






 本文介绍了如何使用Pandas在Python中进行数据分析,包括创建DataFrame、布尔索引反转、Groupby操作、合并数据、删除重复项以及使用isin方法筛选数据。
本文介绍了如何使用Pandas在Python中进行数据分析,包括创建DataFrame、布尔索引反转、Groupby操作、合并数据、删除重复项以及使用isin方法筛选数据。
1.利用字典创建Dataframe:
visits_data = {
'visit_id': [1, 2, 4, 5, 6, 7, 8],
'customer_id': [23, 9, 30, 54, 96, 54, 54]
}
visits_df = pd.DataFrame(visits_data)2.“~”符用来反转布尔索引,例:
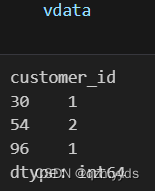
vdata = visits_df[~visits_df['visit_id'].isin(transactions_df['visit_id'])].groupby('customer_id').size()3.Groupby后用size():
df.groupby('customer_id').size()4.groupby().size().reset_index()修改的是分组组内个数的那一列
5.pd.merge()
pd.merge( left, right, how='inner', on=None, left_on=None, right_on=None, left_index=False, right_index=False, sort=False, suffixes=('_x', '_y'), copy=True, indicator=False, validate=None,)
参数on:指定主键,如果两张表有相同的列也可以不指定主键,如果有多个相同的列,在不指定how的情况下,会默认采用内连接,即只拼接这几列都相同的部分
参数left_index和right_index:默认为False,设为True以后会按照两张表的index进行默认内连接
参数how:默认inner 若为outer,为保留两张表全部信息,缺失部分用NaN填充,若为left或right,则保留左(右)表全部信息,缺失部分用NaN填充
参数lefton和righton:可以指定两表中不名字不相同的两列作为主键(按相同的值连接)
参数suffixes:用于修改相同列后的后缀,如suffixes=('_left', '_right')
参数indicator:默认为False,设为True后会在拼接好的表后加一列_merge,用于表明这一行数据来自于哪个表(left_only,right_only,both)(pd.concat中也有这一参数)
6.DataFrame.drop_duplicates(subset=None, keep='first', inplace=False)
用于去除重复项,参数subset用于指定需要筛选的列,inplace默认为False返回一个复制样本,True则在原dataframe上修改
transactions_df.drop_duplicates(subset=['visit_id'])7.dataframe.isin()方法
传入一个Sequence,可以与loc[]连用进行筛选
visits_df[visits_df['visit_id'].isin(transactions_df['visit_id'])]














 158
158











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









