








🤵♂️ 个人主页:@艾派森的个人主页
✍🏻作者简介:Python学习者
🐋 希望大家多多支持,我们一起进步!😄
如果文章对你有帮助的话,
欢迎评论 💬点赞👍🏻 收藏 📂加关注+
目录
1.项目背景
在当今的珠宝市场中,钻石作为一种高价值的商品,其价格受到多种因素的影响,如重量、颜色、净度和切工等。这些因素之间的复杂关系使得钻石定价成为一个具有挑战性的任务。传统上,钻石的定价主要依赖于专家的经验和主观判断,这种方法不仅效率低下,而且难以准确反映市场动态和消费者偏好。
随着大数据和人工智能技术的快速发展,数据驱动的决策制定正在成为各行各业的重要趋势。在钻石市场,通过收集和分析大量的钻石数据,可以更准确地了解市场动态、消费者偏好以及不同钻石特征对价格的影响。这种基于数据的决策制定方法不仅可以提高定价的准确性和效率,还可以为商家提供更加个性化的营销策略。
然而,钻石数据集通常包含大量的特征和复杂的关系,使得直接分析这些数据变得困难。为了解决这个问题,可视化技术被广泛应用于数据分析中。通过将数据以图形、图表等形式展示出来,可以更直观地理解数据之间的关系和规律,从而更容易地发现数据中的隐藏信息。
因此,本研究旨在通过可视化分析技术,对钻石数据集进行深入挖掘和分析。具体来说,我们将利用散点图、箱线图、热力图等可视化工具,探究钻石的质量特征(如重量、颜色、净度和切工)与价格之间的关系,并考察不同特征之间的相关性。通过这种分析,我们可以更准确地了解钻石市场的定价规律,为商家提供更加科学的定价策略和营销策略。
2.数据集介绍
本实验数据集来源于Kaggle,原始数据集共有53940条数据,10个变量,各变量解释如下:
carat:克拉是衡量钻石重量的单位。一克拉相当于200毫克。
cut:钻石的切割指的是它的比例、对称和抛光。这是决定钻石亮度和亮度的关键因素。
color:钻石的颜色是指钻石是否有颜色。美国宝石学会(GIA)将钻石的颜色分为D级(无色)到Z级(浅黄色或棕色)。
clarity:净度衡量钻石内部缺陷(内含物)和外部瑕疵(瑕疵)的存在。GIA将净度等级从Flawless(在10倍放大镜下看不到夹杂物或瑕疵)到Included(肉眼可见的夹杂物和/或瑕疵)。
depth:深度是菱形从切面到表的高度。它表示为钻石总直径的百分比。
table:表大,平方面上的钻石。表百分比是指表面宽度占钻石总直径的百分比。
price:价格是指钻石的成本,它受到各种因素的影响,包括克拉重量、切工、颜色和净度。
x, y, z:这些尺寸分别表示菱形的长度,宽度和深度。它们通常以毫米为单位测量。
3.技术工具
Python版本:3.9
代码编辑器:jupyter notebook
4.导入数据
导入第三方库并加载数据集
查看数据大小
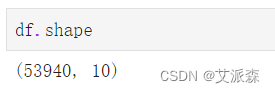
查看数据基本信息
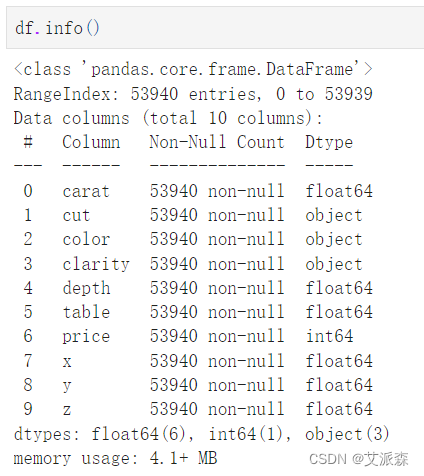
查看数值型变量的描述性统计
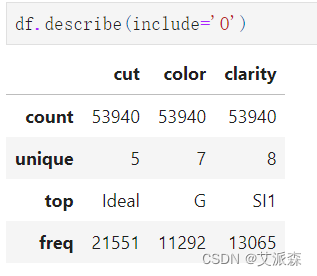
查看非数值型变量的描述性统计
统计数据集缺失情况

发现数据集中并不存在缺失值
统计重复值情况
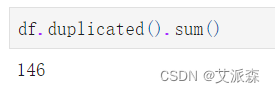
发现数据集中有146个重复值
删除重复值

5.数据可视化


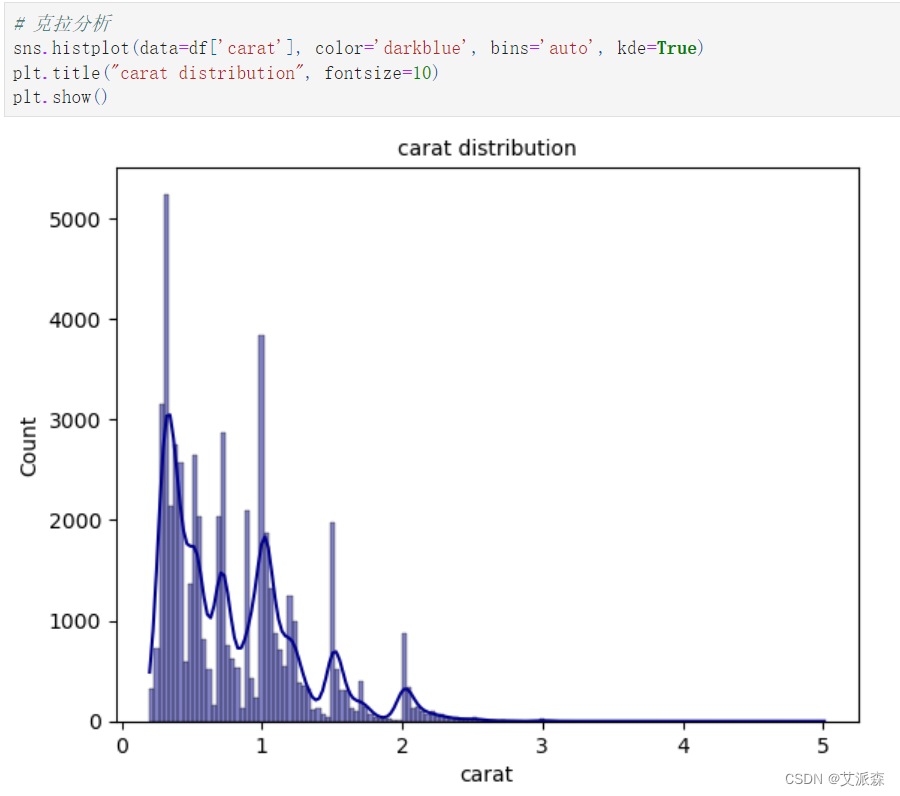
克拉特征分析: 克拉的最小值为0.2,最大值为5.01 克拉的平均值是0.7979 根据histplot,克拉似乎是右偏的。

深度特征分析: 平均深度为61.74。 最小值是43,最大值是79。 从图中可以看出,深度是正态分布的。
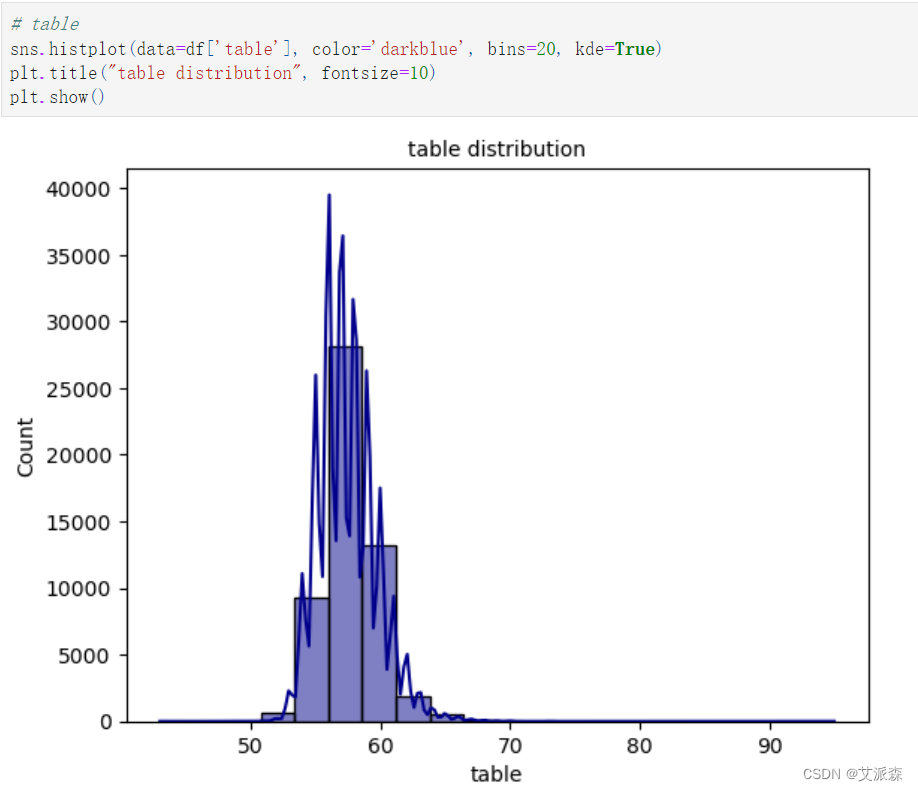
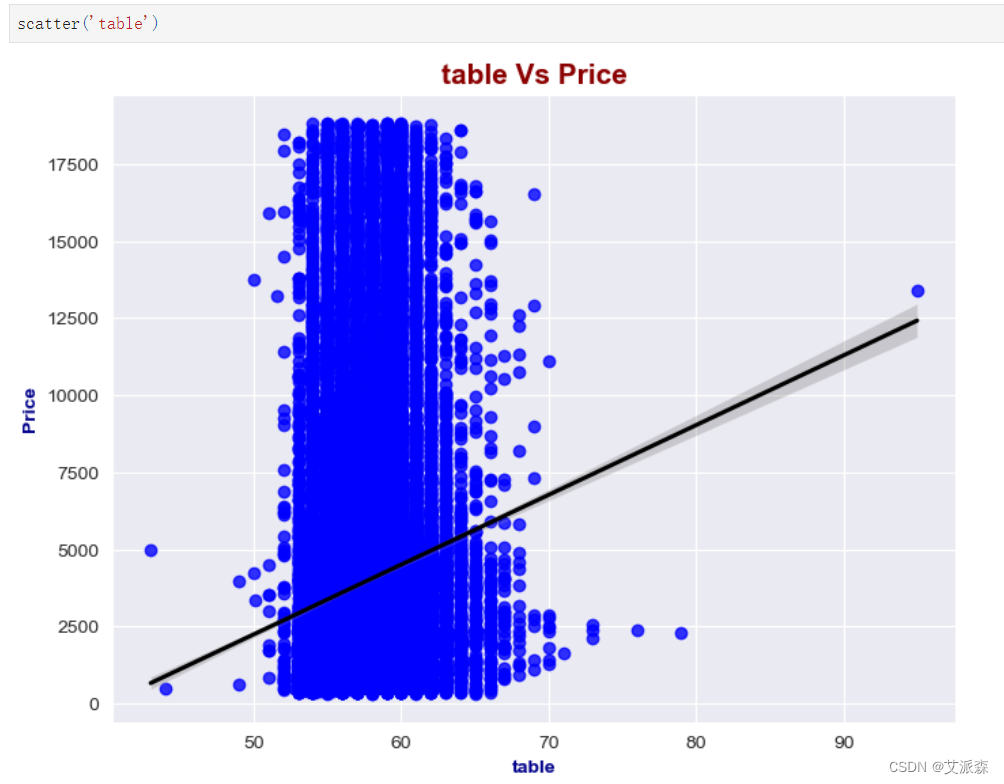
表特征分析: 这个表的平均值是57.45。 最小值是43,最大值是95。 根据汇总统计表,我们可以说这个特征具有右偏度。结果表明,75个分位数等于59,而最大值为95,这意味着75%的行小于分位数3。
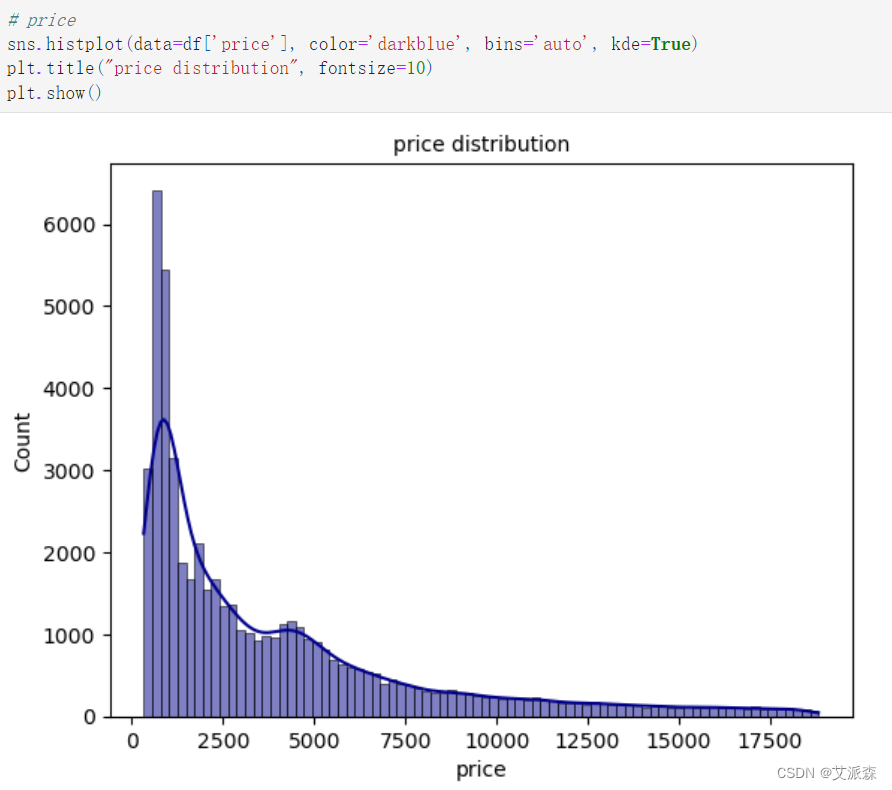
价格特征分析: 最小值为326,最大值为18823。 平均价格是3932美元 根据统计表和他的图可以清楚地看出这个特征是右偏的。
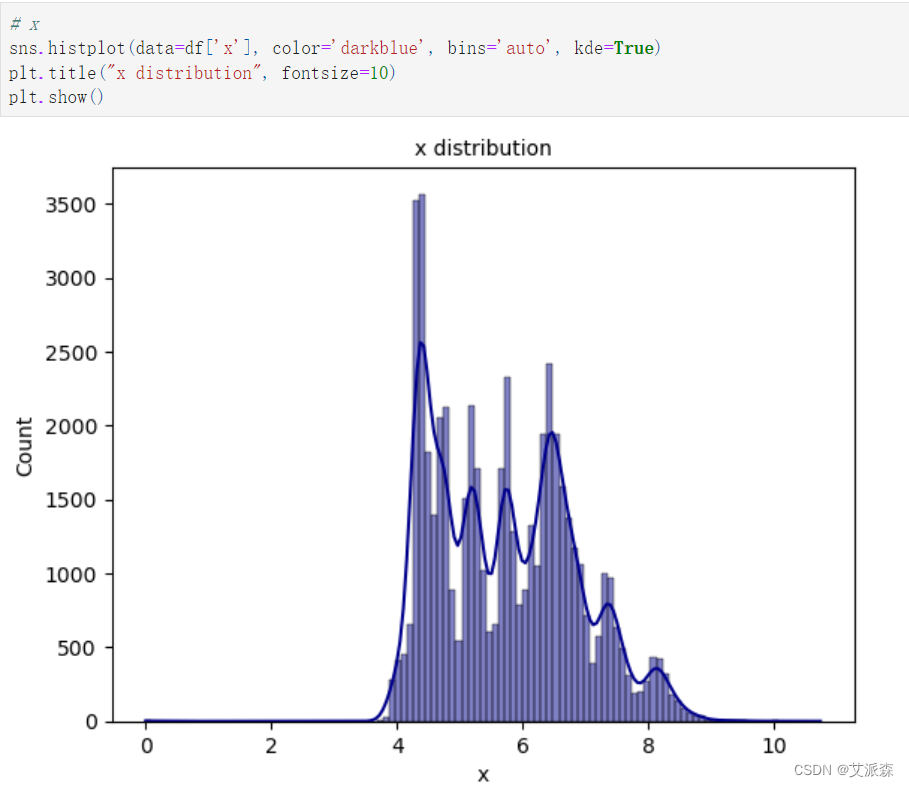
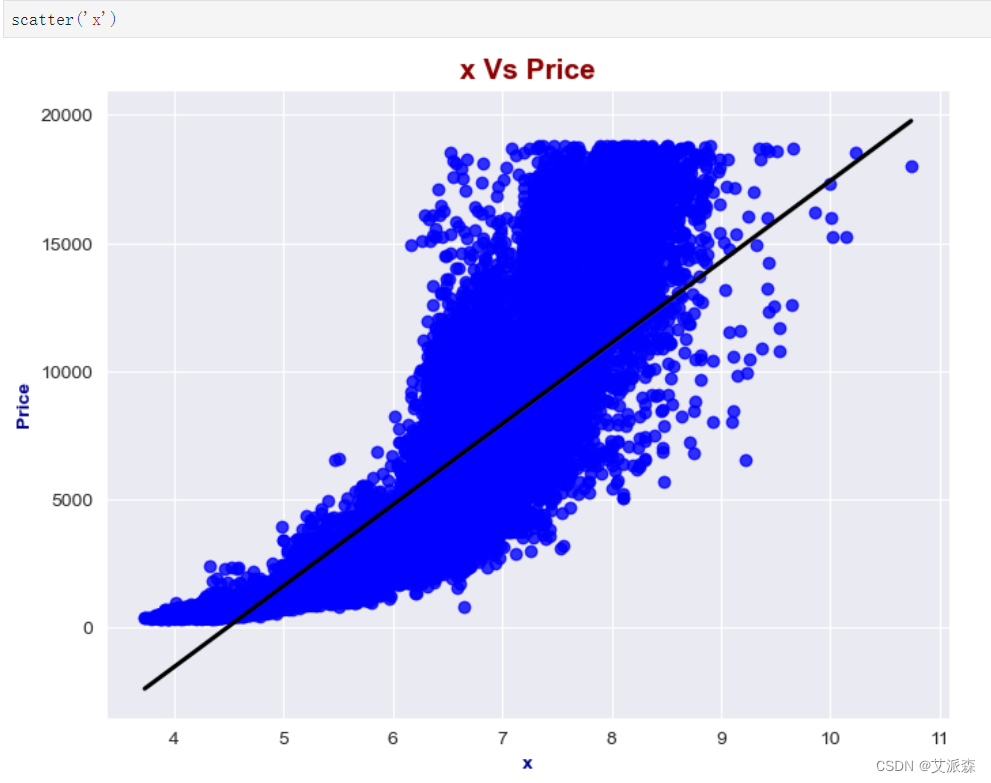
x特征分析: x的最小值为0.0,最大值为10.74。 x的平均值是5.73。 根据histplot,由于平均值略大于中位数(分位数为50%),x特征的分布略有右偏。
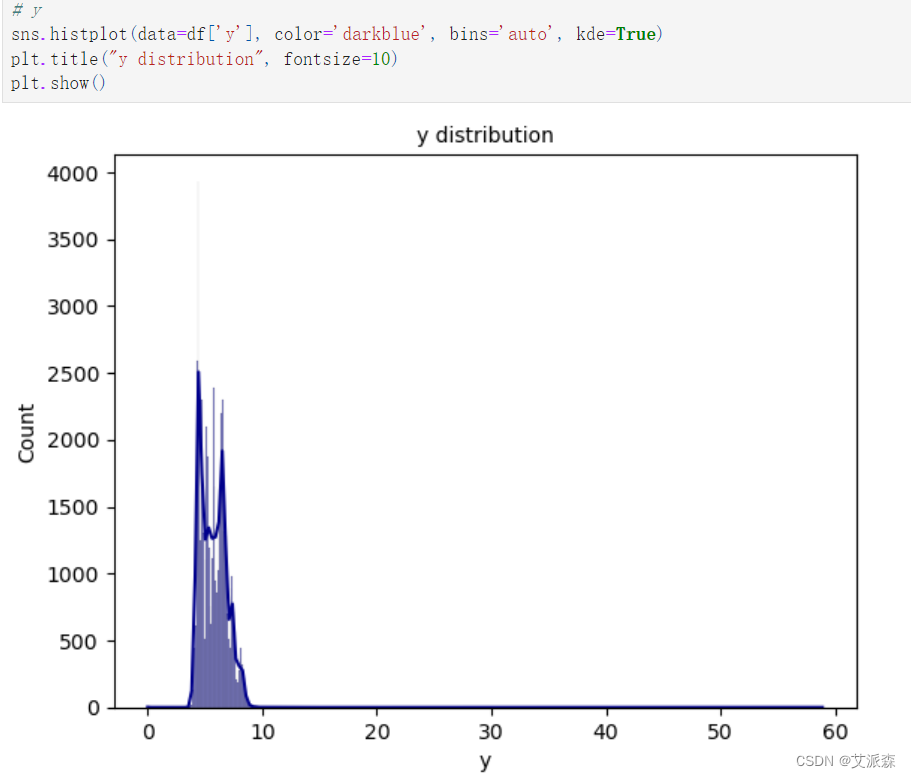
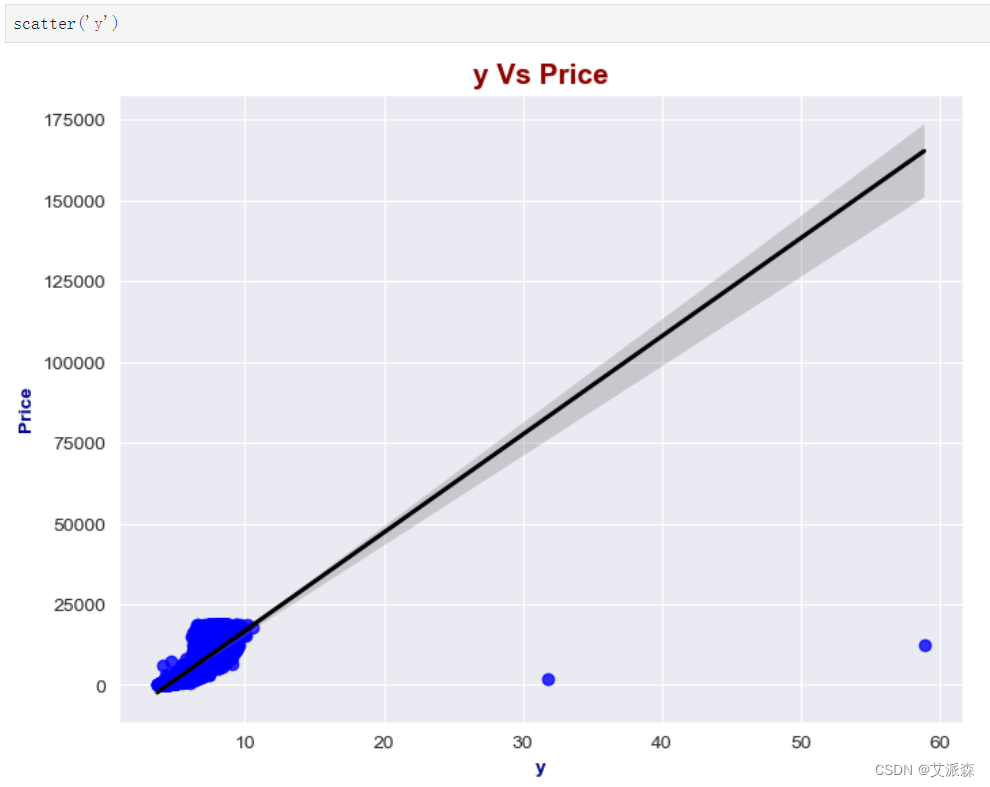
y特征分析: 平均是5.73。 最小值为0,最大值为58.90 根据histplot和汇总统计表,均值和中位数(Q2)几乎相等,我们可以假设y特征是正态分布的。
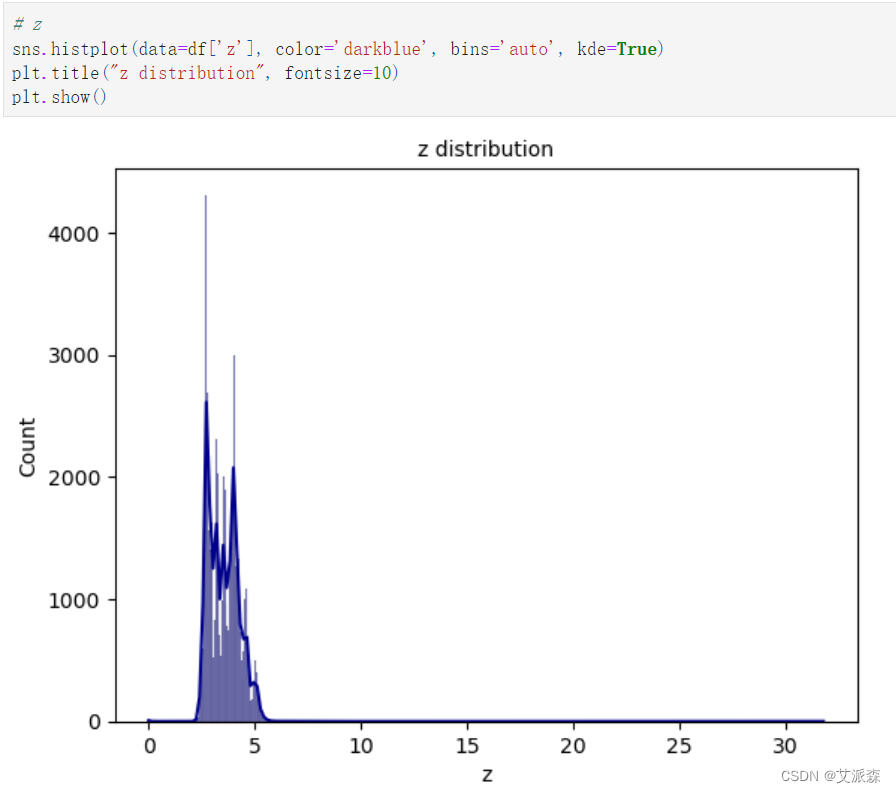
z特征分析: 最小值为0,最大值为31.80。 z的平均值是3.53 根据他的图和统计表,很明显这个特征是正态分布的,因为这个特征的中位数(Q2)和平均值几乎是相等的。




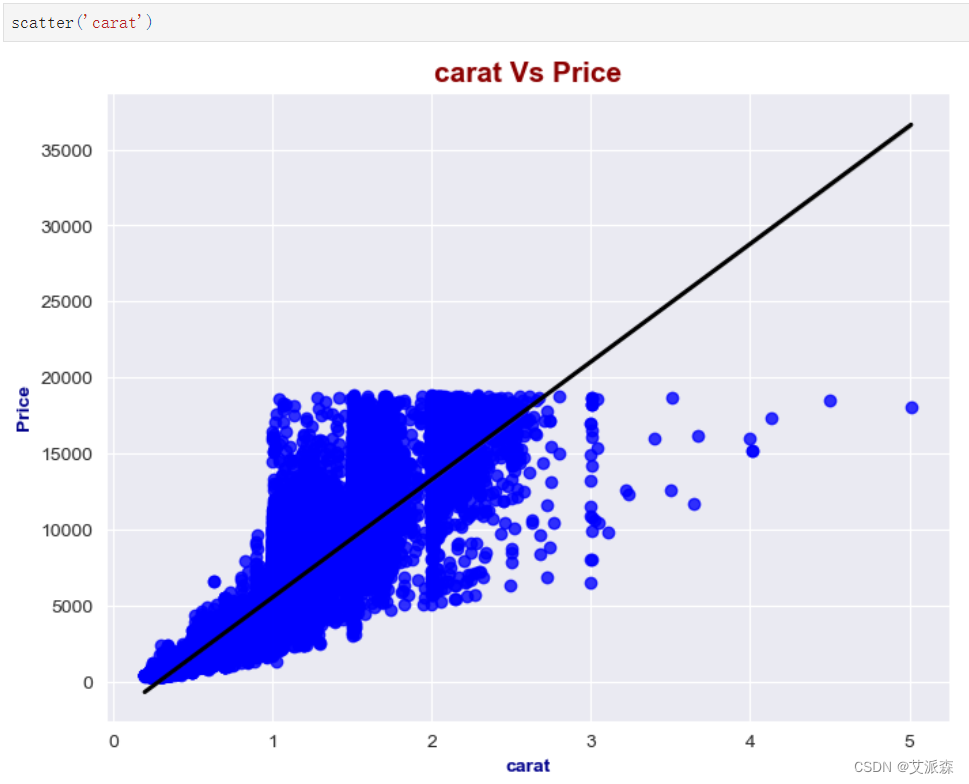

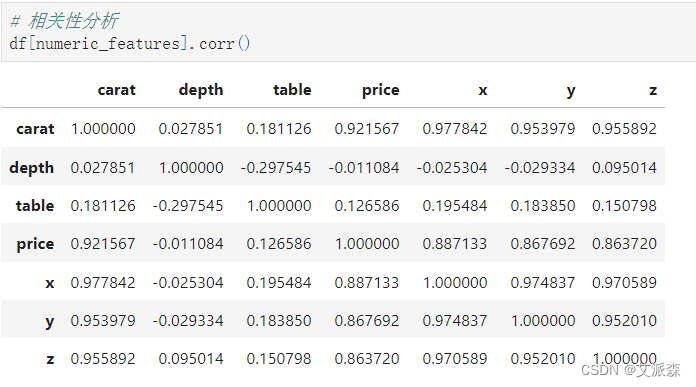
克拉重量与价格(目标)之间存在很强的正相关关系(0.92),表明随着钻石克拉重量的增加,其价格有显著增加的趋势。 克拉重量也与尺寸x、y和z有很强的正相关,这表明越大的钻石往往有更大的克拉重量。 克拉重与表宽之间的相关性适中(0.18),表明这两个变量之间存在轻微的正相关关系。 深度:
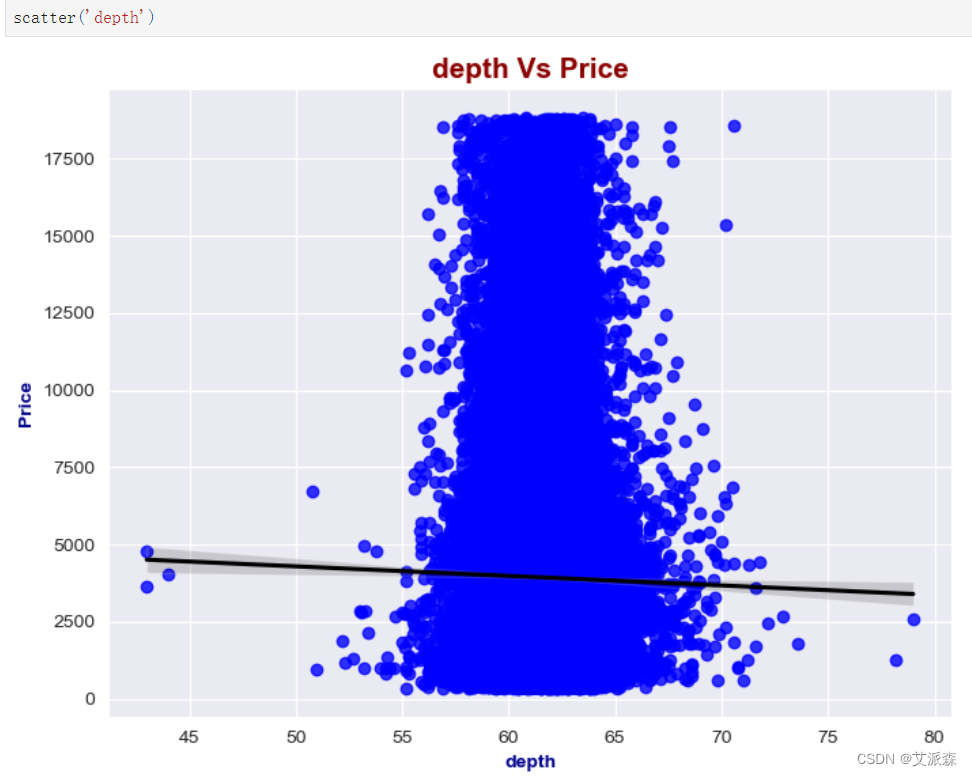
深度和价格之间存在微弱的负相关(-0.01),这表明钻石的深度和价格之间几乎没有关系。 深度与表宽呈中等负相关(-0.30),表明随着金刚石深度的增加,其表宽有减小的趋势。 深度也与尺寸x、y和z呈弱负相关,这表明深度与钻石的物理尺寸之间几乎没有关系。 表:
表宽和价格之间存在弱正相关(0.13),表明这两个变量之间存在轻微的正相关关系。 表宽与克拉重量呈正相关(0.20),表明较大的钻石往往具有更宽的表宽。 表宽与尺寸x、y和z也有微弱的正相关,这表明表宽与钻石的物理尺寸之间存在轻微的正相关。 X y z:
所有三个维度(x, y和z)都与克拉重量有很强的正相关(x为0.97,y为0.95,z为0.95),这表明更大的钻石在所有三个轴上都具有更大的维度。 尺寸(x, y和z)与价格之间存在中等到强烈的正相关关系,这表明越大的钻石往往价格越高。 维度x、y和z也与表宽度有弱到中度的正相关,表明这些变量之间存在轻微的正相关。



源代码
import matplotlib.pyplot as plt
import seaborn as sns
import pandas as pd
import warnings
warnings.filterwarnings("ignore")
df = pd.read_csv("diamonds.csv")
df.head()
df.shape
df.info()
df.describe()
df.describe(include='O')
df.isnull().sum()
df.duplicated().sum()
df.drop_duplicates(inplace=True)
df.duplicated().sum()
# 选出数值变量和类别变量
numeric_features = ["carat", "depth", "table", "price", "x", "y", "z"]
categorial_features = ['cut', 'color', 'clarity']
# 克拉分析
sns.histplot(data=df['carat'], color='darkblue', bins='auto', kde=True)
plt.title("carat distribution", fontsize=10)
plt.show()
克拉特征分析:
克拉的最小值为0.2,最大值为5.01
克拉的平均值是0.7979
根据histplot,克拉似乎是右偏的。
# depth
sns.histplot(data=df['depth'], color='darkblue', bins='auto', kde=True)
plt.title("depth distribution", fontsize=10)
plt.show()
深度特征分析:
平均深度为61.74。
最小值是43,最大值是79。
从图中可以看出,深度是正态分布的。
# table
sns.histplot(data=df['table'], color='darkblue', bins=20, kde=True)
plt.title("table distribution", fontsize=10)
plt.show()
表特征分析:
这个表的平均值是57.45。
最小值是43,最大值是95。
根据汇总统计表,我们可以说这个特征具有右偏度。结果表明,75个分位数等于59,而最大值为95,这意味着75%的行小于分位数3。
# price
sns.histplot(data=df['price'], color='darkblue', bins='auto', kde=True)
plt.title("price distribution", fontsize=10)
plt.show()
价格特征分析:
最小值为326,最大值为18823。
平均价格是3932美元
根据统计表和他的图可以清楚地看出这个特征是右偏的。
# x
sns.histplot(data=df['x'], color='darkblue', bins='auto', kde=True)
plt.title("x distribution", fontsize=10)
plt.show()
x特征分析:
x的最小值为0.0,最大值为10.74。
x的平均值是5.73。
根据histplot,由于平均值略大于中位数(分位数为50%),x特征的分布略有右偏。
# y
sns.histplot(data=df['y'], color='darkblue', bins='auto', kde=True)
plt.title("y distribution", fontsize=10)
plt.show()
y特征分析:
平均是5.73。
最小值为0,最大值为58.90
根据histplot和汇总统计表,均值和中位数(Q2)几乎相等,我们可以假设y特征是正态分布的。
# z
sns.histplot(data=df['z'], color='darkblue', bins='auto', kde=True)
plt.title("z distribution", fontsize=10)
plt.show()
z特征分析:
最小值为0,最大值为31.80。
z的平均值是3.53
根据他的图和统计表,很明显这个特征是正态分布的,因为这个特征的中位数(Q2)和平均值几乎是相等的。
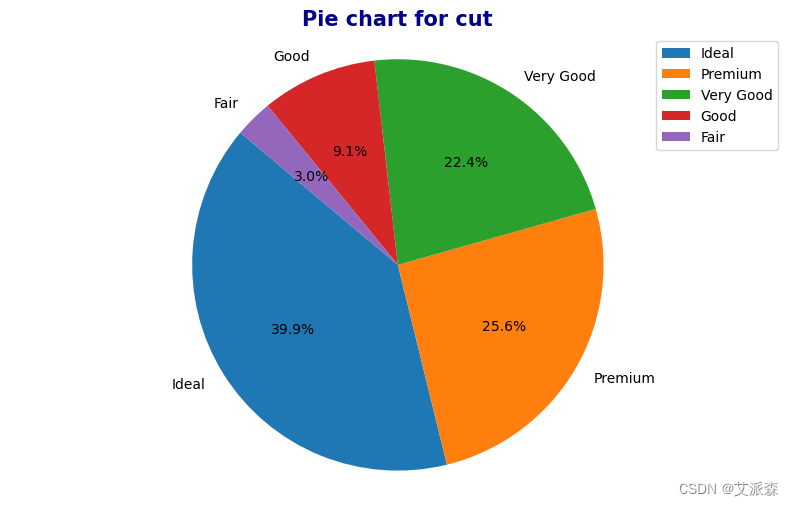
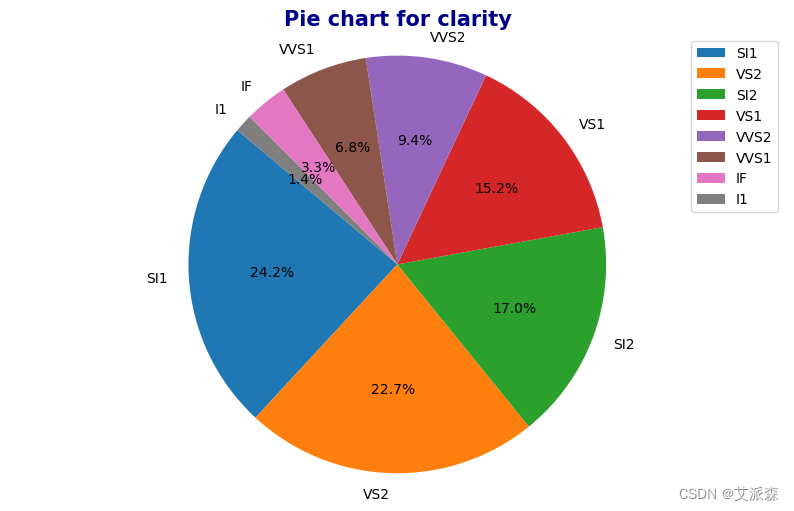
# 为每个分类列绘制饼状图
for column in categorial_features:
counts = df[column].value_counts()
sns.color_palette("bright")
plt.figure(figsize=(10, 6))
plt.pie(counts, labels=counts.index, autopct='%1.1f%%', startangle=140)
plt.title(f'Pie chart for {column}', fontdict={"color" : "darkblue", "weight" : "bold", "size" : 15})
plt.axis('equal')
plt.legend()
plt.show()
# 去除异常数据-钻石在所有三个维度(x, y, z)上的尺寸都为0,而仍然有价值,这是不寻常的。这种差异可能表明数据集中有错误或缺少数据。
df = df[~(df['x'] == 0) | (df['y'] == 0 | (df['z'] == 0))]
df.reset_index(drop=True, inplace=True)
def scatter(col):
plt.figure(figsize=(8, 6))
sns.set_style("darkgrid")
sns.regplot(data=df, x=col, y='price', color='blue', line_kws={"color": 'black'})
plt.title(f"{col} Vs Price", fontdict={"color" : "darkred", "weight" : "bold", "size" : 15})
plt.xlabel(col, fontdict={"color": "darkblue", "weight": "bold", "size": 10})
plt.ylabel('Price', fontdict={"color": "darkblue", "weight": "bold", "size": 10})
plt.show()
scatter('carat')
scatter('depth')
scatter('table')
scatter('x')
scatter('y')
scatter('z')
# 相关性分析
df[numeric_features].corr()
克拉:
克拉重量与价格(目标)之间存在很强的正相关关系(0.92),表明随着钻石克拉重量的增加,其价格有显著增加的趋势。
克拉重量也与尺寸x、y和z有很强的正相关,这表明越大的钻石往往有更大的克拉重量。
克拉重与表宽之间的相关性适中(0.18),表明这两个变量之间存在轻微的正相关关系。
深度:
深度和价格之间存在微弱的负相关(-0.01),这表明钻石的深度和价格之间几乎没有关系。
深度与表宽呈中等负相关(-0.30),表明随着金刚石深度的增加,其表宽有减小的趋势。
深度也与尺寸x、y和z呈弱负相关,这表明深度与钻石的物理尺寸之间几乎没有关系。
表:
表宽和价格之间存在弱正相关(0.13),表明这两个变量之间存在轻微的正相关关系。
表宽与克拉重量呈正相关(0.20),表明较大的钻石往往具有更宽的表宽。
表宽与尺寸x、y和z也有微弱的正相关,这表明表宽与钻石的物理尺寸之间存在轻微的正相关。
X y z:
所有三个维度(x, y和z)都与克拉重量有很强的正相关(x为0.97,y为0.95,z为0.95),这表明更大的钻石在所有三个轴上都具有更大的维度。
尺寸(x, y和z)与价格之间存在中等到强烈的正相关关系,这表明越大的钻石往往价格越高。
维度x、y和z也与表宽度有弱到中度的正相关,表明这些变量之间存在轻微的正相关。
def bivariate_barplot(col):
"""This method would compare price by each categorical feature"""
# 具有聚合指标的条形图
mean = df.groupby(col)['price'].mean()
plt.figure(figsize=(10, 6))
sns.barplot(x=mean.index, y=mean.values, palette='rainbow')
plt.title(f'Mean Price by {col}', fontdict={"color" : "darkred", "weight" : "bold", "size" : 15})
plt.xlabel(col, fontdict={"color" : "darkblue", "weight" : "bold", "size" : 10})
plt.ylabel('Mean Price', fontdict={"color" : "darkblue", "weight" : "bold", "size" : 10})
plt.show()
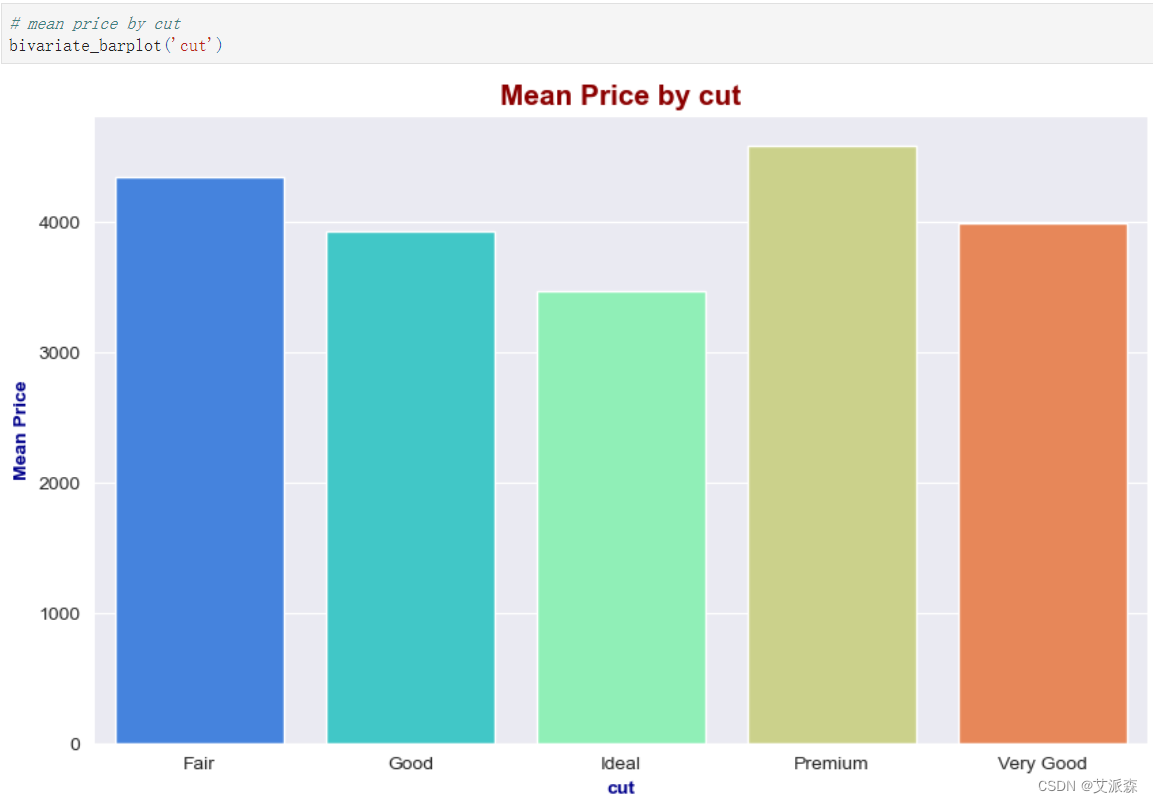
# mean price by cut
bivariate_barplot('cut')
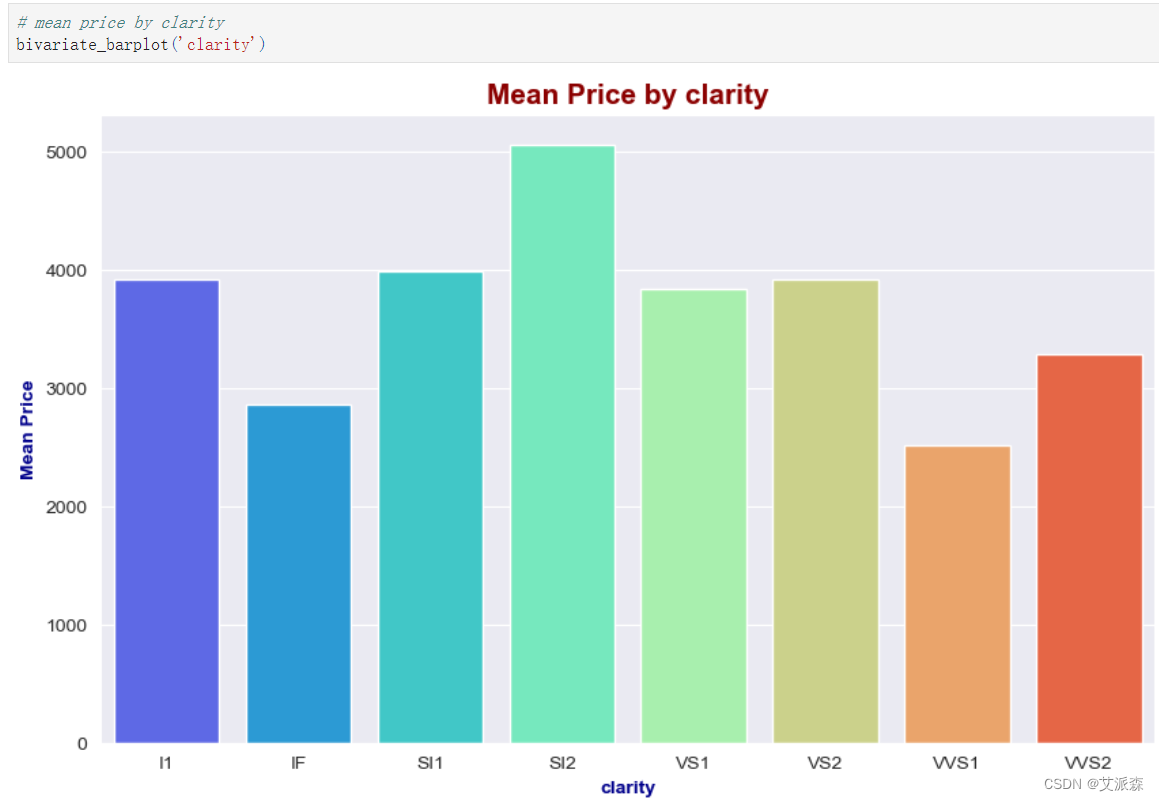
# mean price by clarity
bivariate_barplot('clarity')
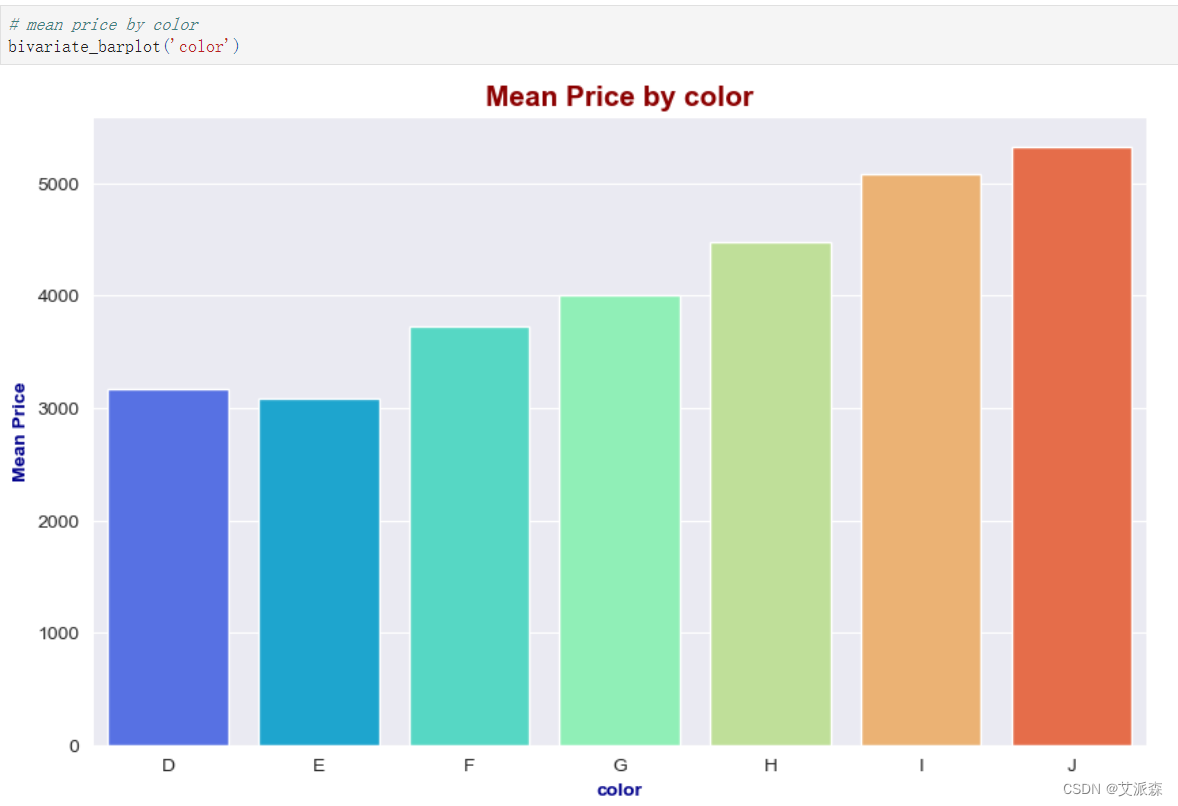
# mean price by color
bivariate_barplot('color')
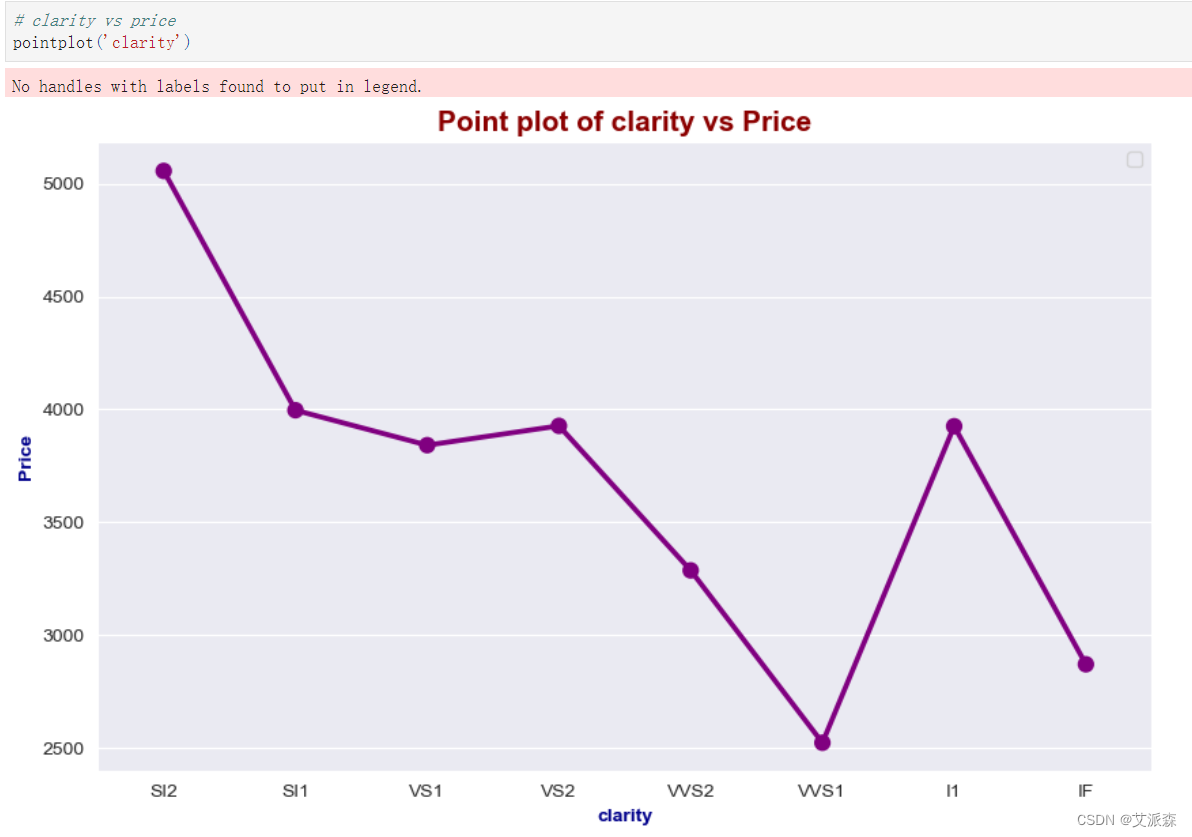
def pointplot(col):
plt.figure(figsize=(10, 6))
sns.pointplot(data=df, x=col, y='price', color='purple', ci=None)
plt.title(f'Point plot of {col} vs Price', fontdict={"color" : "darkred", "weight" : "bold", "size" : 15})
plt.xlabel(col, fontdict={"color" : "darkblue", "weight" : "bold", "size" : 10})
plt.ylabel('Price', fontdict={"color" : "darkblue", "weight" : "bold", "size" : 10})
plt.legend()
plt.show()
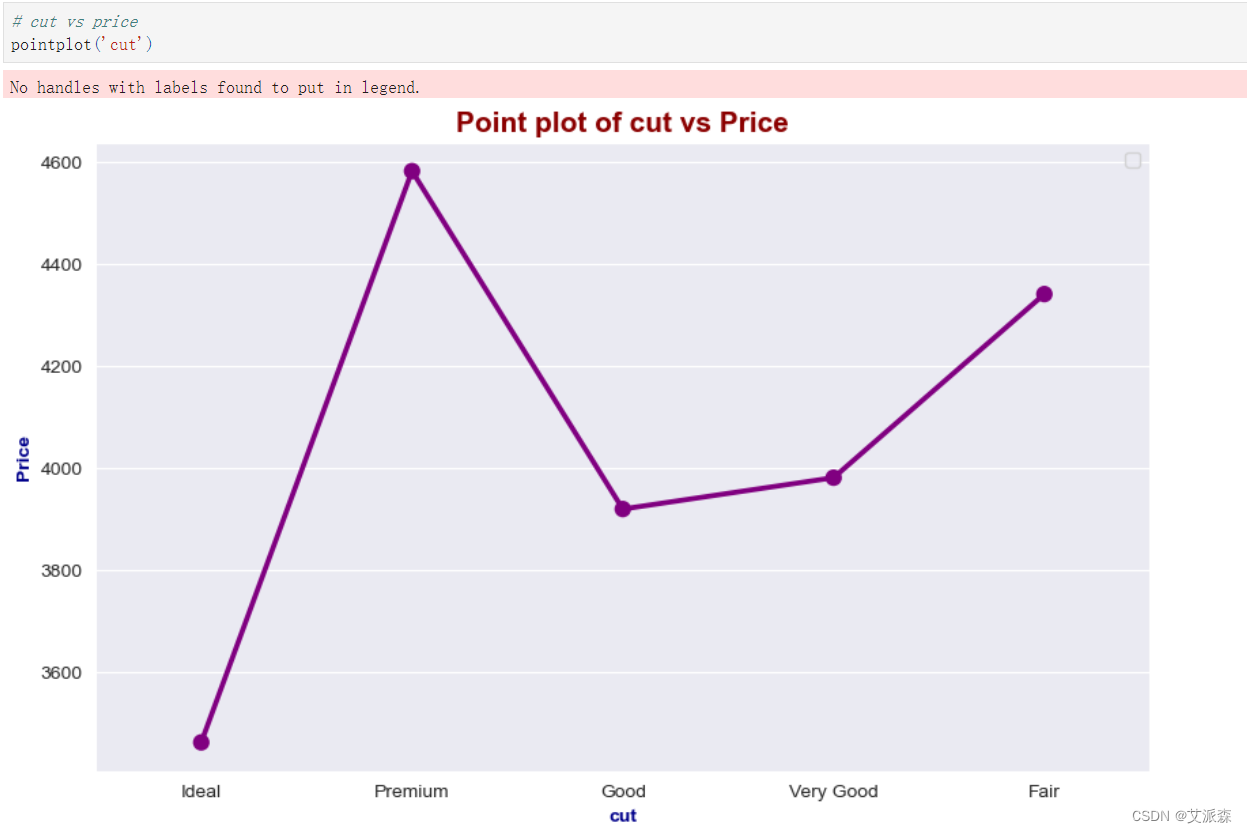
# cut vs price
pointplot('cut')
# clarity vs price
pointplot('clarity')
# clarity vs price
pointplot('color')
资料获取,更多粉丝福利,关注下方公众号获取


















 1479
1479

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











