







文章目录
一、神经网络参数优化器
参考曹健《人工智能实践:Tensorflow2.0 》
深度学习优化算法经历了SGD -> SGDM -> NAG ->AdaGrad -> AdaDelta -> Adam -> Nadam
这样的发展历程。

- 上图中f一般指loss
- 一阶动量:与梯度相关的函数
- 二阶动量:与梯度平方相关的函数
- 不同的优化器,实质上只是定义了不同的一阶动量和二阶动量公式
1.2 SGD(无动量)随机梯度下降。
- 最常用的梯度下降方法是随机梯度下降,即随机采集样本来计算梯度。根据统计学知识有:采样数据的平均值为全量数据平均值的无偏估计。
- 实际计算出来的SGD在全量梯度附近以一定概率出现,batch_size越大,概率分布的方差越小,SGD梯度就越确定,相当于在全量梯度上注入了噪声。适当的噪声是有益的。
- batch_size越小,计算越快,w更新越频繁,学习越快。但是太小的话,SGD梯度和真实梯度差异过大,而且震荡厉害,不利于学习
- SGD梯度有一定随机性,所以可以逃离鞍点、平坦极小值或尖锐极小值区域
- 最初版本是vanilla SGD,没有动量。 m t = g t , V t = 1 m_{t}=g_{t},V_{t}=1 mt=gt,Vt=1(p32—sgd.py)

-
每个bacth_size样本的梯度都不一样,甚至前后差异很大,造成梯度震荡。(比如一个很大的正值接一个很大的负值)
-
神经网络中,输入归一化。但是多层非线性变化后,中间层输入各维度数值差别可能很大。不同方向的敏感度不一样。有的方向更陡,容易震荡。
-
vanilla SGD最大的缺点是下降速度慢,而且可能会在沟壑的两边持续震荡,停留在一个局部最优
点
# sgd
w1.assign_sub(learning_rate * grads[0])
b1.assign_sub(learning_rate * grads[1])
1.3 SGDM——引入动量减少震荡
-
动量法是一种使梯度向量向相关方向加速变化,抑制震荡,最终实现加速收敛的方法。
-
为了抑制SGD的震荡,SGDM认为 梯度下降过程可以加入惯性。如果前后梯度方向相反,动量对冲,减少震荡。如果前后方向相同,步伐加大,加快学习速度。
-
SGDM全称是SGD with Momentum,在SGD基础上引入了一阶动量:
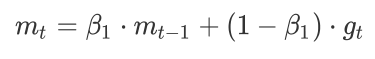
-
一阶动量是各个时刻梯度方向的指数移动平均值,约等于最近 1 / ( 1 − β 1 ) 1/(1-\beta _{1}) 1/(1−β1)个时刻的梯度向量和的平均值。(指数移动平均值大约是过去一段时间的平均值,反映“局部的”参数信息 ) 。 β 1 )。\beta _{1} )。β1的经验值为0.9。所以t 时刻的下降方向主要偏向此前累积的下降方向,并略微偏向当前时刻的下降方向。

老师书上写 W t + 1 = W t − v t = W t − ( α v t − 1 + ε g t ) W_{t+1}=W_{t}-v_{t}=W_{t}-(\alpha v_{t-1}+\varepsilon g_{t}) Wt+1=Wt−vt=Wt−(αvt−1+εgt)
α 、 ε \alpha、\varepsilon α、ε是超参数。 -
SGDM问题1:时刻t的主要下降方向是由累积动量决定的,自己的梯度方向说了也不算。
-
SGD/SGDM 问题2:会被困在一个局部最优点里
-
SGDM 问题3:如果梯度连续多次迭代都是一个方向,剃度一直增大,最后造成梯度爆炸
# sgd-momentun
beta = 0.9
m_w = beta * m_w + (1 - beta) * grads[0]
m_b = beta * m_b + (1 - beta) * grads[1]
w1.assign_sub(learning_rate * m_w)
b1.assign_sub(learning_rate * m_b)
1.4 SGD with Nesterov Acceleration
- SGDM:主要看当前梯度方向。计算当前loss对w梯度,再根据历史梯度计算一阶动量 m t m_{t} mt
- NAG:主要看动量累积之后的梯度方向。 计算参数在累积动量之后的更新值,并计算此时梯度,再将这个梯度带入计算一阶动量 m t m_{t} mt
- 主要差别在于是否先对w减去累积动量
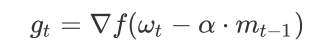
思路如下图:

首先,按照原来的更新方向更新一步(棕色线),然后计算该新位置的梯度方向(红色线),然后
用这个梯度方向修正最终的更新方向(绿色线)。上图中描述了两步的更新示意图,其中蓝色线是标准momentum更新路径。
1.5 AdaGrad——累积全部梯度,自适应学习率
- SGD:对所有的参数使用统一的、固定的学习率
- AdaGrad:自适应学习率。对于频繁更新的参数,不希望被单个样本影响太大,我们给它们很小的学习率;对于偶尔出现的参数,希望能多得到一些信息,我们给它较大的学习率。
- 另一个解释是:初始时刻W离最优点远,学习率需要设置的大一些。随着学习你的进行,离最优点越近,学习率需要不断减小。
- 引入二阶动量——该维度上,所有梯度值的平方和(梯度按位相乘后求和),来度量参数更新频率,用以对学习率进行缩放。(频繁更新的参数、越到学习后期参数也被更新的越多,二阶动量都越大,学习率越小)
V t = ∑ τ = 1 t g τ 2 V_{t}=\sum_{\tau =1}^{t}g_{\tau }^{2} Vt=τ=1∑tgτ2
η t = l r ⋅ m t / V t = l r ⋅ g t / ∑ τ = 1 t g τ 2 \eta _{t}=lr\cdot m_{t}/\sqrt{V_{t}}=lr\cdot g_{t}/\sqrt{\sum_{\tau =1}^{t}g_{\tau }^{2}} ηt<
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 102
102











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









