








🤵♂️ 个人主页:@艾派森的个人主页
✍🏻作者简介:Python学习者
🐋 希望大家多多支持,我们一起进步!😄
如果文章对你有帮助的话,
欢迎评论 💬点赞👍🏻 收藏 📂加关注+
目录
1.项目背景
在当前教育与就业市场日益紧密相连的背景下,会计专业作为商科领域的核心专业之一,其毕业生的就业前景与薪资水平一直备受关注。随着高等教育的普及和会计专业教育的深入发展,每年有大量的会计专业毕业生涌入就业市场,然而,就业市场的竞争激烈程度与毕业生对薪资的期望往往存在较大的落差。这一现象不仅增加了毕业生的就业压力,也对企业的招聘策略提出了挑战。
为了更准确地评估会计专业毕业生的就业竞争力,并帮助他们建立合理的薪资预期,从而提高整体就业率,本研究引入了机器学习技术来构建会计专业毕业生薪资预测模型。机器学习作为人工智能的一个重要分支,能够通过对大量历史数据的分析和学习,发现数据背后的规律和模式,进而对未来的情况进行预测。在薪资预测领域,机器学习模型能够综合考虑多种影响薪资的因素,如学历层次、专业技能、工作经验、就业地区等,从而提供更加精确和个性化的预测结果。
本研究的实验背景正是基于这样的现实需求和技术背景。我们收集了来自多个渠道(如招聘网站、高校就业中心、企业HR部门等)的会计专业毕业生薪资数据,这些数据涵盖了毕业生的基本信息、教育背景、工作经历、薪资水平等多个维度。通过对这些数据进行预处理和特征提取,我们构建了一个基于机器学习的会计专业毕业生薪资预测模型。该模型旨在利用机器学习算法的强大能力,对会计专业毕业生的薪资进行精准预测,为毕业生提供有价值的参考信息,同时也为企业招聘提供科学的决策依据。
综上所述,本研究的实验背景在于解决会计专业毕业生薪资预测中的现实问题,通过引入机器学习技术,构建精准的薪资预测模型,为毕业生和企业提供有益的参考和支持。
2.数据集介绍
本研究的数据集来源于拉勾招聘网站。
我们使用Python网络爬虫Selenium技术模拟浏览器行为并最终获取了拉勾网中会计相关岗位的招聘数据,其中包括岗位名称、公司名称、工作经验要求、学历要求、工作地点、薪酬、公司规模以及公司福利等相关的数据。
3.技术工具
Python版本:3.9
代码编辑器:jupyter notebook
4.实验过程
4.1导入数据
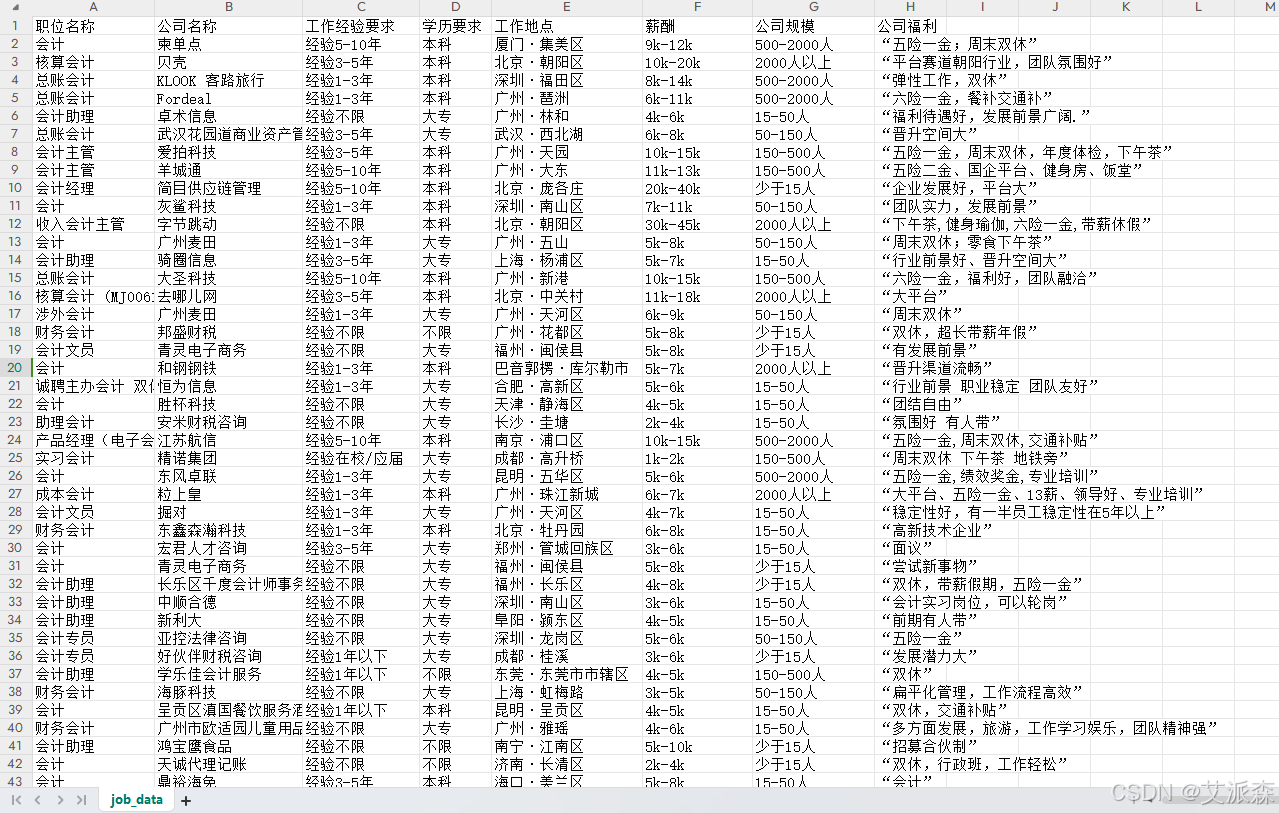
首先使用Pandas库导入我们的数据集并打印前五行数据
查看数据大小

从结果可以发现原始数据集共有542行,8列
查看数据基本信息
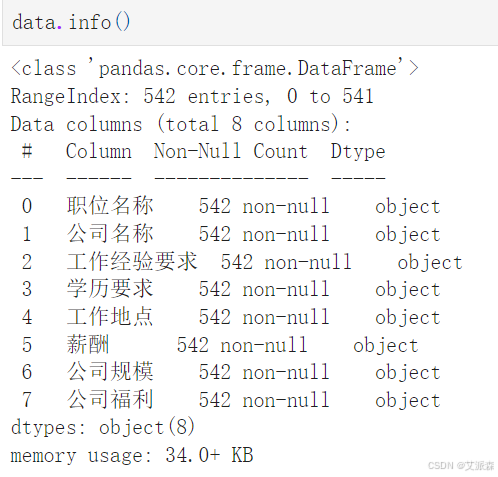
可以看到本数据集各列的名称、有多少个非空值以及数据类型
查看数据的描述性统计
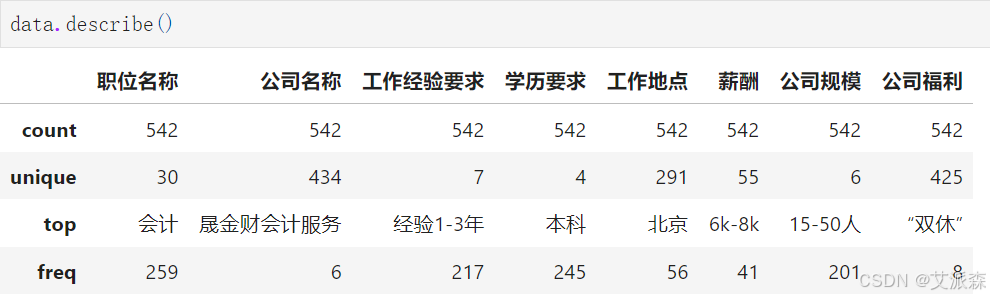
在描述性统计结果中,我们可以看到各变量的总数、唯一值个数、出现最高频率的值以及出现的次数。
4.2数据预处理
在现实生活问题中,我们得到的原始数据往往非常混乱、不全面,机器学习模型往往无法从中有效识别并提取信息。数据和特征决定了机器学习的上限,而模型和算法只是逼近这个上限而已,真实的训练数据总是存在各种各样的问题:各特征(变量)的尺度(量纲)和数量级差异大、存在噪声:包含错误和异常值、存在缺失值、存在冗余特征(变量)等问题,存在上述问题的数据有时也称为“脏数据”,这些“脏数据”会影响机器学习模型预测的有效性(有时会得到相反的结论)、可重复性和泛化能力,从而影响模型的质量。因此在采集完数据后,机器学习建模的首要步骤以及主要步骤便是数据预处理。
数据预处理就是一种数据挖掘技术,本质就是为了将原始数据转换为可以理解的格式或者符合我们挖掘的格式。它可以改进数据的质量,从而有助于提高其后的挖掘过程的准确率和效率,得到高质量的数据。
统计数据集中缺失值的情况
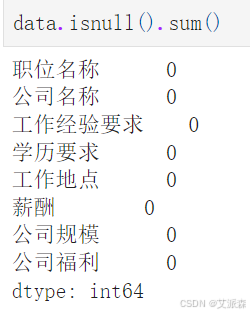
可以发现原始数据集中并不存在缺失值
统计重复值情况
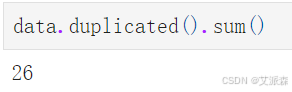
可以发现原始数据集中共有26个重复数据
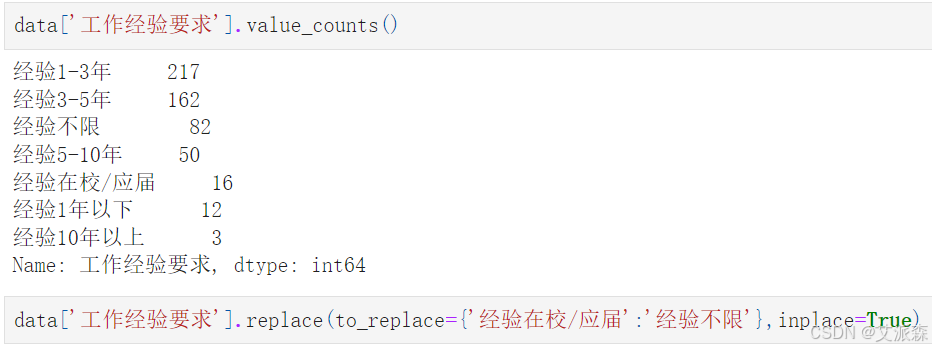
对工作经验要求变量进行处理,将经验在校/应届改为经验不限
处理工作地点变量提取出工作城市
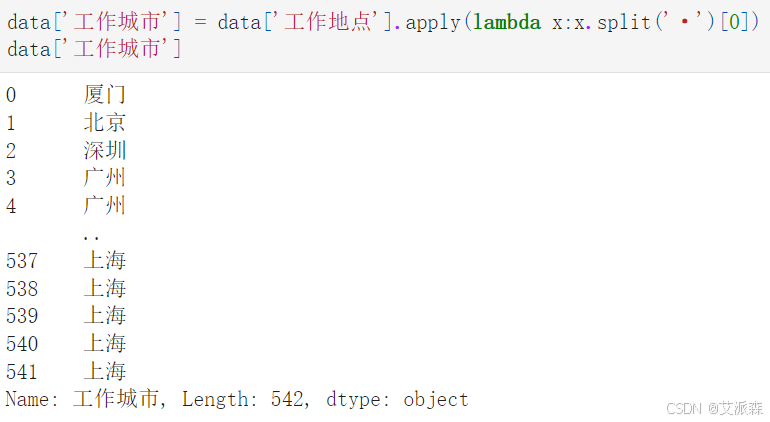
处理薪酬变量得到平均薪资,即薪酬范围的中间值

4.3数据可视化
首先导入数据可视化用到的第三方库
分析平均薪资最高的TOP10城市
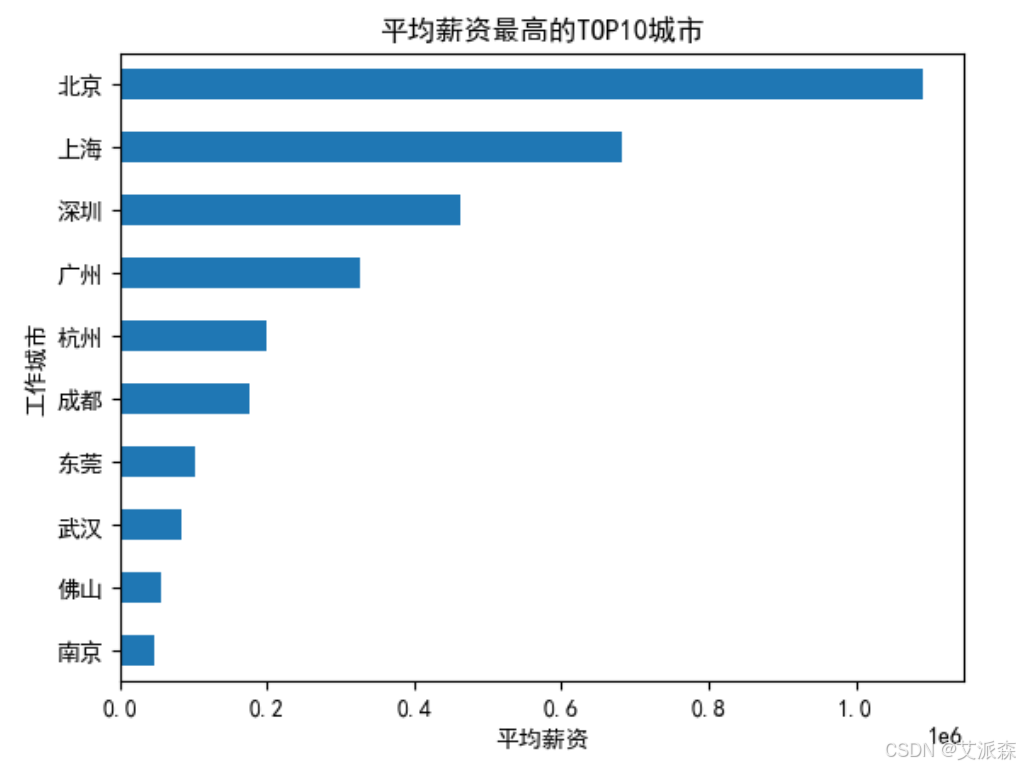
可以看到平均薪资最高的是北京、上海、深圳。
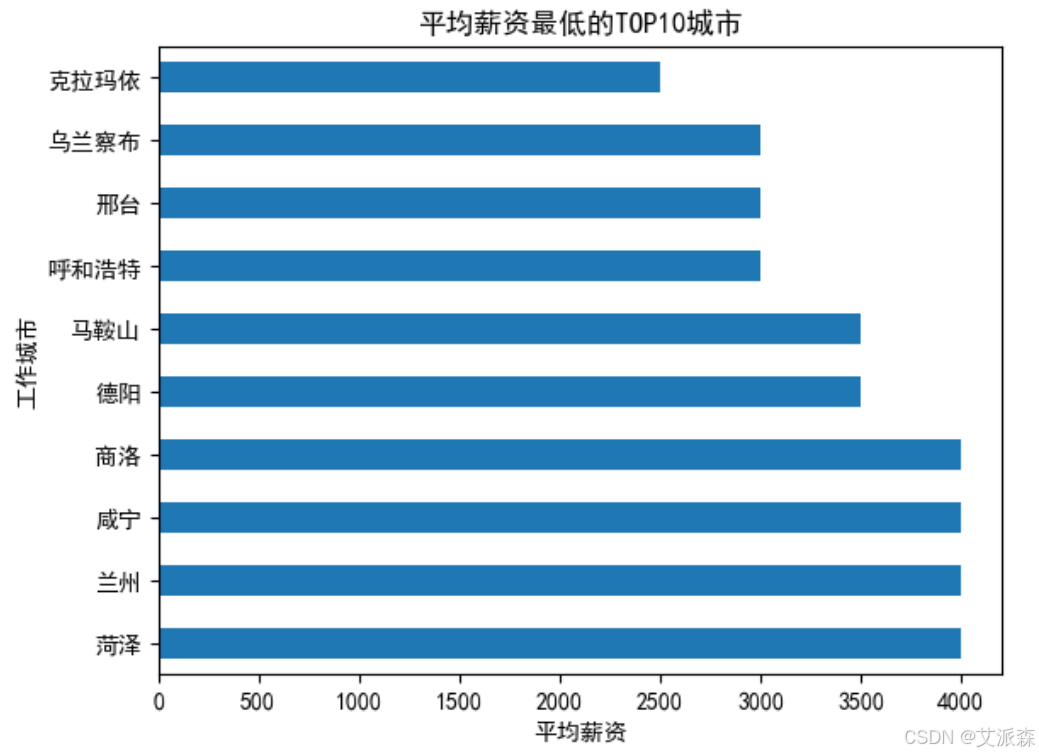
分析平均薪资最低的TOP10城市
分析平均薪资最高的TOP10职位
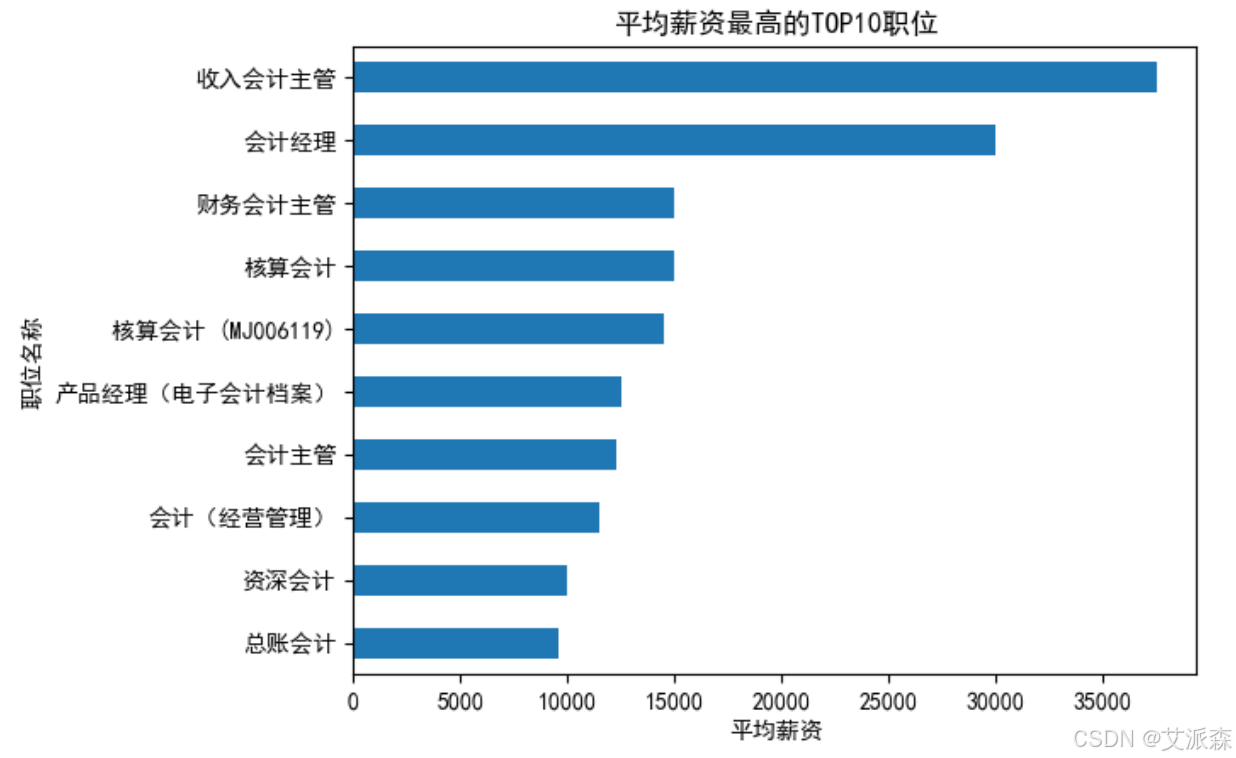
可以看到收入会计主管和会计经理岗位的平均薪资最高。
分析平均薪资最低的TOP10职位
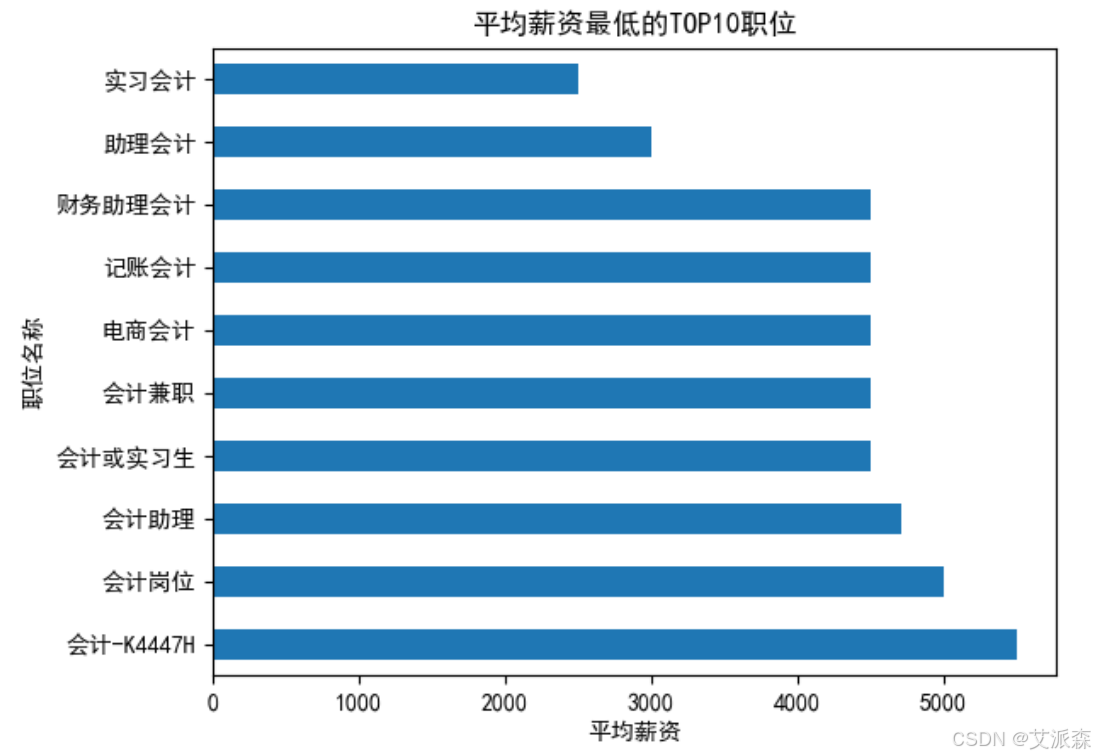
可以看出平均薪资最低的一般都是实习、兼职、助理相关的岗位。
分析不同学历要求的平均薪资
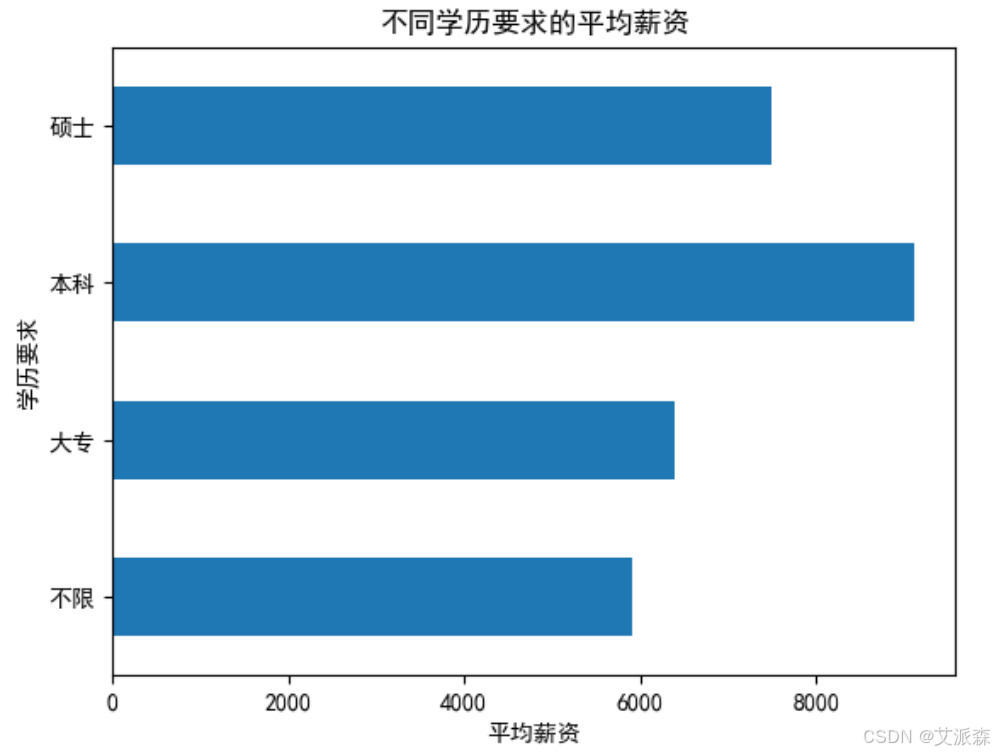
从图中看出本科生的平均薪资最高,可能硕士的岗位数据较少。
分析不同工作经验的平均薪资
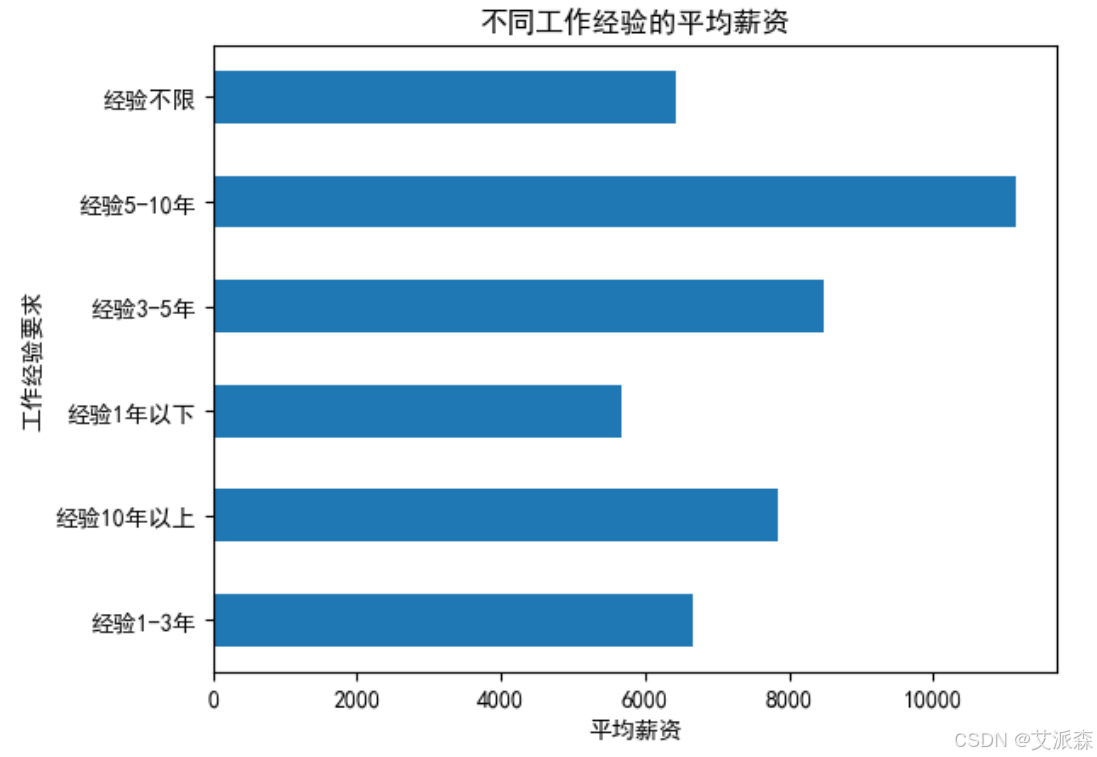
从图中可以看出经验5-10年的平均薪资最高。
分析工作经验要求
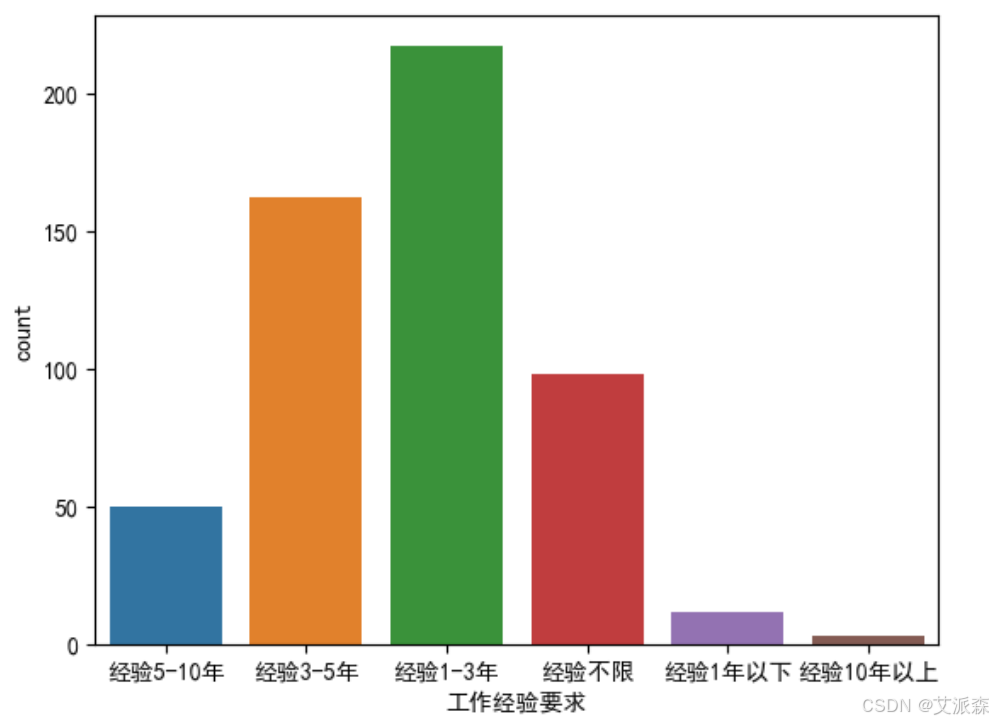
从图中看出,大部分岗位要求的为经验1-5年和经验不限的。
分析学历要求
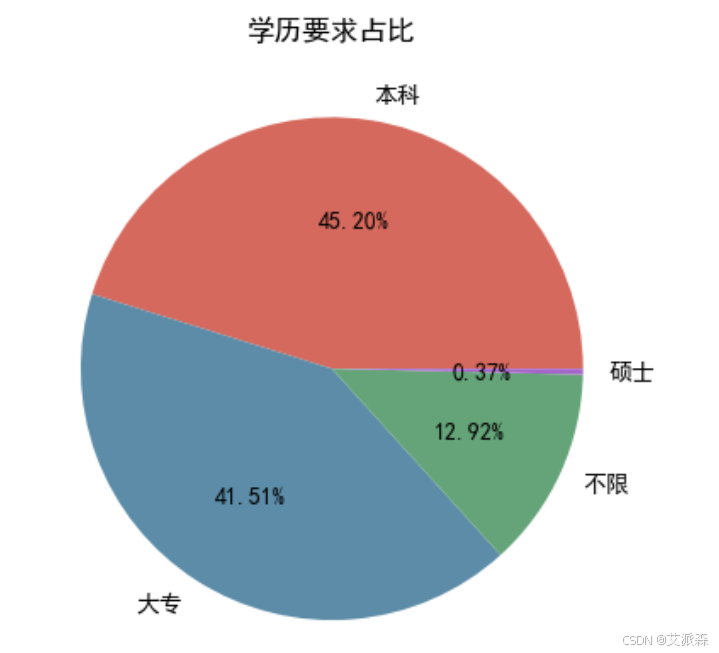
从图中看出本科和大专数量最多。
公司福利词云图

从词云图看出,双休、五险一金、氛围、福利、晋升发展空间等词较多,说明会计岗位的公司福利都挺不错。
4.4特征工程
筛选变量
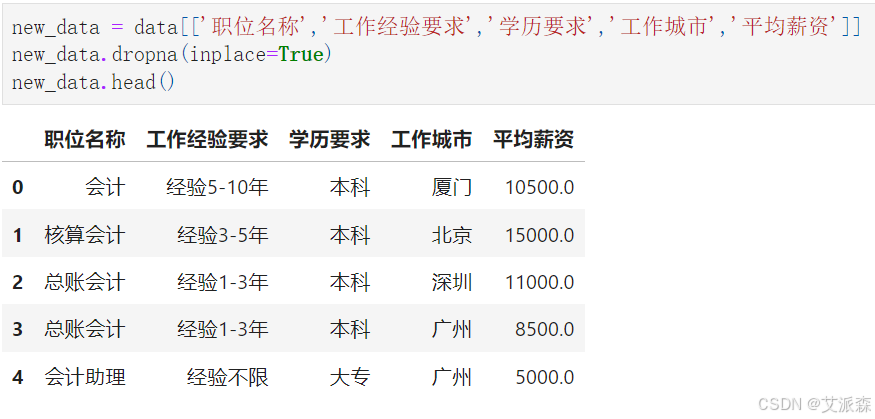
特征编码处理
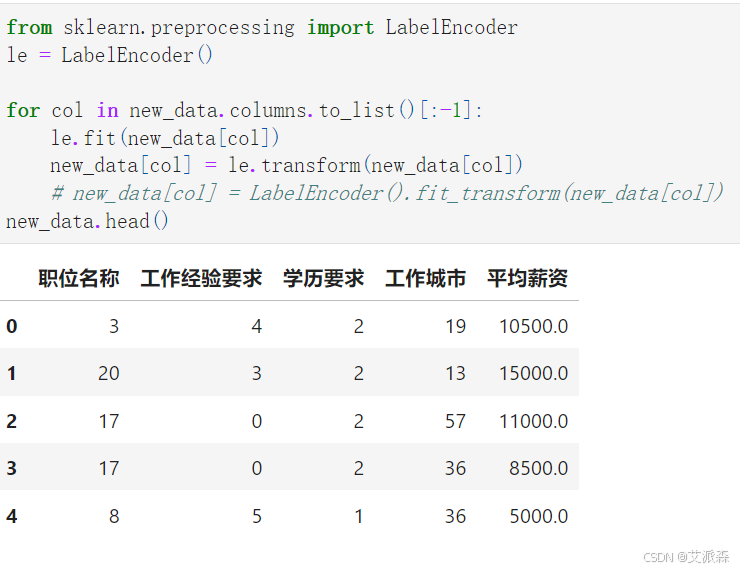
准备建模数据X和y, 并拆分数据集为训练集和测试集,其中测试集比例为0.2

4.5构建模型
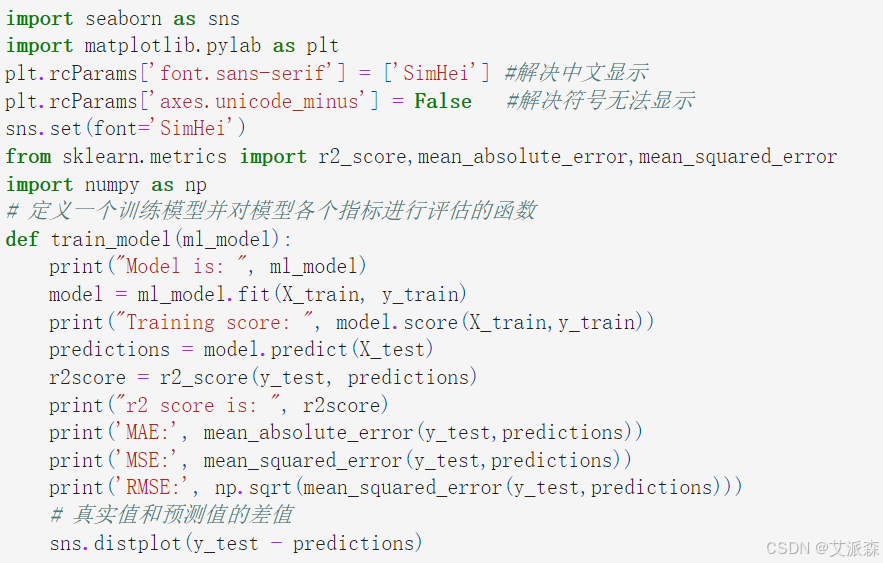
定义一个定义一个训练模型并对模型各个指标进行评估的函数
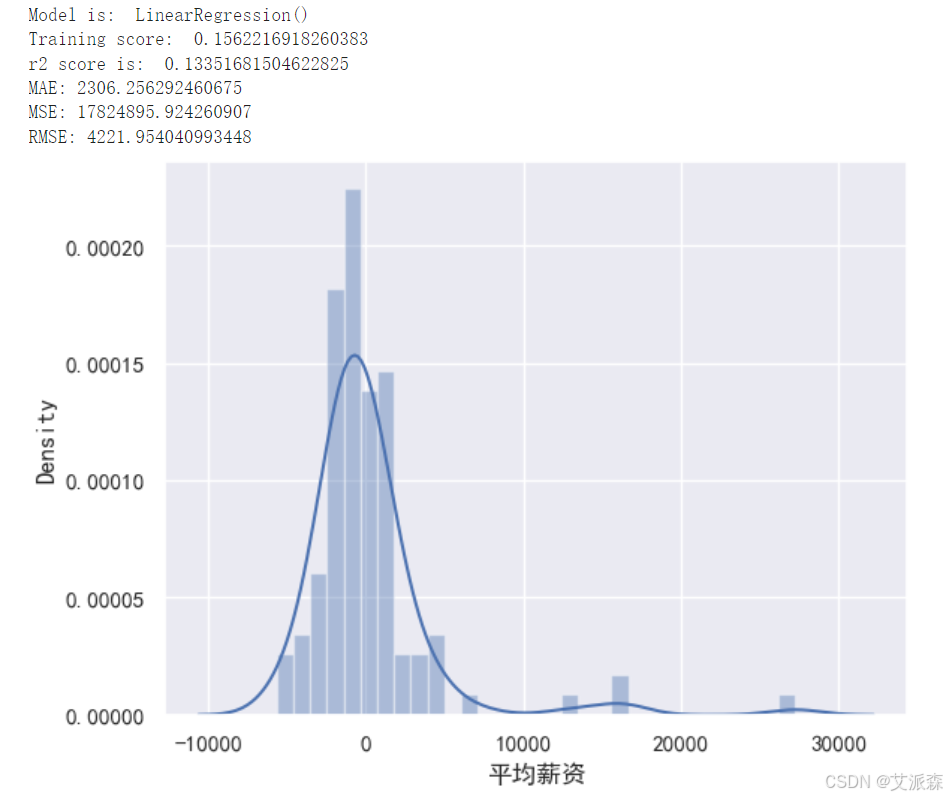
构建多元线性回归模型
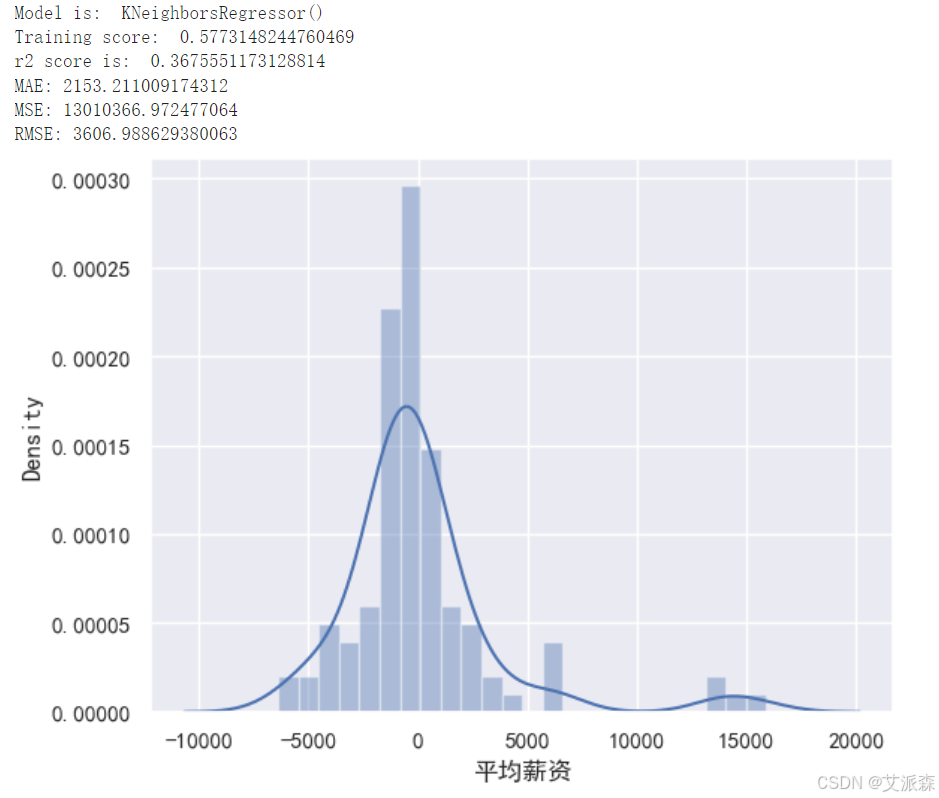
构建KNN模型
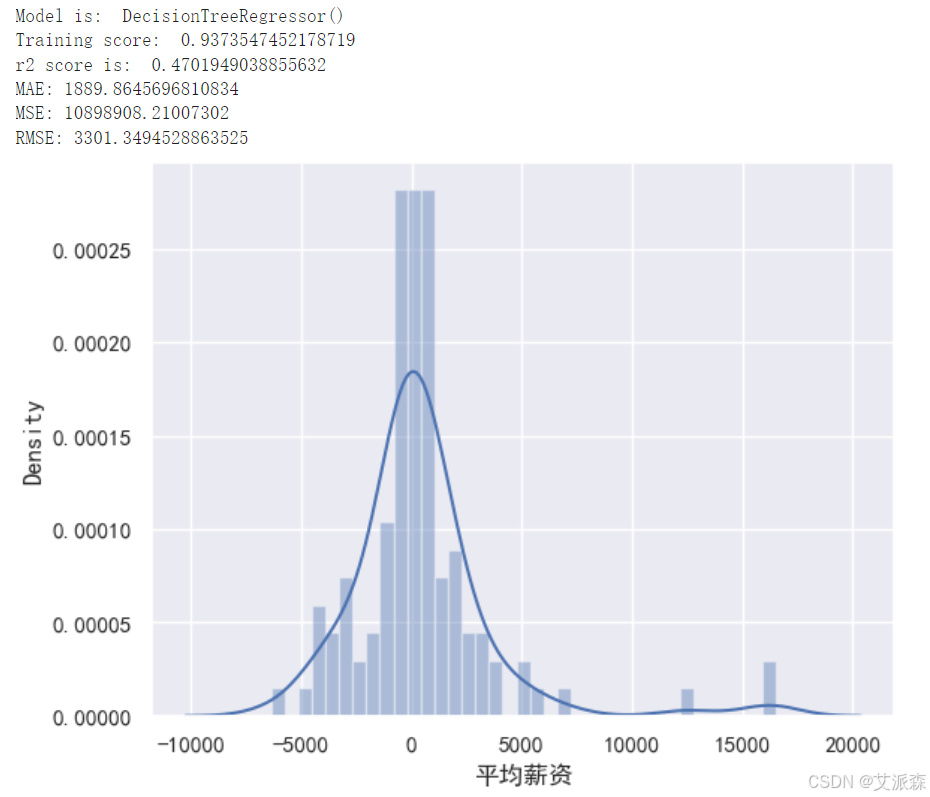
构建决策树模型
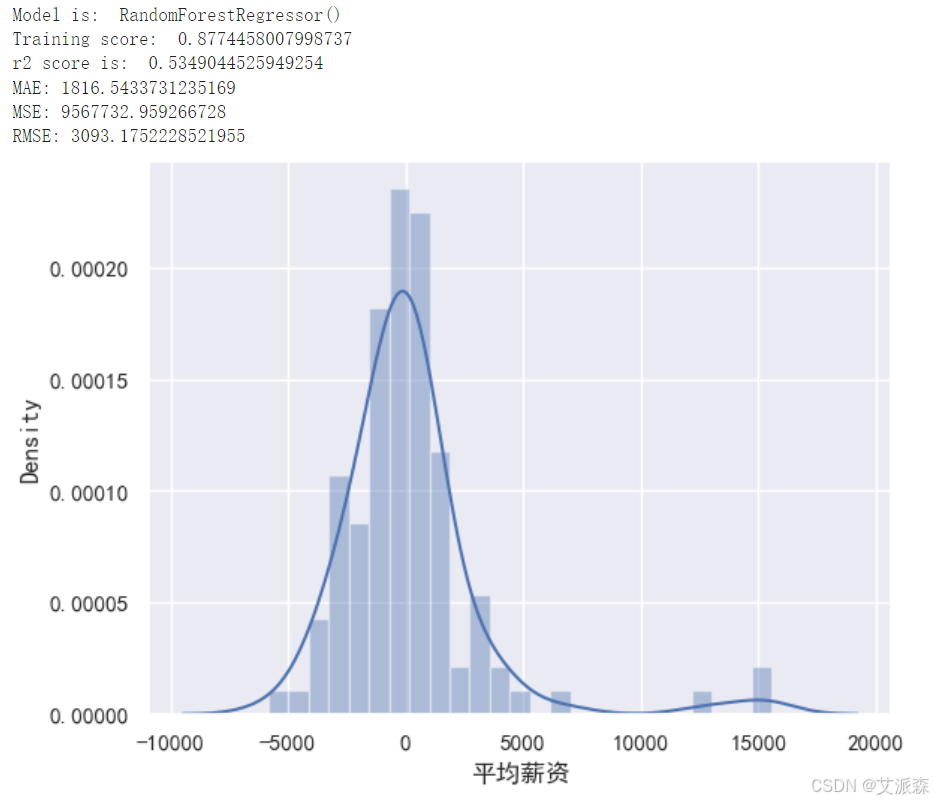
构建随机森林模型
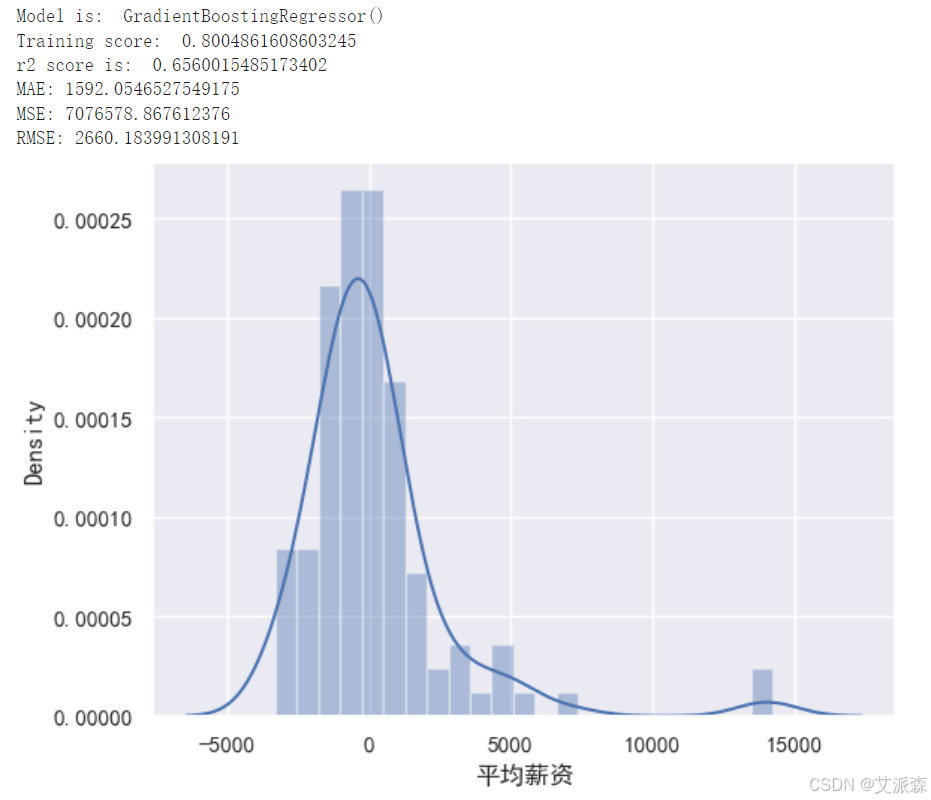
构建GBDT模型
构建XGBoost模型
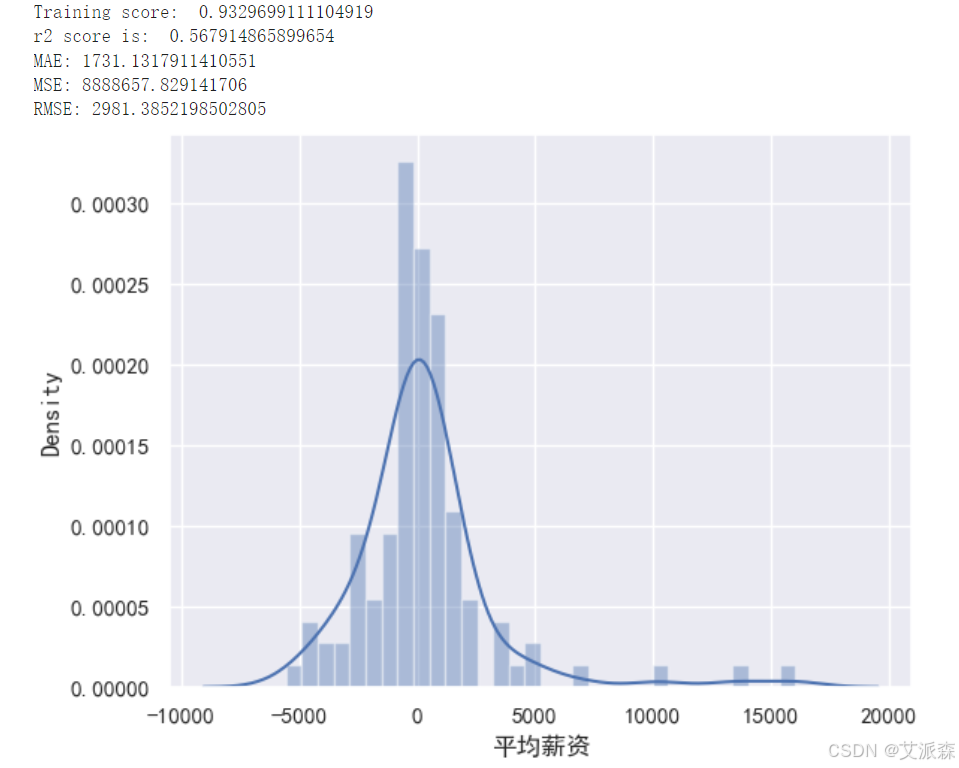
从以上构建模型中,我们看出xgboost模型的效果最好,故我们最终选取其作为最终模型。
4.6特征重要性
打印特征重要性并可视化
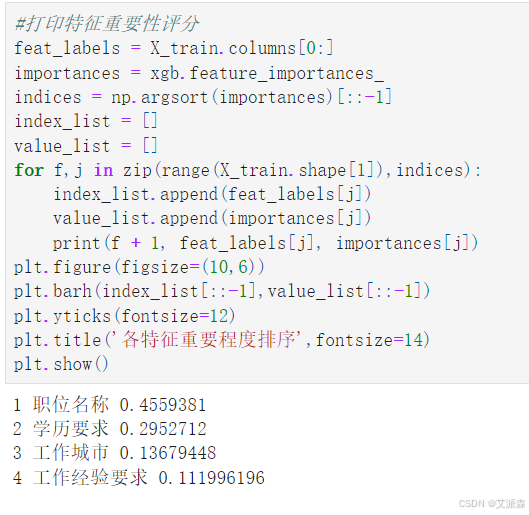
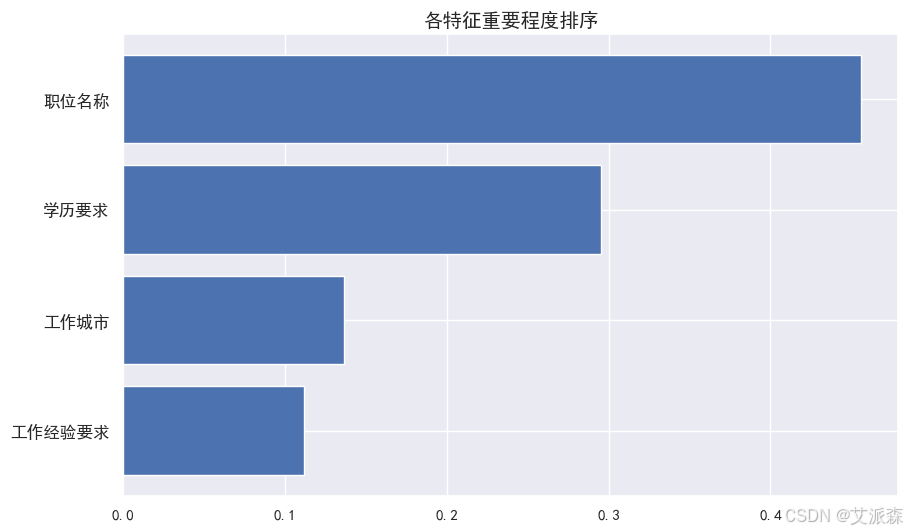
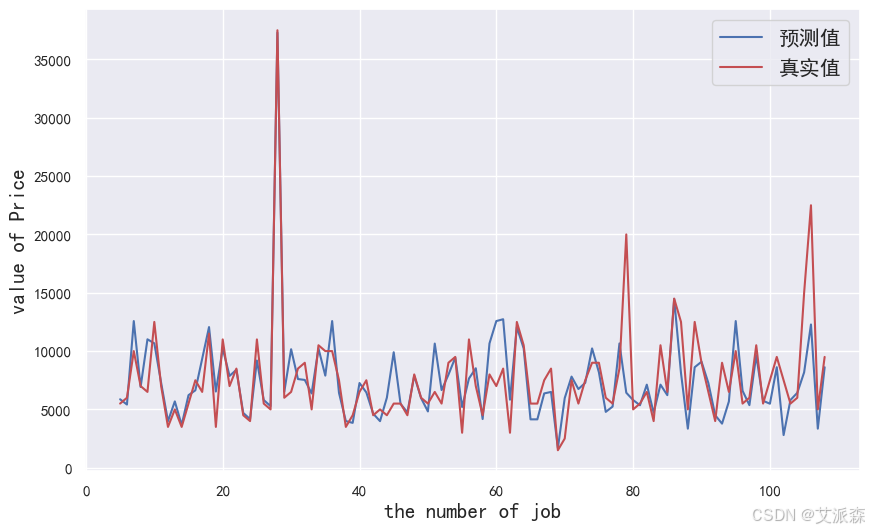
4.7模型预测
使用xgboost模型进行预测并可视化

源代码
import pandas as pd
import warnings
warnings.filterwarnings('ignore')
data = pd.read_csv('job_data.csv')
data.head()
data.shape
data.info()
data.describe()
data.isnull().sum()
data.duplicated().sum()
data.drop_duplicates(inplace=True) # 删除重复数据
data.duplicated().sum()
data['工作经验要求'].value_counts()
data['工作经验要求'].replace(to_replace={'经验在校/应届':'经验不限'},inplace=True)
data['工作城市'] = data['工作地点'].apply(lambda x:x.split('·')[0])
data['工作城市']
def avg_salary(x):
try:
start = x.split('-')[0]
end = x.split('-')[1]
if end[-1] == '千':
start_salary = float(start)*1000
end_salary = float(end[:-1])*1000
elif end[-1] == '万':
if start[-1] == '千':
start_salary = float(start[:-1])*1000
end_salary = float(end[:-1])*10000
else:
start_salary = float(start)*10000
end_salary = float(end[:-1])*10000
elif end[-1] == 'k':
start_salary = float(start[:-1])*1000
end_salary = float(end[:-1])*1000
elif end[-1] == '薪':
salary_number = float(end.split('·')[1][:-1])
if end.split('·')[0][-1] == '万':
if start[-1] == '千':
start_salary = float(start[:-1])*1000/12*salary_number
end_salary = float(end.split('·')[0][:-1])*10000/12*salary_number
else:
start_salary = float(start)*10000/12*salary_number
end_salary = float(end.split('·')[0][:-1])*10000/12*salary_number
elif end.split('·')[0][-1] == '千':
start_salary = float(start)*1000/12*salary_number
end_salary = float(end.split('·')[0][:-1])*1000/12*salary_number
elif end[-1] == '年':
end = end[:-2]
if end[-1] == '万':
if start[-1] == '千':
start_salary = float(start[:-1])*1000
end_salary = float(end[:-1])*10000
else:
start_salary = float(start)*10000
end_salary = float(end[:-1])*10000
return (start_salary+end_salary)/2
except:
return 10000
data['平均薪资'] = data['薪酬'].apply(avg_salary)
data.head()
import matplotlib.pylab as plt
import seaborn as sns
from pyecharts.charts import *
from pyecharts import options as opts
plt.rcParams['font.sans-serif'] = ['SimHei'] #解决中文显示
plt.rcParams['axes.unicode_minus'] = False #解决符号无法显示
# 薪资总体水平最高的TOP10城市
data.groupby('工作城市')['平均薪资'].sum().sort_values(ascending=False)[:10][::-1].plot(kind='barh')
plt.title('薪资总体水平最高的TOP10城市')
plt.show()
# 薪资总体水平最低的TOP10城市
data.groupby('工作城市')['平均薪资'].sum().sort_values(ascending=False)[-10:].plot(kind='barh')
plt.title('薪资总体水平最低的TOP10城市')
plt.show()
# 平均薪资最高的TOP10职位
data.groupby('职位名称')['平均薪资'].mean().sort_values(ascending=False)[:10][::-1].plot(kind='barh')
plt.title('平均薪资最高的TOP10职位')
plt.xlabel('平均薪资')
plt.show()
# 平均薪资最低的TOP10职位
data.groupby('职位名称')['平均薪资'].mean().sort_values(ascending=False)[-10:].plot(kind='barh')
plt.title('平均薪资最低的TOP10职位')
plt.xlabel('平均薪资')
plt.show()
# 不同学历要求的平均薪资
data.groupby('学历要求')['平均薪资'].mean().plot(kind='barh')
plt.title('不同学历要求的平均薪资')
plt.xlabel('平均薪资')
plt.show()
# 不同工作经验的平均薪资
data.groupby('工作经验要求')['平均薪资'].mean().plot(kind='barh')
plt.title('不同工作经验的平均薪资')
plt.xlabel('平均薪资')
plt.show()
# 工作经验要求
sns.countplot(data=data,x='工作经验要求')
plt.show()
# 学历要求
plt.pie(data['学历要求'].value_counts().values.tolist(),
labels=data['学历要求'].value_counts().index.to_list(),
colors=["#d5695d", "#5d8ca8", "#65a479", "#a564c9"], # 设置饼图颜色
autopct='%.2f%%', # 格式化输出百分比
)
plt.title("学历要求占比")
plt.show()
df2 = data['工作城市'].value_counts()
city_data = city_data = [[x+'市',y] if x[-3:] != '自治州' else [x,y] for x,y in zip(df2.index.to_list(),df2.values.tolist())]
map = Map()
map.add('地区',city_data,
maptype='china-cities',
is_map_symbol_show=False,
label_opts=opts.LabelOpts(is_show=False))
map.set_global_opts(
title_opts=opts.TitleOpts('各城市岗位数量分布'),
visualmap_opts=opts.VisualMapOpts(max_=50,min_=1)
)
map.render(path='各城市岗位数量分布.html')
map.render_notebook()
import jieba
import collections
import re
import stylecloud
from PIL import Image
# 封装一个画词云图的函数
def draw_WorldCloud(df,pic_name,color='black'):
data = ''.join([item for item in df])
# 文本预处理 :去除一些无用的字符只提取出中文出来
new_data = re.findall('[\u4e00-\u9fa5]+', data, re.S)
new_data = "".join(new_data)
# 文本分词
seg_list_exact = jieba.cut(new_data)
result_list = []
with open('停用词库.txt', encoding='utf-8') as f: #可根据需要打开停用词库,然后加上不想显示的词语
con = f.readlines()
stop_words = set()
for i in con:
i = i.replace("\n", "") # 去掉读取每一行数据的\n
stop_words.add(i)
for word in seg_list_exact:
if word not in stop_words and len(word) > 1:
result_list.append(word)
word_counts = collections.Counter(result_list)
# 词频统计:获取前100最高频的词
word_counts_top = word_counts.most_common(100)
print(word_counts_top)
# 绘制词云图
stylecloud.gen_stylecloud(text=' '.join(result_list),
collocations=False, # 是否包括两个单词的搭配(二字组)
font_path=r'C:\Windows\Fonts\msyh.ttc', #设置字体
size=800, # stylecloud 的大小
palette='cartocolors.qualitative.Bold_7', # 调色板
background_color=color, # 背景颜色
icon_name='fas fa-circle', # 形状的图标名称
gradient='horizontal', # 梯度方向
max_words=2000, # stylecloud 可包含的最大单词数
max_font_size=150, # stylecloud 中的最大字号
stopwords=True, # 布尔值,用于筛除常见禁用词
output_name=f'{pic_name}.png') # 输出图片
# 打开图片展示
img=Image.open(f'{pic_name}.png')
img.show()
draw_WorldCloud(data['公司福利'],'公司福利词云图')
new_data = data[['职位名称','工作经验要求','学历要求','工作城市','平均薪资']]
new_data.dropna(inplace=True)
new_data.head()
from sklearn.preprocessing import LabelEncoder
le = LabelEncoder()
for col in new_data.columns.to_list()[:-1]:
le.fit(new_data[col])
new_data[col] = le.transform(new_data[col])
# new_data[col] = LabelEncoder().fit_transform(new_data[col])
new_data.head()
from sklearn.model_selection import train_test_split
X = new_data.drop('平均薪资',axis=1)
y = new_data['平均薪资']
# 划分数据集
X_train,X_test,y_train,y_test = train_test_split(X,y,test_size=0.2,random_state=42)
import seaborn as sns
import matplotlib.pylab as plt
plt.rcParams['font.sans-serif'] = ['SimHei'] #解决中文显示
plt.rcParams['axes.unicode_minus'] = False #解决符号无法显示
sns.set(font='SimHei')
from sklearn.metrics import r2_score,mean_absolute_error,mean_squared_error
import numpy as np
# 定义一个训练模型并对模型各个指标进行评估的函数
def train_model(ml_model):
print("Model is: ", ml_model)
model = ml_model.fit(X_train, y_train)
print("Training score: ", model.score(X_train,y_train))
predictions = model.predict(X_test)
r2score = r2_score(y_test, predictions)
print("r2 score is: ", r2score)
print('MAE:', mean_absolute_error(y_test,predictions))
print('MSE:', mean_squared_error(y_test,predictions))
print('RMSE:', np.sqrt(mean_squared_error(y_test,predictions)))
# 真实值和预测值的差值
sns.distplot(y_test - predictions)
# 构建多元线性回归
from sklearn.linear_model import LinearRegression
lg = LinearRegression()
train_model(lg)
# 构建knn回归
from sklearn.neighbors import KNeighborsRegressor
knn = KNeighborsRegressor()
train_model(knn)
# 构建决策树回归
from sklearn.tree import DecisionTreeRegressor
tree = DecisionTreeRegressor()
train_model(tree)
# 构建随机森林回归
from sklearn.ensemble import RandomForestRegressor
forest = RandomForestRegressor()
train_model(forest)
# GBDT回归
from sklearn.ensemble import GradientBoostingRegressor
gbdt = GradientBoostingRegressor()
train_model(gbdt)
# 构建xgboost回归模型
from xgboost import XGBRegressor
xgb = XGBRegressor()
train_model(xgb)
#打印特征重要性评分
feat_labels = X_train.columns[0:]
importances = xgb.feature_importances_
indices = np.argsort(importances)[::-1]
index_list = []
value_list = []
for f,j in zip(range(X_train.shape[1]),indices):
index_list.append(feat_labels[j])
value_list.append(importances[j])
print(f + 1, feat_labels[j], importances[j])
plt.figure(figsize=(10,6))
plt.barh(index_list[::-1],value_list[::-1])
plt.yticks(fontsize=12)
plt.title('各特征重要程度排序',fontsize=14)
plt.show()
# 使用xgboost模型预测并可视化
plt.figure(figsize=(10,6))
y_pred = xgb.predict(X_test)
plt.plot(range(len(y_test))[5:200],y_pred[5:200],'b',label='预测值')
plt.plot(range(len(y_test))[5:200],y_test[5:200],'r',label='真实值')
plt.legend(loc='upper right',fontsize=15)
plt.xlabel('the number of job',fontdict={'weight': 'normal', 'size': 15})
plt.ylabel('value of Price',fontdict={'weight': 'normal', 'size': 15})
plt.show()
资料获取,更多粉丝福利,关注下方公众号获取



















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











