







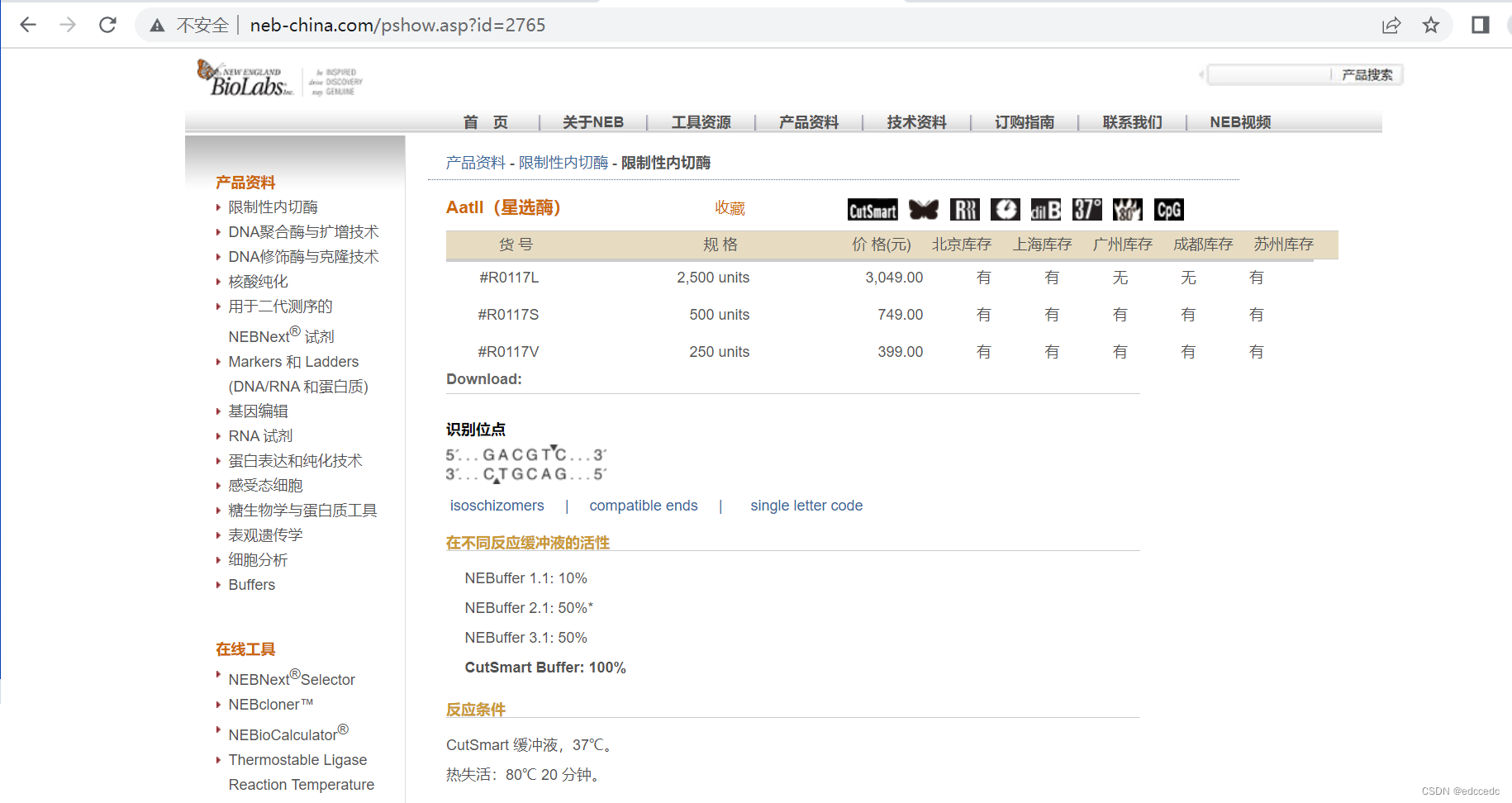
以此网站为例
1、右击检查网页,找到需要爬取的信息的位置。
可以看到,当鼠标停留在h1标签的时候,右边网页内容也相应显示
# http://neb-china.com/pshow.asp?id=2765
import requests
from pyquery import PyQuery as pq
import time
def load_data(url):
# 获取网页内容
# 重试机会
for i in range(3):
try:
response = requests.get(url)
if response.status_code == 200: # 状态码
response.encoding = "utf-8" #设置编码
return response.text
else:
time.sleep(1) # 请求失败则睡一秒再重试
except:
time.sleep(1)2、请求网页,然后将请求到的信息先打印出来看看
html = load_data("http://neb-china.com/pshow.asp?id=2765")
print(html)打印出来的结果即是我们在网页-检查看到的内容,下面再取出我们需要的内容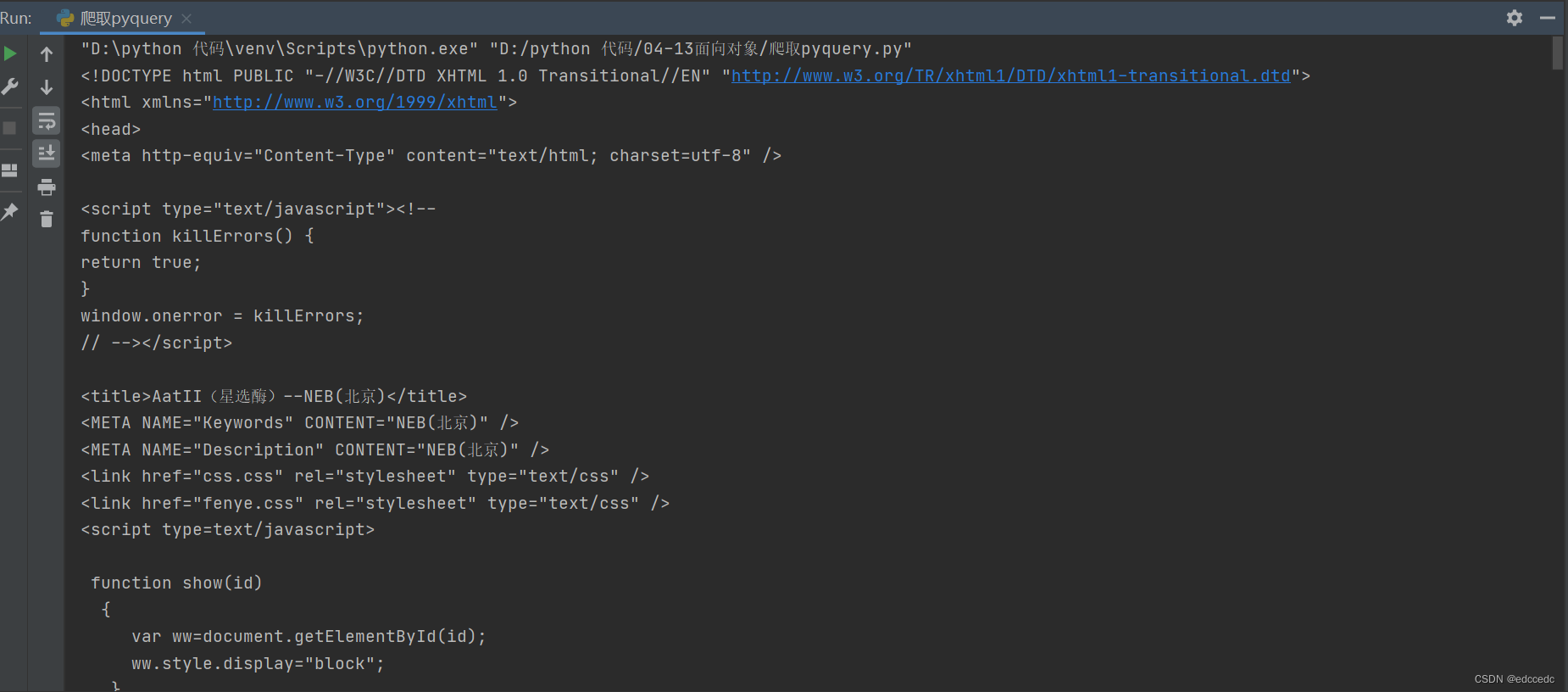
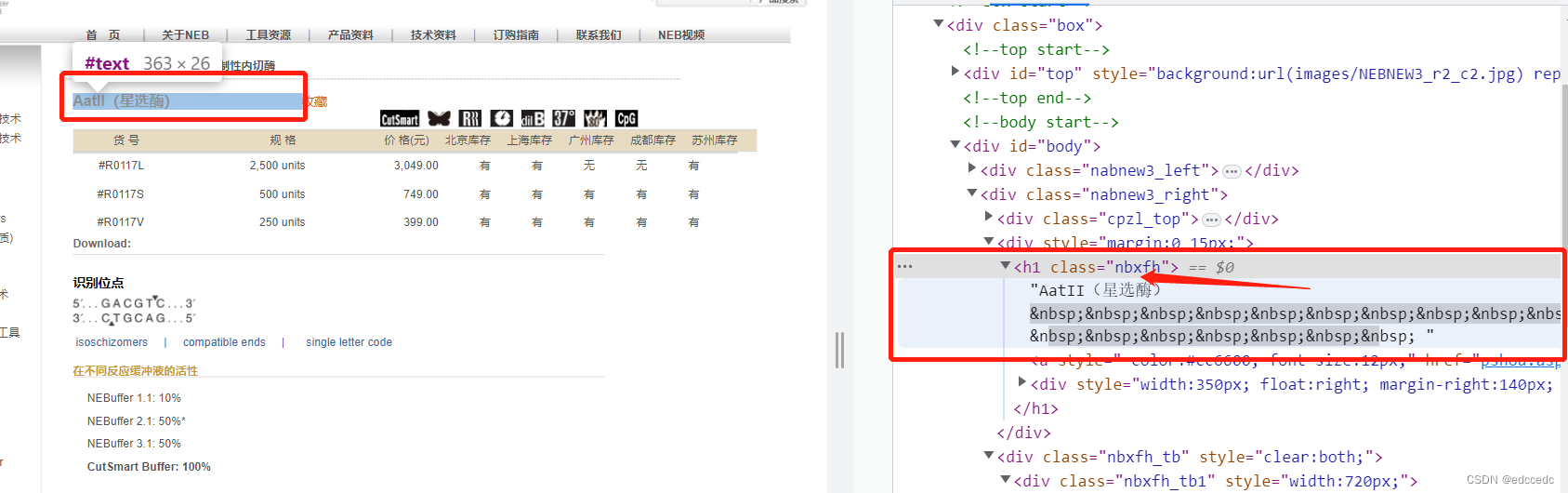
我们先获取出产品名称试试
在前面的图中可以看到,class为nbxfh ,这样就可以用pyquery直接找到了
product_name = html_pq(".nbxfh").text()
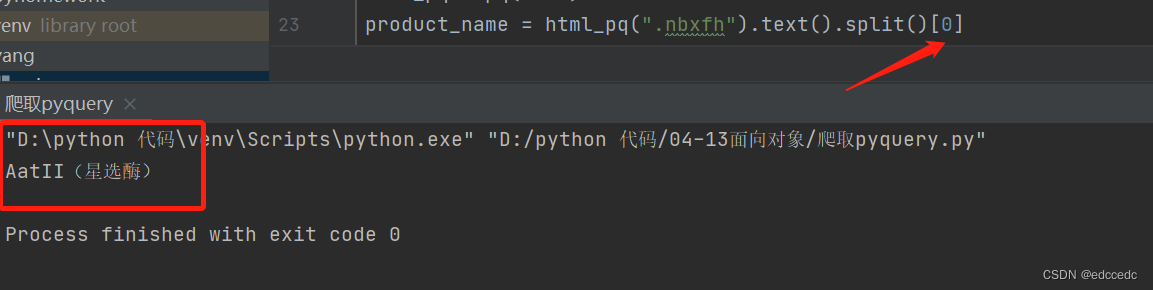
print(product_name) 打印出来的结果如下,但是我们只需要前面的产品名称,再对其进行分割。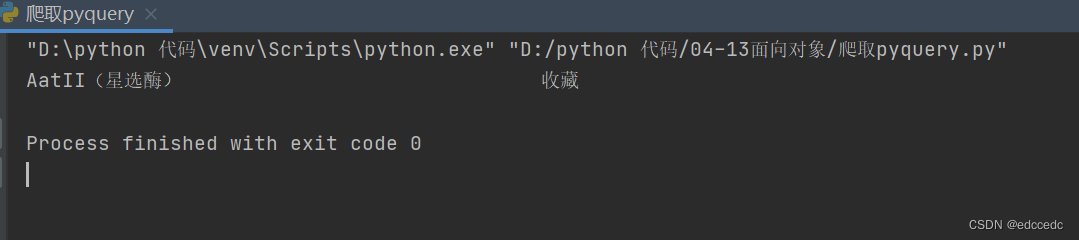
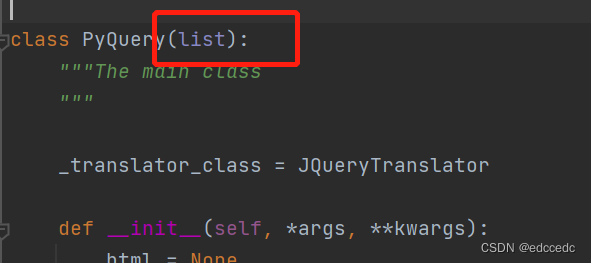
我们在pyquery的文件中可以看到,继承了list,即list的属性它都有
于是我们进行分割,得到的结果如下

再通过下标取出即可,这样就获取了我们想要的产品名称了。
再获取货号、规格等信息:
product_info1 = html_pq(".nbxfh_tb1 .nbxfh_tb3:nth-child(-n+8)").items()
result1 = list(product_info1)
for i in result1:
print(i.text(), end='\t')
完整代码如下:
# http://neb-china.com/pshow.asp?id=2765
import requests
from pyquery import PyQuery as pq
import time
def load_data(url):
# 获取网页内容
# 重试机会
for i in range(3):
try:
response = requests.get(url)
if response.status_code == 200: # 状态码
response.encoding = "utf-8" #设置编码
return response.text
else:
time.sleep(1) # 请求失败则睡一秒再重试
except:
time.sleep(1)
html = load_data("http://neb-china.com/pshow.asp?id=2765")
# print(html)
html_pq = pq(html)
product_name = html_pq(".nbxfh").text().split()[0]
# print(product_name)
product_info = html_pq(".nbxfh_tb2 .nbxfh_tb3:nth-child(-n+3)").items()
result = list(product_info)
product_info1 = html_pq(".nbxfh_tb1 .nbxfh_tb3:nth-child(-n+8)").items()
result1 = list(product_info1)
for i in result1:
print(i.text(), end='\t')














 3498
3498











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









