







1.1 元素的基本概念
- 元素: 由标签头+标签尾+标签头和标签尾包括的文本内容
- 元素的信息:元素的标签名以及元素的属性
- 元素的层级结构:元素之间相互嵌套的层级结构
- 元素定位:通过元素的信息或者元素的层级结构来进行元素定位。

1.2 浏览器开发者工具
-
- 1.点击 浏览器开发者工具左上角的 元素查看器按钮
- 2.点击需要查看的元素
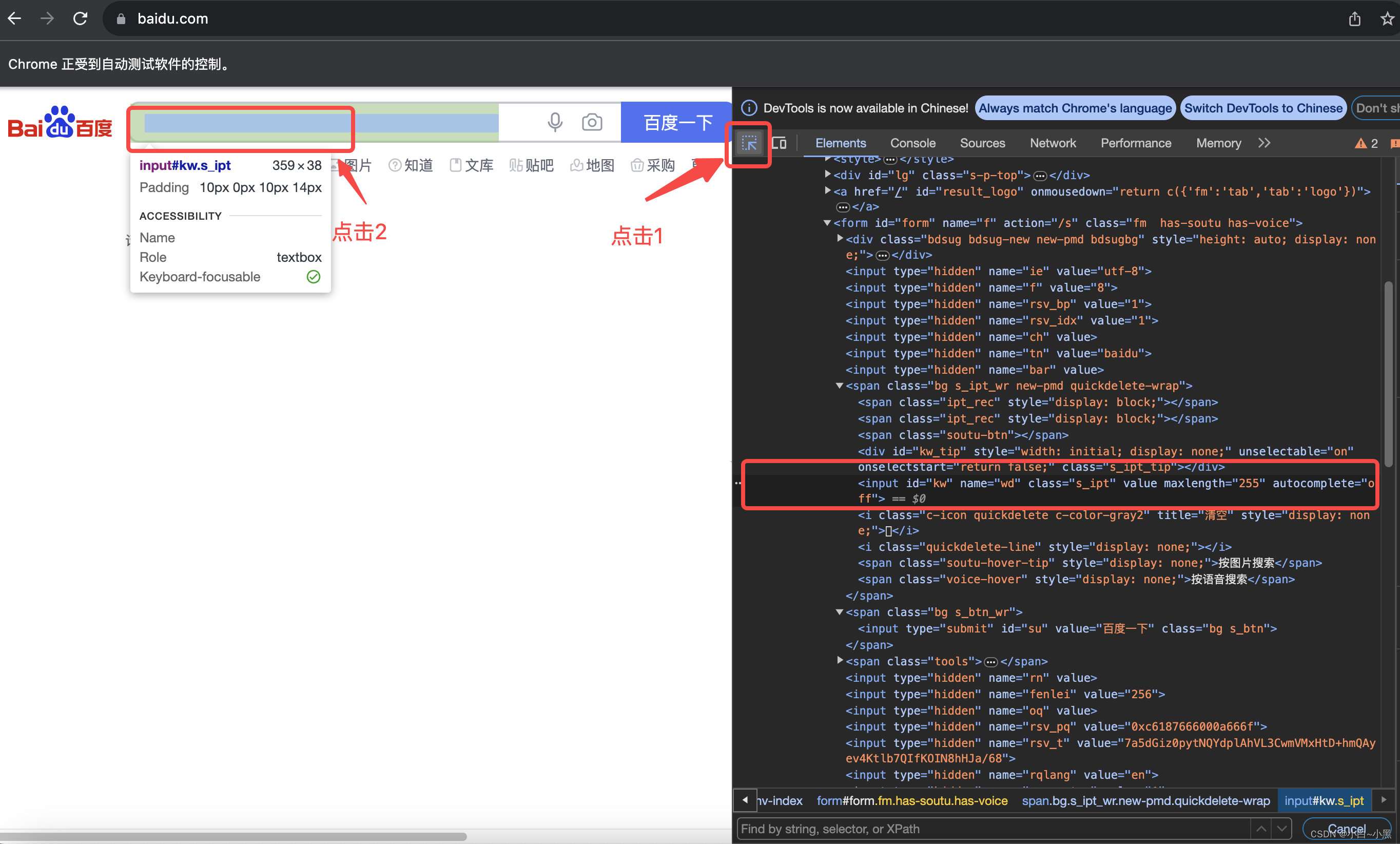
1.3 web元素定位的常用方式
- 通过ID进行定位:
-
- 使用元素的 ID 属性进行定位
- 通过name进行定位:
-
- 使用元素的name属性进行定位
- 通过class_name进行定位:
-
- 使用元素的类属性进行定位
- 通过tag_name进行定位:
-
- 使用元素的标签信息进行定位
- link_text定位:
-
- 通过超链接的全部文本信息进行元素定位
- partail_link_text定位:
-
- 通过超链接的局部文本信息进行元素定位
- 在页面当中,有一些元素无法通过元素的信息精准的定位到,所以需要借助于Xpath或CSS进行定位
-
- XPath定位:XPath 是一种用于在 XML 或 HTML 文档中定位元素的语言。它可以使用路径表达式来定位特定元素。例如,"/html/body/a"可以定位到 HTML 文档中 body 标签下的第一个 a 标签。
- CSS定位:CSS(Cascading Style Sheets)是一种用于描述网页样式的语言。它的主要作用是分离网页的内容和样式,使得网页开发者可以更方便地维护和更新网页样式。使用CSS可以帮助用户准确的定位到特定元素。
1.3.1 通过ID进行定位
- 元素有ID属性,可以通过元素的ID属性值来进行元素定位【遵循html标准规范的代码 ID值是唯一的】
- 定位方法: find_element_by_id(id) # 括号中 id 参数表示的是id的属性值
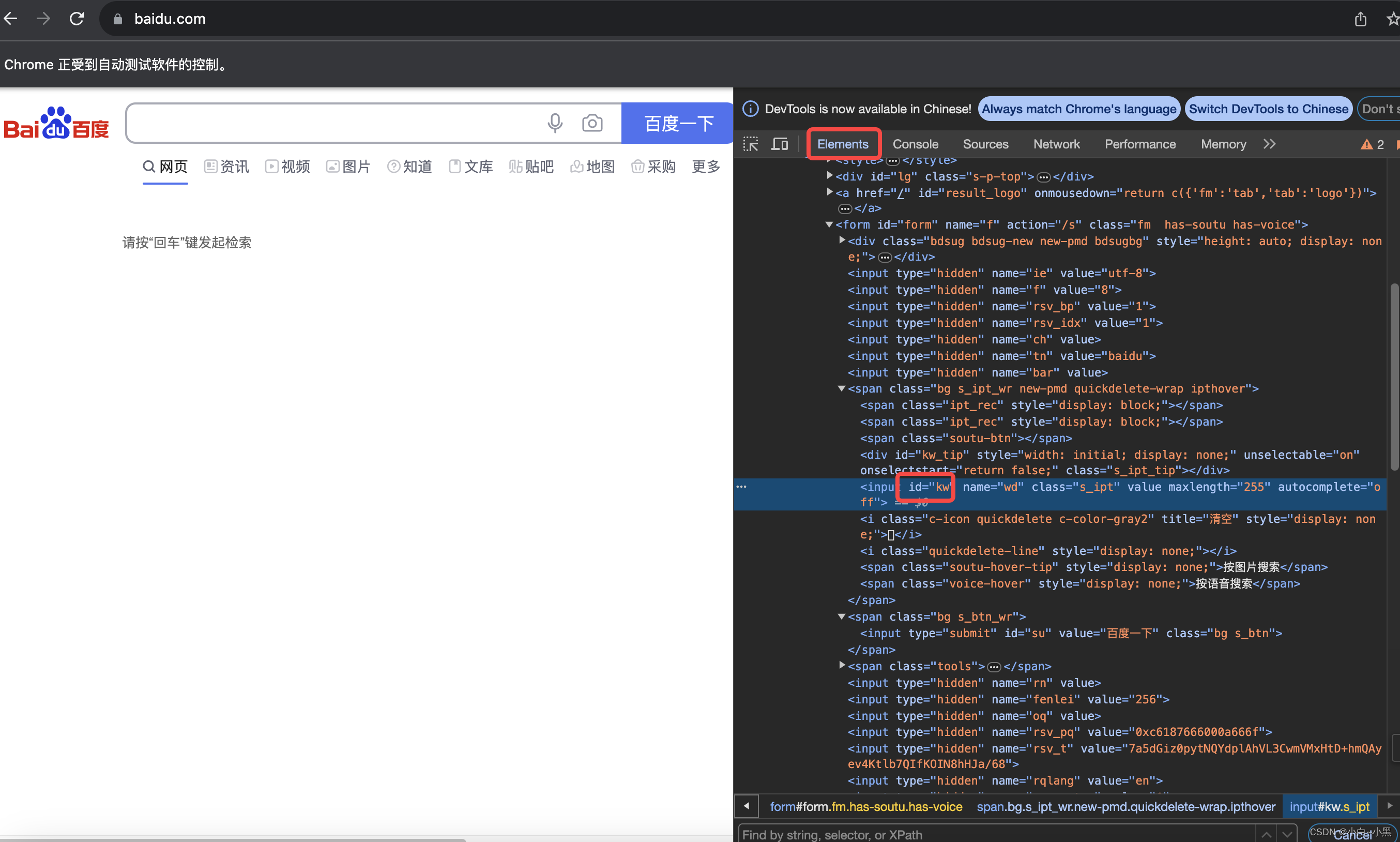
代码示例(by_id):
# 导包
import time
from selenium import webdriver
# 创建浏览器驱动对象
driver = webdriver.Chrome()
# 打开百度网站
driver.get("http://www.baidu.com")
# 通过ID定位到百度输入框并在输入框中输入"百度一下"
driver.find_element_by_id("kw").send_keys("百度一下")
# 等待3s
time.sleep(3)
# 退出浏览器
driver.quit()1.3.2 通过name进行定位
- 元素有name属性 可以通过元素的name属性值进行元素定位 【 在HTML页面中,name属性值是可以重复的。】
- 定位方法: find_element_by_name(name) # 括号中 name 参数表示的是name的属性值
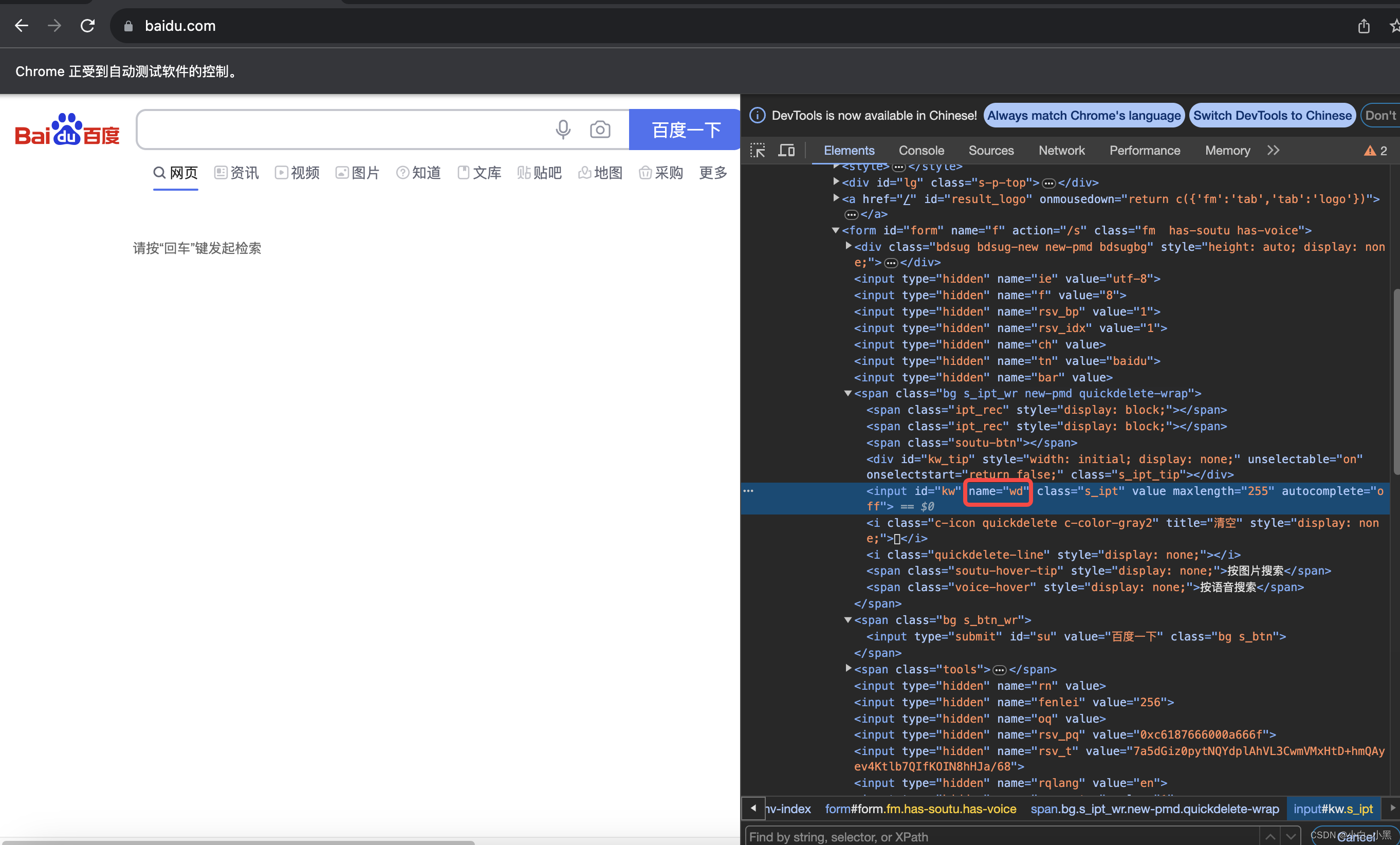
代码示例(by_name):
# 导包
import time
from selenium import webdriver
# 创建浏览器驱动对象
driver = webdriver.Chrome()
# 打开百度网站
driver.get("http://www.baidu.com")
# 通过name定位到百度输入框并在输入框中输入"这是通过name定位进行的输入"
driver.find_element_by_name("wd").send_keys("这是通过name定位进行的输入")
# 等待3s
time.sleep(3)
# 退出浏览器
driver.quit()1.3.3 通过class_name进行定位
- 元素有class属性 可以通过元素的class属性值进行元素定位 【 class属性值是可重复的】
- 定位方法: find_element_by_class_name(class_name) # 括号中 class_name 参数表示的是class的其中一个属性值
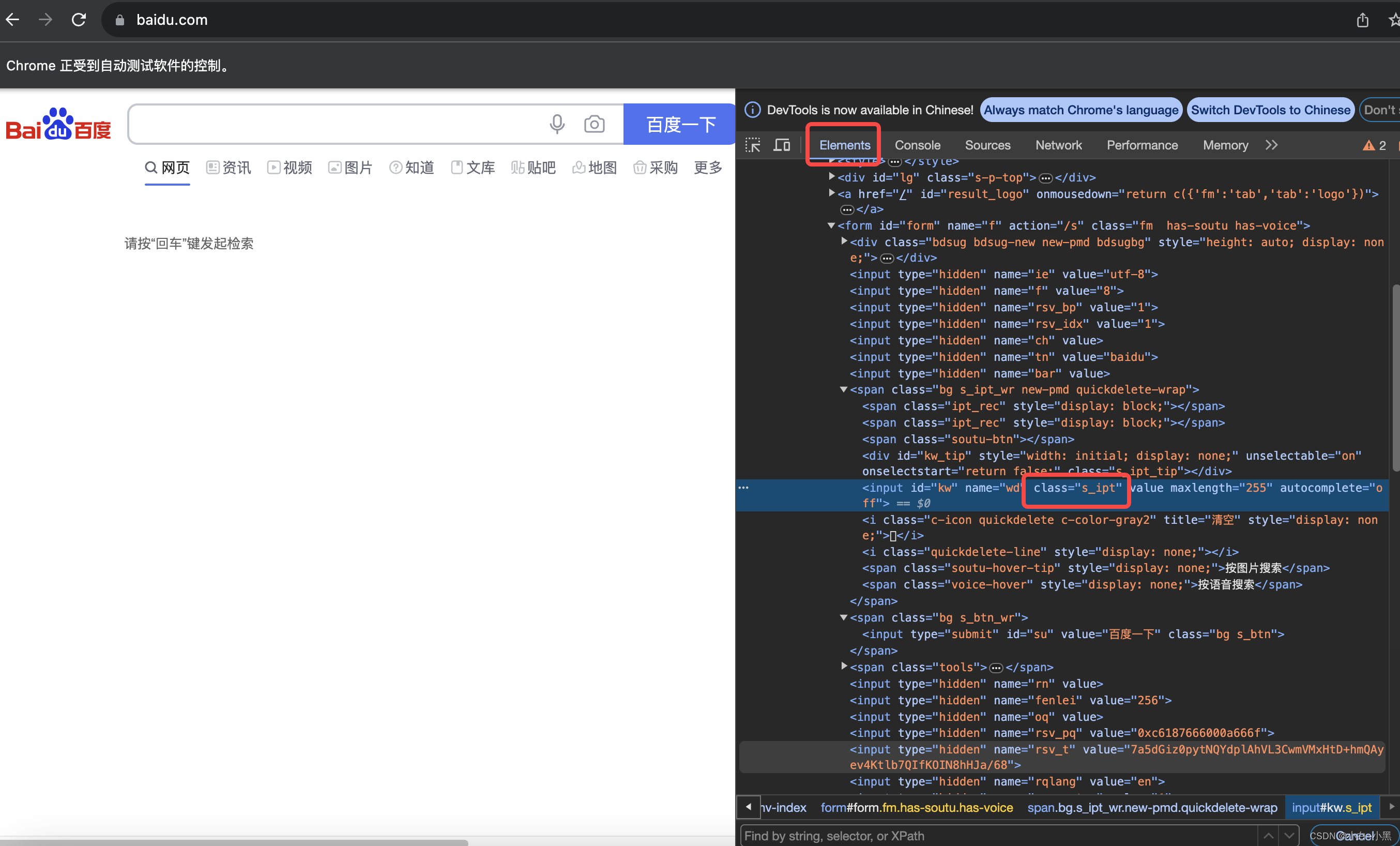
代码示例(by_class_name):
# 导包
import time
from selenium import webdriver
# 创建浏览器驱动对象
driver = webdriver.Chrome()
# 打开百度网站
driver.get("http://www.baidu.com")
# 通过class_name定位到百度输入框并在输入框中输入"这是通过class_name定位进行的输入"
driver.find_element_by_class_name("s_ipt").send_keys("这是通过class_name定位进行的输入")
# 等待3s
time.sleep(3)
# 退出浏览器
driver.quit()1.3.4 通过tag_name进行定位
- 在同一个html页面当中,相同标签元素会有很多。
- 定位方法: find_element_by_tag_name(tag_name) # 括号中 tag_name 表示的是元素的标签名称。
如果有重复的元素,定位到的默认是第一个元素 - 实际工作中一般需要结合定位一组元素的方法,通过下标来选中目标元素
- 一组元素定位方法:
-
- find_elements_by_id(id) 注意elements有s
find_elements_by_tag_name(tag_name) 注意elements有s - 定位一组元素返回的值是一个列表,可以通过下标来使用列表中的元素,下标是从0开始。
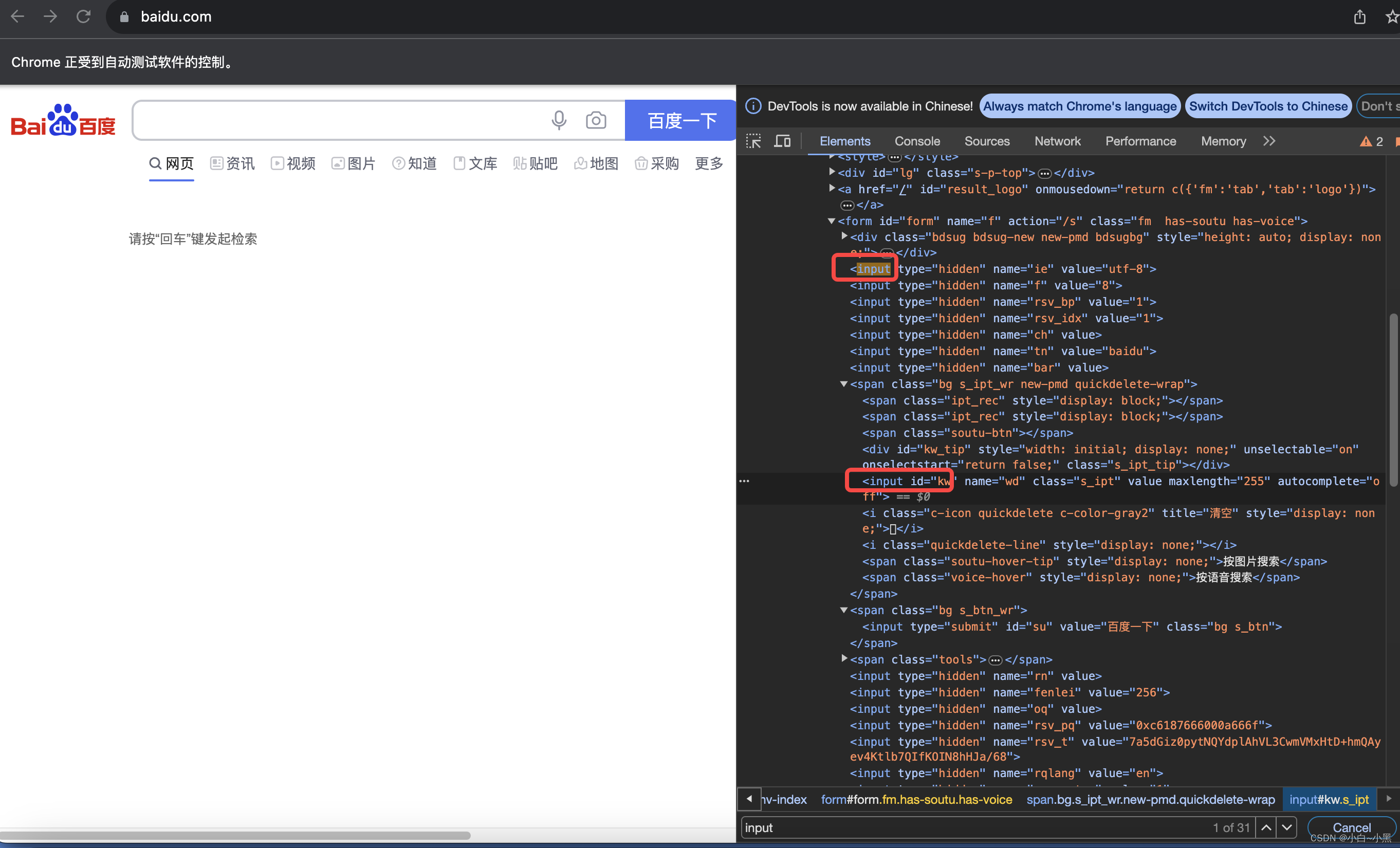
- find_elements_by_id(id) 注意elements有s
代码示例(by_tage_name)
# 导包
import time
from selenium import webdriver
# 创建浏览器驱动对象
driver = webdriver.Chrome()
# 打开百度网站
driver.get("http://www.baidu.com")
# 通过tag_name定位输入框(第8个input标签)
elements = driver.find_elements_by_tag_name("input")
elements[7].send_keys("这是定位一组元素的方法")
# 等待3s
time.sleep(3)
# 退出浏览器
driver.quit()1.3.5通过link_text进行定位
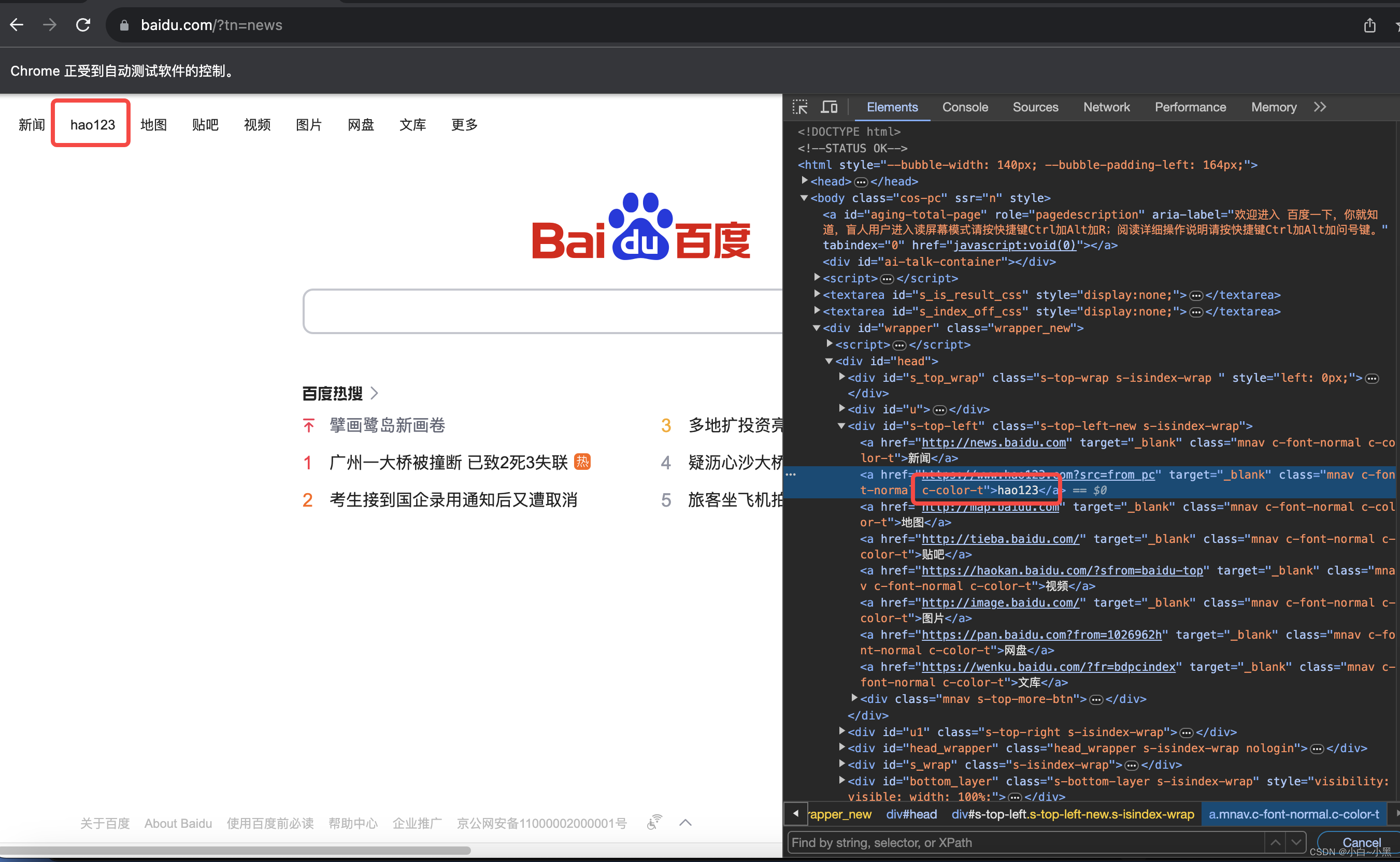
- 主要用来定位a标签,通过超链接的全部文本信息进行元素定位
- 定位方法: find_element_by_link_text(link_text) # 括号中 link_text 参数代表的是a标签的全部文本内容。
代码示例(by_link_text)
# 导包
import time
from selenium import webdriver
# 创建浏览器驱动对象
driver = webdriver.Chrome()
# 打开百度网站
driver.get("http://www.baidu.com")
# 通过partial_link_text定位到"hao123"网站并点击
driver.find_element_by_link_text("hao123").click()
# 等待3s
time.sleep(3)
# 退出浏览器驱动(释放系统资源)
driver.quit()1.3.6 通过partial_link_text进行定位
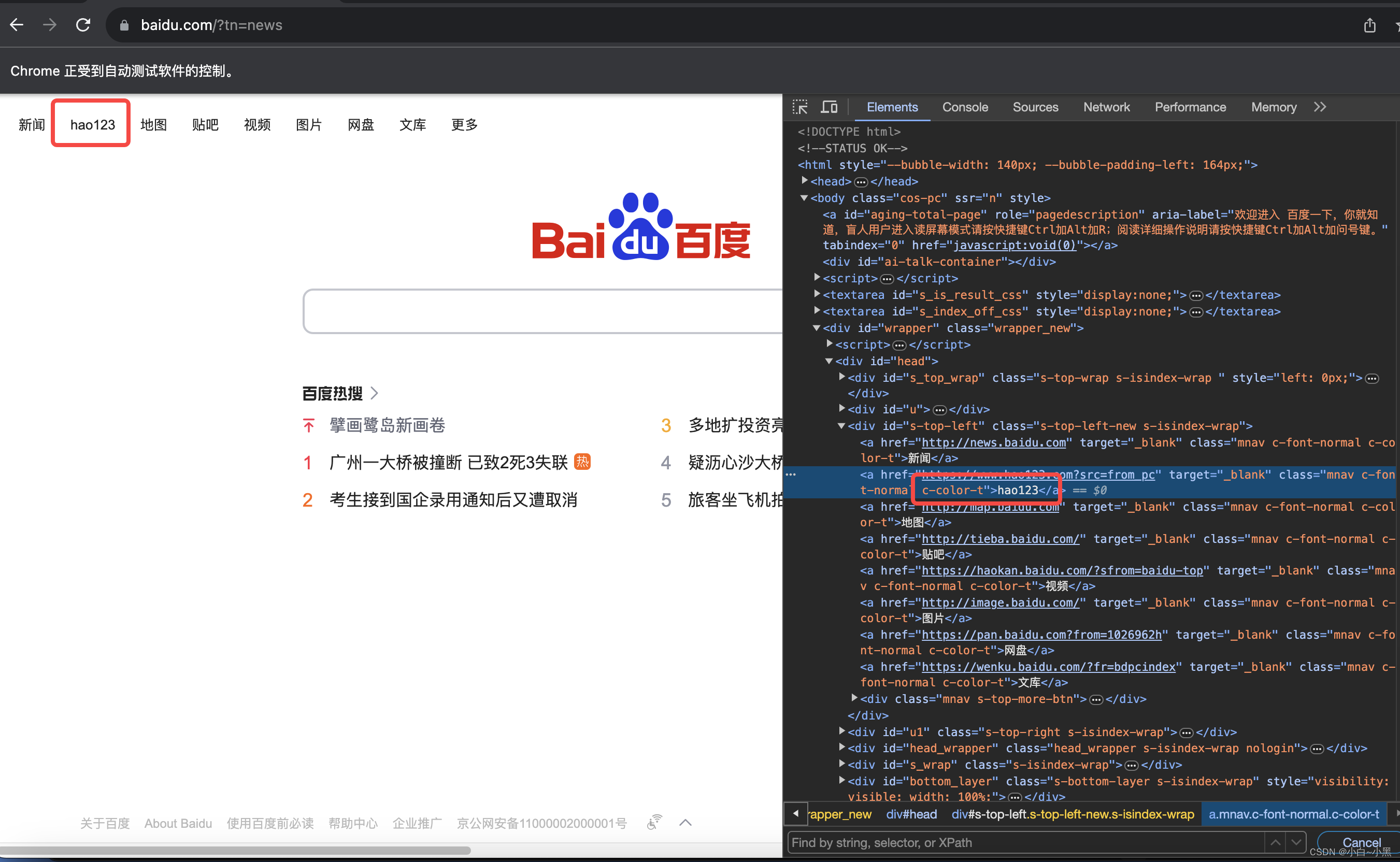
- 主要用来定位a标签,通过超链接的局部文本信息进行元素定位
- 定位方法:find_element_by_partial_link_text(partial_link_text) # 括号中 partial_link_text表示的是a标签 的局部文本内容
代码示例(partial_link_text)
# 导包
import time
from selenium import webdriver
# 创建浏览器驱动对象
driver = webdriver.Chrome()
# 打开百度网站
driver.get("http://www.baidu.com")
# 通过partial_link_text定位到"hao123"网站并点击
driver.find_element_by_partial_link_text("123").click()
# 等待3s
time.sleep(3)
# 退出浏览器驱动(释放系统资源)
driver.quit()未完待续……















 2854
2854











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









