






手搓CNN训练mnist手写数字数据集!
前言
我们使用之前推导过的原理 来实现代码(大家可以看看这篇文章以及后续)
通过拿自己实现的Conv2d对比torch里的Conv2d的FP和BP来验证是否正确。
非常惊喜的是,它是对的!! 结果和torch里的一模一样 ! !
并且还是和之前一样,接口调用方式和torch几乎一样
于是为了让卷积体系完整,在此框架基础上,又另外实现了MaxPool2d , AvgPoo2d 以及BatchNorm2d ,
经过验证它们也是完全正确的!!
本篇就会将代码分享给大家,验证代码也会给出,另外为了进一步证明其正确性,我们用这次实现的所有模块,基于之前几篇文章搭建的体系,来训练手写数字数据集 ! !( 同时给出torch版代码作为对比)
【注】本篇是手写神经网络的延续,至今,我们已经手写了:Linear,Module,Sequential,Tanh,Sigmoid,CrossEntropy,DataLoader,AdamW,等等等等,最重要的是: 我们搭建了一个体系,在自定义模块训练时的调用方式和torch几乎完全一致,但贴合torch并不是目的,目的在于通过手写的方式更好的理解torch底层原理,最最重要的:理解BP的计算方式,因此我们手写这样一个体系很大程度上是为了验证每个模块的正确性
关于本篇的介绍【建议全篇用电脑查看,不然格式显示会很难受】
本篇将要实现:
1.
C
o
n
v
2
d
1 .Conv2d
1.Conv2d
2.
M
a
x
P
o
o
l
2
d
,
A
v
g
P
o
o
l
2
d
2.MaxPool2d, \ AvgPool2d
2.MaxPool2d, AvgPool2d
3.
R
e
L
U
3.ReLU
3.ReLU
4.
F
l
a
t
t
e
n
4.Flatten
4.Flatten
5.
B
a
t
c
h
N
o
r
m
2
d
5.BatchNorm2d
5.BatchNorm2d
其他代码均延用之前实现的代码(有一些小改动),可以看我的上一篇文章,见附录 mytorch.py,我们直接导入这个文件即可
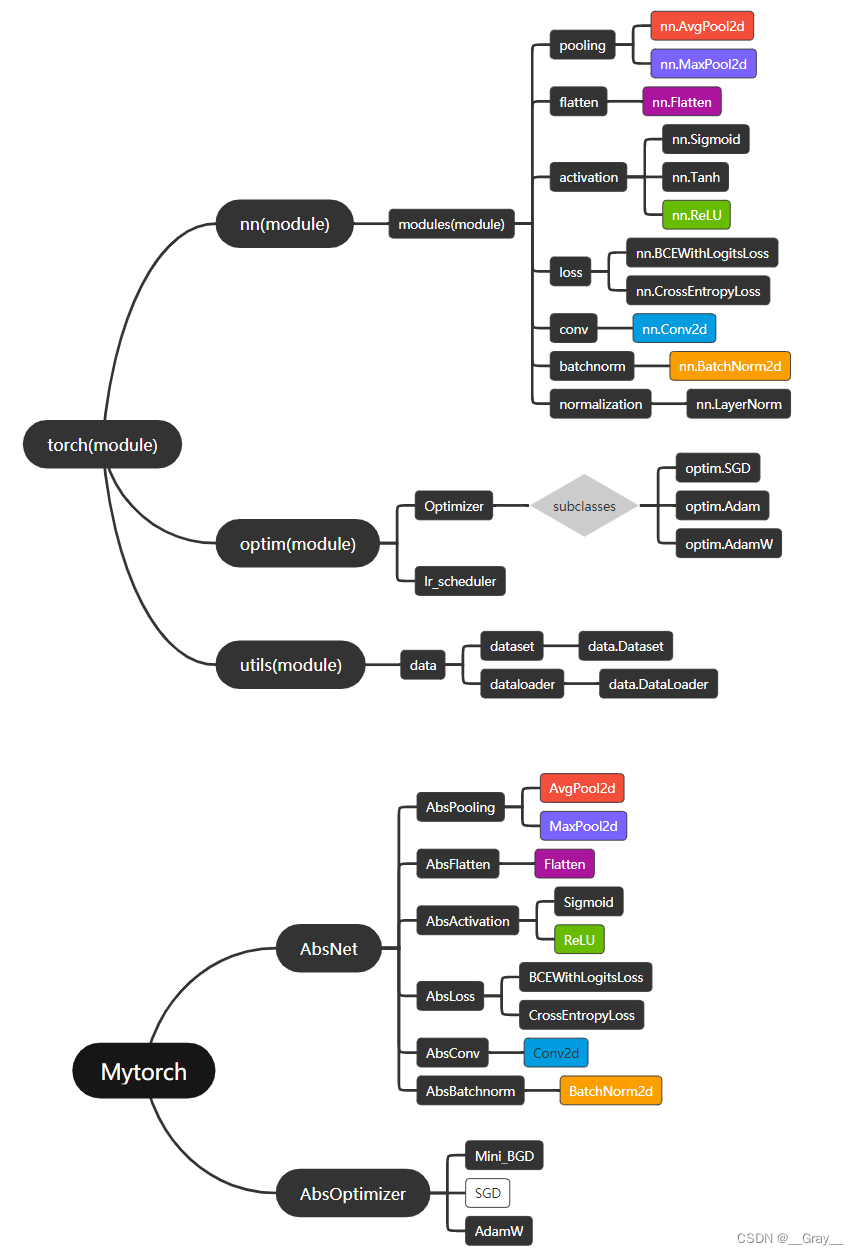
还是和之前一样给出架构对比图,其中黑色代表之前已经实现过了(因为已经实现过,有些没画出来省空间),彩色代表本次实现的,白色代表没实现的
torch-Mytorch架构图
下面进入代码环节!!仍然建议可以从定义数据集和本问题的网络开始看,然后往前回溯,因为日常中我们都是调库,这种方式更贴合思维,同时大家可以对比torch版代码(可以发现几乎是一样的):
【注】以下代码运行环境为python3.9 (一些语法可能3.7及以下不支持,3.8及以上应该都不会有语法不支持的情况)
'''以下是全部所需库,'''
import numpy as np
import math,time
import matplotlib.pyplot as plt
from collections import defaultdict,OrderedDict
from abc import ABC,abstractmethod,abstractproperty
from mytorch import *
'''用于载入数据集'''
from torchvision.datasets import mnist
一、实现 Conv2d,AvgPool2d,MaxPool2d
因为BatchNorm和其他三个不一样,我们分开来写
a. 关于Conv2d,大家请对比原理推导和代码实现查看,为了便于大家理解,变量命名都是和原理推导一样的,其他不做过多解释
b. 关于AvgPool2d和MaxPool2d, 它们和Conv2d过程很像(只能说相比Conv2d有不及而无过之),代码里有注释,相信大家如果能理解Conv2d,那么这两个完全不是问题
c. 关于BatchNorm2d,它的BP和FP与上面三个截然不同(原理在代码里有注释),求导方式是链式法则,不过相比Conv2d简单多了
1.实现抽象模块
(1)AbsConv
之所以把 g e t I n d e x 2 d getIndex2d getIndex2d 放在 A b s C o n v AbsConv AbsConv 是因为,对于 C o n v 1 d , C o n v 2 d , C o n v 3 d Conv1d, Conv2d, Conv3d Conv1d,Conv2d,Conv3d,它们主要区别就在于取索引时维度不同,只需要在 A b s C o n v AbsConv AbsConv 中添加不同维度的 g e t I n d e x getIndex getIndex ,被各自维度的 C o n v Conv Conv 子类继承后就可以直接获得这个函数,其实在后面的Conv2d实现中,_pad,_rotpi,_dilate函数完全可以写成通用的维度形式,但是为了便于理解,还是单独实现(全是2d的操作),方便对照原理理解
'''
下面让我们来实现 CNN 的网络部分,可能看到这么多符号头都要晕了,
不过这些符号的名称和之前发的两篇原理推导的文章是对应的 !
我们先实现Conv2d的抽象基类AbsConv,这个类主要用来初始化和调整一些必要参数,
以便子类的使用,主要要将其写成适用于多维的,
以便后续也可以继承它来实现Conv1d和Conv3d,
我们将取卷积序索引的函数getIndex2d放在这个类里面,
其中getIndex1d和getIndex3d分别对应2d,3d卷积,感兴趣读者可自行实现
'''
class AbsConv(AbsNet):
def __init__(self,in_channels,out_channels,
kernel_size,stride,padding,dilation,bias,dim):
assert type(kernel_size)==int or \
type(kernel_size[0])==int,"kernel_size must be type 'int'"
assert type(stride)==int or \
type(stride[0])==int,"stride must be type 'int'"
assert type(padding)==int or \
type(padding[0])==int,"padding must be type 'int'"
assert type(dilation)==int or \
type(dilation[0])==int,"dilation must be type 'int'"
self.in_channels=in_channels
self.out_channels=out_channels
self.kernel_size=(kernel_size,)*dim \
if type(kernel_size)==int else kernel_size
self.stride=(stride,)*dim \
if type(stride)==int else stride
self.padding=(padding,)*dim \
if type(padding)==int else padding
self.dilation=(dilation,)*dim \
if type(dilation)==int else dilation
self.getIndex=getattr(self,f"getIndex{dim}d")
'''避免重复计算'''
self.lastState=None
self.channel=None
self.row=None
self.col=None
self.bias=bias
self.parameters={}
'''
这个函数至关重要(CNN反向传播原理系列的两篇文章有详细说明,这里再简要提及):
为了让卷积操作更快,我们将使用矩阵乘法来加速卷积运算,
对此我们需要重排输入图像的索引,
目的是将每个卷积步对应的图像部分展成一个长度为kh*kw*kc的向量,
和同样展成向量的卷积核做矩阵乘法
具体地,(c,h,w)形状的图像'展开'为(out_h,out_w,c*kh*kw)
(注意这并不是重排,而是将每一个卷积步里卷积核覆盖的(kh,kw,kc)展开后堆叠在一起!
因为不同卷积步之间有重叠部分,因此'展开'后的结果也会有重复,
我们可以用numpy里索引语法来实现这个操作,而我们的Tensor又恰好继承了ndarray),
最后,为了尽可能减少重复计算,用lastState来记录上一次计算结果,
如果和上次相同就不必重复计算了
'''
def getIndex2d(self,c,h,w,kh,kw,sh,sw,oh,ow):
state=[c,h,w,kh,kw,sh,sw,oh,ow]
if self.lastState==state:
return self.channel,self.row,self.col
self.channel=Tensor([
[[ _ for kc in range(c) for _ in (kc,)*kh*kw]
for j in range(ow)]
for i in range(oh)])
self.row=Tensor([
[[t+i*sh for _ in range(kh) for t in [_]*kw]*c
for j in range(ow)]
for i in range(oh)])
self.col=Tensor([
[[t+j*sw for _ in range(kh) for t in range(kw)]*c
for j in range(ow)]
for i in range(oh)])
self.lastState=state
return self.channel,self.row,self.col
def __call__(self,x):
self.input=x
self.output=self.forward(x)
return self.output
def __repr__(self):
dilation="" if (len(set(self.dilation))==1 and self.dilation[0]==1)\
else f", dilation={self.dilation}"
return f"{self.__class__.__name__}({self.in_channels}, {self.out_channels}, "+\
f"kernel_size={self.kernel_size}, stride={self.stride}, "+\
f"padding={self.padding}{dilation})"
@property
def zero_grad_(self):
self.input.zero_grad_
self.parameters["weight"].zero_grad_
if self.bias:
self.parameters["bias"].zero_grad_
@abstractmethod
def _conv_forward(self,*args,**kwargs):pass
@abstractmethod
def _conv_backward(self,*args,**kwargs):pass
@abstractmethod
def _pad(self,*args,**kwargs):pass
@abstractmethod
def _dilate(self,*args,**kwargs):pass
(2)AbsPooling
将 g e t I n d e x 2 d getIndex2d getIndex2d 放在这里的原因与 A b s C o n v 2 d AbsConv2d AbsConv2d 相同
class AbsPooling(AbsNet):
def __init__(self,kernel_size,stride,padding,dilation,dim):
assert type(kernel_size)==int or \
type(kernel_size[0])==int,"kernel_size must be type 'int'"
assert type(stride)==int or \
type(stride[0])==int,"stride must be type 'int'"
assert type(padding)==int or \
type(padding[0])==int,"padding must be type 'int'"
assert type(dilation)==int or \
type(dilation[0])==int,"dilation must be type 'int'"
self.kernel_size=(kernel_size,)*dim \
if type(kernel_size)==int else kernel_size
self.stride=(stride,)*dim \
if type(stride)==int else stride
self.padding=(padding,)*dim \
if type(padding)==int else padding
self.dilation=(dilation,)*dim \
if type(dilation)==int else dilation
'''避免重复计算'''
self.lastState=None
self.channel=None
self.row=None
self.col=None
self.getIndex=getattr(self,f"getIndex{dim}d")
'''和conv里的getIndex不一样,但基本思路相同,我们希望取出的索引形状为(c,oh,ow,kh*kw)'''
def getIndex2d(self,c,h,w,kh,kw,sh,sw,oh,ow):
state=[c,h,w,kh,kw,sh,sw,oh,ow]
if self.lastState==state:
return self.channel,self.row,self.col
self.channel=Tensor([
[[[kc]*kh*kw
for j in range(ow)]
for i in range(oh)]
for kc in range(c)])
self.row=Tensor([
[[[t+i*sh for t in range(kh) for _ in range(kw)]
for j in range(ow)]
for i in range(oh)]
for kc in range(c)])
self.col=Tensor([
[[[t+j*sw for _ in range(kh) for t in range(kw)]
for j in range(ow)]
for i in range(oh)]
for kc in range(c)])
self.lastState=state
return self.channel,self.row,self.col
def __call__(self,x):
self.input=x
self.output=self.forward(x)
return self.output
def __repr__(self):
kernel_size=self.kernel_size
if len(set(kernel_size))==1:kernel_size=kernel_size[0]
stride=self.stride
if len(set(stride))==1:stride=stride[0]
padding=self.padding
if len(set(padding))==1:padding=padding[0]
dilation=""
if hasattr(self,dilation):
dilation=self.dilation
if len(set(dilation))==1:dilation=dilation[0]
dilation=f", dilation={dilation}"
ceil_mode="" if (not hasattr(self,"ceil_mode"))\
else f", ceil_mode={self.ceil_mode}"
return f"{self.__class__.__name__}(kernel_size={kernel_size}, stride={stride}, "+\
f"padding={padding}{dilation}{ceil_mode})"
@property
def zero_grad_(self):
self.input.zero_grad_
@abstractmethod
def _pad(self,*args,**kwargs):pass
@abstractmethod
def _dilate(self,*args,**kwargs):pass
2.定义“内置”模块
C o n v 2 d Conv2d Conv2d 继承 A b s C o n v AbsConv AbsConv
M a x P o o l 2 d MaxPool2d MaxPool2d 和 A v g P o o l 2 d AvgPool2d AvgPool2d 继承 A b s P o o l i n g AbsPooling AbsPooling
(1)Conv2d (对应于 nn.Conv2d)
原理推导在这里, 很详细,对比查看即可。
【注】
1、尤其需要理解channel,row,col是怎么取出来的
2、原理推导时没有考虑batch_size维度,但是对代码的影响不大,FP完全不用管,BP时只需要最后对batch_size维度求和就行了
class Conv2d(AbsConv):
def __init__(self,in_channels,out_channels,
kernel_size,stride=1,padding=0,dilation=1,bias=True):
super().__init__(in_channels,out_channels,
kernel_size,stride,padding,dilation,bias,dim=2)
'''初始化卷积核,由于随机初始化,不必考虑翻转'''
'''在这里仍然使用kaim_uniform_和之前的Linear一样,这也是torch默认初始化的方式'''
bound=1/math.sqrt(in_channels*self.kernel_size[0]*self.kernel_size[1])
self.parameters["weight"]=Tensor((np.random.rand(out_channels,in_channels,*self.kernel_size)-0.5)*2*bound)
if self.bias:
self.parameters["bias"]=Tensor((np.random.rand(out_channels)-0.5)*2*bound)
'''_pad默认填充0'''
def _pad(self,x,ph,pw):
if x.ndim==3:c,h,w=x.shape
else:bs,c,h,w=x.shape
'''计算padding之后的图像高宽'''
oph=h+ph*2
opw=w+pw*2
if x.ndim==3:
self.pout=Tensor(np.zeros((c,oph,opw)))
self.pout[:,ph:ph+h,pw:pw+w]+=x
else:
self.pout=Tensor(np.zeros((bs,c,oph,opw)))
self.pout[:,:,ph:ph+h,pw:pw+w]+=x
return self.pout
'''dilate表示对卷积核膨胀,间隙默认填充0'''
def _dilate(self,x,dh,dw):
'''计算dilation之后的卷积核大小'''
oc,c,kh,kw=x.shape
okh=(kh-1)*dh+1
okw=(kw-1)*dw+1
self.dout=Tensor(np.zeros((oc,c,okh,okw)))
self.dout[:,:,::dh,::dw]+=self.parameters["weight"]
return self.dout
def _conv_forward(self,A,K,kh,kw,sh,sw,oc,oh,ow):
bs,c,h,w=A.shape
channel,row,col=self.getIndex(c,h,w,kh,kw,sh,sw,oh,ow)
self.FA=A[:,channel,row,col]#(bs,oh,ow,c*h*w)
FK=K.reshape(self.out_channels,-1)[None,:,:].repeat(bs,axis=0)
FA=self.FA.reshape(bs,-1,self.FA.shape[-1]).transpose(0,2,1)
'''这里matmul是批量矩阵乘法 (bs,d1,d2) x (bs,d2,d3) = (bs,d1,d3)'''
self.output=matmul(FK,FA).reshape(bs,oc,oh,ow)
if self.bias:
self.output+=self.parameters["bias"][None,:,None,None]
return self.output
def forward(self,x):
assert len(x.shape)==4,"The input Tensor must be 3-dimensional!"
bs,c,h,w=x.shape
oc,kh,kw=(self.out_channels,*self.kernel_size)
sh,sw=self.stride
ph,pw=self.padding
dh,dw=self.dilation
dkh,dkw=(kh-1)*dh+1,(kw-1)*dw+1
oh=(h+ph*2-dkh)//sh+1
ow=(w+pw*2-dkw)//sw+1
'''
PA : padded A
DK : dilated K
'''
self.PA=self._pad(x,ph,pw)
self.DK=self._dilate(self.parameters["weight"],dh,dw)
return self._conv_forward(self.PA,self.DK,dkh,dkw,sh,sw,oc,oh,ow)
def _rotpi(self,x):
if x.ndim==3:
return x[:,::-1,::-1]
return x[:,:,::-1,::-1]
def _conv_backward(self,cgrad,kh,kw,sh,sw,ph,pw,dh,dw,oc,oh,ow):
bs,c,h,w=self.input.shape
pah,paw=h+2*ph,w+2*pw
dkh,dkw=(kh-1)*dh+1,(kw-1)*dw+1
'''
命名和 原理推导那篇文章相同,可对比查看更易理解
请注意和原理推导的唯一不同只是多了batch_size维度,
通过matmul批量矩阵乘法可以批处理,
然后求导时把所有批量样本的导数加起来即可,其他完全一样
'''
'''求出网络参数的导数'''
MLO=cgrad.reshape(bs,oc,-1)#shape:(bs,oc,oh*ow)
MFA=self.FA.reshape(bs,-1,self.FA.shape[-1]) #shape:(bs,oh*ow,c*okh*okw)
DKgrad=(matmul(MLO,MFA)).reshape(bs,oc,c,dkh,dkw).sum(axis=0)
self.parameters["weight"].grad+=DKgrad[:,:,::dh,::dw]
if self.bias:
self.parameters["bias"].grad+=MLO.sum(axis=-1).sum(0)
'''求出对上一图像层的导数'''
MDK=self.DK.reshape(-1,dkh,dkw) #shape:(oc*c,dkh,dkw)
MRDK=self._rotpi(MDK)
MPRDK=self._pad(MRDK,pah-dkh,paw-dkw) #shape:(oc*c,2*pah-dkh,2*paw-dkw)
PRDK=MPRDK.reshape(oc,c,2*pah-dkh,2*paw-dkw) #shape:(oc,c,2*pah-dkh,2*paw-dkw)
'''取卷积序的索引'''
channel,row,col=self.getIndex(c,2*pah-dkh,2*paw-dkw,pah,paw,sh,sw,oh,ow)
PRAgrad=Tensor(np.zeros((bs,c,pah,paw)))
for b in range(bs):
for i in range(oc):
PRDKi=PRDK[i][channel,row,col] #shape:(oh,ow,c*pah*paw)
PRAgrad[b]+=(MLO[b,i] @ PRDKi.reshape(oh*ow,-1)).reshape(c,pah,paw)
PAgrad=self._rotpi(PRAgrad)
self.input.grad+=PAgrad[:,:,ph:ph+h,pw:pw+w]
return self.input.grad
def backward(self,cgrad):
bs,c,h,w=self.input.shape
oc,kh,kw=(self.out_channels,*self.kernel_size)
sh,sw=self.stride
ph,pw=self.padding
dh,dw=self.dilation
oh=(h+2*ph-((kh-1)*dh+1))//sh+1
ow=(w+2*pw-((kw-1)*dw+1))//sw+1
return self._conv_backward(cgrad,kh,kw,sh,sw,ph,pw,dh,dw,oc,oh,ow)
(2)MaxPool2d (对应于 nn.MaxPool2d)
MaxPool2d原理并不难,重点在于BP时如何将导数放到最大值的位置上,关于其BP的过程可以看看这篇博客
class MaxPool2d(AbsPooling):
def __init__(self,kernel_size,stride=None,padding=0,dilation=1):
stride=kernel_size if stride is None else stride
super().__init__(kernel_size,stride,padding,dilation,dim=2)
self.ceil_mode=False
self._kernel=Tensor(np.zeros(self.kernel_size))
def _pad(self,x,ph,pw):
'''计算padding之后的图像高宽'''
bs,c,h,w=x.shape
oph=h+ph*2
opw=w+pw*2
self.pout=Tensor(np.zeros((bs,c,oph,opw)))
self.pout[:,:,ph:ph+h,pw:pw+w]+=x
return self.pout
'''dilate表示对卷积核膨胀,由于是最大汇聚,间隙默认填充-inf'''
def _dilate(self,x,dh,dw):
'''计算dilation之后的卷积核大小'''
kh,kw=x.shape
okh=(kh-1)*dh+1
okw=(kw-1)*dw+1
self.dout=Tensor(np.array([-np.inf]).repeat(okh*okw).reshape(okh,okw))
self.dout[::dh,::dw]=self._kernel
return self.dout
def _maxpool_forward(self,A,K,kh,kw,sh,sw,oh,ow):
bs,c,h,w=A.shape
channel,row,col=self.getIndex(c,h,w,kh,kw,sh,sw,oh,ow)
self.FA=A[:,channel,row,col]#shape:(bs,c,oh,ow,kh*kw)
self.FA+=K.reshape(-1)
'''self.argmax是需要在反向传播里使用的,用于把最大值放回导数矩阵中'''
self.argmax=self.FA.argmax(axis=-1)
return self.FA.max(axis=-1)
def forward(self,x):
assert len(x.shape)==4,"The input Tensor must be 3-dimensional!"
bs,c,h,w=x.shape
kh,kw=self.kernel_size
sh,sw=self.stride
ph,pw=self.padding
dh,dw=self.dilation
dkh,dkw=(kh-1)*dh+1,(kw-1)*dw+1
oh=(h+ph*2-dkh)//sh+1
ow=(w+pw*2-dkw)//sw+1
self.PA=self._pad(x,ph,pw)
self.DK=self._dilate(self._kernel,dh,dw)
return self._maxpool_forward(self.PA,self.DK,dkh,dkw,sh,sw,oh,ow)
def _maxpool_backward(self,cgrad,c,h,w,kh,kw,sh,sw,ph,pw,dh,dw,oh,ow):
dkh,dkw=self.DK.shape
pmt1=Tensor([[*range(self.input.shape[0])]]*c).transpose(1,0)
pmt2=Tensor([[*range(c)]]*self.input.shape[0])
for i in range(oh):
for j in range(ow):
pi,pj=self.argmax[:,:,i,j]//dkw,self.argmax[:,:,i,j]%dkw
self.PA.grad[pmt1,pmt2,pi+i*sh,pj+j*sw]+=cgrad[:,:,i,j]
self.input.grad+=self.PA.grad[:,:,ph:ph+h,pw:pw+w]
return self.input.grad
def backward(self,cgrad):
bs,c,h,w=self.input.shape
kh,kw=self.kernel_size
sh,sw=self.stride
ph,pw=self.padding
dh,dw=self.dilation
oh=(h+2*ph-((kh-1)*dh+1))//sh+1
ow=(w+2*pw-((kw-1)*dw+1))//sw+1
return self._maxpool_backward(cgrad,c,h,w,kh,kw,sh,sw,ph,pw,dh,dw,oh,ow)
(3)AvgPool2d (对应于 nn.AvgPool2d)
【注】在torch里,AvgPool2d 并没有dilation参数,本篇也并不会用到这个参数,所以_dilate函数实际上什么也没干什么
'''
计算AvgPool2d和MaxPool2d有些不同,
MaxPool是求最大,因此在处理卷积核膨胀时可以通过相加(膨胀间隙为-inf)来滤除中间的间隔,
而对于AvgPool,间隔中的值很重要,所以可以通过初始化一个元素全为 1 的卷积核,
用它与图像相乘,再求平均即可,而对于dilation,由于前向传播的计算方法是相乘,故膨胀间隙填0即可
'''
class AvgPool2d(AbsPooling):
def __init__(self,kernel_size,stride=None,padding=0,dilation=1):
stride=kernel_size if stride is None else stride
super().__init__(kernel_size,stride,padding,dilation,dim=2)
self._dilation=self.dilation
del self.dilation
self._kernel=Tensor(np.ones(self.kernel_size))
def _pad(self,x,ph,pw):
'''计算padding之后的图像高宽'''
bs,c,h,w=x.shape
oph=h+ph*2
opw=w+pw*2
self.pout=Tensor(np.zeros((bs,c,oph,opw)))
self.pout[:,:,ph:ph+h,pw:pw+w]+=x
return self.pout
'''dilate表示对卷积核膨胀,由于是平均,间隙默认填充 inf(这是为了求倒数为0) '''
def _dilate(self,x,dh,dw):
'''计算dilation之后的卷积核大小'''
kh,kw=x.shape
okh=(kh-1)*dh+1
okw=(kw-1)*dw+1
self.dout=Tensor(np.array([np.inf]).repeat(okh*okw).reshape(okh,okw))
self.dout[::dh,::dw]=self._kernel
return self.dout
def _avgpool_forward(self,A,K,kh,kw,sh,sw,oh,ow):
bs,c,h,w=A.shape
channel,row,col=self.getIndex(c,h,w,kh,kw,sh,sw,oh,ow)
self.FA=A[:,channel,row,col]#shape:(bs,c,oh,ow,kh*kw)
self.FA*=K.reshape(-1)
return self.FA.sum(axis=-1)/self._kernel.size
def forward(self,x):
assert len(x.shape)==4,"The input Tensor must be 3-dimensional!"
bs,c,h,w=x.shape
kh,kw=self.kernel_size
sh,sw=self.stride
ph,pw=self.padding
dh,dw=self._dilation
dkh,dkw=(kh-1)*dh+1,(kw-1)*dw+1
oh=(h+ph*2-dkh)//sh+1
ow=(w+pw*2-dkw)//sw+1
self.PA=self._pad(x,ph,pw)
self.DK=self._dilate(self._kernel,dh,dw)
return self._avgpool_forward(self.PA,self.DK,dkh,dkw,sh,sw,oh,ow)
def _avgpool_backward(self,cgrad,c,h,w,kh,kw,sh,sw,ph,pw,dh,dw,oh,ow):
w=self._kernel.size
'''
因为torch里的AvgPool2d本来就没有dilation,
所以这里的backward就没有考虑dilation参数了,
dkh和dkw也用不到
'''
dkh,dkw=self.DK.shape
for i in range(oh):
for j in range(ow):
self.PA.grad[:,:,i*sh:kh+i*sh,j*sw:kw+j*sw]+=cgrad[:,:,i,j][:,:,None,None]/w
self.input.grad+=self.PA.grad[:,:,ph:ph+h,pw:pw+w]
return self.input.grad
def backward(self,cgrad):
bs,c,h,w=self.input.shape
kh,kw=self.kernel_size
sh,sw=self.stride
ph,pw=self.padding
dh,dw=self._dilation
oh=(h+2*ph-((kh-1)*dh+1))//sh+1
ow=(w+2*pw-((kw-1)*dw+1))//sw+1
return self._avgpool_backward(cgrad,c,h,w,kh,kw,sh,sw,ph,pw,dh,dw,oh,ow)
(4) ReLU (对应于 nn.ReLU)
卷积网络自然要配ReLU激活函数,因为其他地方不好排版,就放在这里了.
'''实现ReLU激活函数'''
class ReLU(AbsActivation):
def function(self,x):
return (x>0).astype(np.float32)*x
def forward(self,x):
return self.function(x)
def backward(self,cgrad):
assert self.output.shape==cgrad.shape,"Activation ReLU BP Error!"
try:
self.input.grad+=((self.output>0).astype(np.int32))*cgrad
except (AttributeError):
raise AttributeError("Layer: "+self.__repr()+" absent from FP!")
return self.input.grad
二、实现 Flatten(对应于nn.Flatten)
1.实现抽象模块(AbsFlatten)
class AbsFlatten(AbsNet):
def __call__(self,x):
return self.forward(x)
def __repr__(self):
return f"Flatten(start_dim={self.start_dim}, "+\
f"end_dim={self.end_dim})"
@property
def zero_grad_(self):
self.input.zero_grad_
2.实现“内置”模块 (Flatten)
'''
这里插一句:
由于我们没有实现类似torch中的计算图(torch中定义了数百个函数并且都可以反向传播),
我们没有实现这些,所以所有操作都需要设计一个类,
但是我们可以尽可能将它们写成更通用的格式
'''
class Flatten(AbsFlatten):
def __init__(self,start_dim=1,end_dim=-1):
self.start_dim=start_dim
self.end_dim=end_dim
def forward(self,x):
self.input=x
if self.start_dim==self.end_dim:
return x
shape=list(x.shape)
l=shape[:self.start_dim]
r=shape[self.end_dim%len(shape)+1:]
out=x.reshape(*l,-1,*r)
return out
def backward(self,cgrad):
self.input.grad+=cgrad.reshape(self.input.shape)
return self.input.grad
三、实现 BatchNorm2d
1.实现AbsBatchNorm
最后我们来实现一下BatchNorm,这也是卷积网络中不可或缺的部分之一
虽说卷积网络 卷积、激活、池化这三个就够了,但是规范化会让模型参数始终保持在一个范围,可以有效缓解梯度消失或爆炸,使训练更稳定,也因此会取得更好的训练效果。
在这里先介绍一下nn.BatchNorm2d的流程,以形状为(bs,c,h,w)的张量x为例:
【训练】
F
P
:
FP :
FP:
1、先计算c维度的均值和方差,得到c个均值和方差,然后对每个通道进行规范化
2、如果affine=True,那么需要进行仿射变换 :x*weight+bias,
其中weight初始化为全1,形状为(c,),bias 初始化为全0,形状为(c,),
因此需要将它们调整成形状:(1,c,1,1),然后根据广播机制计算
3、如果
t
r
a
c
k
_
r
u
n
n
i
n
g
_
s
t
a
t
s
=
T
r
u
e
track\_running\_stats=True
track_running_stats=True,
那么会记录
r
u
n
n
i
n
g
_
m
e
a
n
running\_mean
running_mean 和
r
u
n
n
i
n
g
_
v
a
r
running\_var
running_var 的值,
每一批量计算
r
u
n
n
i
n
g
_
m
e
a
n
running\_mean
running_mean 和
r
u
n
n
i
n
g
_
v
a
r
running\_var
running_var 都会更新一次,
【下面这句话之前的表述有误,现在是正确的, 详见文末更新与勘误】
初始化时
r
u
n
n
i
n
g
_
m
e
a
n
running\_mean
running_mean 为全零矩阵 ,
r
u
n
n
i
n
g
_
v
a
r
running\_var
running_var 为全一矩阵,形状为(c,)
注意这里的
r
u
n
n
i
n
g
_
v
a
r
running\_var
running_var 需要采用样本方差来计算(分母除以n-1而不是n)
更新公式为:
r
u
n
n
i
n
g
_
x
=
(
1
−
m
o
m
e
n
t
u
m
)
∗
r
u
n
n
i
n
g
_
x
+
m
o
m
e
n
t
u
m
∗
c
u
r
r
e
n
t
_
x
running\_x=(1-momentum)*running\_x + momentum*current\_x
running_x=(1−momentum)∗running_x+momentum∗current_x
其中 c u r r e n t _ x current\_x current_x 为最近一批数据集的样本均值和样本方差
B
P
:
BP:
BP:
1、计算对
x
x
x 的导数
2、如果
a
f
f
i
n
e
=
T
r
u
e
affine=True
affine=True,则计算
w
e
i
g
h
t
weight
weight 和
b
i
a
s
bias
bias 的导数
否则没有这一步 (原理见下面代码注释)
【预测】
1.如果
t
r
a
c
k
_
r
u
n
n
i
n
g
_
s
t
a
t
s
=
T
r
u
e
track\_running\_stats=True
track_running_stats=True , 那么直接采用训练
r
u
n
n
i
n
g
_
m
e
a
n
running\_mean
running_mean 和
r
u
n
n
n
i
n
g
_
v
a
r
runnning\_var
runnning_var 来规范化,
否则采用样本数据计算来规范化
2.如果
a
f
f
i
n
e
=
T
r
u
e
affine=True
affine=True ,那么采用训练得到的
w
e
i
g
h
t
weight
weight 和
b
i
a
s
bias
bias 进行仿射变换
否则没有这一步
需要注意的是:
规范化过程不采用无偏估计计算方差,而更新
r
u
n
n
i
n
g
_
m
e
a
n
running\_mean
running_mean 和
r
u
n
n
i
n
g
_
v
a
r
running\_var
running_var 的方差要采用无偏估计计算
‘’’
'''
由于不同维度的BatchNorm统一极为简单,只需要将通道后面的维度摊平即可,
因为不需要考虑他们的位置,所以不同维度下的BatchNorm过程可以统一写,可以把计算过程直接写在AbsBatchNorm里:
所有参数均与nn.BatchNorm{1,2,3}d相同,
affine表示规范化后是否进行仿射变换,
track_running_stats表示是否记录滑动平均
如果在训练,就采用规范化,
如果在预测,若track_running_stats ,
则直接用训练中记录的样本和方差(running_mean,running_var)进行规范化,
否则仍然像训练一样计算
affine在训练和预测中都是一样的
具体实现如下:
'''
class AbsBatchNorm(AbsNet):
def __init__(self,num_features,eps,momentum,affine,track_running_stats,dim):
self.num_features=num_features
self.eps=eps
self.momentum=momentum
self.affine=affine
self.track_running_stats=track_running_stats
self.dim=dim
self.training=True
if self.affine:
self.parameters={}
self.parameters["weight"]=Tensor([1.]*num_features)
self.parameters["bias"]=Tensor([0.]*num_features)
if self.track_running_stats:
self.running_mean=Tensor([0.]*num_features)
self.running_var=Tensor([1.]*num_features)
def _normalize(self,x):
'''计算均值和方差'''
N=x.size//x.shape[1]
self.cmean=x.mean(axis=(0,*range(2,x.ndim)),)
self.cvar=x.var(axis=(0,*range(2,x.ndim)))
if self.track_running_stats:
self.running_mean=\
(1-self.momentum)*self.running_mean+self.momentum*self.cmean
'''采用无偏估计'''
self.running_var=\
(1-self.momentum)*self.running_var+self.momentum*self.cvar*N/(N-1)
self.cmean=self.cmean.reshape(1,x.shape[1],*(1,)*(x.ndim-2))
self.cvar=self.cvar.reshape(1,x.shape[1],*(1,)*(x.ndim-2))
return (x-self.cmean)/sqrt(self.cvar+self.eps)
def _affine(self,x):
weight=self.parameters["weight"].reshape(1,x.shape[1],*(1,)*(x.ndim-2))
bias=self.parameters["bias"].reshape(1,x.shape[1],*(1,)*(x.ndim-2))
return x*weight+bias
def __repr__(self):
return f"BatchNorm{self.dim}d({self.num_features}, eps={self.eps}, "+\
f"momentum={self.momentum}, affine={self.affine}, track_running_stats={self.track_running_stats})"
def _check_input_dim(self,x):pass
def __call__(self,x):
self._check_input_dim(x)
self.input=x
self.output=self.forward(x)
return self.output
def forward(self,x):
'''
只有在预测时且记录了running信息,才使用running_...来规范化,否则都使用数据的均值方差来规范化
'''
if not self.training and self.track_running_stats:
out=x-self.running_mean.reshape(1,x.shape[1],*(1,)*(x.ndim-2))
out/=sqrt(self.running_var.reshape(1,x.shape[1],*(1,)*(x.ndim-2))+self.eps)
else:
out=self._normalize(x)
self.normalized=out
if self.affine:
out=self._affine(out)
return out
def backward(self,cgrad):
'''
对每个元素有
FP: out = (x-cmean)/sqrt(cvar+eps)*weight+bias
可见每个元素都是线性变换且一一对应,所以BP过程很简单,
但需要注意:
1.由于FP利用了广播机制,parameters和grad形状不同,
所以形状需要调整
2.BP时,请注意cmean 和 cvar并不是常数!
所以每个元素都是输入层同一通道所有元素的函数,
我们将FP写得更详细一点:
cmean=sum(xi)/N
cvar= sum((xi-cmean)**2)/N
其中 N=batch_size*h*w*...(不包含通道维度的所有维度数乘积)
sum(xi),表示求出i=1,...,N 的所有xi的和
outi=(xi-cmean)/sqrt(cvar+eps)
可以看到每一步都是简单函数求导,
使用多元函数链式法则求导即可,
最后注意把每个位置对同一个位置的导数加起来即可,
注意当前位置元素对对应位置的导数和其他位置是不一样的!
由于过程比较多就不写出来了,大家可以自行计算,在这里给出化简后的结果:
d(outi)/dxi=
[N*cgrad - sum(cgrad*(xi-cmean))/sqrt(cvar+eps)-sum(cgrad)]/[N*sqrt(cvar+eps)]
其中 sum(cgrad) 表示对通道层求和
'''
if self.affine:
self.parameters["weight"].grad +=(cgrad * self.normalized).sum(axis=(0,*range(2,cgrad.ndim)))
self.parameters["bias"].grad+=cgrad.sum(axis=(0,*range(2,cgrad.ndim)))
cgrad*=self.parameters["weight"].reshape(1,cgrad.shape[1],*(1,)*(cgrad.ndim-2))
N=cgrad.size//cgrad.shape[1]
grad=N*cgrad
temp=(cgrad*(self.input-self.cmean)).sum(axis=(0,*range(2,cgrad.ndim)),keepdims=True)
grad-=temp*self.normalized/sqrt(self.cvar+self.eps)
grad-=cgrad.sum(axis=(0,*range(2,cgrad.ndim)),keepdims=True)
grad/=(N*sqrt(self.cvar+self.eps))
self.input.grad+=grad
return self.input.grad
@property
def zero_grad_(self):
self.input.zero_grad_
if self.affine:
self.parameters["weight"].zero_grad_
self.parameters["bias"].zero_grad_
2.实现BatchNorm2d
class BatchNorm2d(AbsBatchNorm):
def __init__(self,num_features,eps=1e-05,momentum=0.1,affine=True,track_running_stats=True):
super().__init__(num_features,eps,momentum,affine,track_running_stats,dim=2)
def _check_input_dim(self,x):
assert x.ndim!=4 ,f"Expect 4D tensor but get {x.ndim}D"
验证环节!!
下面我们来一一验证Conv2d,MaxPool2d,AvgPool2d,BatchNorm2d的正确性
1. Conv2d
'''
因为dilation参数需要很大的输入图像,不方便展示,大家可以自行测试
'''
img=torch.randn(2,2,5,5,requires_grad=True)
myimg=Tensor(img.data.numpy())
conv=nn.Conv2d(2,2,3,padding=2,stride=2)
myconv=Conv2d(2,2,3,padding=2,stride=2)
'''初始化参数要和conv一样'''
myconv.parameters["weight"]=Tensor(conv.weight.data.numpy())
myconv.parameters["bias"]=Tensor(conv.bias.data.numpy())
'''FP'''
out=conv(img)
myout=myconv(myimg)
'''BP'''
out.backward(torch.ones_like(out))
myconv.backward(Tensor(np.ones_like(myout)))
'''设置输出精度为4位'''
np.set_printoptions(precision=4)
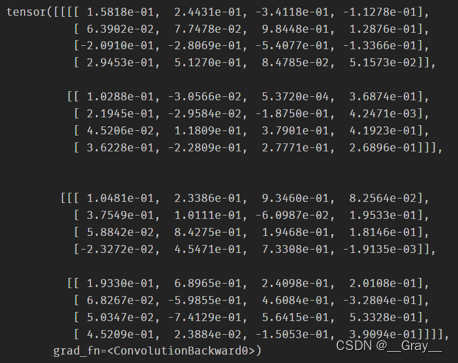
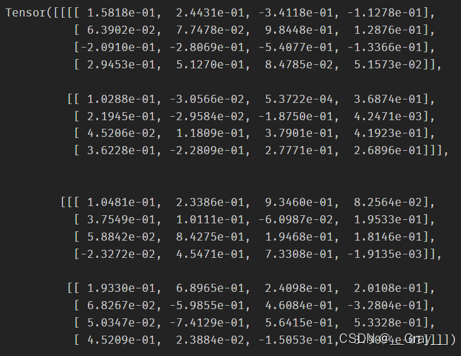
FP结果:
print(out,myout)
out:
myout:
BP结果:
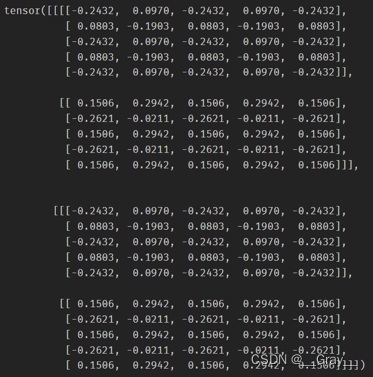
图像层导数:
print(img.grad,myimg.grad)
img.grad:
myimg.grad:
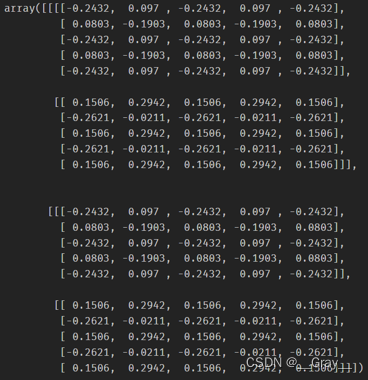
卷积核导数:
print((conv.weight.grad,conv.bias.grad),
(myconv.parameters["weight"].grad,myconv.parameters["bias"].grad))
conv.weight.grad 和 conv.bias.grad:
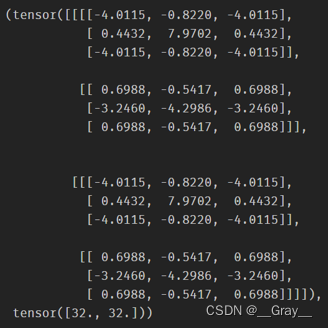
myconv.parameters[“weight”].grad 和
myconv.parameters[“bias”].grad :

2. MaxPool2d
img.grad.zero_()
myimg.zero_grad_
maxp=nn.MaxPool2d(3,1)
mymaxp=MaxPool2d(3,1)
'''FP'''
out=maxp(img)
myout=mymaxp(myimg)
'''BP'''
out.backward(out)
mymaxp.backward(myout)
print(out,myout)
out:
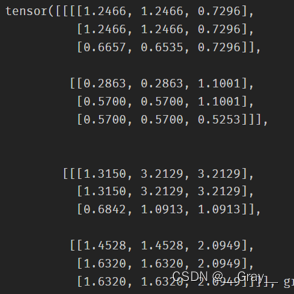
myout:
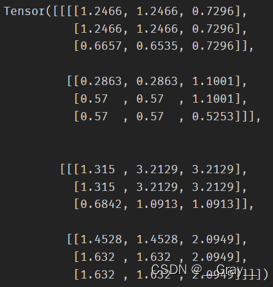
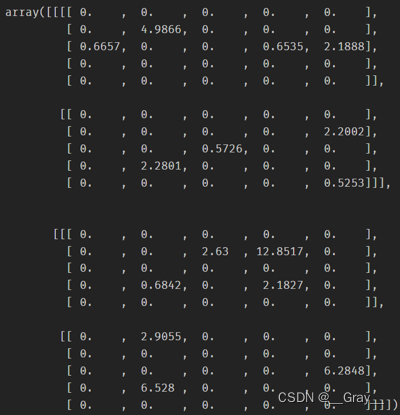
print(img.grad,myimg.grad)
img.grad:
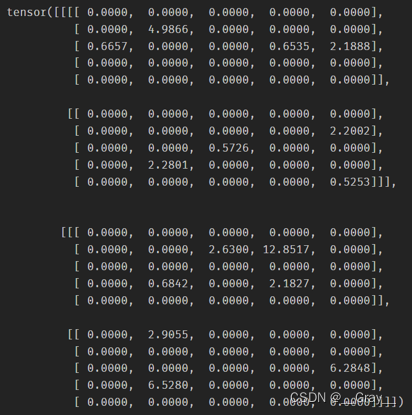
myimg.grad:
3. AvgPool2d
img.grad.zero_()
myimg.zero_grad_
avgp=nn.AvgPool2d(3,1)
myavgp=AvgPool2d(3,1)
'''FP'''
out=avgp(img)
myout=myavgp(myimg)
'''BP'''
out.backward(out)
myavgp.backward(myout)
print(out,myout)
out:
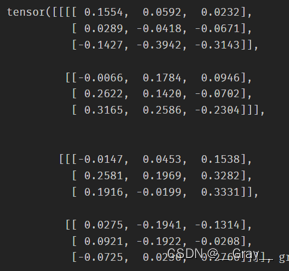
myout:

print(img.grad,myimg.grad)
img.grad:
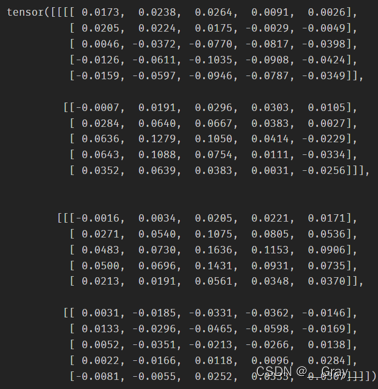
myimg.grad:
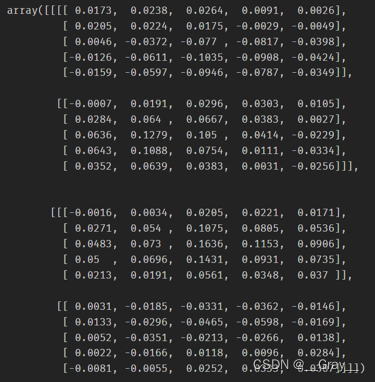
4. BatchNorm2d
img.grad.zero_()
myimg.zero_grad_
bn=nn.BatchNorm2d(num_features=2,eps= 1e-05,momentum= 0.1,affine = True,
track_running_stats= True)
mybn=BatchNorm2d(num_features=2,eps= 1e-05,momentum= 0.1,affine = True,
track_running_stats= True)
cgrad=torch.randn(*out.shape)
mycgrad=Tensor(cgrad.data.numpy())
'''FP'''
out=bn(img)
myout=mybn(myimg)
'''BP'''
out.backward(cgrad)
mybn.backward(mycgrad)
print(out,myout)
out:
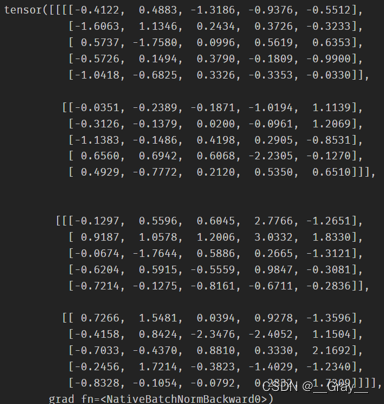
myout:
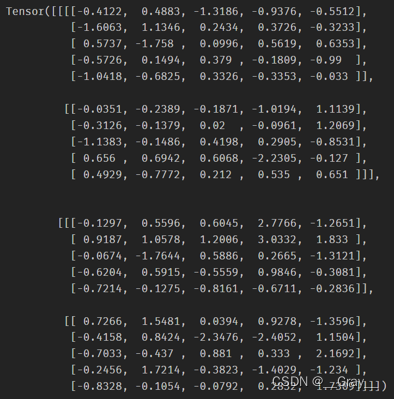
图像层导数
print(img.grad,myimg.grad)
img.grad:
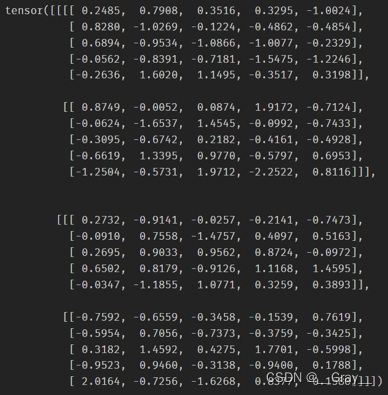
myimg.grad:
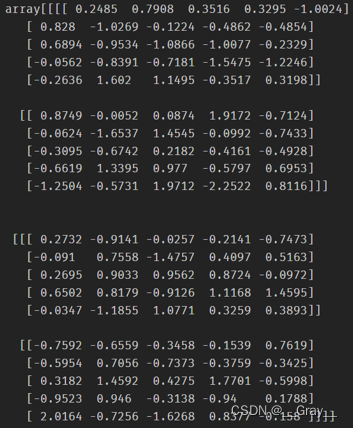
a f f i n e affine affine 仿射变换参数的导数 :
print((bn.weight.grad,bn.bias.grad),
(mybn.parameters["weight"].grad,mybn.parameters["bias"].grad))
bn.weight.grad 和 bn.bias.grad:

mybn.parameters[“weight”].grad 和 mybn.parameters[“bias”].grad:

r u n n i n g _ m e a n running\_mean running_mean 和 r u n n i n g _ v a r running\_var running_var (训练过程中的滑动平均):
print((bn.running_mean,bn.running_var),
(mybn.running_mean,mybn.running_var))
bn.running_mean 和 bn.running_var:
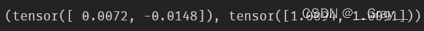
mybn.running_mean 和 mybn.running_var:

至此经过验证全部正确!!!
在mnist手写数字数据集上训练!!!
1.定义数据集和本问题的网络
从这里开始可以对比torch代码查看
'''
手写数字数据集图像大小为(28,28)且没有通道维度,需要添加通道维度
'''
class Dataset:
def __init__(self,mnist_datas):
self.datas=mnist_datas
def __len__(self,):
return len(self.datas)
def __getitem__(self,i):
img,label=self.datas[i]
return Tensor(np.array(img))[None,:,:],Tensor([label])
'''
定义数据transform
对数据进行规范化,手写数字数据集的图像像素值全是0和255
'''
def trans(x):
x=np.array(x,dtype=np.float32)/255
x=(x-0.5)/0.5
return x
'''定义本问题的网络'''
class conv_block(Module):
def __init__(self,in_channels,out_channels,stride=1,padding=1):
self.conv=Conv2d(in_channels,out_channels,3,stride=stride,padding=padding)
self.bn=BatchNorm2d(out_channels)
self.relu=ReLU()
def forward(self,x):
out=self.relu(self.bn(self.conv(x)))
return out
class Net(Sequential):
def __init__(self):
super().__init__(
Conv2d(1,32,kernel_size=3,stride=2,padding=1),#(32,14,14)
MaxPool2d(kernel_size=3,stride=2),#(32,6,6)
conv_block(32,64,2),#(64,3,3)
AvgPool2d(3),
Flatten(start_dim=1),
Linear(64,10)
)
2.定义训练、预测函数
'''
定义误差积累类,用来计算同一个epoch的误差
[参考李沐老师的动手深度学习实现]
'''
class Accumulater:
def __init__(self,n):
self.data=[0.]*n
def add(self,*args):
self.data=[o+float(m) for o,m in zip(self.data,args)]
def __getitem__(self,i):
return self.data[i]
'''定义训练函数,两个优化器都可以'''
def train(net,data_iter,lr,num_epochs):
# optimizer=Mini_BGD(net,lr=lr)
optimizer=AdamW(net,lr=lr)
loss=CrossEntropyLoss(net,reduction="sum")
loss_lst=[]
net.train()
for e in range(num_epochs):
metric=Accumulater(2)
for x,y in data_iter:
l=loss(net(x),y)
optimizer.zero_grad()
loss.backward()
optimizer.step()
metric.add(l.sum(),x.shape[0])
loss_lst+=[metric[0]/metric[1]]
if e%5==0:
print(f"Epoch:{e} Loss:",loss_lst[-1])
plt.xlabel("num_epochs")
plt.ylabel("loss")
plt.plot(loss_lst)
plt.show()
print("final loss:",loss_lst[-1])
return net
'''定义预测函数''
def predict(net,tst_data_iter):
R=0
All=0
net.eval()
for x,y in tst_data_iter:
y_pre=net(x).argmax(-1)
if y_pre.item()==y.item():R+=1
All+=1
print("Accuracy:",f'{R/All:.6f}')
3.训练并预测
实际上mnist数据集有专门的测试集,但是因为数据量太大,卷积网络和池化计算慢,因此我们将mnist的训练集分成两部分,前1500为训练集,1500之后(1500-60000)测试集,可以看到即使测试集远远超过了训练集,采用卷积网络也能达到90%以上的预测准确率!!
if __name__=="__main__":
train_set = mnist.MNIST('./data', train=True, transform=trans, download=True)
dset=Dataset(train_set)
'''
由于我们写的网络基于numpy,训练速度比较慢,只在前1500个数据上训练
但仍然需要很久,建议调成200左右
'''
data_iter=DataLoader(dset,batch_size=10,sampler=range(1500))
net=Net()
print(net)
net=train(net,data_iter,0.01,30)
'''在1500之后的全部数据集上进行预测'''
predict(net,DataLoader(Dataset(train_set),batch_size=1,sampler=range(1500,60000)))
运行结果(依次显示):
Net(
(0): Conv2d(1, 32, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1))
(1): MaxPool2d(kernel_size=3, stride=2, padding=0, ceil_mode=False)
(2): conv_block(
(conv): Conv2d(32, 64, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1))
(bn): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU()
)
(3): AvgPool2d(kernel_size=3, stride=3, padding=0)
(4): Flatten(start_dim=1, end_dim=-1)
(5): Linear(in_features=64, out_features=10, bias=True)
)
Epoch:0 Loss: 1.340585384495729
Epoch:5 Loss: 0.13921133203361882
Epoch:10 Loss: 0.020423666107907926
Epoch:15 Loss: 0.001857435497068079
Epoch:20 Loss: 0.0009473942800860873
Epoch:25 Loss: 0.0005541677277146111
loss曲线:
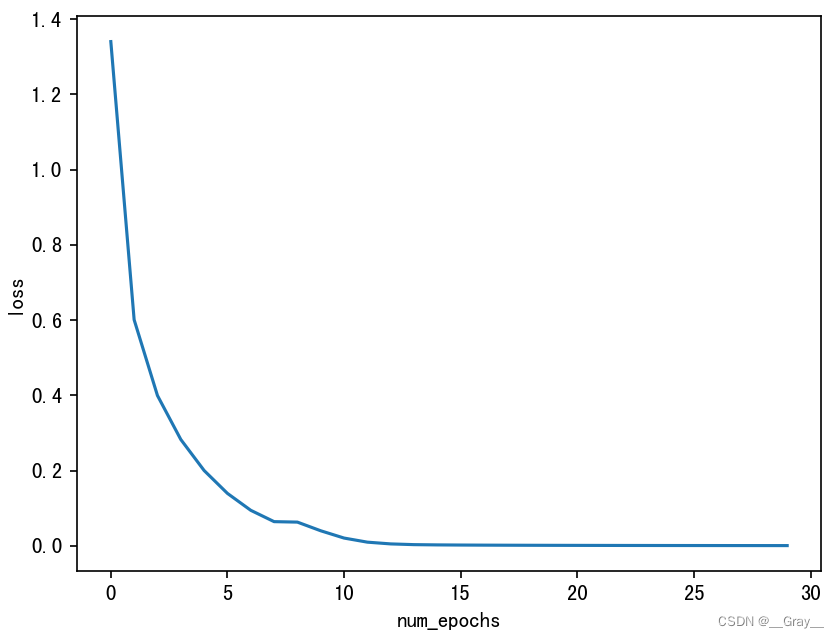
final loss: 0.0003739399661963382
Accuracy: 0.924752
附录
完整代码(main.py)
#!/usr/bin/env python
# coding: utf-8
# author: iiGray
import numpy as np
import math,time
import matplotlib.pyplot as plt
from collections import defaultdict,OrderedDict
from abc import ABC,abstractmethod,abstractproperty
from mytorch import *
from torchvision.datasets import mnist
class AbsConv(AbsNet):
def __init__(self,in_channels,out_channels,
kernel_size,stride,padding,dilation,bias,dim):
assert type(kernel_size)==int or \
type(kernel_size[0])==int,"kernel_size must be type 'int'"
assert type(stride)==int or \
type(stride[0])==int,"stride must be type 'int'"
assert type(padding)==int or \
type(padding[0])==int,"padding must be type 'int'"
assert type(dilation)==int or \
type(dilation[0])==int,"dilation must be type 'int'"
self.in_channels=in_channels
self.out_channels=out_channels
self.kernel_size=(kernel_size,)*dim \
if type(kernel_size)==int else kernel_size
self.stride=(stride,)*dim \
if type(stride)==int else stride
self.padding=(padding,)*dim \
if type(padding)==int else padding
self.dilation=(dilation,)*dim \
if type(dilation)==int else dilation
self.getIndex=getattr(self,f"getIndex{dim}d")
self.lastState=None
self.channel=None
self.row=None
self.col=None
self.bias=bias
self.parameters={}
def getIndex2d(self,c,h,w,kh,kw,sh,sw,oh,ow):
state=[c,h,w,kh,kw,sh,sw,oh,ow]
if self.lastState==state:
return self.channel,self.row,self.col
self.channel=Tensor([
[[ _ for kc in range(c) for _ in (kc,)*kh*kw]
for j in range(ow)]
for i in range(oh)])
self.row=Tensor([
[[t+i*sh for _ in range(kh) for t in [_]*kw]*c
for j in range(ow)]
for i in range(oh)])
self.col=Tensor([
[[t+j*sw for _ in range(kh) for t in range(kw)]*c
for j in range(ow)]
for i in range(oh)])
self.lastState=state
return self.channel,self.row,self.col
def __call__(self,x):
self.input=x
self.output=self.forward(x)
return self.output
def __repr__(self):
dilation="" if (len(set(self.dilation))==1 and self.dilation[0]==1)\
else f", dilation={self.dilation}"
return f"{self.__class__.__name__}({self.in_channels}, {self.out_channels}, "+\
f"kernel_size={self.kernel_size}, stride={self.stride}, "+\
f"padding={self.padding}{dilation})"
@property
def zero_grad_(self):
self.input.zero_grad_
self.parameters["weight"].zero_grad_
if self.bias:
self.parameters["bias"].zero_grad_
@abstractmethod
def _conv_forward(self,*args,**kwargs):pass
@abstractmethod
def _conv_backward(self,*args,**kwargs):pass
@abstractmethod
def _pad(self,*args,**kwargs):pass
@abstractmethod
def _dilate(self,*args,**kwargs):pass
class AbsPooling(AbsNet):
def __init__(self,kernel_size,stride,padding,dilation,dim):
assert type(kernel_size)==int or \
type(kernel_size[0])==int,"kernel_size must be type 'int'"
assert type(stride)==int or \
type(stride[0])==int,"stride must be type 'int'"
assert type(padding)==int or \
type(padding[0])==int,"padding must be type 'int'"
assert type(dilation)==int or \
type(dilation[0])==int,"dilation must be type 'int'"
self.kernel_size=(kernel_size,)*dim \
if type(kernel_size)==int else kernel_size
self.stride=(stride,)*dim \
if type(stride)==int else stride
self.padding=(padding,)*dim \
if type(padding)==int else padding
self.dilation=(dilation,)*dim \
if type(dilation)==int else dilation
'''避免重复计算'''
self.lastState=None
self.channel=None
self.row=None
self.col=None
self.getIndex=getattr(self,f"getIndex{dim}d")
'''和conv里的getIndex不一样,但基本思路相同,我们希望取出的索引形状为(c,oh,ow,kh*kw)'''
def getIndex2d(self,c,h,w,kh,kw,sh,sw,oh,ow):
state=[c,h,w,kh,kw,sh,sw,oh,ow]
if self.lastState==state:
return self.channel,self.row,self.col
self.channel=Tensor([
[[[kc]*kh*kw
for j in range(ow)]
for i in range(oh)]
for kc in range(c)])
self.row=Tensor([
[[[t+i*sh for t in range(kh) for _ in range(kw)]
for j in range(ow)]
for i in range(oh)]
for kc in range(c)])
self.col=Tensor([
[[[t+j*sw for _ in range(kh) for t in range(kw)]
for j in range(ow)]
for i in range(oh)]
for kc in range(c)])
self.lastState=state
return self.channel,self.row,self.col
def __call__(self,x):
self.input=x
self.output=self.forward(x)
return self.output
def __repr__(self):
kernel_size=self.kernel_size
if len(set(kernel_size))==1:kernel_size=kernel_size[0]
stride=self.stride
if len(set(stride))==1:stride=stride[0]
padding=self.padding
if len(set(padding))==1:padding=padding[0]
dilation=""
if hasattr(self,dilation):
dilation=self.dilation
if len(set(dilation))==1:dilation=dilation[0]
dilation=f", dilation={dilation}"
ceil_mode="" if (not hasattr(self,"ceil_mode"))\
else f", ceil_mode={self.ceil_mode}"
return f"{self.__class__.__name__}(kernel_size={kernel_size}, stride={stride}, "+\
f"padding={padding}{dilation}{ceil_mode})"
@property
def zero_grad_(self):
self.input.zero_grad_
@abstractmethod
def _pad(self,*args,**kwargs):pass
@abstractmethod
def _dilate(self,*args,**kwargs):pass
class AbsFlatten(AbsNet):
def __call__(self,x):
return self.forward(x)
def __repr__(self):
return f"Flatten(start_dim={self.start_dim}, "+\
f"end_dim={self.end_dim})"
@property
def zero_grad_(self):
self.input.zero_grad_
class Conv2d(AbsConv):
def __init__(self,in_channels,out_channels,
kernel_size,stride=1,padding=0,dilation=1,bias=True):
super().__init__(in_channels,out_channels,
kernel_size,stride,padding,dilation,bias,dim=2)
bound=1/math.sqrt(in_channels*self.kernel_size[0]*self.kernel_size[1])
self.parameters["weight"]=Tensor((np.random.rand(out_channels,in_channels,*self.kernel_size)-0.5)*2*bound)
if self.bias:
self.parameters["bias"]=Tensor((np.random.rand(out_channels)-0.5)*2*bound)
'''_pad默认填充0'''
def _pad(self,x,ph,pw):
if x.ndim==3:c,h,w=x.shape
else:bs,c,h,w=x.shape
'''计算padding之后的图像高宽'''
oph=h+ph*2
opw=w+pw*2
if x.ndim==3:
self.pout=Tensor(np.zeros((c,oph,opw)))
self.pout[:,ph:ph+h,pw:pw+w]+=x
else:
self.pout=Tensor(np.zeros((bs,c,oph,opw)))
self.pout[:,:,ph:ph+h,pw:pw+w]+=x
return self.pout
'''dilate表示对卷积核膨胀,间隙默认填充0'''
def _dilate(self,x,dh,dw):
'''计算dilation之后的卷积核大小'''
oc,c,kh,kw=x.shape
okh=(kh-1)*dh+1
okw=(kw-1)*dw+1
self.dout=Tensor(np.zeros((oc,c,okh,okw)))
self.dout[:,:,::dh,::dw]+=self.parameters["weight"]
return self.dout
def _conv_forward(self,A,K,kh,kw,sh,sw,oc,oh,ow):
bs,c,h,w=A.shape
channel,row,col=self.getIndex(c,h,w,kh,kw,sh,sw,oh,ow)
self.FA=A[:,channel,row,col]#(bs,oh,ow,c*h*w)
FK=K.reshape(self.out_channels,-1)[None,:,:].repeat(bs,axis=0)
FA=self.FA.reshape(bs,-1,self.FA.shape[-1]).transpose(0,2,1)
'''这里matmul是批量矩阵乘法 (bs,d1,d2) x (bs,d2,d3) = (bs,d1,d3)'''
self.output=matmul(FK,FA).reshape(bs,oc,oh,ow)
if self.bias:
self.output+=self.parameters["bias"][None,:,None,None]
return self.output
def forward(self,x):
assert len(x.shape)==4,"The input Tensor must be 3-dimensional!"
bs,c,h,w=x.shape
oc,kh,kw=(self.out_channels,*self.kernel_size)
sh,sw=self.stride
ph,pw=self.padding
dh,dw=self.dilation
dkh,dkw=(kh-1)*dh+1,(kw-1)*dw+1
oh=(h+ph*2-dkh)//sh+1
ow=(w+pw*2-dkw)//sw+1
'''
PA : padded A
DK : dilated K
'''
self.PA=self._pad(x,ph,pw)
self.DK=self._dilate(self.parameters["weight"],dh,dw)
return self._conv_forward(self.PA,self.DK,dkh,dkw,sh,sw,oc,oh,ow)
def _rotpi(self,x):
if x.ndim==3:
return x[:,::-1,::-1]
return x[:,:,::-1,::-1]
def _conv_backward(self,cgrad,kh,kw,sh,sw,ph,pw,dh,dw,oc,oh,ow):
bs,c,h,w=self.input.shape
pah,paw=h+2*ph,w+2*pw
dkh,dkw=(kh-1)*dh+1,(kw-1)*dw+1
MLO=cgrad.reshape(bs,oc,-1)#shape:(bs,oc,oh*ow)
MFA=self.FA.reshape(bs,-1,self.FA.shape[-1]) #shape:(bs,oh*ow,c*okh*okw)
DKgrad=(matmul(MLO,MFA)).reshape(bs,oc,c,dkh,dkw).sum(axis=0)
self.parameters["weight"].grad+=DKgrad[:,:,::dh,::dw]
if self.bias:
self.parameters["bias"].grad+=MLO.sum(axis=-1).sum(0)
'''求出对上一图像层的导数'''
MDK=self.DK.reshape(-1,dkh,dkw) #shape:(oc*c,dkh,dkw)
MRDK=self._rotpi(MDK)
MPRDK=self._pad(MRDK,pah-dkh,paw-dkw) #shape:(oc*c,2*pah-dkh,2*paw-dkw)
PRDK=MPRDK.reshape(oc,c,2*pah-dkh,2*paw-dkw) #shape:(oc,c,2*pah-dkh,2*paw-dkw)
'''取卷积序的索引'''
channel,row,col=self.getIndex(c,2*pah-dkh,2*paw-dkw,pah,paw,sh,sw,oh,ow)
PRAgrad=Tensor(np.zeros((bs,c,pah,paw)))
for b in range(bs):
for i in range(oc):
PRDKi=PRDK[i][channel,row,col] #shape:(oh,ow,c*pah*paw)
PRAgrad[b]+=(MLO[b,i] @ PRDKi.reshape(oh*ow,-1)).reshape(c,pah,paw)
PAgrad=self._rotpi(PRAgrad)
self.input.grad+=PAgrad[:,:,ph:ph+h,pw:pw+w]
return self.input.grad
def backward(self,cgrad):
bs,c,h,w=self.input.shape
oc,kh,kw=(self.out_channels,*self.kernel_size)
sh,sw=self.stride
ph,pw=self.padding
dh,dw=self.dilation
oh=(h+2*ph-((kh-1)*dh+1))//sh+1
ow=(w+2*pw-((kw-1)*dw+1))//sw+1
return self._conv_backward(cgrad,kh,kw,sh,sw,ph,pw,dh,dw,oc,oh,ow)
class MaxPool2d(AbsPooling):
def __init__(self,kernel_size,stride=None,padding=0,dilation=1):
stride=kernel_size if stride is None else stride
super().__init__(kernel_size,stride,padding,dilation,dim=2)
self.ceil_mode=False
self._kernel=Tensor(np.zeros(self.kernel_size))
def _pad(self,x,ph,pw):
'''计算padding之后的图像高宽'''
bs,c,h,w=x.shape
oph=h+ph*2
opw=w+pw*2
self.pout=Tensor(np.zeros((bs,c,oph,opw)))
self.pout[:,:,ph:ph+h,pw:pw+w]+=x
return self.pout
'''dilate表示对卷积核膨胀,由于是最大汇聚,间隙默认填充-inf'''
def _dilate(self,x,dh,dw):
'''计算dilation之后的卷积核大小'''
kh,kw=x.shape
okh=(kh-1)*dh+1
okw=(kw-1)*dw+1
self.dout=Tensor(np.array([-np.inf]).repeat(okh*okw).reshape(okh,okw))
self.dout[::dh,::dw]=self._kernel
return self.dout
def _maxpool_forward(self,A,K,kh,kw,sh,sw,oh,ow):
bs,c,h,w=A.shape
channel,row,col=self.getIndex(c,h,w,kh,kw,sh,sw,oh,ow)
self.FA=A[:,channel,row,col]#shape:(bs,c,oh,ow,kh*kw)
self.FA+=K.reshape(-1)
'''self.argmax是需要在反向传播里使用的,用于把最大值放回导数矩阵中'''
self.argmax=self.FA.argmax(axis=-1)
return self.FA.max(axis=-1)
def forward(self,x):
assert len(x.shape)==4,"The input Tensor must be 3-dimensional!"
bs,c,h,w=x.shape
kh,kw=self.kernel_size
sh,sw=self.stride
ph,pw=self.padding
dh,dw=self.dilation
dkh,dkw=(kh-1)*dh+1,(kw-1)*dw+1
oh=(h+ph*2-dkh)//sh+1
ow=(w+pw*2-dkw)//sw+1
self.PA=self._pad(x,ph,pw)
self.DK=self._dilate(self._kernel,dh,dw)
return self._maxpool_forward(self.PA,self.DK,dkh,dkw,sh,sw,oh,ow)
def _maxpool_backward(self,cgrad,c,h,w,kh,kw,sh,sw,ph,pw,dh,dw,oh,ow):
dkh,dkw=self.DK.shape
pmt1=Tensor([[*range(self.input.shape[0])]]*c).transpose(1,0)
pmt2=Tensor([[*range(c)]]*self.input.shape[0])
for i in range(oh):
for j in range(ow):
pi,pj=self.argmax[:,:,i,j]//dkw,self.argmax[:,:,i,j]%dkw
self.PA.grad[pmt1,pmt2,pi+i*sh,pj+j*sw]+=cgrad[:,:,i,j]
self.input.grad+=self.PA.grad[:,:,ph:ph+h,pw:pw+w]
return self.input.grad
def backward(self,cgrad):
bs,c,h,w=self.input.shape
kh,kw=self.kernel_size
sh,sw=self.stride
ph,pw=self.padding
dh,dw=self.dilation
oh=(h+2*ph-((kh-1)*dh+1))//sh+1
ow=(w+2*pw-((kw-1)*dw+1))//sw+1
return self._maxpool_backward(cgrad,c,h,w,kh,kw,sh,sw,ph,pw,dh,dw,oh,ow)
class AvgPool2d(AbsPooling):
def __init__(self,kernel_size,stride=None,padding=0,dilation=1):
stride=kernel_size if stride is None else stride
super().__init__(kernel_size,stride,padding,dilation,dim=2)
self._dilation=self.dilation
del self.dilation
self._kernel=Tensor(np.ones(self.kernel_size))
def _pad(self,x,ph,pw):
'''计算padding之后的图像高宽'''
bs,c,h,w=x.shape
oph=h+ph*2
opw=w+pw*2
self.pout=Tensor(np.zeros((bs,c,oph,opw)))
self.pout[:,:,ph:ph+h,pw:pw+w]+=x
return self.pout
'''dilate表示对卷积核膨胀,由于是平均,间隙默认填充 inf(这是为了求倒数为0) '''
def _dilate(self,x,dh,dw):
'''计算dilation之后的卷积核大小'''
kh,kw=x.shape
okh=(kh-1)*dh+1
okw=(kw-1)*dw+1
self.dout=Tensor(np.array([np.inf]).repeat(okh*okw).reshape(okh,okw))
self.dout[::dh,::dw]=self._kernel
return self.dout
def _avgpool_forward(self,A,K,kh,kw,sh,sw,oh,ow):
bs,c,h,w=A.shape
channel,row,col=self.getIndex(c,h,w,kh,kw,sh,sw,oh,ow)
self.FA=A[:,channel,row,col]#shape:(bs,c,oh,ow,kh*kw)
self.FA*=K.reshape(-1)
return self.FA.sum(axis=-1)/self._kernel.size
def forward(self,x):
assert len(x.shape)==4,"The input Tensor must be 3-dimensional!"
bs,c,h,w=x.shape
kh,kw=self.kernel_size
sh,sw=self.stride
ph,pw=self.padding
dh,dw=self._dilation
dkh,dkw=(kh-1)*dh+1,(kw-1)*dw+1
oh=(h+ph*2-dkh)//sh+1
ow=(w+pw*2-dkw)//sw+1
self.PA=self._pad(x,ph,pw)
self.DK=self._dilate(self._kernel,dh,dw)
return self._avgpool_forward(self.PA,self.DK,dkh,dkw,sh,sw,oh,ow)
def _avgpool_backward(self,cgrad,c,h,w,kh,kw,sh,sw,ph,pw,dh,dw,oh,ow):
w=self._kernel.size
dkh,dkw=self.DK.shape
for i in range(oh):
for j in range(ow):
self.PA.grad[:,:,i*sh:kh+i*sh,j*sw:kw+j*sw]+=cgrad[:,:,i,j][:,:,None,None]/w
self.input.grad+=self.PA.grad[:,:,ph:ph+h,pw:pw+w]
return self.input.grad
def backward(self,cgrad):
bs,c,h,w=self.input.shape
kh,kw=self.kernel_size
sh,sw=self.stride
ph,pw=self.padding
dh,dw=self._dilation
oh=(h+2*ph-((kh-1)*dh+1))//sh+1
ow=(w+2*pw-((kw-1)*dw+1))//sw+1
return self._avgpool_backward(cgrad,c,h,w,kh,kw,sh,sw,ph,pw,dh,dw,oh,ow)
'''实现ReLU激活函数'''
class ReLU(AbsActivation):
def function(self,x):
return (x>0).astype(np.float32)*x
def forward(self,x):
return self.function(x)
def backward(self,cgrad):
assert self.output.shape==cgrad.shape,"Activation ReLU BP Error!"
try:
self.input.grad+=((self.output>0).astype(np.int32))*cgrad
except (AttributeError):
raise AttributeError("Layer: "+self.__repr()+" absent from FP!")
return self.input.grad
class Flatten(AbsFlatten):
def __init__(self,start_dim=1,end_dim=-1):
self.start_dim=start_dim
self.end_dim=end_dim
def forward(self,x):
self.input=x
if self.start_dim==self.end_dim:
return x
shape=list(x.shape)
l=shape[:self.start_dim]
r=shape[self.end_dim%len(shape)+1:]
out=x.reshape(*l,-1,*r)
return out
def backward(self,cgrad):
self.input.grad+=cgrad.reshape(self.input.shape)
return self.input.grad
class AbsBatchNorm(AbsNet):
def __init__(self,num_features,eps,momentum,affine,track_running_stats,dim):
self.num_features=num_features
self.eps=eps
self.momentum=momentum
self.affine=affine
self.track_running_stats=track_running_stats
self.dim=dim
self.training=True
if self.affine:
self.parameters={}
self.parameters["weight"]=Tensor([1.]*num_features)
self.parameters["bias"]=Tensor([0.]*num_features)
if self.track_running_stats:
self.running_mean=Tensor([0.]*num_features)
self.running_var=Tensor([1.]*num_features)
def _normalize(self,x):
'''计算均值和方差'''
N=x.size//x.shape[1]
self.cmean=x.mean(axis=(0,*range(2,x.ndim)),)
self.cvar=x.var(axis=(0,*range(2,x.ndim)))
if self.track_running_stats:
self.running_mean=\
(1-self.momentum)*self.running_mean+self.momentum*self.cmean
'''采用无偏估计'''
self.running_var=\
(1-self.momentum)*self.running_var+self.momentum*self.cvar*N/(N-1)
self.cmean=self.cmean.reshape(1,x.shape[1],*(1,)*(x.ndim-2))
self.cvar=self.cvar.reshape(1,x.shape[1],*(1,)*(x.ndim-2))
return (x-self.cmean)/sqrt(self.cvar+self.eps)
def _affine(self,x):
weight=self.parameters["weight"].reshape(1,x.shape[1],*(1,)*(x.ndim-2))
bias=self.parameters["bias"].reshape(1,x.shape[1],*(1,)*(x.ndim-2))
return x*weight+bias
def __repr__(self):
return f"BatchNorm{self.dim}d({self.num_features}, eps={self.eps}, "+\
f"momentum={self.momentum}, affine={self.affine}, track_running_stats={self.track_running_stats})"
def _check_input_dim(self,x):pass
def __call__(self,x):
self._check_input_dim(x)
self.input=x
self.output=self.forward(x)
return self.output
def forward(self,x):
'''
只有在预测时且记录了running信息,才使用running_...来规范化,否则都使用数据的均值方差来规范化
'''
if not self.training and self.track_running_stats:
out=x-self.running_mean.reshape(1,x.shape[1],*(1,)*(x.ndim-2))
out/=sqrt(self.running_var.reshape(1,x.shape[1],*(1,)*(x.ndim-2))+self.eps)
else:
out=self._normalize(x)
self.normalized=out
if self.affine:
out=self._affine(out)
return out
def backward(self,cgrad):
if self.affine:
self.parameters["weight"].grad +=(cgrad * self.normalized).sum(axis=(0,*range(2,cgrad.ndim)))
self.parameters["bias"].grad+=cgrad.sum(axis=(0,*range(2,cgrad.ndim)))
cgrad*=self.parameters["weight"].reshape(1,cgrad.shape[1],*(1,)*(cgrad.ndim-2))
N=cgrad.size//cgrad.shape[1]
grad=N*cgrad
temp=(cgrad*(self.input-self.cmean)).sum(axis=(0,*range(2,cgrad.ndim)),keepdims=True)
grad-=temp*self.normalized/sqrt(self.cvar+self.eps)
grad-=cgrad.sum(axis=(0,*range(2,cgrad.ndim)),keepdims=True)
grad/=(N*sqrt(self.cvar+self.eps))
self.input.grad+=grad
return self.input.grad
@property
def zero_grad_(self):
self.input.zero_grad_
if self.affine:
self.parameters["weight"].zero_grad_
self.parameters["bias"].zero_grad_
class BatchNorm2d(AbsBatchNorm):
def __init__(self,num_features,eps=1e-05,momentum=0.1,affine=True,track_running_stats=True):
super().__init__(num_features,eps,momentum,affine,track_running_stats,dim=2)
def _check_input_dim(self,x):
assert x.ndim==4 ,f"Expect 4D tensor but get {x.ndim}D"
'''------------------------------------------BEGIN------------------------------------'''
def trans(x):
x=np.array(x,dtype=np.float32)/255
x=(x-0.5)/0.5
return x
class Dataset:
def __init__(self,mnist_datas):
self.datas=mnist_datas
def __len__(self,):
return len(self.datas)
def __getitem__(self,i):
img,label=self.datas[i]
return Tensor(np.array(img))[None,:,:],Tensor([label])
class conv_block(Module):
def __init__(self,in_channels,out_channels,stride=1,padding=1):
self.conv=Conv2d(in_channels,out_channels,3,stride=stride,padding=padding)
self.bn=BatchNorm2d(out_channels)
self.relu=ReLU()
def forward(self,x):
out=self.relu(self.bn(self.conv(x)))
return out
class Net(Sequential):
def __init__(self):
super().__init__(
Conv2d(1,32,kernel_size=3,stride=2,padding=1),#(32,14,14)
MaxPool2d(kernel_size=3,stride=2),#(32,6,6)
conv_block(32,64,2),#(64,3,3)
AvgPool2d(3),
Flatten(start_dim=1),
Linear(64,10)
)
class Accumulater:
def __init__(self,n):
self.data=[0.]*n
def add(self,*args):
self.data=[o+float(m) for o,m in zip(self.data,args)]
def __getitem__(self,i):
return self.data[i]
def train(net,data_iter,lr,num_epochs):
# optimizer=Mini_BGD(net,lr=lr)
optimizer=AdamW(net,lr=lr)
loss=CrossEntropyLoss(net,reduction="sum")
loss_lst=[]
net.train()
for e in range(num_epochs):
metric=Accumulater(2)
for x,y in data_iter:
l=loss(net(x),y)
optimizer.zero_grad()
loss.backward()
optimizer.step()
metric.add(l,x.shape[0])
loss_lst+=[metric[0]/metric[1]]
if e%5==0:
print(f"Epoch:{e} Loss:\t",loss_lst[-1])
plt.xlabel("num_epochs")
plt.ylabel("loss")
plt.plot(loss_lst)
plt.show()
print("final loss:",loss_lst[-1])
return net
def predict(net,tst_data_iter):
R=0
All=0
net.eval()
for x,y in tst_data_iter:
y_pre=net(x).argmax(-1)
if y_pre.item()==y.item():R+=1
All+=1
print("Accuracy:",f'{R/All:.6f}')
if __name__=="__main__":
train_set = mnist.MNIST('./data', train=True, transform=trans, download=True)
dset=Dataset(train_set)
'''由于我们写的网络基于numpy,训练速度慢,只在前600个数据上训练'''
data_iter=DataLoader(dset,batch_size=10,sampler=range(1500))
net=Net()
print(net)
net=train(net,data_iter,0.01,30)
'''在1500之后的全部数据集上进行预测'''
predict(net,DataLoader(dset,batch_size=1,sampler=range(1500,60000)))
mytorch.py
【注】添加注释的为相比上次改动了的
#!/usr/bin/env python
# coding: utf-8
#author: iiGray
import numpy as np
import math,pickle,time
import matplotlib.pyplot as plt
from collections import defaultdict,OrderedDict
from abc import ABC,abstractmethod,abstractproperty
def add_grad(func):
def inner(self,*args,**kwargs):
ret=func(self,*args,**kwargs)
ret.detach=False
ret.grad=np.zeros(ret.shape)
return ret
return inner
def add_grad_inplace(func):
def inner(self, *args, **kwargs):
grad = self.grad
ret = Tensor(func(self, *args, **kwargs))
ret.grad = getattr(grad, func.__name__)(*args, **kwargs)
return ret
return inner
class Tensor(np.ndarray):
def __new__(cls,input_array,requires_grad=True):
if type(input_array)==tuple:
obj=np.random.randn(*input_array).view(cls)
else:
obj=np.asarray(input_array).view(cls)
obj.grad=np.zeros(obj.shape)
return obj
@add_grad
def mean(self,*args,**kwargs):
return super().mean(*args,**kwargs)
@add_grad
def var(self,*args,**kwargs):
return super().var(*args,**kwargs)
@add_grad
def std(self,*args,**kwargs):
return super().std(*args,**kwargs)
@add_grad
def sum(self,*args,**kwargs):
return super().sum(*args,**kwargs)
@add_grad
def __add__(self,*args,**kwargs):
return super().__add__(*args,**kwargs)
@add_grad
def __pow__(self,*args,**kwargs):
return super().__pow__(*args,**kwargs)
@add_grad
def __radd__(self,*args,**kwargs):
return super().__radd__(*args,**kwargs)
@add_grad
def __sub__(self,*args,**kwargs):
return super().__sub__(*args,**kwargs)
@add_grad
def __rsub__(self,*args,**kwargs):
return super().__rsub__(*args,**kwargs)
@add_grad
def __mul__(self,*args,**kwargs):
return super().__mul__(*args,**kwargs)
@add_grad
def __rmul__(self,*args,**kwargs):
return super().__rmul__(*args,**kwargs)
@add_grad
def __pow__(self,*args,**kwargs):
return super().__pow__(*args,**kwargs)
@add_grad
def __truediv__(self,*args,**kwargs):
return super().__truediv__(*args,**kwargs)
@add_grad
def __rtruediv__(self,*args,**kwargs):
return super().__rtruediv__(*args,**kwargs)
@add_grad
def __itruediv__(self,*args,**kwargs):
return super().__itruediv__(*args,**kwargs)
@add_grad
def __floordiv__(self,*args,**kwargs):
return super().__floordiv__(*args,**kwargs)
@add_grad
def __rfloordiv__(self,*args,**kwargs):
return super().__rfloordiv__(*args,**kwargs)
@add_grad
def __matmul__(self,*args,**kwargs):
return super().__matmul__(*args,**kwargs)
@add_grad
def __rmatmul__(self,*args,**kwargs):
return super().__rmatmul__(*args,**kwargs)
@add_grad
def __mod__(self,*args,**kwargs):
return super().__mod__(*args,**kwargs)
@add_grad
def __rmod__(self,*args,**kwargs):
return super().__rmod__(*args,**kwargs)
@add_grad
def __eq__(self,*args,**kwargs):
return super().__eq__(*args,**kwargs)
@add_grad
def __le__(self,*args,**kwargs):
return super().__le__(*args,**kwargs)
@add_grad
def __ge__(self,*args,**kwargs):
return super().__ge__(*args,**kwargs)
@add_grad
def __lt__(self,*args,**kwargs):
return super().__lt__(*args,**kwargs)
@add_grad
def __gt__(self,*args,**kwargs):
return super().__gt__(*args,**kwargs)
@add_grad
def max(self,*args,**kwargs):
return super().max(*args,**kwargs)
@add_grad
def argmax(self,*args,**kwargs):
return super().argmax(*args,**kwargs)
@add_grad_inplace
def transpose(self,*args,**kwargs):
return super().transpose(*args,**kwargs)
@add_grad_inplace
def reshape(self,*args,**kwargs):
return super().reshape(*args,**kwargs)
@add_grad_inplace
def repeat(self,*args,**kwargs):
return super().repeat(*args,**kwargs)
@add_grad_inplace
def astype(self,*args,**kwargs):
return super().astype(*args,**kwargs)
@add_grad_inplace
def __getitem__(self,*args,**kwargs):
return super().__getitem__(*args,**kwargs)
@property
def zero_grad_(self):
self.grad=np.zeros(self.grad.shape)
@property
def flatten(self):
return self.reshape(-1)
def exp(x):
return Tensor(np.exp(np.array(x)))
def log(x):
return Tensor(np.log(np.array(x)))
'''添加sqrt和matmul需要在实现BatchNorm中使用'''
def sqrt(x):
return Tensor(np.sqrt(np.array(x)))
def matmul(x,y):
return Tensor(np.matmul(np.array(x),np.array(y)))
class MyTorch(ABC):pass
'''
添加了train和eval方法,
为了区分模型在训练和预测时的两种状态
'''
class AbsNet(MyTorch):
@abstractmethod
def __init__(self,*args,**kwargs):pass
@abstractmethod
def __call__(self,*args,**kwargs):pass
@abstractmethod
def forward(self,*args,**kwargs):pass
@abstractmethod
def backward(self,*args,**kwargs):pass
def train(self):
self.training=True
def eval(self):
self.training=False
class AbsActivation(AbsNet):
def __init__(self,*args,**kwargs):pass
@abstractmethod
def function(self,*args,**kwargs):pass
def __call__(self,x):
self.input=x
self.output=self.forward(x)
return self.output
def __repr__(self):
return f"{self.__class__.__name__}()"
@property
def zero_grad_(self):
if "input" in self.__dict__.keys():
self.input.zero_grad_
class AbsModule(AbsNet):
@abstractproperty
def zero_grad_(self):pass
@abstractproperty
def __repr__(self):pass
class AbsContainer(AbsNet):
def __len__(self):return len(self._modules)
@property
def _modules(self):
if 'modules' not in self.__dict__:
self.modules=OrderedDict()
self._module_list=[]
return self.modules
def add_module(self,name,module):
if not isinstance(name,str):
raise TypeError("Input:name must be a string!")
if type(module).__base__.__base__ not in (AbsNet,AbsModule):
raise TypeError("Input:module must be a built-in module!")
self._modules[name]=module
self._module_list+=[module]
class AbsOptimizer(MyTorch):
@abstractmethod
def __init__(self,*args,**kwargs):pass
@abstractmethod
def _block_step(self,*args,**kwargs):pass
@abstractmethod
def step(self,*args,**kwargs):pass
def zero_grad(self):
self.parameters.zero_grad_
class AbsLoss(AbsNet):
@abstractproperty
def outgrad(self):pass
@abstractmethod
def forward(self,*args,**kwargs):pass
def __call__(self,*args,**kwargs):
return self.forward(*args,**kwargs)
def backward(self):
cgrad=self.outgrad
for block_name,block in reversed(self.net.__dict__.items()):
block_base=type(block).__base__
if block_base is dict:
for dic_block_name,dict_block in reversed(block.items()):
cgrad=dict_block.backward(cgrad)
elif block_base.__base__ in (AbsNet,AbsModule):
cgrad=block.backward(cgrad)
class Linear(AbsModule):
def __init__(self,in_features,out_features,bias=True):
self.in_features=in_features
self.out_features=out_features
self.bias=bias
'''使用和torch.nn.Linear中一样参数初始化:参数a=sqrt(5),mode='fan_in'的kaiming_uniform_初始化'''
bound=1/math.sqrt(in_features)
self.parameters={"weight":Tensor((np.random.rand(in_features,out_features)-0.5)*2*bound)}
if bias:
self.parameters["bias"]=Tensor((np.random.rand(1,out_features)-0.5)*2*bound)
def __call__(self,x):
self.input=x
self.output=self.forward(x)
return self.output
def forward(self,x):
out=x @ self.parameters["weight"]
if self.bias:
out+=self.parameters["bias"]
return out
def backward(self,cgrad):
try:
self.input.grad= cgrad @ self.parameters["weight"].T
except AttributeError:
raise AttributeError("The layer: "+self.__repr__()+" absent from FP!")
self.parameters["weight"].grad+= self.input.T @ cgrad
if self.bias:
self.parameters["bias"].grad+= cgrad.sum(0,keepdims=True)
return self.input.grad
def __repr__(self):
return f"Linear(in_features={self.in_features}, "+\
f"out_features={self.out_features}, bias={self.bias})"
@property
def zero_grad_(self):
if "input" in self.__dict__.keys():
self.input.zero_grad_
self.parameters["weight"].zero_grad_
if self.bias:
self.parameters["bias"].zero_grad_
class Sigmoid(AbsActivation):
def function(self,x):
return 1/(1+exp(-x))
def forward(self,x):
return self.function(x)
def backward(self,cgrad):
assert self.output.shape==cgrad.shape,"Activation Sigmoid BP Error!"
try:
self.input.grad=(self.output*(1-self.output))*cgrad
except (AttributeError):
raise AttributeError("Layer: " +self.__repr__()+" absent from FP!")
return self.input.grad
class Tanh(AbsActivation):
def function(self,x):
return (1-exp(-2*x))/(1+exp(-2*x))
def forward(self,x):
return self.function(x)
def backward(self,cgrad):
assert self.output.shape==cgrad.shape,"Activation Tanh BP Error!"
try:
self.input.grad=(1-self.output**2)*cgrad
except (AttributeError):
raise AttributeError("Layer: " +self.__repr__()+" absent from FP!")
return self.input.grad
'''实现ReLU激活函数'''
class ReLU(AbsActivation):
def function(self,x):
return (x>0).astype(np.float32)*x
def forward(self,x):
return self.function(x)
def backward(self,cgrad):
assert self.output.shape==cgrad.shape,"Activation ReLU BP Error!"
try:
self.input.grad=((self.output>0).astype(np.int32))*cgrad
except (AttributeError):
raise AttributeError("Layer: "+self.__repr()+" absent from FP!")
return self.input.grad
class Module(AbsModule):
def __init__(self, *args, **kwargs):
raise NotImplementedError("Class: \"Module\" has to be overrided!")
def __call__(self, *args, **kwargs):
return self.forward(*args, **kwargs)
def train(self):
for block_name,block in reversed(self.__dict__.items()):
if type(block).__base__.__base__ not in (AbsNet,AbsModule):continue
block.train()
def eval(self):
for block_name,block in reversed(self.__dict__.items()):
if type(block).__base__.__base__ not in (AbsNet,AbsModule):continue
block.eval()
def forward(self, *args, **kwargs):
raise NotImplementedError("Function: \"forward()\" has to be overloaded!")
def backward(self, cgrad):
for block_name, block in reversed(self.__dict__.items()):
if type(block).__base__.__base__ not in (AbsNet,AbsModule): continue
cgrad = block.backward(cgrad)
return cgrad
def __repr__(self):
name = f"{self.__class__.__name__}(\n"
for block_name, block in self.__dict__.items():
if type(block).__base__.__base__ not in (AbsNet,AbsModule): continue
block_repr = "\n ".join(block.__repr__().split('\n'))
name += " (" + str(block_name) + "): " + block_repr + "\n"
return name + ")"
@property
def zero_grad_(self):
for block_name, block in self.__dict__.items():
if type(block).__base__.__base__ not in (AbsNet,AbsModule): continue
block.zero_grad_
'''
相比上次添加了,__getitem__方法,
使其可以索引访问Sequential的每个块
'''
class Sequential(AbsContainer,AbsModule):
def __init__(self, *args):
if len(args) == 1 and isinstance(args[0],OrderedDict):
for name, module in args[0].items():
self.add_module(name, module)
else:
for idx, module in enumerate(args):
self.add_module(f'{idx}', module)
def append(self, module):
self.add_module(f'{len(self)}', module)
def train(self):
for idx, block in self.modules.items():
if type(block).__base__.__base__ not in (AbsNet,AbsModule): continue
block.train()
def eval(self):
for idx, block in self.modules.items():
if type(block).__base__.__base__ not in (AbsNet,AbsModule): continue
block.eval()
def __getitem__(self,i):
return self._module_list[i]
def __call__(self, *args, **kwargs):
return self.forward(*args, **kwargs)
def forward(self, x):
out = x
for idx, block in self.modules.items():
out = block(out)
return out
def backward(self, cgrad):
for idx, block in reversed(self.modules.items()):
if type(block).__base__.__base__ not in (AbsNet,AbsModule):
continue
cgrad = block.backward(cgrad)
return cgrad
def __repr__(self):
name = f"{self.__class__.__name__}(\n"
for idx, block in self.modules.items():
if type(block).__base__.__base__ not in (AbsNet,AbsModule):
continue
block_repr = "\n ".join(block.__repr__().split('\n'))
name += " (" + str(idx) + "): " + block_repr + "\n"
return name + ")"
@property
def zero_grad_(self):
for idx, block in self.modules.items():
if type(block).__base__.__base__ not in (AbsNet,AbsModule): continue
block.zero_grad_
class BCEWithLogitsLoss(AbsLoss):
def __init__(self,net,reduction="none"):
self.net=net
self.reduction=reduction
self.function=Sigmoid()
def forward(self,y,y_hat):
self.out=y
self.hat=y_hat
p=self.function(y)
ret=-(y_hat*log(p)+(1-y_hat)*log(1-p))
if self.reduction=="mean":return ret.mean()
elif self.reduction=="sum":return ret.sum()
return ret
@property
def outgrad(self):
out=self.out
hat=self.hat
out.grad=(self.function(out)-hat)/out.shape[0]
return out.grad
class Softmax(AbsModule):
def __init__(self,dim=None):
'''dim 是softmax函数的作用维度'''
self.dim=dim
def __call__(self,x):
if self.dim is None:
self.dim=x.ndim-1
self.input=x
self.output=self.forward(x)
return self.output
def forward(self,x):
self.ex=exp(x)
self.sex=self.ex.sum(axis=self.dim,keepdims=True)
return self.ex/self.sex
def backward(self,cgrad):
self.input.grad+=(self.ex*(self.sex-self.ex)/(self.sex*self.sex))
self.input.grad*=cgrad
return self.input.grad
def __repr__(self):
return f"Softmax(dim={self.dim})"
@property
def zero_grad_(self):
self.input.zero_grad_
'''实现交叉熵损失函数,请注意,交叉熵损失函数内部会自动加上Softmax'''
class CrossEntropyLoss(AbsLoss):
def __init__(self,net,reduction="none"):
self.net=net
self.reduction=reduction
self.function=Softmax(None)
'''独热编码,需要把标签转换成独热的形式'''
def one_hot(self,y,num_classes):
l=num_classes
onehot=y.repeat(l,axis=-1).reshape(*list(y.shape)[:-1],l)
sz,isz=onehot.size,onehot.shape[-1]
ran=np.arange(isz).repeat(sz//isz).reshape(isz,-1).T.reshape(*onehot.shape)
onehot=(onehot==Tensor(ran)).astype(np.int32)
onehot=onehot.reshape(self.out.shape)
return onehot
def forward(self,y,y_hat):
self.out=y
self.hat=self.one_hot(y_hat,y.shape[-1])
p=log(self.function(y))
ret=-(p*self.hat).sum(axis=-1)
if self.reduction=="mean":return ret.mean()
elif self.reduction=="sum":return ret.sum()
return ret
@property
def outgrad(self):
out=self.out
hat=self.hat
out.grad=(self.function(out)-hat)/out.shape[0]
return out.grad
class Mini_BGD(AbsOptimizer):
def __init__(self,net,lr=0.001):
self.parameters=net
self.lr=lr
def _block_step(self,module):
for block_name,block in module.items():
block_base=type(block).__base__
if block_base is Module:
self._block_step(block.__dict__)
continue
elif block_base is AbsContainer:
self._block_step(block.modules)
continue
elif block_base is dict:
self._block_step(block)
continue
if (block_base.__base__ is not AbsNet) or (not hasattr(block,"parameters")):
continue
for name,weight in block.parameters.items():
weight-=self.lr*weight.grad
def step(self):
self._block_step(self.parameters.__dict__)
class AdamW(AbsOptimizer):
def __init__(self,net,lr=0.01,betas=(0.9,0.999),eps=1e-08,weight_decay=0.01):
self.parameters=net
self.lr=lr
self.betas=betas
self.eps=eps
self.weight_decay=weight_decay
self.t=0
self.mt=defaultdict(dict)
self.vt=defaultdict(dict)
'''init_parameters是为了初始化self.mt和self.vt的,
采用递归实现也是为了解决Sequential的嵌套问题'''
self.init_parameters(net.__dict__,"")
def init_parameters(self,module_dict,cname):
'''cname记录当前的module或者容器的'目录+名称',
我们之前实现的所有__repr__方法可以保证任何两个不同的模块都不同名'''
for block_name,block in module_dict.items():
block_base=type(block).__base__
if block_base is Module:
self.init_parameters(block.__dict__,cname+block_name)
continue
elif block_base is AbsContainer:
self.init_parameters(block.modules,cname+block_name)
continue
elif block_base is dict:
self.init_parameters(block,cname+block_name)
continue
if (block_base.__base__ is not AbsNet) or (not hasattr(block,"parameters")):
continue
for name,weight in block.parameters.items():
self.mt[cname+block_name][name]=np.zeros_like(weight)
self.vt[cname+block_name][name]=np.zeros_like(weight)
def _block_step(self,module_dict,cname,beta1,beta2,t):
for block_name,block in module_dict.items():
block_base=type(block).__base__
if block_base is Module:
self._block_step(block.__dict__,cname+block_name,beta1,beta2,t)
continue
elif block_base is AbsContainer:
self._block_step(block.modules,cname+block_name,beta1,beta2,t)
continue
elif block_base is dict:
self._block_step(block,cname+block_name,beta1,beta2,t)
continue
if (block_base.__base__ is not AbsNet) or (not hasattr(block,"parameters")):
continue
for name,weight in block.parameters.items():
gt=weight.grad
mt=self.mt[cname+block_name][name]
vt=self.vt[cname+block_name][name]
weight-=self.lr*gt
self.mt[cname+block_name][name]=beta1*mt+(1-beta1)*gt
self.vt[cname+block_name][name]=beta2*vt+(1-beta2)*(gt*gt)
mt=mt/(1-np.power(beta1,self.t))
vt=vt/(1-np.power(beta2,self.t))
weight-=self.lr*mt/(np.sqrt(vt)+self.eps)
def step(self):
beta1,beta2=self.betas
self.t+=1
self._block_step(self.parameters.__dict__,"",beta1,beta2,self.t)
'''
添加了collate_fn和sampler的实现,
让DataLoader可以随意的以任何方式取数据
'''
class DataLoader:
def __init__(self,dataset,batch_size,collate_fn=None,sampler=None):
self.dataset=dataset
self.batch_size=batch_size
self.collate_fn=self.collate if collate_fn is None else collate_fn
self.sampler=range(len(dataset)) if sampler is None else sampler
self.sample_iter=iter(self.sampler)
self.num=0
self.stop=False
self.final=False
def collate(self,batch):
return [Tensor(np.stack([batch[i][j] for i in range(len(batch))]))\
for j in range(len(batch[0]))]
def __iter__(self):
return self
def __next__(self):
if self.final==True:
self.num=0
self.final=False
self.sample_iter=iter(self.sampler)
if not self.stop:
bs=self.batch_size
num=self.num
self.num=min(self.num+bs,len(self.sampler))
if self.num==len(self.sampler):self.stop=True
batch=[]
bs=self.num-num
for _ in range(bs):
c=next(self.sample_iter)
batch+=[self.dataset[c]]
return self.collate_fn(batch)
self.stop=False
self.final=True
raise StopIteration
这里给出torch版代码:
#!/usr/bin/env python
# coding: utf-8
#author: iiGray
import torch
from torch import nn
from torch.nn import functional as F
import torch.utils.data as tud
from torchvision.datasets import mnist
import numpy as np
import matplotlib.pyplot as plt
def trans(x):
x=np.array(x,dtype=np.float32)/255
x=(x-0.5)/0.5
return x
class Dataset(tud.Dataset):
def __init__(self, mnist_datas):
self.datas = mnist_datas
def __len__(self, ):
return len(self.datas)
def __getitem__(self, i):
img, label = self.datas[i]
return torch.tensor(img[None, :, :]), torch.tensor(label)
class conv_block(nn.Module):
def __init__(self, in_channels, out_channels, stride=1):
super().__init__()
self.conv = nn.Conv2d(in_channels, out_channels, 3, stride=stride, padding=1)
self.bn = nn.BatchNorm2d(out_channels)
self.relu = nn.ReLU()
def forward(self, x):
out = self.relu(self.bn(self.conv(x)))
return out
class Net(nn.Sequential):
def __init__(self):
super().__init__(
nn.Conv2d(1, 32, kernel_size=3, stride=2, padding=1), # (32,14,14)
nn.MaxPool2d(kernel_size=3, stride=2), # (32,6,6)
conv_block(32, 64, 2), # (64,3,3)
nn.AvgPool2d(3),
nn.Flatten(start_dim=1),
nn.Linear(64, 10)
)
class Accumulater:
def __init__(self,n):
self.data=[0.]*n
def add(self,*args):
self.data=[o+float(m) for o,m in zip(self.data,args)]
def __getitem__(self,i):
return self.data[i]
def train(net,data_iter,lr,num_epochs):
# optimizer=torch.optim.SGD(net.parameters(),lr=lr)
optimizer=torch.optim.AdamW(net.parameters(),lr=lr)
loss=nn.CrossEntropyLoss(reduction="sum")
loss_lst=[]
net.train()
for e in range(num_epochs):
metric=Accumulater(2)
for x,y in data_iter:
l=loss(net(x),y)
optimizer.zero_grad()
l.backward()
optimizer.step()
with torch.no_grad():
metric.add(l.sum(),x.shape[0])
loss_lst+=[metric[0]/metric[1]]
if e % 5 == 0:
print(f"Epoch:{e} Loss:\t", loss_lst[-1])
plt.xlabel("num_epochs")
plt.ylabel("loss")
plt.plot(loss_lst)
plt.show()
print("final loss:",loss_lst[-1])
return net
def predict(net,tst_data_iter):
R=0
All=0
net.eval()
for x,y in tst_data_iter:
y_pre=net(x).argmax(-1)
if y_pre.item()==y.item():R+=1
All+=1
print("Accuracy:",f'{R/All:.6f}')
if __name__=="__main__":
train_set = mnist.MNIST('./data', train=True, transform=trans, download=True)
dset = Dataset(train_set)
'''由于我们写的网络基于numpy,训练速度比较慢,只在前1500个数据上训练'''
data_iter = tud.DataLoader(dset, batch_size=10, sampler=range(1500))
net = Net()
print(net)
net = train(net, data_iter, 0.01, 30)
'''在1500之后的全部数据集上进行预测'''
predict(net, tud.DataLoader(dset, batch_size=1, sampler=range(1500,60000)))
运行结果(依次显示):
Net(
(0): Conv2d(1, 32, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1))
(1): MaxPool2d(kernel_size=3, stride=2, padding=0, dilation=1, ceil_mode=False)
(2): conv_block(
(conv): Conv2d(32, 64, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1))
(bn): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU()
)
(3): AvgPool2d(kernel_size=3, stride=3, padding=0)
(4): Flatten(start_dim=1, end_dim=-1)
(5): Linear(in_features=64, out_features=10, bias=True)
)
Epoch:0 Loss: 1.2525546153386433
Epoch:5 Loss: 0.1269009583890438
Epoch:10 Loss: 0.021628122963011264
Epoch:15 Loss: 0.0038329388679315644
Epoch:20 Loss: 0.00257651609989504
Epoch:25 Loss: 0.0017569300504401326
loss曲线:
final loss: 0.0012651231014169752
Accuracy: 0.915265
尾注
训练只使用了mnist训练集的前1500,测试集为mnist训练集的1500-60000,而达到了90%以上的准确率,直接证明本网络是没有问题的,另外,之所以手写版和torch版训练过程和结果不同,是因为参数初始化不同
【更新与勘误】
2024.2.28 此处 描述错误,代码没有问题(之前写的是running_mean和running_var初始化均为全零矩阵,这是错误的),应该是初始化时running_mean是全零矩阵,running_var是全一矩阵(原文已修改)














 4055
4055











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









