






手写MLP和BP,彻底搞清神经网络训练的底层原理!
如果不想抄代码或者想获得数据,详见我的github
前言
回想起我初学神经网络与反向传播,以及torch框架时的种种挫折,我发现痛苦的根源在于各种知识点非常零散,虽然理论类的博客很多(给了我很多帮助),但深入讲解代码实现的却不多。所以为了搞懂pytorch体系,我阅读了不少torch的python源码,梳理出了torch主干, 并尝试只用numpy库和python内置库实现了一个小型神经网络系统。在这里分享给大家,欢迎大家批评与指正,另外这是我的第一篇博客,真诚希望大家指出我的不足之处,我会一定会加以改进。
为了便于理解,本篇文章只实现最简单的多层感知机,使用逻辑回归解决平面点集的二分类问题,让初接触这方面的
读者能够快速入门,让有这方面基础的读者的也能巩有所收获。(我的水平也不足以去讲解整个torch体系hhhhh…)
为了不让文章的开头太突兀,我会尽量详细说明。
但在此之前需要有以下基础:
1.扎实的Python语言基础,会使用numpy,类的继承,装饰器语法
2.线性代数知识,矩阵乘法和哈达玛乘积的概念
3.函数偏导数与链式求导法则
4.了解机器学习里使用梯度下降算法求解分类回归问题的思维方法(这个很重要)
5.想不出来了…每个人不一样,也不好评估
反向传播的实现本篇文章的核心之一,在这里我附上我当时学习反向传播其中一个比较好的博客 链接
看不懂不要紧,我也会画一张图,给出一个具体例子。
关于本篇的介绍【有不少公式编辑,建议全篇用电脑查看,不然格式显示会很难受】
下面很啰嗦,不想读的话直接看图就好
1.
本篇拟仅用
n
u
m
p
y
库和
p
y
t
h
o
n
内置库手搓一个小型的神经网络系统
,
对
t
o
r
c
h
最核心的几个模块进行了
p
y
t
h
o
n
实现
,
本篇通过实现最基本的多层感知机
(
M
u
l
t
i
l
a
y
e
r
P
e
r
c
e
p
t
r
o
n
)
,
神经网络的最基本训练方式
(
B
a
c
k
P
r
o
p
a
g
a
t
i
o
n
)
,
希望能够理清
t
o
r
c
h
的主干框架结构
,
以便加深对神经网络的理解
1.本篇拟仅用numpy库和python内置库手搓一个小型的神经网络系统,\\ 对torch最核心的几个模块进行了python实现,\\ \quad \\ 本篇通过实现最基本的多层感知机(Multilayer \ Perceptron),\\ 神经网络的最基本训练方式(BackPropagation),\\ 希望能够理清torch的主干框架结构,以便加深对神经网络的理解
1.本篇拟仅用numpy库和python内置库手搓一个小型的神经网络系统,对torch最核心的几个模块进行了python实现,本篇通过实现最基本的多层感知机(Multilayer Perceptron),神经网络的最基本训练方式(BackPropagation),希望能够理清torch的主干框架结构,以便加深对神经网络的理解
\quad \\ \quad
2.
本篇全部采用类来实现
,
避免多文件带来的阅读不便
,
M
y
t
o
r
c
h
尽可能地贴合了
t
o
r
c
h
的体系
,
是使用
n
u
m
p
y
对
t
o
r
c
h
体系主干部分的简单实现
,
包括
:
网络自动求导
,
前向、反向传播机制
L
i
n
e
a
r
,
M
o
d
u
l
e
模块
,
S
i
g
m
o
i
d
,
T
a
n
h
激活函数
B
C
E
W
i
t
h
L
o
g
i
t
s
L
o
s
s
损失函数
,
M
i
n
i
_
B
G
D
梯度下降算法
D
a
t
a
s
e
t
,
D
a
t
a
L
o
a
d
e
r
数据集和数据迭代器
2.本篇全部采用类来实现,避免多文件带来的阅读不便,\\ Mytorch尽可能地贴合了torch的体系,\\ 是使用numpy对torch体系主干部分的简单实现,\\ 包括: \\ 网络自动求导,前向、反向传播机制 \\ \quad \\ Linear,Module模块, Sigmoid,Tanh激活函数 \\ \quad \\ BCEWithLogitsLoss损失函数, Mini\_BGD 梯度下降算法 \\ \quad \\ Dataset,DataLoader 数据集和数据迭代器
2.本篇全部采用类来实现,避免多文件带来的阅读不便,Mytorch尽可能地贴合了torch的体系,是使用numpy对torch体系主干部分的简单实现,包括:网络自动求导,前向、反向传播机制Linear,Module模块,Sigmoid,Tanh激活函数BCEWithLogitsLoss损失函数,Mini_BGD梯度下降算法Dataset,DataLoader数据集和数据迭代器
\quad \\ \quad
3.
未实现
:
普通
t
e
n
s
o
r
的求导机制
(
所以
b
a
c
k
w
a
r
d
会和
t
o
r
c
h
体系有一定的差异
,
比如
d
e
t
a
c
h
和
i
s
_
l
e
a
f
等
,
但基本原理相同
)
,
C
N
N
,
R
N
N
等网络
,
R
e
L
U
,
G
L
U
等激活函数
,
C
r
o
s
s
E
n
t
r
o
p
y
L
o
s
s
,
B
C
E
L
o
s
s
等损失函数
,
S
e
q
u
e
n
t
i
a
l
,
M
o
d
u
l
e
L
i
s
t
等辅助容器类
,
S
G
D
,
A
d
a
m
等梯度下降算法
,
S
t
e
p
L
R
等学习率调度器
等等等等
.
.
.
.
.
.
3.未实现: \\ 普通tensor的求导机制(所以backward会和torch体系有一定的差异,比如detach和is\_leaf等,但基本原理相同), \\ \quad \\ CNN,RNN等网络, ReLU,GLU等激活函数, \\ \quad \\ CrossEntropyLoss,BCELoss等损失函数, Sequential,ModuleList等辅助容器类, \\ \quad \\ SGD,Adam等梯度下降算法, \ StepLR等学习率调度器 \\ \quad \\ 等等等等......
3.未实现:普通tensor的求导机制(所以backward会和torch体系有一定的差异,比如detach和is_leaf等,但基本原理相同),CNN,RNN等网络,ReLU,GLU等激活函数,CrossEntropyLoss,BCELoss等损失函数,Sequential,ModuleList等辅助容器类,SGD,Adam等梯度下降算法, StepLR等学习率调度器等等等等......
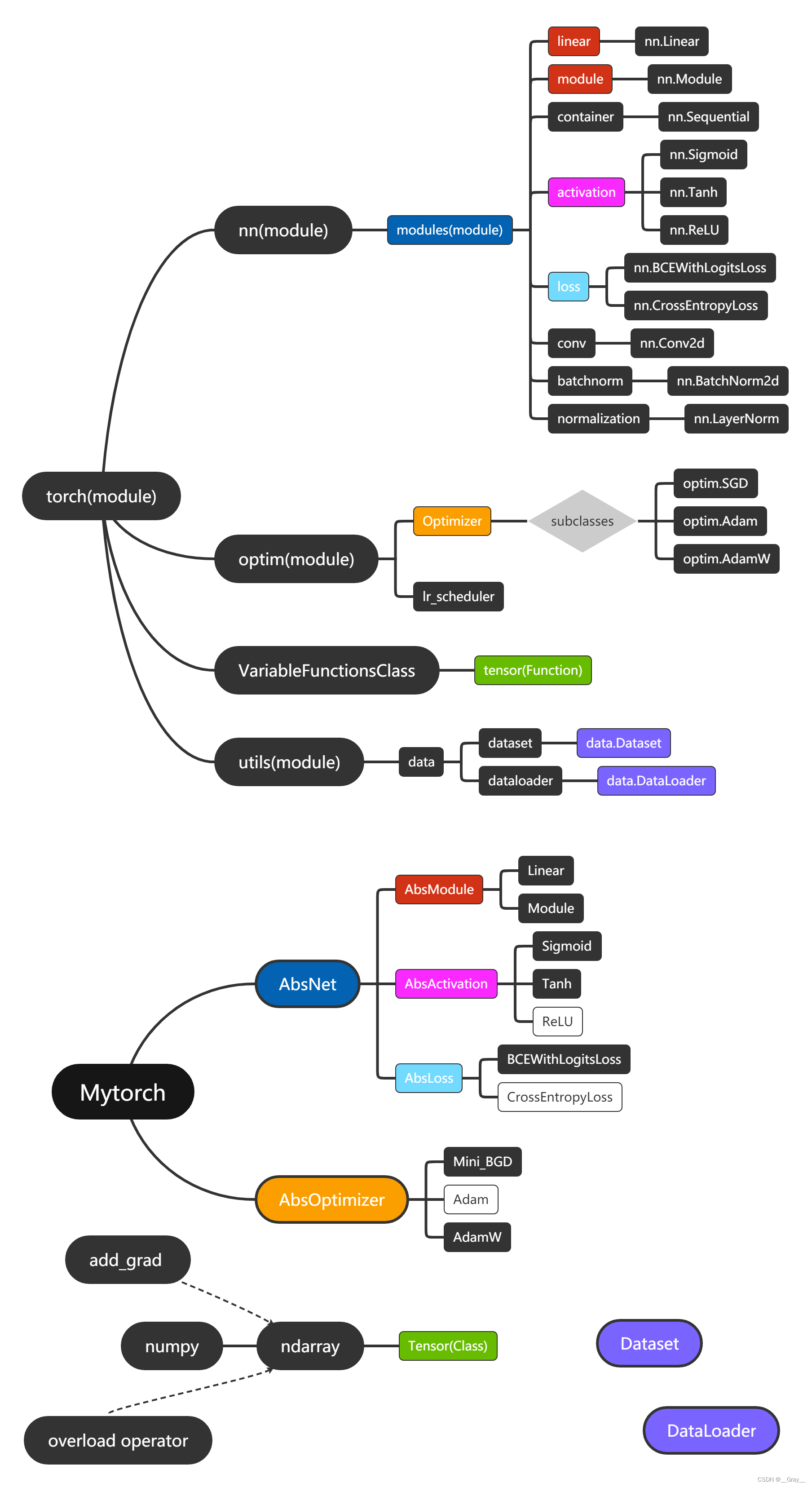
[ 补充 ] 1. t o r c h 是一个含有多个模块的庞大的深度学习框架 , 其底层主要由 C / C + + 实现 , 本篇全部采用 p y t h o n , 其主要目的在于理清 t o r c h 的主干结构 , 而不是复现 t o r c h . 2. 下图是 t o r c h 主干框架 ( 的仅仅一小部分 ) 和本篇将实现的框架结构 , 相同颜色表示相互对应 , 可以看出 M y t o r c h 和 t o r c h 的架构并不一样 ( 只提取了主干 ) 3. 白框部分未实现,感兴趣的读者 ( 真的会有么 h h h h ) 可以尝试实现 [补充] \\ 1.torch是一个含有多个模块的庞大的深度学习框架,其底层主要由C/C++实现,\\ 本篇全部采用python,其主要目的在于理清torch的主干结构,而不是复现torch. \\ 2.下图是torch主干框架(的仅仅一小部分)和本篇将实现的框架结构,相同颜色表示相互对应,\\ 可以看出Mytorch和torch的架构并不一样(只提取了主干) \\ 3.白框部分未实现,感兴趣的读者(真的会有么hhhh )可以尝试实现 [补充]1.torch是一个含有多个模块的庞大的深度学习框架,其底层主要由C/C++实现,本篇全部采用python,其主要目的在于理清torch的主干结构,而不是复现torch.2.下图是torch主干框架(的仅仅一小部分)和本篇将实现的框架结构,相同颜色表示相互对应,可以看出Mytorch和torch的架构并不一样(只提取了主干)3.白框部分未实现,感兴趣的读者(真的会有么hhhh)可以尝试实现
torch-Mytorch架构图
反向传播原理公式
相信大家都看过了那篇博客,或者已经对反向传播有所了解了,这里给出所需公式,以及一张图,让大家更加直观的理解
本节主要讲述反向传播原理 , 给出本篇实现反向传播代码需要依赖的基本公式 本节主要讲述反向传播原理,给出本篇实现反向传播代码需要依赖的基本公式\quad \\ \quad 本节主要讲述反向传播原理,给出本篇实现反向传播代码需要依赖的基本公式
[
注
]
因为
[注] 因为
[注]因为导数要放在形状和原矩阵一样的矩阵中(这句话很重要),
故矩阵偏微分采用分母布局
(
所以和雅可比不同
,
雅可比是分子布局
)
,
故矩阵偏微分采用分母布局(所以和雅可比不同,雅可比是分子布局),\quad \\ \quad
故矩阵偏微分采用分母布局(所以和雅可比不同,雅可比是分子布局),
以下公式均以分母布局给出
(
即偏导数矩阵和被求的偏导数的原矩阵形状相同
)
:
以下公式均以分母布局给出(即偏导数矩阵和被求的偏导数的原矩阵形状相同): \quad \\ \quad
以下公式均以分母布局给出(即偏导数矩阵和被求的偏导数的原矩阵形状相同):
元素级别函数求导 ( 函数作用于矩阵等价于作用于矩阵中每个元素 , 激活函数求导需要用到 ) : 元素级别函数求导(函数作用于矩阵等价于作用于矩阵中每个元素,激活函数求导需要用到): 元素级别函数求导(函数作用于矩阵等价于作用于矩阵中每个元素,激活函数求导需要用到):
∂
f
(
W
)
∂
W
=
[
∂
f
(
w
11
)
∂
w
11
.
.
.
∂
f
(
w
1
n
)
∂
w
1
n
.
.
.
.
.
.
.
.
.
∂
f
(
w
n
1
)
∂
w
n
1
.
.
.
∂
f
(
w
n
n
)
∂
w
n
n
]
\cfrac{\partial f(W)}{\partial W}=\begin{bmatrix} \cfrac{\partial f(w_{11})}{\partial w_{11}} & ... & \cfrac{\partial f(w_{1n})}{\partial w_{1n}} \\ ... & ... & ... \\ \cfrac{\partial f(w_{n1})}{\partial w_{n1}} & ... & \cfrac{\partial f(w_{nn})}{\partial w_{nn}} \end{bmatrix}
∂W∂f(W)=
∂w11∂f(w11)...∂wn1∂f(wn1).........∂w1n∂f(w1n)...∂wnn∂f(wnn)
\quad \\ \quad
标量对向量求导及链式法则 : 标量对向量求导及链式法则: 标量对向量求导及链式法则:
∂ y ∂ X = [ ∂ y ∂ x 1 ∂ y ∂ x 2 . . . ∂ y ∂ x n ] T , w h e r e y ∈ R , X ∈ R n × 1 \cfrac{\partial y}{\partial X}=\begin{bmatrix}\cfrac{\partial y}{\partial x_1} \ & \cfrac{\partial y}{\partial x_2}\ & ... \ & \cfrac{\partial y}{\partial x_n}\end{bmatrix}^T , \ where \ y \in R \ , \ X \in R^{n \times 1} ∂X∂y=[∂x1∂y ∂x2∂y ... ∂xn∂y]T, where y∈R , X∈Rn×1
∂
z
∂
X
=
∂
Y
∂
X
⋅
∂
z
∂
Y
=
J
X
(
Y
)
T
⋅
∂
z
∂
Y
,
w
h
e
r
e
X
∈
R
n
×
1
,
Y
=
F
(
X
)
∈
R
m
×
1
,
z
=
G
(
X
)
∈
R
\cfrac{\partial z}{\partial X}=\cfrac{\partial Y}{\partial X} \cdot \cfrac{\partial z}{\partial Y}=J_X(Y)^T \cdot \cfrac{\partial z}{\partial Y} \ , where \ X \in R^{n \times 1} \ , \ Y=F(X) \in R^{m \times 1}\ , \ z=G(X) \in R
∂X∂z=∂X∂Y⋅∂Y∂z=JX(Y)T⋅∂Y∂z ,where X∈Rn×1 , Y=F(X)∈Rm×1 , z=G(X)∈R
\quad \\ \quad
推论(参数矩阵求导需要用到) , 大家不妨写几个具体的矩阵验证一下 : 推论(参数矩阵求导需要用到),大家不妨写几个具体的矩阵验证一下: 推论(参数矩阵求导需要用到),大家不妨写几个具体的矩阵验证一下:
∂ z ∂ X = A T ⋅ ∂ z ∂ ( A X ) , w h e r e z = f ( A X ) ∈ R , A ∈ R m × n , X ∈ R n × p \cfrac{\partial z}{\partial X}=A^T \cdot \cfrac{\partial z}{\partial (AX)} , \ where\ z=f(AX) \in R , \ A \in R^{m \times n} , \ X \in R^{n \times p} ∂X∂z=AT⋅∂(AX)∂z, where z=f(AX)∈R, A∈Rm×n, X∈Rn×p
∂
z
∂
X
=
∂
z
∂
(
X
B
)
⋅
B
T
,
w
h
e
r
e
z
=
f
(
X
B
)
∈
R
,
B
∈
R
p
×
m
,
X
∈
R
n
×
p
\cfrac{\partial z}{\partial X}=\cfrac{\partial z}{\partial (XB)} \cdot B^T ,\ where \ z=f(XB) \in R, \ B \in R^{p \times m}\ , \ X \in R^{n \times p}
∂X∂z=∂(XB)∂z⋅BT, where z=f(XB)∈R, B∈Rp×m , X∈Rn×p
\quad \\ \quad
有了上述基础
,
就可以来搭建整个网络体系了
,
这里给出一个具体例子
,
本篇将以与该例相同的模式搭建
:
有了上述基础,就可以来搭建整个网络体系了,这里给出一个具体例子,\\ 本篇将以与该例相同的模式搭建:\quad \\ \quad
有了上述基础,就可以来搭建整个网络体系了,这里给出一个具体例子,本篇将以与该例相同的模式搭建:

好了好了,差不多了,让我们进入正题,建议可以从定义数据集和本问题的网络开始看,然后往前回溯,因为日常中我们都是调库,这种方式更贴合思维,同时大家可以对比torch版代码(可以发现几乎是一样的):
【注】以下代码运行环境为python3.9 (一些语法可能3.7及以下不支持,3.8及以上应该都不会有语法不支持的情况)
'''以下是全部所需库,pickle用于载入数据集,数据集很简单,后面会提到'''
import numpy as np
import math,pickle,time
import matplotlib.pyplot as plt
from collections import defaultdict
from abc import ABC,abstractmethod,abstractproperty
使用numpy搭建Mytorch体系
1.为ndarray加上导数矩阵
装饰在前向和反向传播中需要用到的成员方法 , 使参数在传递过程中始终拥有导数 装饰在前向和反向传播中需要用到的成员方法,使参数在传递过程中始终拥有导数 装饰在前向和反向传播中需要用到的成员方法,使参数在传递过程中始终拥有导数
'''对于拷贝传递返回值的成员方法,导数也拷贝生成'''
def add_grad(func):
def inner(self,*args,**kwargs):
ret=func(self,*args,**kwargs)
ret.detach=False
ret.grad=np.zeros(ret.shape)
return ret
return inner
'''对于引用传递返回值的成员方法,导数也取引用'''
'''
修改了add_grad_inplace,
之前的方法其实并没有让导数的内容和原数组一一对应,本篇未用到这个方法,
但是后续会更新的"手写CNN"里会用到
'''
def add_grad_inplace(func):
def inner(self, *args, **kwargs):
grad = self.grad
ret = Tensor(func(self, *args, **kwargs))
ret.grad = getattr(grad, func.__name__)(*args, **kwargs)
return ret
return inner
class Tensor(np.ndarray):
'''传入元组会生成元组形状的随机矩阵,其余参数仅进行拷贝封装'''
'''
修改了__new__方法的if,else条件判断,代码更简洁和通用,注释掉的是修改前的
'''
def __new__(cls, input_array, requires_grad=True):
if type(input_array) == tuple:
obj = np.random.randn(*input_array).view(cls)
else:
obj = np.asarray(input_array).view(cls)
obj.grad = np.zeros(obj.shape)
return obj
# def __new__(cls,input_array,requires_grad=True):
# obj=np.asarray(input_array).view(cls) \
# if type(input_array) in (list,Tensor,np.ndarray) \
# else np.random.randn(*input_array).view(cls)
# obj.grad=np.zeros(obj.shape)
# return obj
'''我一通乱装饰,实际上真正用到的没这么多,选择自己需要的进行装饰就好'''
@add_grad
def mean(self,*args,**kwargs):
return super().mean(*args,**kwargs)
@add_grad
def std(self,*args,**kwargs):
return super().std(*args,**kwargs)
@add_grad
def sum(self,*args,**kwargs):
return super().sum(*args,**kwargs)
@add_grad
def __add__(self,*args,**kwargs):
return super().__add__(*args,**kwargs)
@add_grad
def __radd__(self,*args,**kwargs):
return super().__radd__(*args,**kwargs)
@add_grad
def __sub__(self,*args,**kwargs):
return super().__sub__(*args,**kwargs)
@add_grad
def __rsub__(self,*args,**kwargs):
return super().__rsub__(*args,**kwargs)
@add_grad
def __mul__(self,*args,**kwargs):
return super().__mul__(*args,**kwargs)
@add_grad
def __rmul__(self,*args,**kwargs):
return super().__rmul__(*args,**kwargs)
@add_grad
def __pow__(self,*args,**kwargs):
return super().__pow__(*args,**kwargs)
@add_grad
def __rtruediv__(self,*args,**kwargs):
return super().__rtruediv__(*args,**kwargs)
@add_grad
def __truediv__(self,*args,**kwargs):
return super().__truediv__(*args,**kwargs)
@add_grad
def __matmul__(self,*args,**kwargs):
return super().__matmul__(*args,**kwargs)
@add_grad
def __rmatmul__(self,*args,**kwargs):
return super().__rmatmul__(*args,**kwargs)
@add_grad_inplace
def reshape(self,*args,**kwargs):
return super().reshape(*args,**kwargs)
@add_grad_inplace
def __getitem__(self,*args,**kwargs):
return super().__getitem__(*args,**kwargs)
@property
def zero_grad_(self):
self.grad=np.zeros(self.grad.shape)
'''定义网络所需的函数'''
'''
现在这种写法更加简便,其实受益于继承关系,直接Tensor(np.exp(x))也可以,
但是有风险会报错
'''
def exp(x):
return Tensor(np.exp(np.array(x)))
def log(x):
return Tensor(np.log(np.array(x)))
2.定义抽象模块
定义一个 M y T o r c h 抽象类 , 充当该体系一切类的基类 定义一个MyTorch抽象类,充当该体系一切类的基类 定义一个MyTorch抽象类,充当该体系一切类的基类
A b s N e t 表示网络主体模块,一切在前向传播中需要经历的模块都继承自该模块 AbsNet表示网络主体模块,一切在前向传播中需要经历的模块都继承自该模块 AbsNet表示网络主体模块,一切在前向传播中需要经历的模块都继承自该模块
A b s O p t i m i z e r 表示求解算法模块,一切基于梯度下降的求解算法都继承自该模块 AbsOptimizer表示求解算法模块,一切基于梯度下降的求解算法都继承自该模块 AbsOptimizer表示求解算法模块,一切基于梯度下降的求解算法都继承自该模块
A b s A c t i v a t i o n 是激活函数模块,一切激活函数 . . . . . . AbsActivation是激活函数模块,一切激活函数...... AbsActivation是激活函数模块,一切激活函数......
A b s M o d u l e 是网络参数模块 , 一切 . . . . . . AbsModule是网络参数模块,一切...... AbsModule是网络参数模块,一切......
A b s L o s s 是损失函数模块 , 一 . . . . . AbsLoss是损失函数模块,一..... AbsLoss是损失函数模块,一.....
各个模块的继承关系如上面那个 M y t o r c h 架构图 各个模块的继承关系如上面那个Mytorch架构图 各个模块的继承关系如上面那个Mytorch架构图
class MyTorch(ABC):pass
class AbsNet(MyTorch):
@abstractmethod
def __init__(self,*args,**kwargs):pass
@abstractmethod
def __call__(self,*args,**kwargs):pass
@abstractmethod
def forward(self,*args,**kwargs):pass
@abstractmethod
def backward(self,*args,**kwargs):pass
class AbsActivation(AbsNet):
def __init__(self,*args,**kwargs):pass
@abstractmethod
def function(self,*args,**kwargs):pass
def __call__(self,x):
self.input=x
self.output=self.forward(x)
return self.output
@property
def zero_grad_(self):
if "input" in self.__dict__.keys():
self.input.zero_grad_
class AbsOptimizer(MyTorch):
@abstractmethod
def __init__(self,*args,**kwargs):pass
@abstractmethod
def step(self,*args,**kwargs):pass
def zero_grad(self):
self.parameters.zero_grad_
class AbsModule(AbsNet):
@abstractproperty
def zero_grad_(self):pass
@abstractmethod
def __repr__(self):pass
class AbsLoss(AbsNet):
@abstractproperty
def outgrad(self):pass
@abstractmethod
def forward(self,*args,**kwargs):pass
def __call__(self,*args,**kwargs):
return self.forward(*args,**kwargs)
def backward(self):
cgrad=self.outgrad
for block_name,block in reversed(self.net.__dict__.items()):
if type(block).__base__.__base__ is not AbsNet:
continue
cgrad=block.backward(cgrad)
3.定义“内置”模块
不同类型的模块需继承各自相应的抽象模块
定义内置模块需要继承 A b s M o d u l e , 并实现 _ _ r e p r _ _ 方法方便打印 , 同时实现导数清零方法 ( 因为参数网络不一样 ) 定义内置模块需要继承AbsModule,并实现\_\_repr\_\_方法方便打印,同时实现导数清零方法\\ (因为参数网络不一样) 定义内置模块需要继承AbsModule,并实现__repr__方法方便打印,同时实现导数清零方法(因为参数网络不一样)
定义内置激活函数需要继承 A b s A c t i v a t i o n , 并需要重载 _ _ i n i t _ _ , f o r w a r d 和 b a c k w a r d 定义内置激活函数需要继承AbsActivation,并需要重载\_\_init\_\_,forward和backward 定义内置激活函数需要继承AbsActivation,并需要重载__init__,forward和backward
定义内置损失函数需继承 A b s L o s s , 不用重载 b a c k w a r d , 但要实现 o u t g r a d 方法 ( 即损失函数对最后输出的导数 ) 定义内置损失函数需继承AbsLoss,不用重载backward,但要实现outgrad方法 \\ (即损失函数对最后输出的导数) 定义内置损失函数需继承AbsLoss,不用重载backward,但要实现outgrad方法(即损失函数对最后输出的导数)
定义内置梯度下降算法需继承 A b s O p t i m i z e r , 并实现 s t e p 方法 定义内置梯度下降算法需继承AbsOptimizer,并实现step方法 定义内置梯度下降算法需继承AbsOptimizer,并实现step方法
(1)Linear (对应于 nn.Linear)
由于torch.nn.Linear参数初始化采用了kaiming_uniform_初始化,我们也这样初始化,其实就是从一个
U(-bound,bound) 的均匀分布中随机抽取
'''定义线性层'''
class Linear(AbsModule):
def __init__(self,in_features,out_features,bias=True):
self.in_features=in_features
self.out_features=out_features
self.bias=bias
'''使用和torch.nn.Linear中一样参数初始化:参数a=sqrt(5),mode='fan_in'的kaiming_uniform_初始化'''
bound=1/math.sqrt(in_features)
self.parameters={"weight":Tensor((np.random.rand(in_features,out_features)-0.5)*2*bound)}
if bias:
self.parameters["bias"]=Tensor((np.random.rand(1,out_features)-0.5)*2*bound)
def __call__(self,x):
self.input=x
self.output=self.forward(x)
return self.output
def forward(self,x):
out=x @ self.parameters["weight"]
if self.bias:
out+=self.parameters["bias"]
return out
def backward(self,cgrad):
try:
self.input.grad= cgrad @ self.parameters["weight"].T
except AttributeError:
raise AttributeError("The layer: "+self.__repr__()+" absent from FP!")
self.parameters["weight"].grad+= self.input.T @ cgrad
if self.bias:
self.parameters["bias"].grad+= cgrad.sum(0,keepdims=True)
return self.input.grad.copy()
def __repr__(self):
return f"Linear(in_features={self.in_features}, "+\
f"out_features={self.out_features}, bias={self.bias})"
@property
def zero_grad_(self):
if "input" in self.__dict__.keys():
self.input.zero_grad_
self.parameters["weight"].zero_grad_
if self.bias:
self.parameters["bias"].zero_grad_
(2)激活函数 (对应于 nn.Sigmoid 和 nn.Tanh )
'''定义激活函数层,这里使用Sigmoid,Tanh'''
class Sigmoid(AbsActivation):
def function(self,x):
return 1/(1+exp(-x))
def forward(self,x):
return self.function(x)
def backward(self,cgrad):
assert self.output.shape==cgrad.shape,"Activation Sigmoid BP Error!"
try:
self.input.grad=(self.output*(1-self.output))*cgrad
except (AttributeError):
raise AttributeError("Layer: " +self.__repr__()+" absent from FP!")
return self.input.grad
def __repr__(self):
return "Sigmoid()"
class Tanh(AbsActivation):
def function(self,x):
return (1-exp(-2*x))/(1+exp(-2*x))
def forward(self,x):
return self.function(x)
def backward(self,cgrad):
assert self.output.shape==cgrad.shape,"Activation Tanh BP Error!"
try:
self.input.grad=(1-self.output**2)*cgrad
except (AttributeError):
raise AttributeError("Layer: " +self.__repr__()+" absent from FP!")
return self.input.grad
def __repr__(self):
return "Tanh()"
(3) Module (对应于 nn.Module )
自定义网络只需继承 M o d u l e , 并只需实现 _ _ i n i t _ _ 和 f o r w a r d 即可 自定义网络只需继承Module,并只需实现\_\_init\_\_和forward即可 自定义网络只需继承Module,并只需实现__init__和forward即可
'''定义模块层'''
class Module(AbsModule):
def __init__(self,*args,**kwargs):
raise NotImplementedError("Class: \"Module\" has to be overrided!")
def __call__(self,*args,**kwargs):
return self.forward(*args,**kwargs)
def forward(self,*args,**kwargs):
raise NotImplementedError("Function: \"forward()\" has to be overloaded!")
def backward(self,cgrad):
for block_name,block in reversed(self.__dict__.items()):
if type(block).__base__ not in (AbsActivation,AbsModule,Module):continue
cgrad=block.backward(cgrad)
return cgrad
def __repr__(self):
name="Net(\n"
for block_name,block in self.__dict__.items():
if type(block).__base__ not in (AbsNet,AbsActivation,AbsModule,):
continue
name+=" ("+str(block_name)+"): "+block.__repr__()+"\n"
return name+")"
@property
def zero_grad_(self):
for block_name,block in self.__dict__.items():
if type(block).__base__ not in (AbsActivation,AbsModule,Module):continue
block.zero_grad_
(4) BCEWithLogitsLoss (对应于 nn.BCEWithLogitsLoss)
这个损失函数是BCELoss和Sigmoid激活的整合,其原理可以参考这篇博客, 其导数可以查看上面我给出的反向传播那张图,另外值得一提的是,其形式上和回归问题的平方损失函数是一样的,非常优美。
'''定义损失函数,这里实现二元交叉熵+ Sigmoid 损失函数'''
class BCEWithLogitsLoss(AbsLoss):
def __init__(self,net,reduction="none"):
self.net=net
self.reduction=reduction
self.function=Sigmoid()
def forward(self,y,y_hat):
self.out=y
self.hat=y_hat
p=self.function(y)
ret=-(y_hat*log(p)+(1-y_hat)*log(1-p))
if self.reduction=="mean":return ret.mean()
elif self.reduction=="sum":return ret.sum()
return ret
@property
def outgrad(self):
out=self.out
hat=self.hat
out.grad=(self.function(out)-hat)/out.shape[0]
return out.grad
(5) Mini_BGD(小批量梯度下降算法,类似于torch.optim.SGD,因为torch貌似未实现普通的BGD)
'''定义梯度下降算法,这里使用最普通的小批量梯度下降算法,其实和SGD区别只在于遍历数据集的方式'''
class Mini_BGD(AbsOptimizer):
def __init__(self,net,lr=0.001):
self.parameters=net
self.lr=lr
def step(self):
for block_name,block in reversed(self.parameters.__dict__.items()):
if type(block).__base__!=AbsModule:continue
for name,weight in block.parameters.items():
weight-=self.lr*weight.grad
(6) 定义一个非常厉害的优化器AdamW优化算法
我知道这东西放在这里可能有些突兀, 但 A d a m 系列优化器已经是训练 t r a n s f o r m e r 的主流优化器了,有必要提一下下, 大家跑这份代码的时候,注释掉随机数种子,对比我列出的这两种算法多跑几次, 就知道 A d a m W 有多厉害了 h h h . . . 我知道这东西放在这里可能有些突兀,\\ 但Adam系列优化器已经是训练 transformer的主流优化器了,有必要提一下下,\\ 大家跑这份代码的时候,注释掉随机数种子,对比我列出的这两种算法多跑几次,\\ 就知道AdamW有多厉害了hhh... 我知道这东西放在这里可能有些突兀,但Adam系列优化器已经是训练transformer的主流优化器了,有必要提一下下,大家跑这份代码的时候,注释掉随机数种子,对比我列出的这两种算法多跑几次,就知道AdamW有多厉害了hhh...
这里给出它的公式 ( 从 t o r c h 源码复制粘贴的 ) : 这里给出它的公式(从torch源码复制粘贴的): 这里给出它的公式(从torch源码复制粘贴的):
input : γ (lr) , β 1 , β 2 (betas) , θ 0 (params) , f ( θ ) (objective) , ϵ (epsilon) λ (weight decay) , amsgrad , maximize initialize : m 0 ← 0 (first moment) , v 0 ← 0 ( second moment) , v 0 ^ m a x ← 0 for t = 1 to … do if maximize : g t ← − ∇ θ f t ( θ t − 1 ) else g t ← ∇ θ f t ( θ t − 1 ) θ t ← θ t − 1 − γ λ θ t − 1 m t ← β 1 m t − 1 + ( 1 − β 1 ) g t v t ← β 2 v t − 1 + ( 1 − β 2 ) g t 2 m t ^ ← m t / ( 1 − β 1 t ) v t ^ ← v t / ( 1 − β 2 t ) if a m s g r a d v t ^ m a x ← m a x ( v t ^ m a x , v t ^ ) θ t ← θ t − γ m t ^ / ( v t ^ m a x + ϵ ) else θ t ← θ t − γ m t ^ / ( v t ^ + ϵ ) r e t u r n θ t \begin{aligned} &\rule{110mm}{0.4pt} \\ &\textbf{input} : \gamma \text{(lr)}, \: \beta_1, \beta_2 \text{(betas)}, \: \theta_0 \text{(params)}, \: f(\theta) \text{(objective)}, \: \epsilon \text{ (epsilon)} \\ &\hspace{13mm} \lambda \text{(weight decay)}, \: \textit{amsgrad}, \: \textit{maximize} \\ &\textbf{initialize} : m_0 \leftarrow 0 \text{ (first moment)}, v_0 \leftarrow 0 \text{ ( second moment)}, \: \widehat{v_0}^{max}\leftarrow 0 \\[-1.ex] &\rule{110mm}{0.4pt} \\ &\textbf{for} \: t=1 \: \textbf{to} \: \ldots \: \textbf{do} \\ &\hspace{5mm}\textbf{if} \: \textit{maximize}: \\ &\hspace{10mm}g_t \leftarrow -\nabla_{\theta} f_t (\theta_{t-1}) \\ &\hspace{5mm}\textbf{else} \\ &\hspace{10mm}g_t \leftarrow \nabla_{\theta} f_t (\theta_{t-1}) \\ &\hspace{5mm} \theta_t \leftarrow \theta_{t-1} - \gamma \lambda \theta_{t-1} \\ &\hspace{5mm}m_t \leftarrow \beta_1 m_{t-1} + (1 - \beta_1) g_t \\ &\hspace{5mm}v_t \leftarrow \beta_2 v_{t-1} + (1-\beta_2) g^2_t \\ &\hspace{5mm}\widehat{m_t} \leftarrow m_t/\big(1-\beta_1^t \big) \\ &\hspace{5mm}\widehat{v_t} \leftarrow v_t/\big(1-\beta_2^t \big) \\ &\hspace{5mm}\textbf{if} \: amsgrad \\ &\hspace{10mm}\widehat{v_t}^{max} \leftarrow \mathrm{max}(\widehat{v_t}^{max}, \widehat{v_t}) \\ &\hspace{10mm}\theta_t \leftarrow \theta_t - \gamma \widehat{m_t}/ \big(\sqrt{\widehat{v_t}^{max}} + \epsilon \big) \\ &\hspace{5mm}\textbf{else} \\ &\hspace{10mm}\theta_t \leftarrow \theta_t - \gamma \widehat{m_t}/ \big(\sqrt{\widehat{v_t}} + \epsilon \big) \\ &\rule{110mm}{0.4pt} \\[-1.ex] &\bf{return} \: \theta_t \\[-1.ex] &\rule{110mm}{0.4pt} \\[-1.ex] \end{aligned} input:γ(lr),β1,β2(betas),θ0(params),f(θ)(objective),ϵ (epsilon)λ(weight decay),amsgrad,maximizeinitialize:m0←0 (first moment),v0←0 ( second moment),v0 max←0fort=1to…doifmaximize:gt←−∇θft(θt−1)elsegt←∇θft(θt−1)θt←θt−1−γλθt−1mt←β1mt−1+(1−β1)gtvt←β2vt−1+(1−β2)gt2mt ←mt/(1−β1t)vt ←vt/(1−β2t)ifamsgradvt max←max(vt max,vt )θt←θt−γmt /(vt max+ϵ)elseθt←θt−γmt /(vt +ϵ)returnθt
'''定义另一个非常厉害的学习率调度器AdamW优化算法'''
class AdamW(AbsOptimizer):
def __init__(self,net,lr=0.01,betas=(0.9,0.999),eps=1e-08,weight_decay=0.01):
self.parameters=net
self.lr=lr
self.betas=betas
self.eps=eps
self.weight_decay=weight_decay
'''初始化t,mt,vt'''
self.t=0
self.mt=defaultdict(dict)
self.vt=defaultdict(dict)
for block_name,block in reversed(self.parameters.__dict__.items()):
if type(block).__base__!=AbsModule:continue
for name,weight in block.parameters.items():
self.mt[block_name][name]=np.zeros_like(weight)
self.vt[block_name][name]=np.zeros_like(weight)
def step(self):
beta1,beta2=self.betas
self.t+=1
for block_name,block in self.parameters.__dict__.items():
if type(block).__base__!=AbsModule:continue
for name,weight in block.parameters.items():
gt=weight.grad
mt=self.mt[block_name][name]
vt=self.vt[block_name][name]
weight-=self.lr*gt
self.mt[block_name][name]=beta1*mt+(1-beta1)*gt
self.vt[block_name][name]=beta2*vt+(1-beta2)*(gt*gt)
mt=mt/(1-np.power(beta1,self.t))
vt=vt/(1-np.power(beta2,self.t))
weight-=self.lr*mt/(np.sqrt(vt)+self.eps)
(7) DataLoader (对应于torch.utils.data.DataLoader)
'''定义批量数据迭代器,使数据集可以按照小批量传入网络'''
class DataLoader:
def __init__(self,dataset,batch_size):
self.dataset=dataset
self.batch_size=batch_size
self.num=0
self.stop=False
self.final=False
def __iter__(self):
return self
'''变量self.final使其可以反复迭代'''
def __next__(self):
if self.final==True:
self.num=0
self.final=False
if not self.stop:
bs=self.batch_size
num=self.num
self.num=min(self.num+bs,len(self.dataset))
if self.num==len(self.dataset):self.stop=True
return [Tensor(np.stack([self.dataset[i][j]
for i in range(num,self.num)]))
for j in range(2)]
self.stop=False
self.final=True
raise StopIteration
定义数据集和本问题的网络
从这里开始可以对比torch代码查看,另外,Dataset 对应于torch.utils.data.Dataset
'''定义数据集'''
class Dataset:
def __init__(self,data):
self.data=data if type(data)==list else pickle.load(open(data,"rb"))
def __getitem__(self,i):
return \
np.array(list(self.data[i][0])),np.array([self.data[i][1]],dtype=np.int32)
def __len__(self):
return len(self.data)
'''采用多层感知机,并使用tanh作为激活函数'''
class Net(Module):
def __init__(self,in_dim):
self.linear1=Linear(in_dim,5)
self.tanh1=Tanh()
self.linear2=Linear(5,3)
self.tanh2=Tanh()
self.linear3=Linear(3,1)
def forward(self,x):
out=self.linear1(x)
out=self.tanh1(out)
out=self.linear2(out)
out=self.tanh2(out)
out=self.linear3(out)
return out
定义绘图,训练,预测函数
这里解释一下数据集,data_path是.pkl 文件,dots=pickle.load(open(data_path,“rb”))是一个列表,
其元素格式为 (x,y),L ,其中(x,y)是坐标, L 是类别并且只有0,1取值
def draw(data_pth):
dots=pickle.load(open(data_pth,"rb"))
dots0=[[dot[0][0],dot[0][1]] for dot in dots if dot[-1]==0]
dots0x=[k[0] for k in dots0]
dots0y=[k[1] for k in dots0]
dots1=[[dot[0][0],dot[0][1]] for dot in dots if dot[-1]==1]
dots1x=[k[0] for k in dots1]
dots1y=[k[1] for k in dots1]
plt.scatter(dots0x,dots0y,c="g")
plt.scatter(dots1x,dots1y,c="b")
def train(net,dataloader,epochs,lr,eps=1e-5):
'''选择优化器(两个都可以)'''
# optimizer=Mini_BGD(net,lr=lr)
optimizer=AdamW(net,lr=lr)
'''选择损失函数'''
l=BCEWithLogitsLoss(net,reduction="mean")
loss_lst=[100]
'''开始遍历epochs次数据集'''
for _ in range(epochs):
'''对每次遍历取出小批量(这是必要的,尤其在数据量很大的时候)'''
for x,y in dataloader:
'''前向传播'''
y_pre=net(x)
'''计算损失函数'''
loss=l(y_pre,y)
'''记录误差'''
loss_lst+=[loss]
'''反向传播求导数'''
l.backward()
'''更新参数'''
optimizer.step()
'''导数清零'''
optimizer.zero_grad()
'''误差足够低时退出'''
if abs(loss_lst[-1]-loss_lst[-2])<eps:
break
'''输出训练信息'''
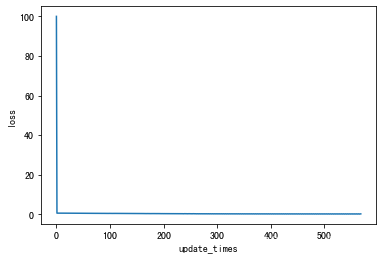
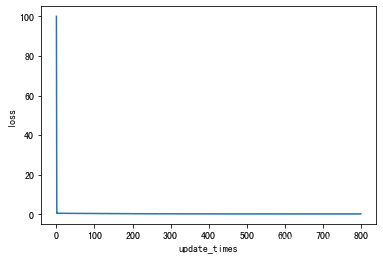
print("Update times:",len(loss_lst))
print("Final_Loss:",loss_lst[-1])
plt.xlabel("update_times")
plt.ylabel("loss")
plt.plot(loss_lst)
plt.show()
def predict(net,test_dataset,trn_path=False,eps=0.001):
'''初始化真阳,真阴,假阳,假阴'''
TP,TN,FP,FN=0,0,0,0
ALL=len(test_dataset)
datas=[[[],[]],[[],[]]]
for i in range(ALL):
dot,l=test_dataset[i]
dot=dot[None,:]
l=l[None,:]
out=net(dot)[0][0]
pre=0 if out <0 else 1
datas[pre][0]+=[dot[0][0]]
datas[pre][1]+=[dot[0][1]]
if l==1:
if out<0:FP+=1
else:TP+=1
else:
if out<0:TN+=1
else: FN+=1
if trn_path:
draw(trn_path)
'''绘出预测情况,黄色为预测负类,红色为预测正类'''
plt.scatter(datas[0][0],datas[0][1],c="y")
plt.scatter(datas[1][0],datas[1][1],c="r")
plt.show()
'''精确率'''
print("Precision:\t",(TP+eps)/(TP+FP+eps))
'''召回率'''
print("Recall:\t",(TP+eps)/(TP+FN+eps))
'''准确率'''
print("Accuracy:\t",(TP+TN+eps)/(TP+TN+FP+FN+eps))
训练
if __name__=="__main__":
'''载入训练集和测试集'''
trn_dataset=Dataset("trn_datas.pkl")
tst_dataset=Dataset("tst_datas.pkl")
'''设置随机数种子以便复现'''
np.random.seed(0)
net=Net(in_dim=2)
dataloader=DataLoader(trn_dataset,batch_size=50)
'''查看模型结构'''
print(net)
train(net,dataloader,epochs=200,lr=0.001)
结果:
Net(
(linear1): Linear(in_features=2, out_features=5, bias=True)
(tanh1): Tanh()
(linear2): Linear(in_features=5, out_features=3, bias=True)
(tanh2): Tanh()
(linear3): Linear(in_features=3, out_features=1, bias=True)
)
Update times: 569
Final_Loss: 0.28847184152795263
验证
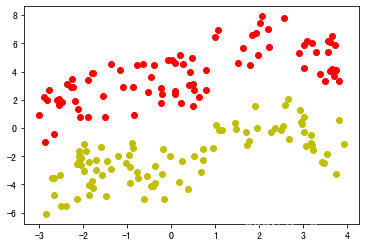
由于本任务简单,采用训练集来验证 ( 仅因以此来绘图比较简单, 实际上验证集不应与训练集和测试集相交 ) 由于本任务简单,采用训练集来验证(仅因以此来绘图比较简单,\\ 实际上验证集不应与训练集和测试集相交) 由于本任务简单,采用训练集来验证(仅因以此来绘图比较简单,实际上验证集不应与训练集和测试集相交)
predict(net,trn_dataset)
结果:
【注】红色为预测正类,黄色为预测负类, 并且由于数据集含有异常点,这是最高准确率了
Precision: 0.9404768990845347
Recall: 0.9404768990845347
Accuracy: 0.9428574693858892
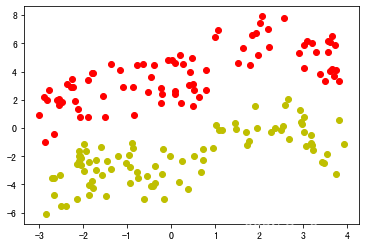
测试
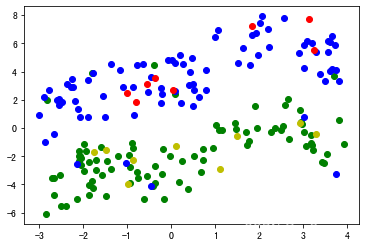
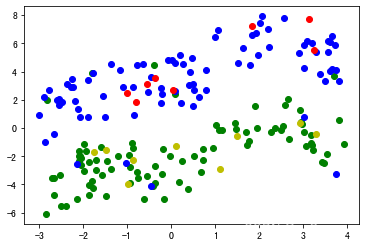
绘出原始训练数据集 , 蓝色为样本正类,绿色为样本负类 绘出原始训练数据集,蓝色为样本正类,绿色为样本负类 绘出原始训练数据集,蓝色为样本正类,绿色为样本负类
draw("trn_datas.pkl")
结果: 结果: 结果:
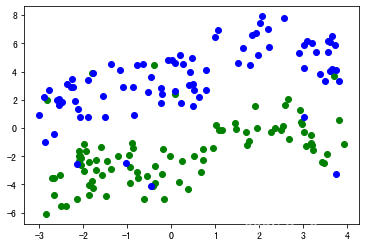
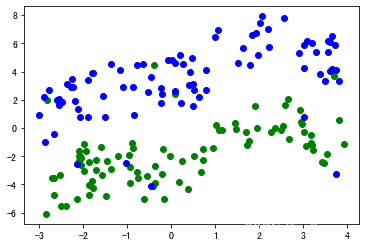
在测试集上进行预测 , 并与原始训练集绘在同一张图上 在测试集上进行预测,并与原始训练集绘在同一张图上 在测试集上进行预测,并与原始训练集绘在同一张图上
predict(net,tst_dataset,trn_path="trn_datas.pkl")
结果: 结果: 结果:
Precision: 1.0
Recall: 1.0
Accuracy: 1.0
可见其全部正确 可见其全部正确 可见其全部正确
附录
代码和数据集地址(就是本篇开头链接):链接
这里给出torch版代码:
#!/usr/bin/env python
# coding: utf-8
#author:iiGray
import torch
from torch import nn
from torch.utils import data
import pickle
import matplotlib.pyplot as plt
class Dataset(data.Dataset):
def __init__(self,data):
self.data=data if type(data)==list else pickle.load(open(data,"rb"))
def __getitem__(self,i):
return \
torch.FloatTensor(list(self.data[i][0])),torch.FloatTensor([self.data[i][1]])
def __len__(self):
return len(self.data)
class Net(nn.Module):
def __init__(self,in_dim):
super().__init__()
self.linear1=nn.Linear(in_dim,5)
self.tanh1=nn.Tanh()
self.linear2=nn.Linear(5,3)
self.tanh2=nn.Tanh()
self.linear3=nn.Linear(3,1)
def forward(self,x):
out=self.linear1(x)
out=self.tanh1(out)
out=self.linear2(out)
out=self.tanh2(out)
out=self.linear3(out)
return out
def draw(data_pth):
dots=pickle.load(open(data_pth,"rb"))
dots0=[[dot[0][0],dot[0][1]] for dot in dots if dot[-1]==0]
dots0x=[k[0] for k in dots0]
dots0y=[k[1] for k in dots0]
dots1=[[dot[0][0],dot[0][1]] for dot in dots if dot[-1]==1]
dots1x=[k[0] for k in dots1]
dots1y=[k[1] for k in dots1]
plt.scatter(dots0x,dots0y,c="g")
plt.scatter(dots1x,dots1y,c="b")
def train(net,dataloader,epochs,lr,eps=1e-5):
# optimizer=torch.optim.SGD(net.parameters(),lr=lr)
optimizer=torch.optim.AdamW(net.parameters(),lr=lr)
l=nn.BCEWithLogitsLoss()
loss_lst=[100]
for _ in range(epochs):
for x,y in dataloader:
y_pre=net(x)
loss=l(y_pre,y)
loss.backward()
with torch.no_grad():
ls=loss.item()
loss_lst+=[ls]
optimizer.step()
optimizer.zero_grad()
if abs(loss_lst[-1]-loss_lst[-2])<eps:
break
print("Update times:",len(loss_lst))
print("Final_Loss:",loss_lst[-1])
plt.xlabel("update_times")
plt.ylabel("loss")
plt.plot(loss_lst)
plt.show()
def predict(net,test_dataset,trn_path=False,eps=0.001):
TP,TN,FP,FN=0,0,0,0
ALL=len(test_dataset)
datas=[[[],[]],[[],[]]]
for i in range(ALL):
dot,l=test_dataset[i]
dot=dot[None,:]
l=l[None,:]
out=net(dot)[0][0]
pre=0 if out <0 else 1
datas[pre][0]+=[dot[0][0]]
datas[pre][1]+=[dot[0][1]]
if l==1:
if out<0:FP+=1
else:TP+=1
else:
if out<0:TN+=1
else: FN+=1
if trn_path:
draw(trn_path)
plt.scatter(datas[0][0],datas[0][1],c="y")
plt.scatter(datas[1][0],datas[1][1],c="r")
plt.show()
print("Precision:\t",(TP+eps)/(TP+FP+eps))
print("Recall:\t",(TP+eps)/(TP+FN+eps))
print("Accuracy:\t",(TP+TN+eps)/(TP+TN+FP+FN+eps))
if __name__=="__main__":
trn_dataset=Dataset("trn_datas.pkl")
tst_dataset=Dataset("tst_datas.pkl")
torch.manual_seed(0)
net=Net(in_dim=2)
dataloader=data.DataLoader(trn_dataset,batch_size=50)
print(net)
train(net,dataloader,epochs=200,lr=0.001)
predict(net,trn_dataset)
draw("trn_datas.pkl")
predict(net,tst_dataset,"trn_datas.pkl")
运行结果(依次显示):
Net(
(linear1): Linear(in_features=2, out_features=5, bias=True)
(tanh1): Tanh()
(linear2): Linear(in_features=5, out_features=3, bias=True)
(tanh2): Tanh()
(linear3): Linear(in_features=3, out_features=1, bias=True)
)
Update times: 801
Final_Loss: 0.28874489665031433
Precision: 0.9404768990845347
Recall: 0.9404768990845347
Accuracy: 0.9428574693858892
Precision: 1.0
Recall: 1.0
Accuracy: 1.0
结果是一样滴,不过大家发现没有,似乎我们手搓出来(Updatetimes=569)的比torch(Updatetimes=801)收敛更快,我也不知为什么,我觉得是更可能是巧合,但也可能某个地方没注意到吧,欢迎大家指出错误。
尾注
该数据集是代码随机生成的,具体过程见 𝑔𝑒𝑛𝑒𝑟𝑎𝑡𝑒_𝑑𝑎𝑡𝑎 文件(github里),为了更专注于探索底层的逻辑,这份数据的训练很简单,基本可以预测全对,但要想让训练集精确率和召回率同时达到 93% 以上, 会稍有难度. 同时,本篇未考虑过拟合等问题.
最后的最后,这份代码只是我在学习过程中帮助理解的练习代码,本来只是图一乐hhh,但后来越发觉得是一份很宝贵的资料,因此决定整理一下,既进行了巩固,又能够分享给大家。
而其中的设计在大佬们看来可能会有不合理的地方,毕竟我写的时候也没有考虑到太多因素,也许有些地方会有笔误,不过欢迎大家交流!
【更新与勘误】
2023.10.1: 在 定义“内置”模块 部分下方添加了补充说明
2023.10.3: 更新了为ndarray加上导数 部分内容, 纠正了 add_grad_inplace的写法(本篇未用到这个,可以忽略),简化了Tensor.__new__ 方法的判断和exp,log的实现,删除了一些本篇未用到的无关函数,后续篇章若用到会特别说明
这里顺便解释一下为什么 为了实现Tensor,要继承ndarray,而不是让data和grad分别作为Tensor的两个成员变量,因为不继承的话,像shape,__len__这些属性或方法都需要重写或装饰,不如直接继承再附带一个导数方便。
2023.10.9 更新:将BCEWithLogitsLoss 的 __call__方法放在了其父类AbsLoss里, 后面实现其他损失函数不必再重写__call__方法,反向传播例子 图有误 (最后一层求导应该是 ∂ L ∂ O \cfrac{\partial L}{\partial O} ∂O∂L)已更新,代码没问题
2023.11.9
注释:
1.手搓部分代码运行环境为py3.9,py3.7及以下版本可能不支持 reversed(dict_items)的语法,这么写是为了简便写法,如果语法不支持,也可以转成列表手动反向遍历,但是需要注意必须保证遍历时取出的是对象的引用,而不是对象的拷贝,否则参数更新时就会更新对象的拷贝而不是对象本身,相当于没有更新参数了
2.之前忘了提及,大家如果了解过pytorch,应该知道tensor反向传播时,应当传入一个与它形状相同的导数矩阵,这个矩阵作为误差函数从后面传过来的导数,而我们知道tensor的导数和它本身形状相同,因此在pytorch的tensor反向传播时,当前tensor ( 记为 A ) 的导数是通过它后面的那个 tensor( 记为 B ) 的backward()方法算出来的,因此 B 在backward时,必须知道 A 是如何运算得到 B 的,而我们知道tensor有一个grad_fn属性,正是用来表示前一个tensor通过什么运算得到当前tensor的, 本篇手搓代码为了简洁,让每个 ‘tensor’ 的 backward()都求它自己的导数而不是它的前一个‘tensor’的导数,这样就不必记录grad_fn了
2023.12.12
3.torch里tensor的反向传播和优化器的参数更新是分离的,通过将tensor外套一个nn.Parameter,将tensor转成可以被优化器更新的网络参数,只有Parameter类型的参数可以被网络更新,这样就解决了“如果想要在网络里使用tensor又不想被更新怎么办”的问题,而本篇处于简洁考虑,没有实现Parameter, 后续有机会会实现














 2927
2927











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









