






DiffRhythm 是一种基于潜扩散模型(Latent Diffusion Model)的AI音乐生成技术,以其快速生成完整歌曲(最长4分45秒,仅需不到10秒)而著称。ComfyUI 则是一个强大的开源节点式界面,最初用于图像生成,现通过插件扩展支持音乐生成。两者融合的最新成果是 ComfyUI_DiffRhythm,它将 DiffRhythm 的音乐生成能力集成到 ComfyUI 的工作流中,提供灵活的参数调整和可视化操作体验。
本指南将带你完成从安装到生成音乐的完整流程。
第一步:环境准备
-
安装 ComfyUI
- 下载:从 GitHub(github.com/comfyanonymous/ComfyUI)克隆最新版本的 ComfyUI,或下载预编译版本(Windows/macOS/Linux 均支持)。
- 依赖安装:进入 ComfyUI 目录,运行 pip install -r requirements.txt 安装基础依赖。确保安装 PyTorch(推荐 nightly 版以支持最新功能)。
- 启动验证:运行 python main.py,浏览器应打开 localhost:8188,显示默认工作流界面。
-
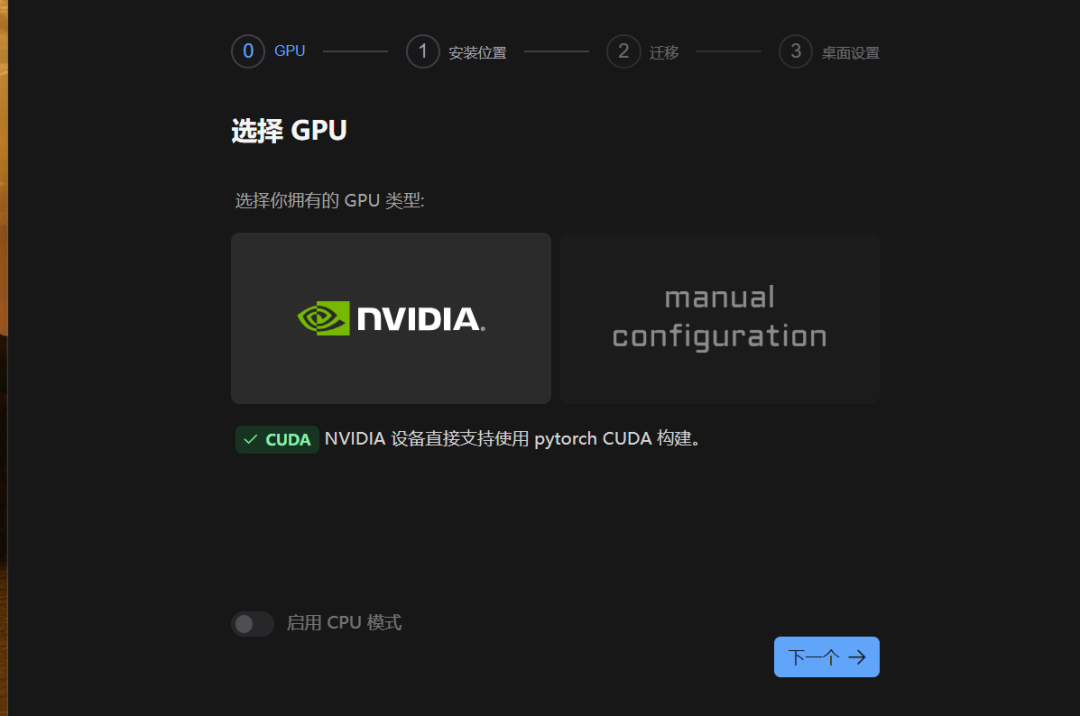
硬件要求
最低配置:NVIDIA GPU(至少 4GB VRAM),支持 CUDA;或 CPU(速度较慢)。
推荐配置:8GB+ VRAM GPU,以支持完整歌曲生成和高保真输出。
第二步:安装 ComfyUI_DiffRhythm 插件
- 克隆插件
打开终端,进入 ComfyUI 的 custom_nodes 目录:
bash
```
cd ComfyUI/custom_nodesgit clone https://github.com/billwuhao/ComfyUI_DiffRhythm.git
```
- 进入插件目录并安装依赖:
bash
```
cd ComfyUI_DiffRhythmpip install -r requirements.txt
```
-
下载模型
-
DiffRhythm-full
-
VAE 模型
-
插件首次运行时会自动从 Hugging Face 下载所需模型(如 cfm_full_model.pt 和 vae_model.pt),并存储在 ComfyUI/models/TTS/DiffRhythm 文件夹中。
-
如果需要手动下载,可访问以下链接:
-
下载后,将 cfm_full_model.pt 和 comfig.json 放入 ComfyUI/models/TTS/DiffRhythm。
-
-
重启 ComfyUI
- 关闭终端,重新运行 python main.py,确保插件加载成功。
 ------
------
第三步:创建音乐生成工作流
-
打开 ComfyUI 界面
-
进入空白工作区。
添加节点
-
Text Input:用于输入歌词或风格提示。
-
Audio Output:用于预览和保存生成的音频。
-
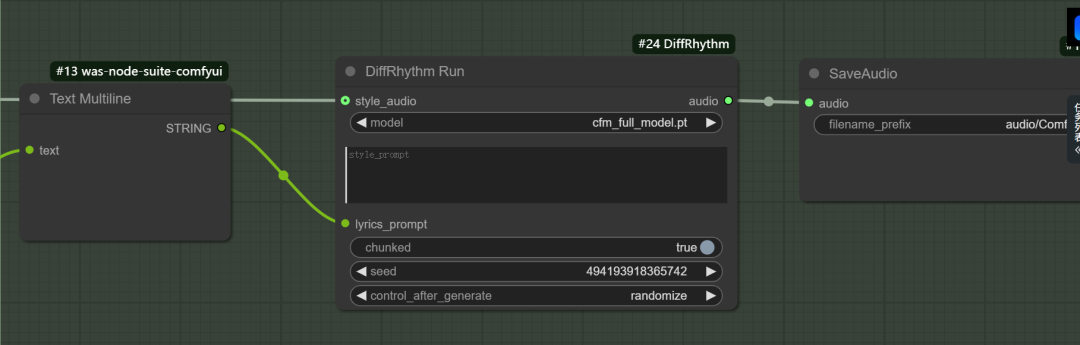
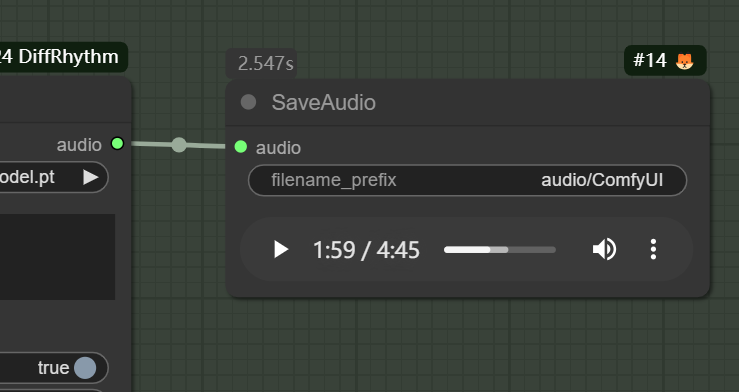
点击右侧面板的“Add Node”按钮,在搜索框中输入 DiffRhythm,选择 DiffRhythm Full Song Generator 节点并添加到工作流。
-
添加其他辅助节点(可选):
连接节点 - 将 Text Input 的输出连接到 DiffRhythm Full Song Generator 的 prompt 输入。
-
将 DiffRhythm Full Song Generator 的 audio 输出连接到 Audio Output。
-
-
配置参数
lyrics:输入歌词(可选,如不填则随机生成)。
-
style_prompt:输入音乐风格(如“pop”、“jazz”)。
-
duration:设置歌曲长度(默认4分45秒,最大值)。
-
steps:推理步数(建议32步,平衡速度与质量)。
-
CFG Scale:无分类器引导尺度(默认7.5,可调至5-10)。
-
DiffRhythm Full Song Generator:
-
Audio Output:设置保存路径(如 output/song.wav)。
-
第四步:生成并预览音乐
-
运行工作流
- 点击右上角的“Queue Prompt”按钮,启动生成过程。
- 生成时间取决于硬件性能,通常在10秒内完成。
-
预览结果
- 生成完成后,Audio Output 节点会显示音频预览控件。点击播放按钮即可试听。
-
调整与优化
如果音乐不符合预期,可调整 style_prompt 或 CFG Scale,然后重新运行。
增加 steps(如50步)可提升细节,但耗时稍长。
第五步:高级用法(可选)
-
云端运行
-
- 如果本地硬件不足,可使用 ComfyUI Cloud(comfy.icu)运行 DiffRhythm 工作流。
- 上传工作流 JSON 文件,按 GPU 使用时间计费,无需本地安装。
-
多风格融合
-
- 在 style_prompt 中输入多种风格(如“pop with jazz elements”),实验混合效果。
-
批量生成
-
- 添加 Batch Prompt 节点,输入多组提示,生成多个音乐片段。
注意事项
-
常见问题排查
-
- 模型未加载:检查 ComfyUI/models/TTS/DiffRhythm 是否包含所需文件。
- 内存不足:降低 duration 或使用云端服务。
- 音频无声:确保提示有效,避免过于抽象的描述。
-
性能优化
-
- 使用 --fast 参数启动 ComfyUI,启用实验性加速。
- 确保 GPU 驱动和 CUDA 版本与 PyTorch 兼容。
-
社区资源
-
-
访问 ComfyUI Discord 或 GitHub Issues 获取最新支持和更新。
为了帮助大家更好地掌握 ComfyUI,我在去年花了几个月的时间,撰写并录制了一套ComfyUI的基础教程,共六篇。这套教程详细介绍了选择ComfyUI的理由、其优缺点、下载安装方法、模型与插件的安装、工作流节点和底层逻辑详解、遮罩修改重绘/Inpenting模块以及SDXL工作流手把手搭建。
-
由于篇幅原因,本文精选几个章节,详细版点击下方卡片免费领取
一、ComfyUI配置指南
- 报错指南
- 环境配置
- 脚本更新
- 后记
- …
二、ComfyUI基础入门
- 软件安装篇
- 插件安装篇
- …
三、 ComfyUI工作流节点/底层逻辑详解
- ComfyUI 基础概念理解
- Stable diffusion 工作原理
- 工作流底层逻辑
- 必备插件补全
- …
四、ComfyUI节点技巧进阶/多模型串联
- 节点进阶详解
- 提词技巧精通
- 多模型节点串联
- …
五、ComfyUI遮罩修改重绘/Inpenting模块详解
- 图像分辨率
- 姿势
- …

六、ComfyUI超实用SDXL工作流手把手搭建
- Refined模型
- SDXL风格化提示词
- SDXL工作流搭建
- …

由于篇幅原因,本文精选几个章节,详细版点击下方卡片免费领取



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









