











🤵♂️ 个人主页:@艾派森的个人主页
✍🏻作者简介:Python学习者
🐋 希望大家多多支持,我们一起进步!😄
如果文章对你有帮助的话,
欢迎评论 💬点赞👍🏻 收藏 📂加关注+
目录
1.项目背景
随着信息技术的不断发展,人们在日常生活中面临着越来越多的选择,例如在电影、音乐、图书等娱乐领域。为了帮助用户更好地发现符合其兴趣和偏好的内容,推荐系统应运而生。推荐系统通过分析用户的历史行为、兴趣和偏好,向用户提供个性化的推荐内容,从而提升用户体验和平台的粘性。
协同过滤是推荐系统中常用的一种方法,它主要分为基于用户的协同过滤和基于物品的协同过滤。基于用户的协同过滤通过分析用户之间的相似性来进行推荐,而基于物品的协同过滤则通过分析物品之间的相似性来进行推荐。然而,这两种方法都存在一些问题,如稀疏性、冷启动等。
在协同过滤方法中,记忆和模型是两个重要的方面。记忆方法依赖于用户或物品的历史行为数据,通过直接利用这些数据进行推荐。然而,当数据稀疏时,记忆方法的效果可能受到限制。相比之下,模型方法通过建立数学模型来捕捉用户和物品之间的复杂关系,能够更好地处理稀疏性和冷启动问题。
因此,结合记忆和模型的协同过滤成为一种有吸引力的方法。这种方法通过将记忆和模型相结合,克服各自的局限性,提高推荐系统的性能。在电影推荐场景中,用户的历史观影记录可以作为记忆的一部分,而模型可以学习用户对不同类型、演员、导演等因素的偏好,从而提供更加个性化的推荐。
通过研究基于记忆和模型的协同过滤在电影推荐中的应用,我们可以进一步改善推荐系统的准确性和用户满意度,提高用户对推荐系统的信任度,促进电影产业的发展。
2.数据集介绍
本数据集来源于kaggle,原始数据集共有2个,movies.csv和ratings.csv,共有100836条,6个特征变量,各变量含义如下:
userId:用户ID
movieId:电影ID
rating:用户给出的评分
timestamp:时间戳,即评论时间
title:电影名称
genres:电影类型
3.技术工具
Python版本:3.9
代码编辑器:jupyter notebook
4.实验过程
4.1加载数据
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
from sklearn.model_selection import train_test_split
from sklearn.metrics.pairwise import cosine_similarity
from sklearn.decomposition import TruncatedSVD
ratings = pd.read_csv("ratings.csv")
movies = pd.read_csv("movies.csv")
ratings = ratings.merge(movies, on="movieId") # 合并数据
ratings.head()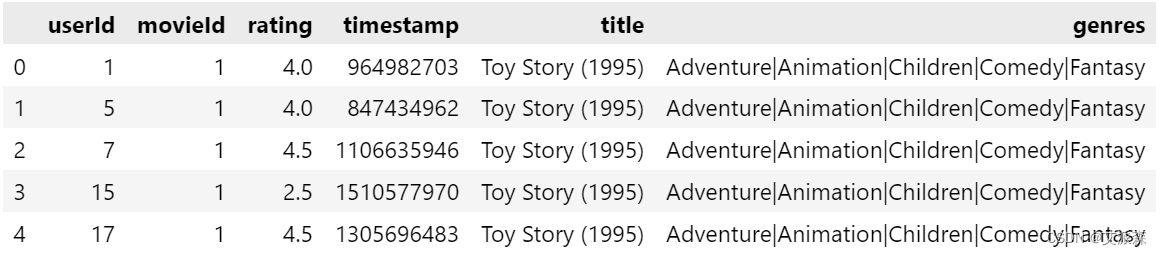
查看数据大小

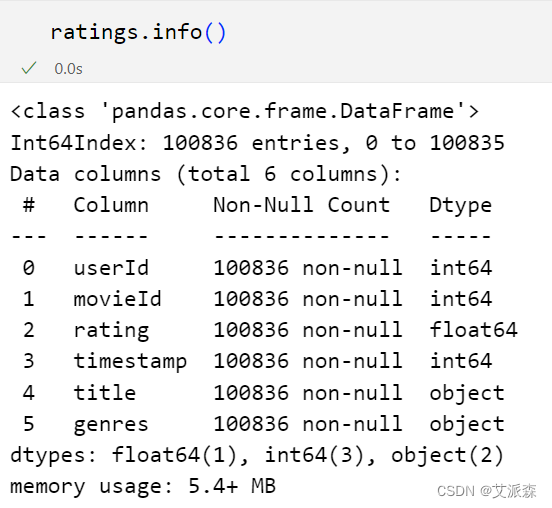
查看数据基本信息
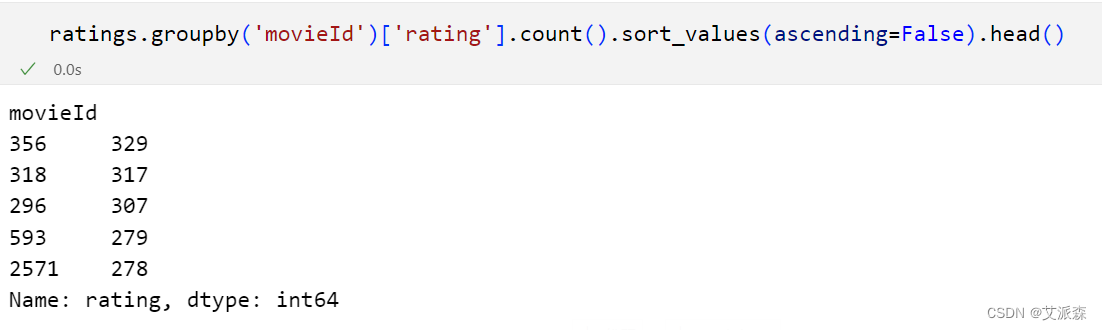
查看评论最多的电影
4.2创建训练集与测试集
# 拆分训练集和测试集
X_train, X_test = train_test_split(ratings, test_size = 0.30, random_state = 42)
print(X_train.shape)
print(X_test.shape)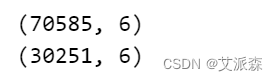
# 将评分转换为电影特征
user_data = X_train.pivot(index = 'userId', columns = 'movieId', values = 'rating').fillna(0)
user_data.head()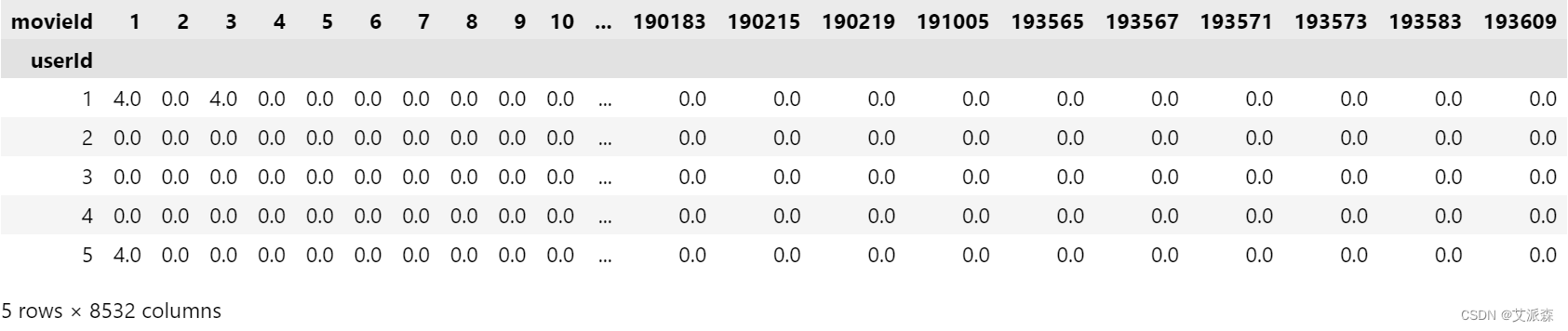
创建训练和测试数据集的副本
数据集“虚拟列车”(Dummy Train)将被用来进行预测,特别是对尚未被用户评分的电影。为了区分已经评分的电影和还没有评分的电影,我们将给用户评分的电影指定一个0分,这表明我们需要在预测过程中忽略它们。相反,为了预测目的,尚未被用户评分的电影将被标记为1。
另一方面,将使用“Dummy Test”数据集进行评估。在评价过程中,我们只会对用户评价过的电影进行预测,并将其标记为1。这与“虚拟火车”数据集相反,在“虚拟火车”数据集中,我们只关注那些已经被评为评估目的的电影。
dummy_train = X_train.copy()
dummy_test = X_test.copy()
dummy_train['rating'] = dummy_train['rating'].apply(lambda x: 0 if x > 0 else 1)
dummy_test['rating'] = dummy_test['rating'].apply(lambda x: 1 if x > 0 else 0)
dummy_train = dummy_train.pivot(index = 'userId', columns = 'movieId', values = 'rating').fillna(1)
dummy_test = dummy_test.pivot(index ='userId', columns = 'movieId', values = 'rating').fillna(0)
dummy_train.head()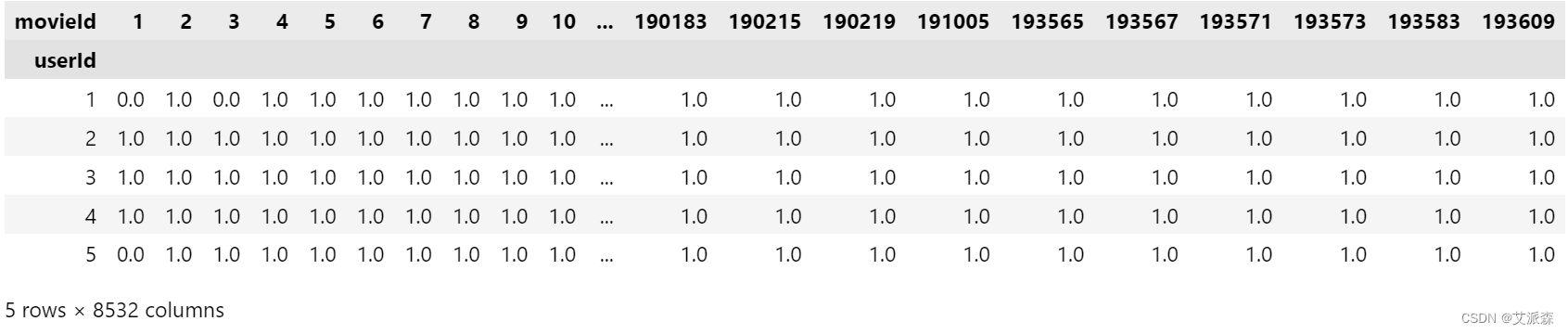
4.3基于用户的协同过滤
基于用户的相似矩阵-使用余弦相似度
# 基于用户的相似矩阵-使用余弦相似度
user_similarity = cosine_similarity(user_data)
user_similarity[np.isnan(user_similarity)] = 0
print(user_similarity)
print("- "*10)
print(user_similarity.shape)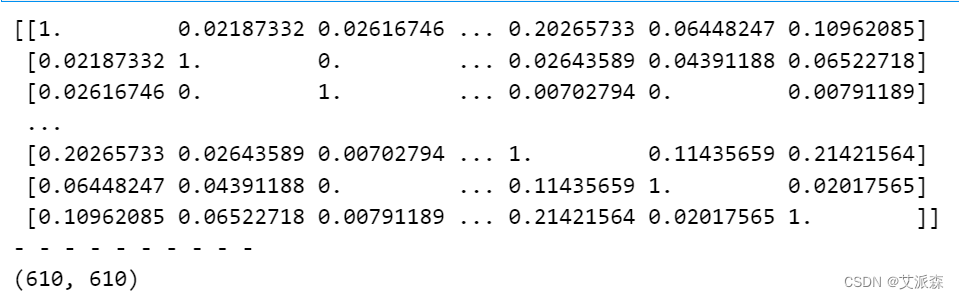
预测电影的用户评分
user_predicted_ratings = np.dot(user_similarity, user_data)
print(user_predicted_ratings)
print(user_predicted_ratings.shape)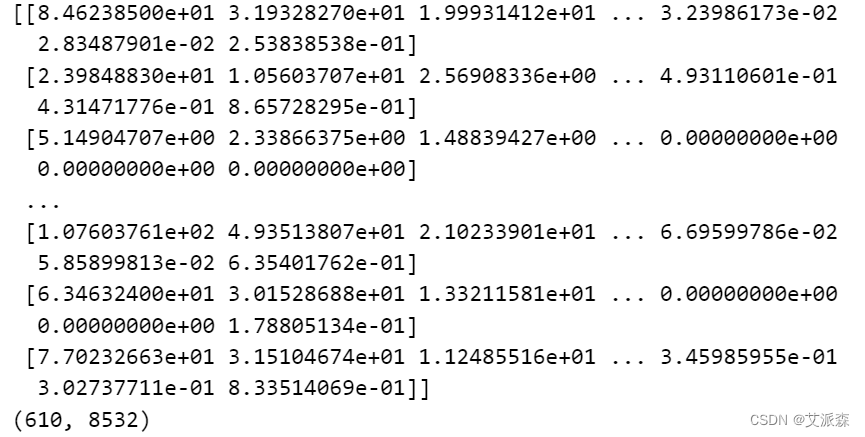
我们的目标是提供电影推荐,排除用户已经观看和评分的电影。我们特别感兴趣的是推荐用户尚未评分的电影,我们将忽略任何已经收到用户评分的电影。为了实现这一点,我们将依赖之前构建的虚拟训练矩阵,它可以帮助我们识别哪些电影已经被用户评分过,因此应该被排除在推荐之外。
user_final_ratings = np.multiply(user_predicted_ratings, dummy_train)
user_final_ratings.head()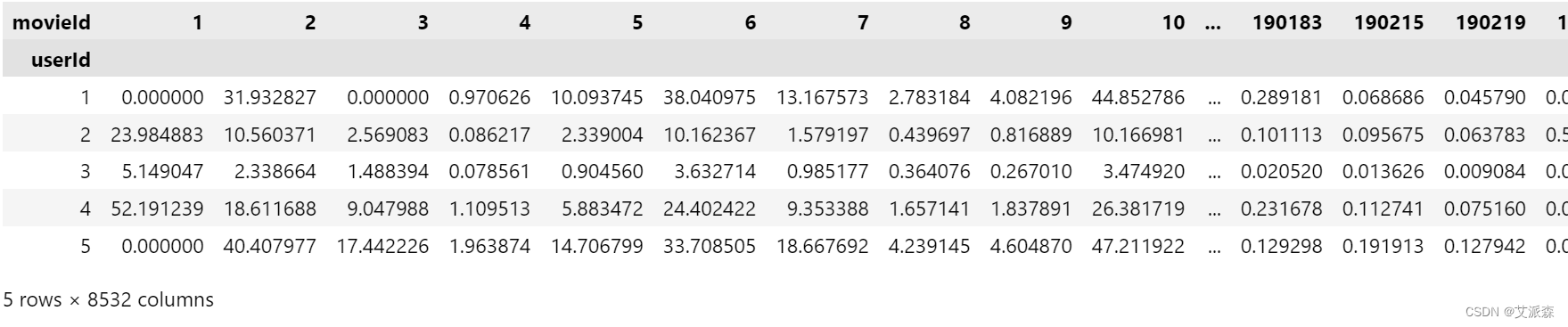
给用户ID为42的推荐的前5部电影
user_final_ratings.iloc[42].sort_values(ascending = False)[0:5]
user_ratings = user_final_ratings.iloc[42]
top_movie_ids = user_ratings.sort_values(ascending=False).head(5).index
top_movies = movies[movies['movieId'].isin(top_movie_ids)][['movieId', 'title']]
print("Top 5 movie recommendations for User 42:")
for movie_id, movie_title in zip(top_movies['movieId'], top_movies['title']):
print(f"Movie ID: {movie_id}, Title: {movie_title}")
4.4基于项目的协同过滤
使用透视表得出每个用户对每个电影的评分,并用0填充缺失值
movie_features = X_train.pivot(index = 'movieId', columns = 'userId', values = 'rating').fillna(0)
movie_features.head()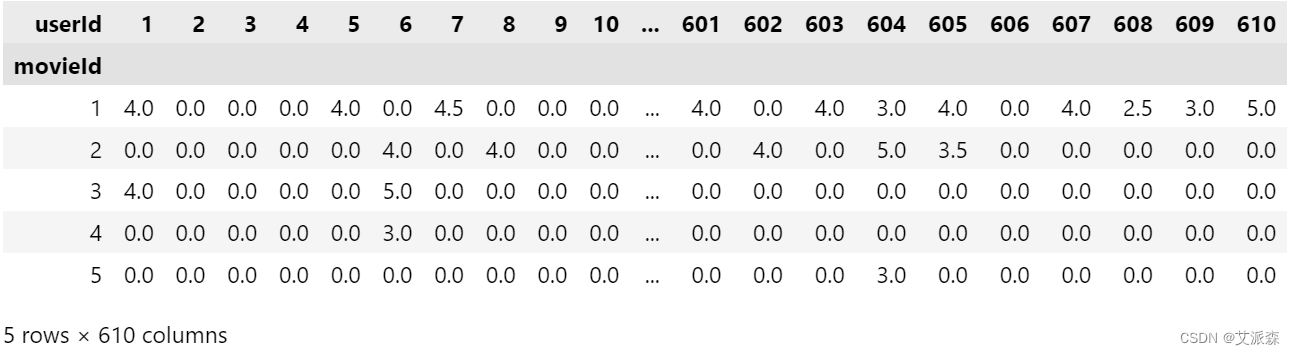
基于项目的相似度矩阵-使用余弦相似度
item_similarity = cosine_similarity(movie_features)
item_similarity[np.isnan(item_similarity)] = 0
print(item_similarity)
print("- "*10)
print(item_similarity.shape)
预测电影的用户评分
item_predicted_ratings = np.dot(movie_features.T, item_similarity)
print(item_predicted_ratings)
print(item_predicted_ratings.shape)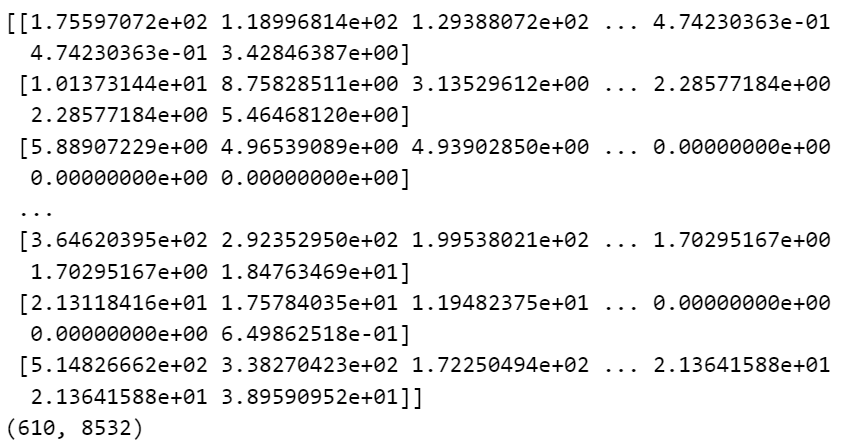
仅过滤用户未评分的电影的评分以进行推荐
item_final_ratings = np.multiply(item_predicted_ratings, dummy_train)
item_final_ratings.head()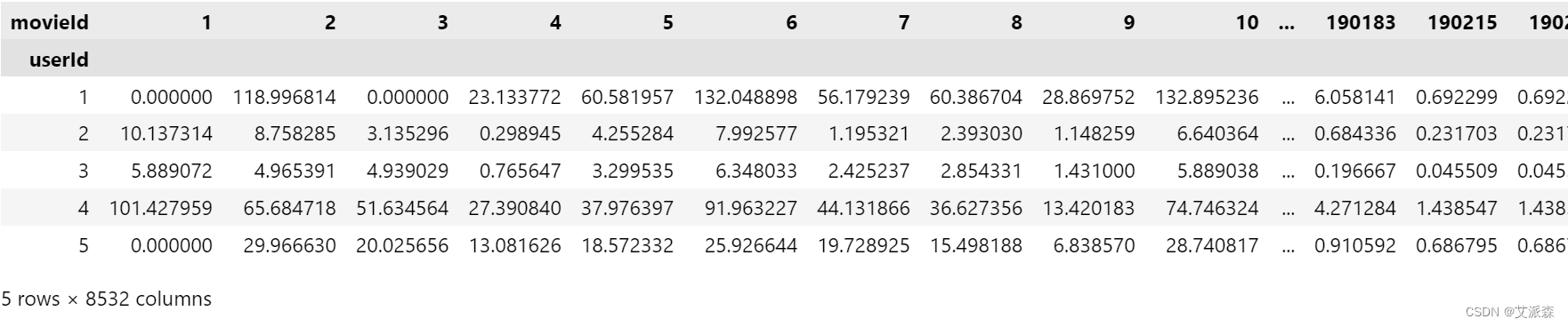
给用户ID为42推荐的前5部电影
item_final_ratings.iloc[42].sort_values(ascending = False)[0:5]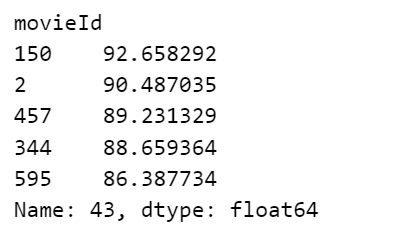
item_ratings = item_final_ratings.iloc[42]
top_movie_ids = item_ratings.sort_values(ascending=False).head(5).index
top_movies = movies[movies['movieId'].isin(top_movie_ids)][['movieId', 'title']]
print("Top 5 movie recommendations for User 42:")
for movie_id, movie_title in zip(top_movies['movieId'], top_movies['title']):
print(f"Movie ID: {movie_id}, Title: {movie_title}")
4.5基于模型的协同过滤
我们将通过分析电影评分和识别特定用户的评分与看过类似电影的其他用户的评分之间的相似性来向用户推荐商品。为此,我们将采用基于模型的协同过滤技术。这种方法允许我们根据他们的集体数据,通过识别多个用户的偏好模式来预测特定用户的电影偏好。
filtered = ratings[ratings['movieId']==50]['title']
filtered.unique()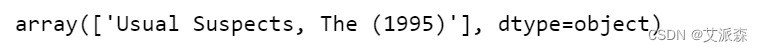
效用矩阵
效用矩阵包含完整的用户电影偏好数据集,通常表示为矩阵。效用矩阵趋于稀疏,因为没有用户会对整个列表中的每部电影进行评分或观看。
rating_crosstab = pd.pivot_table(data=ratings,
values='rating',
index='userId',
columns='title', fill_value=0)
rating_crosstab.head()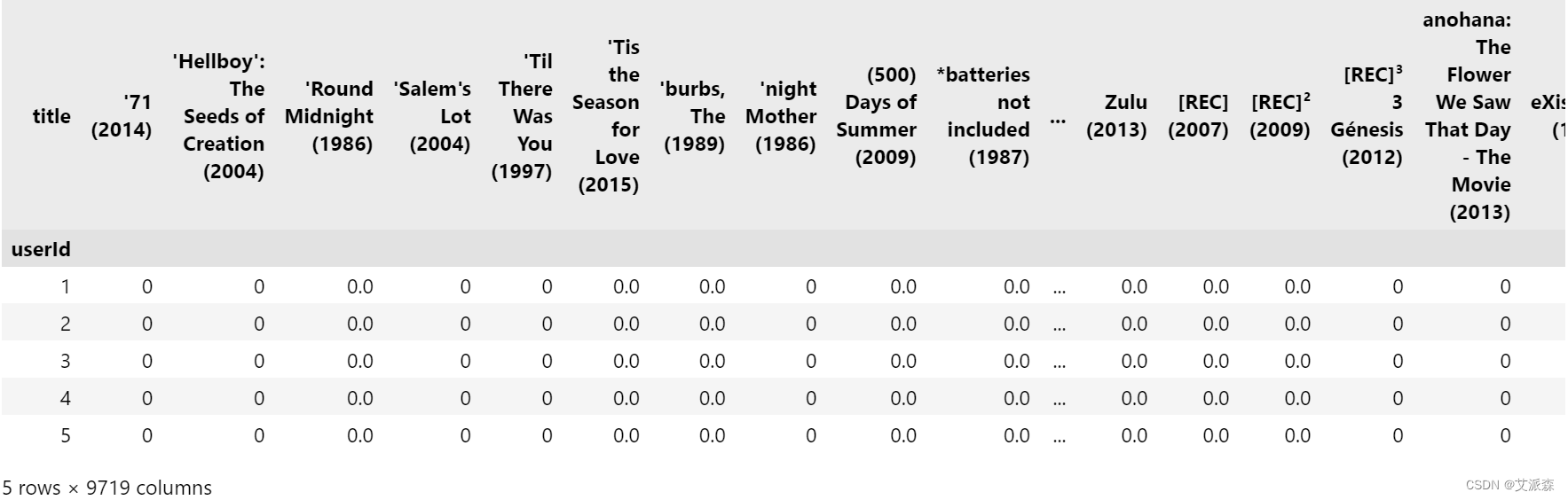
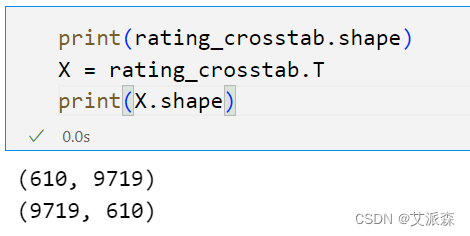
分解矩阵
svd = TruncatedSVD(n_components=12, random_state=12)
resultant_matrix = svd.fit_transform(X)
resultant_matrix.shape
相关矩阵
corr_mat = np.corrcoef(resultant_matrix)
corr_mat.shape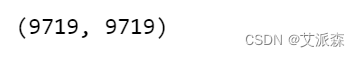
movies_names = rating_crosstab.columns
movies_list = list(rating_crosstab.columns)
usual_suspects = movies_list.index('Usual Suspects, The (1995)')
print(usual_suspects)
corr_usual_suspects = corr_mat[usual_suspects]
corr_usual_suspects.shape
推荐10部高度相关的电影
print('Recommended movie: ', movies_names[(corr_usual_suspects<1.0)
& (corr_usual_suspects>0.95)][0:9])
虽然我们要求输出的是前10部电影,但是满足要求的只有3部。
5.总结
本实验采用用户对电影的评分数据,利用基于用户、项目和模型的协同过滤方法,旨在提高电影推荐系统的准确性和个性化程度。以下是对实验的总结:
-
基于用户的协同过滤: 通过分析用户之间的相似性,实验中采用了基于用户的协同过滤方法。该方法利用用户历史的电影评分数据,找到具有相似评分模式的用户群体,并向目标用户推荐这些相似用户喜欢的电影。实验结果表明,基于用户的协同过滤在某些情况下能够有效提高推荐的准确性。
-
基于项目的协同过滤: 本实验还采用了基于项目的协同过滤方法,通过分析电影之间的相似性,向用户推荐与其过去喜欢的电影相似的其他电影。这种方法可以克服基于用户的方法中可能存在的用户个体差异,提高推荐的普适性。实验结果显示,基于项目的协同过滤对于一些用户具有更好的推荐性能。
-
基于模型的协同过滤: 为了进一步提高推荐系统的性能,本实验引入了基于模型的协同过滤方法。该方法通过建立数学模型来捕捉用户和电影之间的复杂关系,可以更好地处理数据稀疏性和冷启动问题。实验结果表明,基于模型的协同过滤在许多情况下都能够提供更为准确和个性化的推荐。
-
改进方向: 尽管实验取得了一定的成功,仍然存在一些改进的空间。未来的研究可以考虑引入更多的上下文信息,例如用户的社交关系、电影的内容特征等,以进一步提高推荐系统的精准度和适应性。
总体而言,本实验通过基于用户、项目和模型的协同过滤方法,有效提升了电影推荐系统的性能,为个性化推荐领域的研究提供了有益的经验和启示。
文末推荐与福利
《巧用ChatGPT高效搞定Excel数据分析》免费包邮送出3本!

内容简介:
本书以Excel 2021办公软件为操作平台,创新地借助当下最热门的AI工具——ChatGPT,来学习Excel数据处理与数据分析的相关方法、技巧及实战应用,同时也向读者分享在ChatGPT的帮助下进行数据分析的思路和经验。
全书共10章,分别介绍了在ChatGPT的帮助下,使用Excel在数据分析中的应用、建立数据库、数据清洗与加工、计算数据、简单分析数据、图表分析、数据透视表分析、数据工具分析、数据结果展示,最后通过行业案例,将之前学习的数据分析知识融会贯通,应用于实际工作中,帮助读者迅速掌握多项数据分析的实战技能。
本书内容循序渐进,章节内容安排合理,案例丰富翔实,适合零基础想快速掌握数据分析技能的读者学习,可以作为期望提高数据分析操作技能水平、积累和丰富实操经验的商务人员的案头参考书,也可以作为各大、中专职业院校,以及计算机培训班的相关专业的教学参考用书。
编辑推荐:
(1)ChatGPT指导,学习简单:利用ChatGPT引导学习,轻松学会各种知识技能
(2)案例翔实,实用性强:案例涵盖各行各业,商业性和实用性强
(3)图文并茂,易学易会:知识讲解步骤引导+图解操作,看书学习不枯燥
(4)实战技巧,高手支招:精选24个实用技巧,对知识查漏补缺和拓展延伸
(5)配套资源,轻松学习:配套学习文件+同步视频讲解+精美的PPT课件
- 抽奖方式:评论区随机抽取3位小伙伴免费送出!
- 参与方式:关注博主、点赞、收藏、评论区评论“人生苦短,拒绝内卷!”(切记要点赞+收藏,否则抽奖无效,每个人最多评论三次!)
- 活动截止时间:2023-11-19 20:00:00
名单公布时间:2023-11-19 21:00:00

资料获取,更多粉丝福利,关注下方公众号获取


















 2417
2417











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











