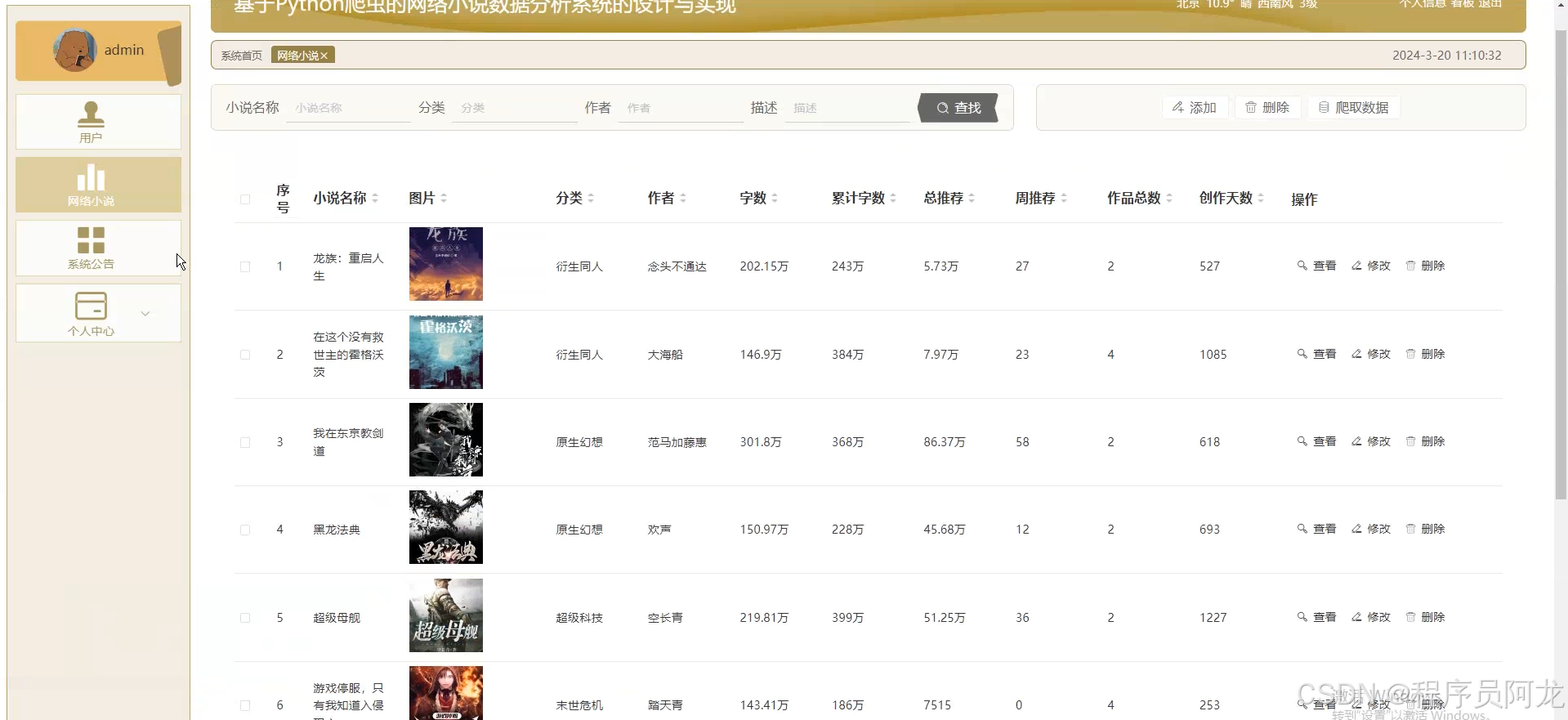
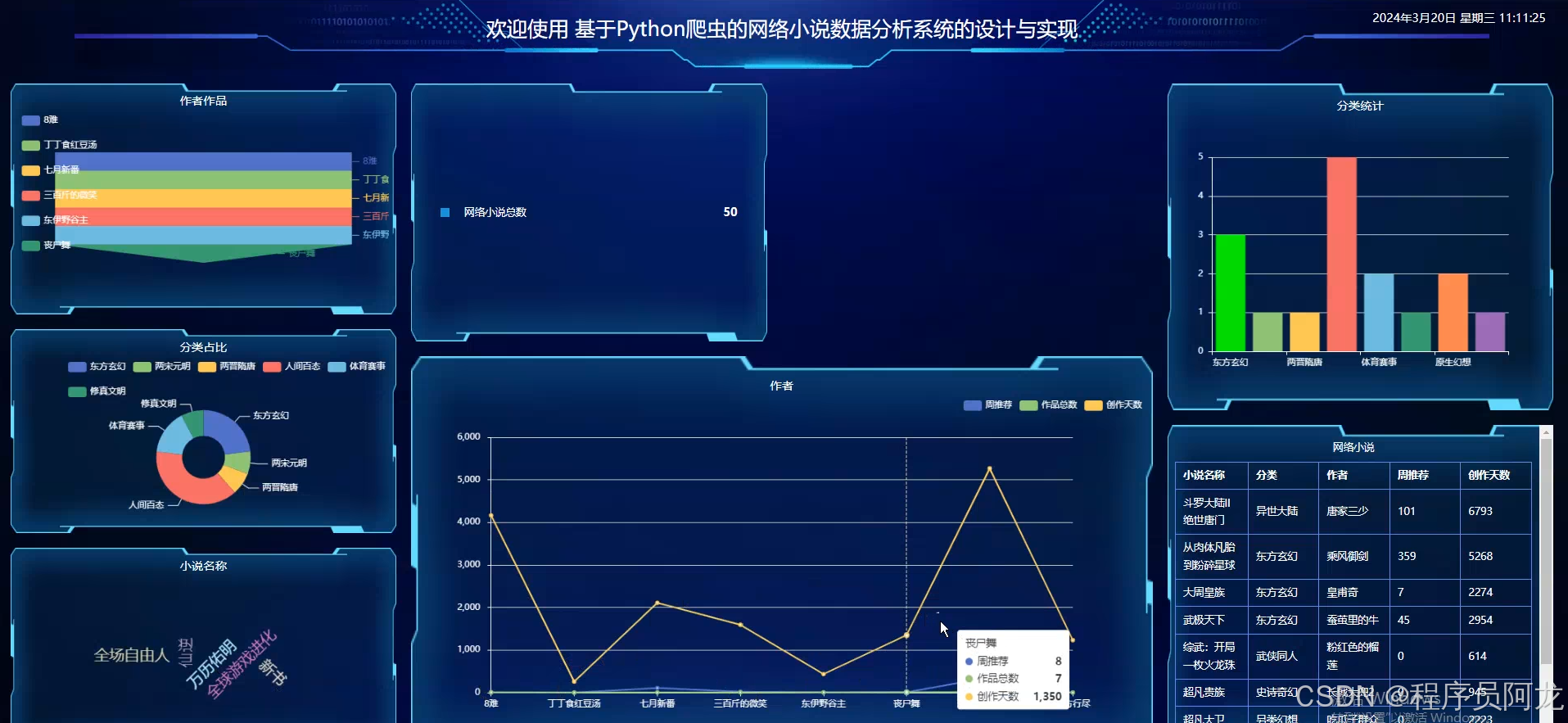
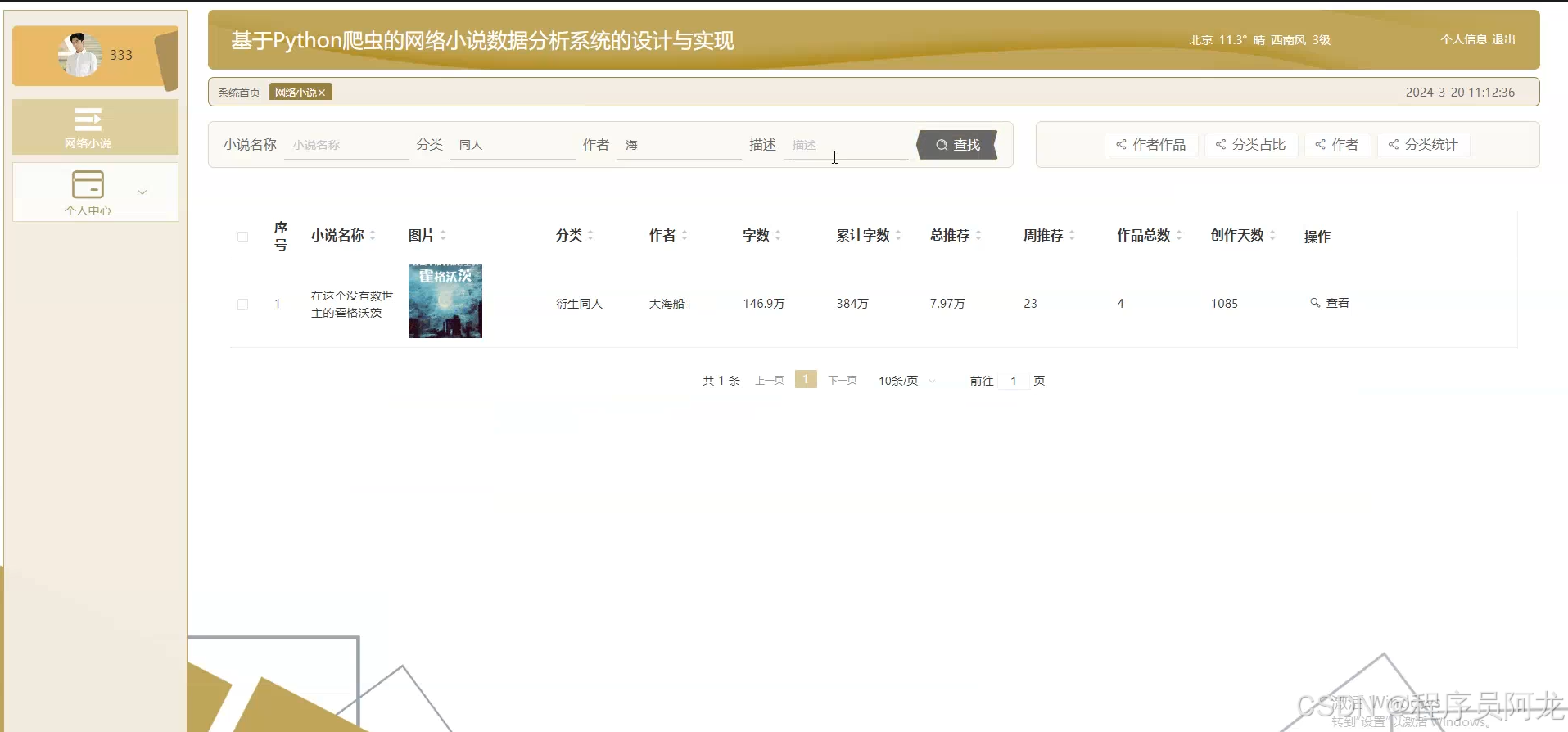

1. 爬虫框架:Python爬虫(Scrapy/BeautifulSoup)
Python爬虫是系统的核心部分,用于从互联网抓取网络小说的相关数据。常见的Python爬虫框架有Scrapy和BeautifulSoup:
- Scrapy:是一个强大的Python爬虫框架,能够高效地抓取网页内容并进行处理,适用于需要爬取大量网页的任务。Scrapy具有自动化的请求处理、数据清洗和存储功能,适用于大型爬取项目,能够高效地抓取网络小说数据并进行预处理。
- BeautifulSoup:是Python的一个库,常用于解析HTML和XML文档,可以将网页中的内容提取出来,并用于进一步处理。适用于抓取数据量较小或需要较精细控制的场景。
系统通过爬虫框架抓取网络小说的章节内容、作者信息、小说评分等数据,存储到数据库中,供后续的数据分析和可视化处理。
2. 大数据处理:Hadoop
Hadoop是一个开源的分布式计算框架,能够处理大规模数据集。它采用分布式存储和计算,通过HDFS(Hadoop分布式文件系统)和MapReduce进行大数据处理。在网络小说数据分析系统中,Hadoop的主要作用是存储和处理大规模的小说数据。
- HDFS:将抓取的小说数据存储在HDFS上,能够处理大量的文本数据,并且提供高容错性和高可用性。
- MapReduce:对存储在HDFS中的数据进行分布式处理,进行一些计算密集型的操作,如对小说章节进行分析、词频统计等。
使用Hadoop,可以让系统在抓取和存储大量小说数据时保持高效性,满足大数据的存储和处理需求。
3. 数据分析:Spark
Apache Spark是一个开源的大数据计算框架,能够处理海量数据并提供快速的并行计算能力。Spark适用于需要高速计算的数据分析任务,它支持批处理和流处理,可以将抓取的网络小说数据进行实时或批量处理。
- Spark SQL:Spark的SQL模块可以用来对存储在HDFS或者其他存储系统中的数据进行结构化查询分析。在小说数据分析中,可以使用Spark SQL来进行数据筛选、聚合、分析等操作。
- MLlib:Spark的机器学习库,可以对小说数据进行一些高级分析,比如预测小说的流行趋势、进行情感分析等。
- Spark Streaming:如果需要进行实时数据处理和分析,Spark Streaming可以帮助系统对抓取的小说数据进行实时处理,实时更新数据集并进行分析。
Spark的高性能数据处理能力,使得系统能够对网络小说数据进行高效、深度的分析,支持大规模的数据计算任务。
4. 数据仓库:Hive
Hive是一个建立在Hadoop之上的数据仓库,提供SQL查询能力,能够方便地对大规模数据进行查询和分析。它将结构化的数据存储在HDFS上,并提供类似SQL的查询接口。
- HiveQL:Hive使用一种类似SQL的查询语言,叫做HiveQL,开发人员可以通过编写HiveQL语句对存储在HDFS中的小说数据进行查询、分析和处理。
- 数据存储:在本系统中,抓取到的网络小说数据经过初步处理后,可以存储到Hive表中,便于后续的批量数据处理和分析。通过Hive可以轻松地进行数据查询和聚合计算,为后续的数据分析提供支持。
Hive的使用,可以极大地简化对海量小说数据的查询工作,使得系统可以方便地从大规模数据集中提取有价值的信息。
5. 关系型数据库:MySQL
MySQL是一个广泛使用的关系型数据库管理系统,适合存储结构化数据。在本系统中,MySQL主要用来存储抓取到的网络小说的基本信息,如小说的标题、作者、类型、章节内容等。
- 数据存储:抓取到的网络小说数据会被存储在MySQL数据库中,使用关系型数据表结构来管理数据。每本小说可以有独立的表,包含相关的章节、评分和评论信息。
- 查询与检索:在数据分析和报告生成时,MySQL可以高效地检索小说数据,为后续的分析和可视化提供支持。
MySQL提供了高效的查询功能,适用于存储和快速检索结构化的小说数据,满足系统在实时查询和报告生成方面的需求。
6. 数据分析与可视化:Python数据分析库(Pandas、Matplotlib、Seaborn)
Python的各类数据分析和可视化库是系统中的另一个重要部分。在数据存储和处理后,Python的数据分析工具用于进行深入分析,并将结果以直观的图形展示出来。
- Pandas:是Python中最常用的数据分析库,用于数据清洗、处理和分析。通过Pandas,开发人员可以轻松地对爬取的网络小说数据进行预处理、数据合并、排序和统计分析。
- Matplotlib:是一个强大的绘图库,可以生成各种类型的静态图表,如折线图、柱状图等,用于展示小说的阅读量、评分分布等数据。
- Seaborn:在Matplotlib的基础上进行扩展,提供更简洁的接口和更美观的图表样式,用于生成数据的可视化效果,帮助用户更直观地理解数据分析结果。
通过这些Python库,系统可以生成丰富的图表和数据报表,帮助分析网络小说的流行趋势、读者偏好、章节热度等信息。
7. 数据清洗与预处理:Python数据处理库(NumPy、OpenPyXL)
数据清洗和预处理是分析之前的重要步骤,Python的数据处理库如NumPy和OpenPyXL能够帮助系统完成这项工作。
- NumPy:用于高效处理大规模数组数据,帮助对小说文本数据进行处理,提取有价值的特征,如词频、句子长度等。
- OpenPyXL:用于操作Excel文件,处理数据报告或批量数据集,以便进一步分析和存储。
数据清洗和预处理对于确保分析数据的准确性和质量至关重要,通过这些工具,可以高效地准备数据进行后续分析。

核心数据库代码:
# coding: utf-8
__author__ = 'ila'
import json
from flask import current_app as app
from pyspark.ml.classification import LogisticRegression
from pyspark.ml.clustering import KMeans
from pyspark.ml.feature import VectorAssembler
from pyspark.ml.regression import LinearRegression
from pyspark.sql import SparkSession
def spark_read_mysql(sql, json_filename):
'''
排序
:param sql:
:param json_filename:
:return:
'''
df = app.spark.read.format("jdbc").options(url=app.jdbc_url,
dbtable=sql).load()
count = df.count()
df_data = df.toPandas().to_dict()
json_data = []
for i in range(count):
temp = {}
for k, v in df_data.items():
temp[k] = v.get(i)
json_data.append(temp)
with open(json_filename, 'w', encoding='utf-8') as f:
f.write(json.dumps(json_data, indent=4, ensure_ascii=False))
def linear(table_name):
'''
回归
:param table_name:
:return:
'''
spark = SparkSession.builder.appName("flask").getOrCreate()
training = spark.read.format("libsvm").table(table_name)
lr = LinearRegression(maxIter=20, regParam=0.01, elasticNetParam=0.6)
lrModel = lr.fit(training)
trainingSummary = lrModel.summary
print("numIterations: %d" % trainingSummary.totalIterations)
print("objectiveHistory: %s" % str(trainingSummary.objectiveHistory))
trainingSummary.residuals.show()
print("RMSE: %f" % trainingSummary.rootMeanSquaredError)
print("r2: %f" % trainingSummary.r2)
result = trainingSummary.residuals.toJSON()
spark.stop()
return result
def cluster(table_name):
'''
聚类
:param table_name:
:return:
'''
spark = SparkSession.builder.appName("flask").getOrCreate()
dataset = spark.read.format("libsvm").table(table_name)
kmeans = KMeans().setK(2).setSeed(1)
model = kmeans.fit(dataset)
centers = model.clusterCenters()
for center in centers:
print(center)
return centers
def selector(table_name, Cols):
'''
分类
:return:
'''
spark = SparkSession.builder.appName("flask").getOrCreate()
data = spark.read.table(table_name)
assembler = VectorAssembler(inputCols=Cols, outputCol="features")
data = assembler.transform(data).select("features", "label")
train_data, test_data = data.randomSplit([0.7, 0.3], seed=0)
lr = LogisticRegression(featuresCol="features", labelCol="label")
model = lr.fit(train_data)
predictions = model.transform(test_data)
return predictions.toJSON()
爬虫代码介绍:
# # -*- coding: utf-8 -*-
# 数据爬取文件
import scrapy
import pymysql
import pymssql
from ..items import WangluoxiaoshuoItem
import time
from datetime import datetime,timedelta
import datetime as formattime
import re
import random
import platform
import json
import os
import urllib
from urllib.parse import urlparse
import requests
import emoji
import numpy as np
import pandas as pd
from sqlalchemy import create_engine
from selenium.webdriver import ChromeOptions, ActionChains
from scrapy.http import TextResponse
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.support import expected_conditions as EC
from selenium.webdriver.support.wait import WebDriverWait
if self.table_exists(cursor, 'di2zvh33_wangluoxiaoshuo') == 1:
cursor.close()
connect.close()
self.temp_data()
return
list = response.css('ul[class="all-img-list cf"] li')
for item in list:
fields = WangluoxiaoshuoItem()
if '(.*?)' in '''div.book-mid-info h2 a::text''':
try:
fields["name"] = str( re.findall(r'''div.book-mid-info h2 a::text''', item.extract(), re.DOTALL)[0].strip())
except:
pass
else:
try:
fields["name"] = str( self.remove_html(item.css('''div.book-mid-info h2 a::text''').extract_first()))
except:
pass
if '(.*?)' in '''div.book-img-box a img::attr(src)''':
try:
fields["picture"] = str('https:'+ re.findall(r'''div.book-img-box a img::attr(src)''', item.extract(), re.DOTALL)[0].strip())
except:
pass
else:
try:
fields["picture"] = str('https:'+ self.remove_html(item.css('''div.book-img-box a img::attr(src)''').extract_first()))
except:
pass
if '(.*?)' in '''a.go-sub-type::text''':
try:
fields["fenlei"] = str( re.findall(r'''a.go-sub-type::text''', item.extract(), re.DOTALL)[0].strip())
except:
pass
else:
try:
fields["fenlei"] = str( self.remove_html(item.css('''a.go-sub-type::text''').extract_first()))
except:
pass
if '(.*?)' in '''p.intro::text''':
try:
fields["miaoshu"] = str( re.findall(r'''p.intro::text''', item.extract(), re.DOTALL)[0].strip())
except:
pass
else:
try:
fields["miaoshu"] = str( self.remove_html(item.css('''p.intro::text''').extract_first()))
except:
pass
if '(.*?)' in '''div.book-img-box a::attr(href)''':
try:
fields["xqdz"] = str('https:'+ re.findall(r'''div.book-img-box a::attr(href)''', item.extract(), re.DOTALL)[0].strip())
except:
pass
else:
try:
fields["xqdz"] = str('https:'+ self.remove_html(item.css('''div.book-img-box a::attr(href)''').extract_first()))
except:
pass
detailUrlRule = item.css('div.book-img-box a::attr(href)').extract_first()
if self.protocol in detailUrlRule or detailUrlRule.startswith('http'):
pass
elif detailUrlRule.startswith('//'):
detailUrlRule = self.protocol + ':' + detailUrlRule
elif detailUrlRule.startswith('/'):
detailUrlRule = self.protocol + '://' + self.hostname + detailUrlRule
fields["laiyuan"] = detailUrlRule
else:
detailUrlRule = self.protocol + '://' + self.hostname + '/' + detailUrlRule
detailUrlRule ='https:'+ detailUrlRule
yield scrapy.Request(url=detailUrlRule, meta={'fields': fields}, callback=self.detail_parse, dont_filter=True)
# 详情解析
def detail_parse(self, response):
fields = response.meta['fields']
try:
if '(.*?)' in '''span.author::text''':
fields["author"] = str( re.findall(r'''span.author::text''', response.text, re.S)[0].strip().replace('作者:',''))
else:
if 'author' != 'xiangqing' and 'author' != 'detail' and 'author' != 'pinglun' and 'author' != 'zuofa':
fields["author"] = str( self.remove_html(response.css('''span.author::text''').extract_first()).replace('作者:',''))
else:
try:
fields["author"] = str( emoji.demojize(response.css('''span.author::text''').extract_first()).replace('作者:',''))
except:
pass
except:
pass
try:
if '(.*?)' in '''p.count em::text''':
fields["zishu"] = str( re.findall(r'''p.count em::text''', response.text, re.S)[0].strip())
else:
if 'zishu' != 'xiangqing' and 'zishu' != 'detail' and 'zishu' != 'pinglun' and 'zishu' != 'zuofa':
fields["zishu"] = str( self.remove_html(response.css('''p.count em::text''').extract_first()))
else:
try:
fields["zishu"] = str( emoji.demojize(response.css('''p.count em::text''').extract_first()))
except:
pass
except:
pass
try:
if '(.*?)' in '''p.count em:nth-child(3)::text''':
fields["zongtuijian"] = str( re.findall(r'''p.count em:nth-child(3)::text''', response.text, re.S)[0].strip())
else:
if 'zongtuijian' != 'xiangqing' and 'zongtuijian' != 'detail' and 'zongtuijian' != 'pinglun' and 'zongtuijian' != 'zuofa':
fields["zongtuijian"] = str( self.remove_html(response.css('''p.count em:nth-child(3)::text''').extract_first()))
else:
try:
fields["zongtuijian"] = str( emoji.demojize(response.css('''p.count em:nth-child(3)::text''').extract_first()))
except:
pass
except:
pass
try:
if '(.*?)' in '''p.count em:nth-child(5)::text''':
fields["zhoutuijian"] = int( re.findall(r'''p.count em:nth-child(5)::text''', response.text, re.S)[0].strip())
else:
if 'zhoutuijian' != 'xiangqing' and 'zhoutuijian' != 'detail' and 'zhoutuijian' != 'pinglun' and 'zhoutuijian' != 'zuofa':
fields["zhoutuijian"] = int( self.remove_html(response.css('''p.count em:nth-child(5)::text''').extract_first()))
else:
try:
fields["zhoutuijian"] = int( emoji.demojize(response.css('''p.count em:nth-child(5)::text''').extract_first()))
except:
pass
except:
pass
try:
if '(.*?)' in '''div.work-number em.color-font-card::text''':
fields["worknum"] = int( re.findall(r'''div.work-number em.color-font-card::text''', response.text, re.S)[0].strip())
else:
if 'worknum' != 'xiangqing' and 'worknum' != 'detail' and 'worknum' != 'pinglun' and 'worknum' != 'zuofa':
fields["worknum"] = int( self.remove_html(response.css('''div.work-number em.color-font-card::text''').extract_first()))
else:
try:
fields["worknum"] = int( emoji.demojize(response.css('''div.work-number em.color-font-card::text''').extract_first()))
except:
pass
except:
pass
try:
if '(.*?)' in '''div.write em.color-font-card::text''':
fields["writenum"] = str( re.findall(r'''div.write em.color-font-card::text''', response.text, re.S)[0].strip())
else:
if 'writenum' != 'xiangqing' and 'writenum' != 'detail' and 'writenum' != 'pinglun' and 'writenum' != 'zuofa':
fields["writenum"] = str( self.remove_html(response.css('''div.write em.color-font-card::text''').extract_first()))
else:
try:
fields["writenum"] = str( emoji.demojize(response.css('''div.write em.color-font-card::text''').extract_first()))
except:
pass
except:
pass
try:
if '(.*?)' in '''div.days em.color-font-card::text''':
fields["days"] = int( re.findall(r'''div.days em.color-font-card::text''', response.text, re.S)[0].strip())
else:
if 'days' != 'xiangqing' and 'days' != 'detail' and 'days' != 'pinglun' and 'days' != 'zuofa':
fields["days"] = int( self.remove_html(response.css('''div.days em.color-font-card::text''').extract_first()))
else:
try:
fields["days"] = int( emoji.demojize(response.css('''div.days em.color-font-card::text''').extract_first()))
except:
pass
except:
pass
return fields
# 数据清洗
def pandas_filter(self):
engine = create_engine('mysql+pymysql://root:123456@localhost/spiderdi2zvh33?charset=UTF8MB4')
df = pd.read_sql('select * from wangluoxiaoshuo limit 50', con = engine)
# 重复数据过滤
df.duplicated()
df.drop_duplicates()
#空数据过滤
df.isnull()
df.dropna()
# 填充空数据
df.fillna(value = '暂无')
# 异常值过滤
# 滤出 大于800 和 小于 100 的
a = np.random.randint(0, 1000, size = 200)
cond = (a<=800) & (a>=100)
a[cond]
# 过滤正态分布的异常值
b = np.random.randn(100000)
# 3σ过滤异常值,σ即是标准差
cond = np.abs(b) > 3 * 1
b[cond]
# 正态分布数据
df2 = pd.DataFrame(data = np.random.randn(10000,3))
# 3σ过滤异常值,σ即是标准差
cond = (df2 > 3*df2.std()).any(axis = 1)
# 不满⾜条件的⾏索引
index = df2[cond].index
# 根据⾏索引,进⾏数据删除
df2.drop(labels=index,axis = 0)
# 去除多余html标签
def remove_html(self, html):
if html == None:
return ''
pattern = re.compile(r'<[^>]+>', re.S)
return pattern.sub('', html).strip()
# 数据库连接
def db_connect(self):
type = self.settings.get('TYPE', 'mysql')
host = self.settings.get('HOST', 'localhost')
port = int(self.settings.get('PORT', 3306))
user = self.settings.get('USER', 'root')
password = self.settings.get('PASSWORD', '123456')
try:
database = self.databaseName
except:
database = self.settings.get('DATABASE', '')
if type == 'mysql':
connect = pymysql.connect(host=host, port=port, db=database, user=user, passwd=password, charset='utf8')
else:
connect = pymssql.connect(host=host, user=user, password=password, database=database)
return connect
# 断表是否存在
def table_exists(self, cursor, table_name):
cursor.execute("show tables;")
tables = [cursor.fetchall()]
table_list = re.findall('(\'.*?\')',str(tables))
table_list = [re.sub("'",'',each) for each in table_list]
if table_name in table_list:
return 1
else:
return 0
# 数据缓存源
def temp_data(self):
connect = self.db_connect()
cursor = connect.cursor()
sql = '''
insert into `wangluoxiaoshuo`(
id
,name
,picture
,author
,fenlei
,miaoshu
,zishu
,zongtuijian
,zhoutuijian
,worknum
,writenum
,days
,xqdz
)
select
id
,name
,picture
,author
,fenlei
,miaoshu
,zishu
,zongtuijian
,zhoutuijian
,worknum
,writenum
,days
,xqdz
from `di2zvh33_wangluoxiaoshuo`
where(not exists (select
id
,name
,picture
,author
,fenlei
,miaoshu
,zishu
,zongtuijian
,zhoutuijian
,worknum
,writenum
,days
,xqdz
from `wangluoxiaoshuo` where
`wangluoxiaoshuo`.id=`di2zvh33_wangluoxiaoshuo`.id
))
order by rand()
limit 50;
'''
cursor.execute(sql)
connect.commit()
connect.close()

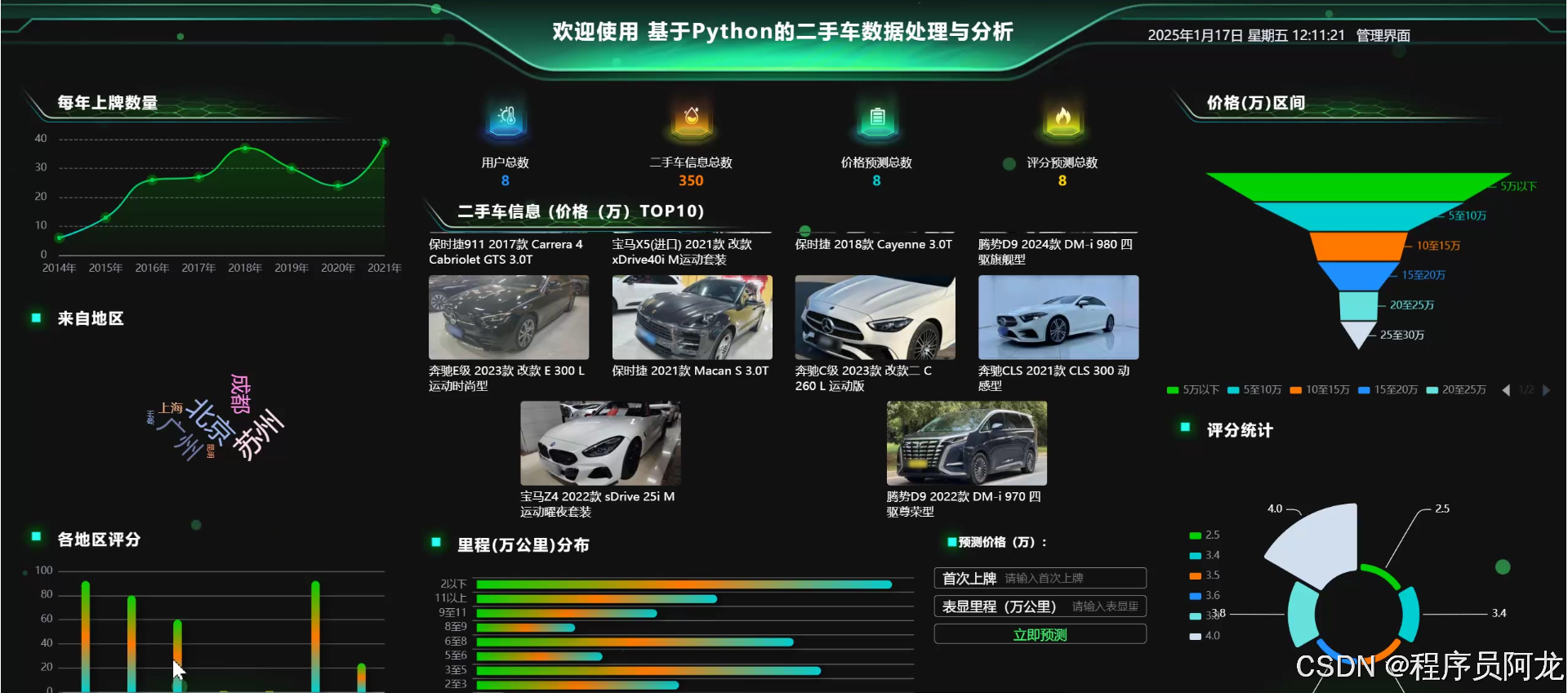
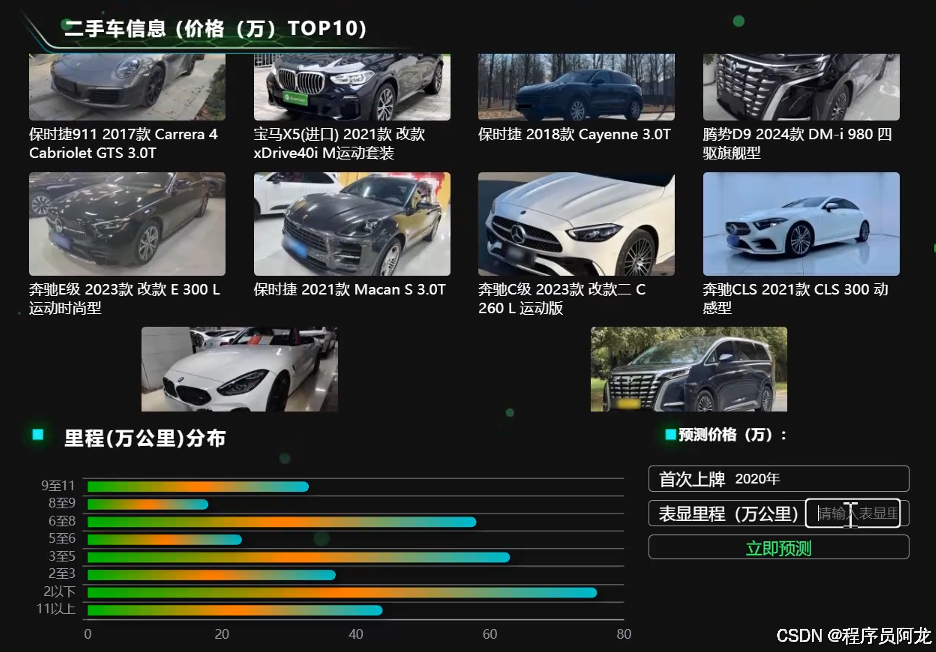
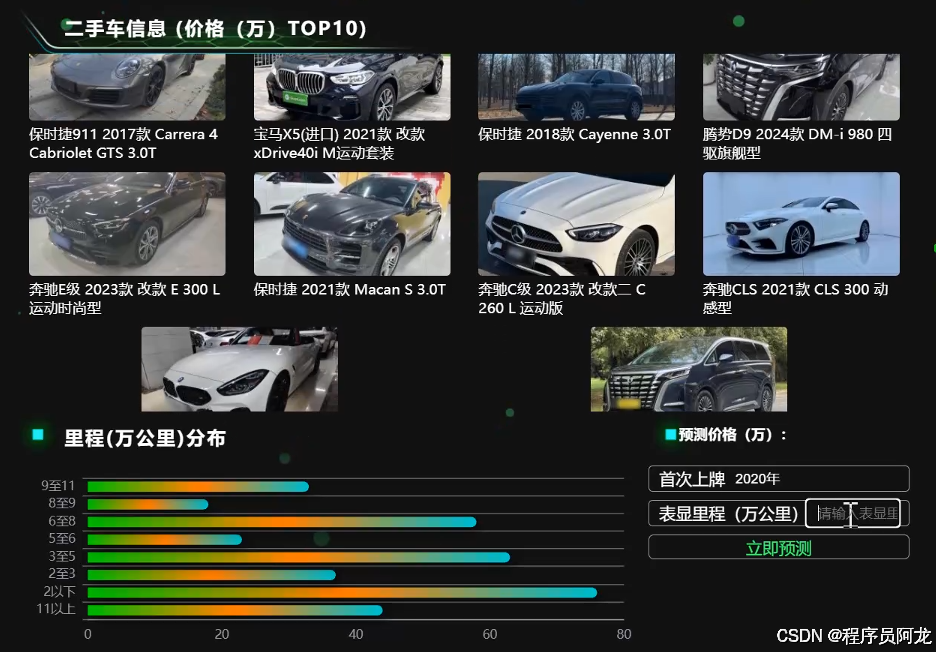


















 2464
2464

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











