






正如我们在之前的概述中所看到的,神经辐射场(NeRFs) [4]的提出是神经场景表示领域的突破。给定底层场景的一些图像,我们可以训练 NeRF 以高分辨率生成该场景的任意视点。简而言之,NeRF 利用深度学习提供 3D 场景的逼真渲染。
但是,他们有一些值得注意的问题。在本概述中,我们将特别关注 NeRF 的两个局限性:
- 训练能够准确渲染新视点的 NeRF 需要许多底层场景的图像。
- 使用 NeRF 执行训练(和渲染)速度很慢。
作为这些问题的解决方案,我们将概述 NeRF 方法的两个值得注意的扩展:PixelNeRF [1] 和 InstantNGP [2]。在学习这些方法的过程中,我们将看到 NeRF 面临的大多数问题都可以通过制作更高质量的输入数据并利用深度神经网络的能力将学习模式推广到新场景来解决。

(来自 [1, 2])
背景
我们最近了解了许多通过深度学习对 3D 形状和场景进行建模的不同方法。这些概述包含几个背景概念,这些概念也有助于理解本概述中的概念:
- 代表3D形状
- 前馈神经网络
- 位置嵌入
- 有符号距离函数
- 3D 数据如何表示
除了这些概念之外,在本概述中对 NeRF 有一个有效的理解也是非常有用的 [4]。为了建立这种理解,我建议阅读我对 NeRF 的概述。
代表 3D 形状 representing 3D shapes
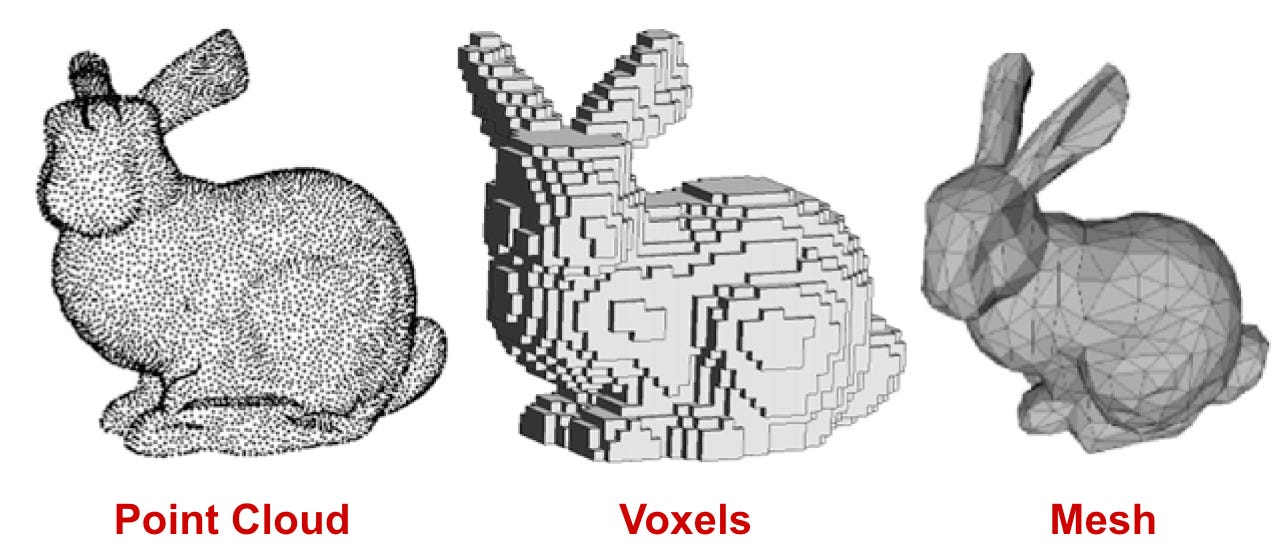
当考虑如何在计算机中存储 3D 形状时,我们有三种选择:点云、网格或体素。这些表示方法各有不同的优点和局限性,但它们都是直接表示 3D 形状的有效方法。让我们了解一下它们的工作原理。
点云。point cloud.
点云非常容易理解。从名字上我们可以推断出,它们只是存储了一组具有 [x, y, z]空间坐标的点,这些点用于表示底层的几何图形;见下文。
((来源source))
点云很有用,因为它们与我们从激光雷达或深度感应相机等传感器获得的数据类型非常匹配。但是,点云不提供防水watertight表面(即具有一个封闭表面的形状)。
网。mesh.
可以提供防水表面的一种 3D 表示是网格。网格是基于描述基础形状的顶点、边和面集合的 3D 形状表示。简而言之,网格只是多边形(例如三角形)的列表,当它们缝合在一起时,形成 3D 几何形状。
基于体素的表示。voxel-based representation. 体素只是具有体积的像素。我们在 3D 空间中拥有体素(即立方体),而不是 2D 图像中的像素。为了用体素表示 3D 形状,我们可以:
-
将 3D 空间的一部分划分为离散体素
-
识别每个体素是否被填充
使用这种简单的技术,我们可以构造一个基于体素的 3D 对象。为了获得更准确的表示,我们只需增加使用的体素数量,形成更精细的 3D 空间离散化。请参阅下面的点云、网格和体素之间差异的说明。
(来自[3])(from [3])
有符号距离函数signed distance functions
使用点云、网格或体素直接存储 3D 形状需要大量内存。相反,我们通常希望存储更有效的形状的间接表示。一种方法是使用有符号距离函数 (SDF)。
给定一个空间Given a spatial [x, y, z]点作为输入,SDF 将输出从该点到所表示的底层对象的最近表面的距离。SDF 输出的符号指示该空间点是在对象表面的内部(负)还是外部(正)。请参见下面的等式。
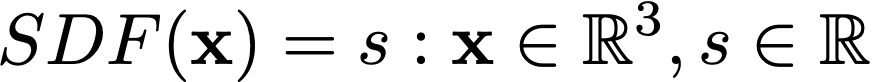
我们可以通过找到 SDF 等于 0 的位置来识别 3D 物体的表面,这表明给定点位于物体的边界处。使用 SDF 找到该表面后,我们可以使用 Marching Cubes等算法生成网格Marching Cubes。.
为什么这有用?在较高的层面上,SDF 允许我们存储函数而不是 3D 形状的直接表示。这个函数的存储效率可能更高,而且我们无论如何都可以使用来恢复网格表示!
前馈神经网络feed-forward neural networks
许多高精度 3D 形状建模方法都基于前馈网络架构。这种架构采用向量作为输入,并在网络的每个层中应用相同的两个变换:
-
线性变换Linear transformation
-
非线性激活函数Non-linear activation function
尽管我们输入的维度是固定的,但网络架构的两个方面可供我们自由选择:隐藏维度和层数。作为从业者,我们应该设置的这样的变量称为超参数。这些超参数的正确设置取决于我们试图解决的问题和/或应用程序。
代码。the code.前馈网络没有太多复杂性。我们可以在 PyTorch 中轻松实现它们,如下所示。
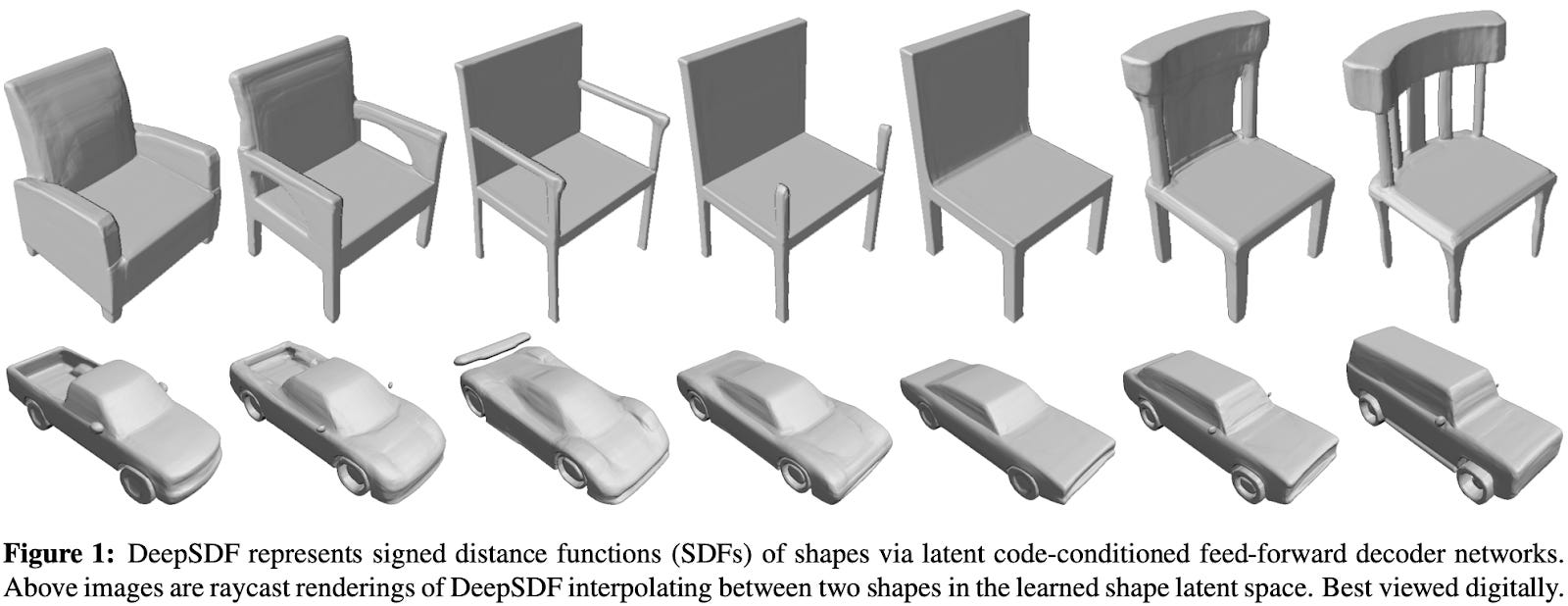
DeepSDF:学习形状表示的连续符号距离函数DeepSDF: Learning Continuous Signed Distance Functions for Shape Representation[1] [1]
(来自[1])(from [1])
计算机图形学和 3D 计算机视觉方面的先前研究提出了许多表示 3D 形状和几何形状的经典方法。在 [1] 中,作者提出了一种基于深度学习的方法,称为 DeepSDF,它使用神经网络来学习各种形状的连续 SDF。简而言之,这意味着我们可以使用单个前馈神经网络对多种不同类型的 3D 形状的基于 SDF 的表示进行编码,从而允许对这些形状进行表示、插值甚至从部分数据完成;往上看。
背后的想法很简单:我们希望使用神经网络直接对 SDF 的值执行回归。regression为此,我们在 SDF 的点样本(即 [x, y, z]具有相关 SDF 值的各个点)上训练该模型。如果我们以这种方式训练网络,那么我们可以轻松预测查询位置的 SDF 值,并通过找到 SDF 等于 0 的点来恢复形状的表面。
我们如何表示形状?更具体地说,考虑单个形状,我们从中采样固定数量的具有 SDF 值的 3D 点样本。我们在这里应该注意的是,获取更多的点样本将允许以更高精度表示形状,但这是以增加计算成本为代价的。
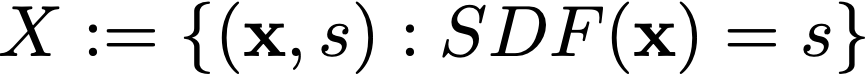
在上面的等式中, x是包含坐标的向量 [x, y, z] ,而s是与给定形状的这些坐标相关联的 SDF 值。
训练神经网络。training the neural network.从这里,我们可以直接训练前馈神经网络,通过使用 L1 回归损失对这些样本对进行训练来生成作为输入s给出的SDF 值。然后,生成的模型可以输出准确的 SDF 值来表示基础形状;请参见下面的左子图。
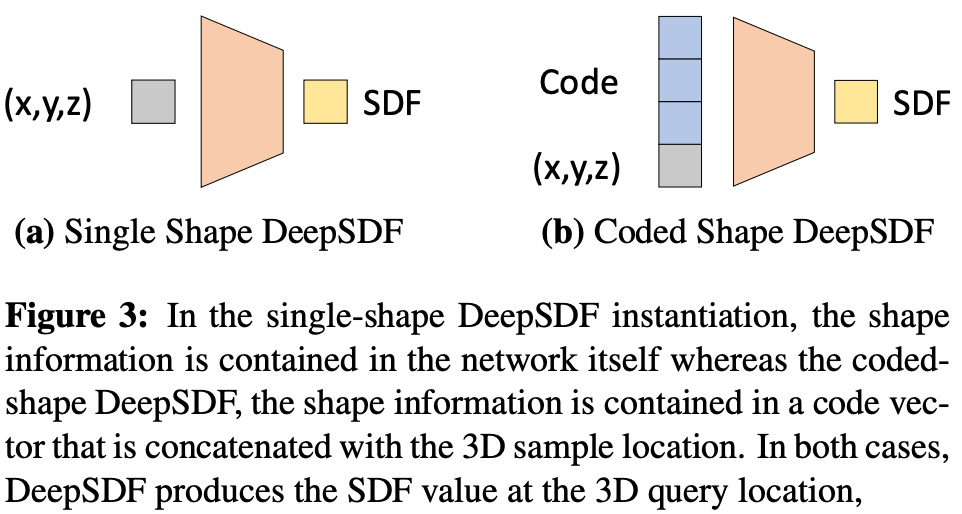
(来自[1])(from [1])
这种模型的局限性在于它仅代表单一形状。理想情况下,我们希望使用单个神经网络对各种形状进行建模。为了实现这一点,我们可以将一个潜在向量(即上图中的“代码”)与每个形状相关联。这是一个低维向量,对于存储在我们的神经网络中的每个形状来说都是唯一的。该潜在向量可以作为输入添加到神经网络中,以通知网络它正在为特定形状生成输出。这个简单的技巧允许我们在单个模型中表示多个形状(这可以节省大量内存!);参见上面的右子图。
我们可能要问的最后一个问题是:我们如何获得每个形状的潜在向量? 在[1]中,作者通过提出一种自动解码器架构来做到这一点,该架构(i)将潜在向量添加到模型的输入中,并且 (ii)在训练期间通过梯度下降学习每个形状的最佳潜在向量;见下文。
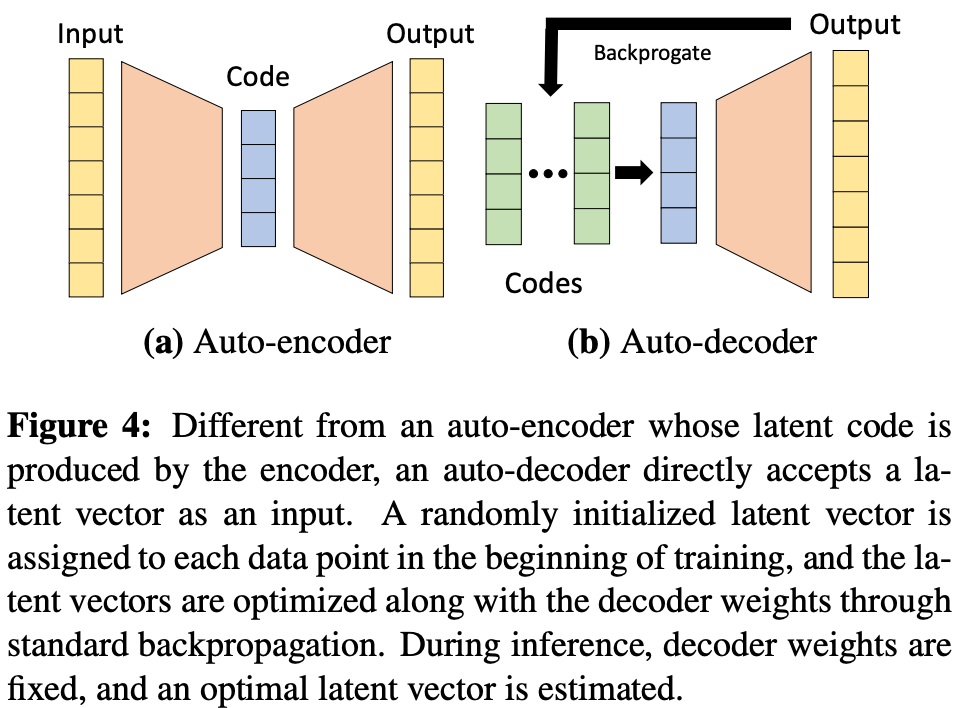
(来自[1])(from [1])
通常,潜在向量是通过自动编码器架构学习的autoencoder architecture,但这需要添加额外的编码器模块,从而产生额外的计算费用。[1] 中的作者提出了自动解码器方法来避免这种额外的计算。这些方法之间的差异如下所示。
产生一个形状。producing a shape.要使用 DeepSDF 进行推理,我们必须:
-
从一组稀疏/不完整的 SDF 值样本开始
-
从这些样本中确定最佳的潜在向量
-
使用我们训练有素的神经网络对 3D 空间中的一堆不同点进行推理,以确定 SDF 值
从这里,我们可以使用诸如Marching CubesMarching Cubes之类的算法来可视化 DeepSDF 表示的形状,这些算法可以离散化 3D 空间并根据这些 SDF 值提取实际的 3D 几何形状。
数据。the data. DeepSDF 使用合成DeepSDF is trained and evaluated using the synthetic ShapeNetShapeNet数据集进行训练和评估。特别是,它的性能是通过四项任务来衡量的。
-
表示训练集中的形状
-
重建看不见的(测试)形状
-
完成部分形状
-
从潜在空间中采样新形状
对于前三个任务,我们看到 DeepSDF 往往始终优于基线方法,这表明它可以高精度地表示复杂的形状,甚至可以很好地从不完整的样本中恢复形状。考虑到我们在单个内存高效的神经网络中存储大量 3D 形状,这是非常了不起的;见下文。
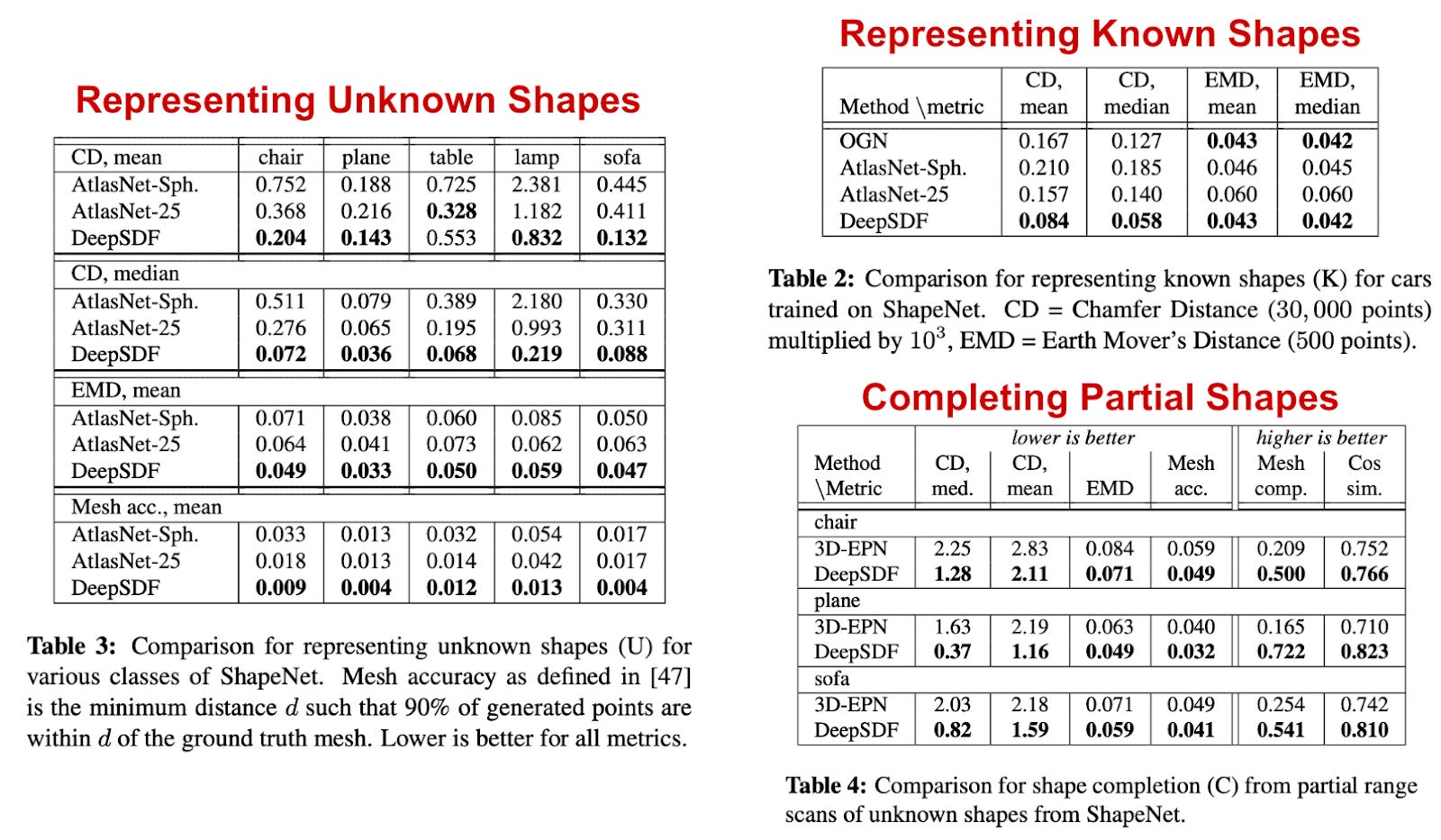
(来自[1])(from [1])
我们还可以对 DeepSDF 模型的嵌入空间进行插值以产生一致的结果。这使我们能够做一些事情,例如找到卡车和汽车之间的平均形状;见下文。

(来自[1])(from [1])
从这些结果中,我们可以看到,潜在向量之间的插值产生了形状之间的平滑过渡,这表明 DeepSDF 嵌入的连续 SDF 是有意义的!DeepSDF 利用的表示形式捕获了形状的常见特征(例如卡车床或椅子扶手)。对于这样一个简单的前馈网络来说,这是非常了不起的。
要点Takeaways
DeepSDF 是一种前馈生成神经网络,我们可以用它来表示和操纵 3D 形状。使用此模型,我们可以轻松执行诸如生成形状的网格表示、从不完整或嘈杂的数据中恢复基础形状,甚至生成作为已知几何形状的插值的新形状等任务。DeepSDF 的优点和局限性概述如下。
大量压缩。lots of compression.为了在计算机中存储 3D 几何图形,我们可以使用网格或体素表示。为了避免直接存储这样的形状的内存开销,我们可以使用像 DeepSDF 这样的生成模型。通过这种方法,我们不再需要几何体的直接网格编码。相反,我们可以使用 DeepSDF(一种易于存储的小型神经网络)来准确生成各种形状的网格。
修复损坏的几何体。fixing a broken geometry.给定底层形状的部分或噪声表示,DeepSDF 可用于恢复精确的网格;见下文。相比之下,大多数现有方法无法执行此类任务 - 它们需要访问与用于训练模型的数据类型相匹配的完整 3D 形状表示。

(来自[1])(from [1])
插入潜在空间。interpolating the latent space. 深度 SDF 可以表示许多不同的形状,并将它们的属性嵌入到低维潜在空间中。另外,实验表明这个潜在空间是有意义的并且具有良好的覆盖范围。实际上,这意味着我们可以采用潜在向量(即不同对象的向量表示),在它们之间进行线性插值linearly interpolate,并产生有效的新颖形状。我们可以轻松地使用它来生成具有各种有趣属性的新形状。
限制。limitations.DeepSDF 很棒,但它总是需要访问(可能有噪声或不完整的)3D 几何体来运行推理。另外,搜索最佳可能的潜在向量(即,由于自动解码器方法,这必须始终在执行推理之前完成)在计算上是昂贵的。这样一来,DeepSDF的推理能力就受到了一定的限制。总而言之,该方法速度缓慢,并且无法从头开始生成新形状,这为未来的工作留下了改进的空间。















 9655
9655

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









