






 文章探讨了机器学习中如何对数据进行编码,如one-hot编码和位置编码,以及NeRF架构中如何使用位置编码来改善渲染。InstantNGP引入了多分辨率哈希编码,显著加快了NeRF的训练速度,同时指出仍有改进空间,如寻找更好的编码方案和平衡速度与质量的关系。
文章探讨了机器学习中如何对数据进行编码,如one-hot编码和位置编码,以及NeRF架构中如何使用位置编码来改善渲染。InstantNGP引入了多分辨率哈希编码,显著加快了NeRF的训练速度,同时指出仍有改进空间,如寻找更好的编码方案和平衡速度与质量的关系。
输入编码Input Encodings
有时,我们不想将数据直接输入到机器学习模型中,因此我们会传递该数据的编码版本作为输入。这是机器学习中的一个基本概念。例如,考虑一下分类变量的one-hot 编码。one-hot encodings一个更复杂的例子是 核函数,或者我们在将数据传递kernel functions给模型之前传递数据的函数(即,可能使其线性可分)。linearly separable在每种情况下,我们都会对输入进行编码/转换,使其采用更适合模型的格式。
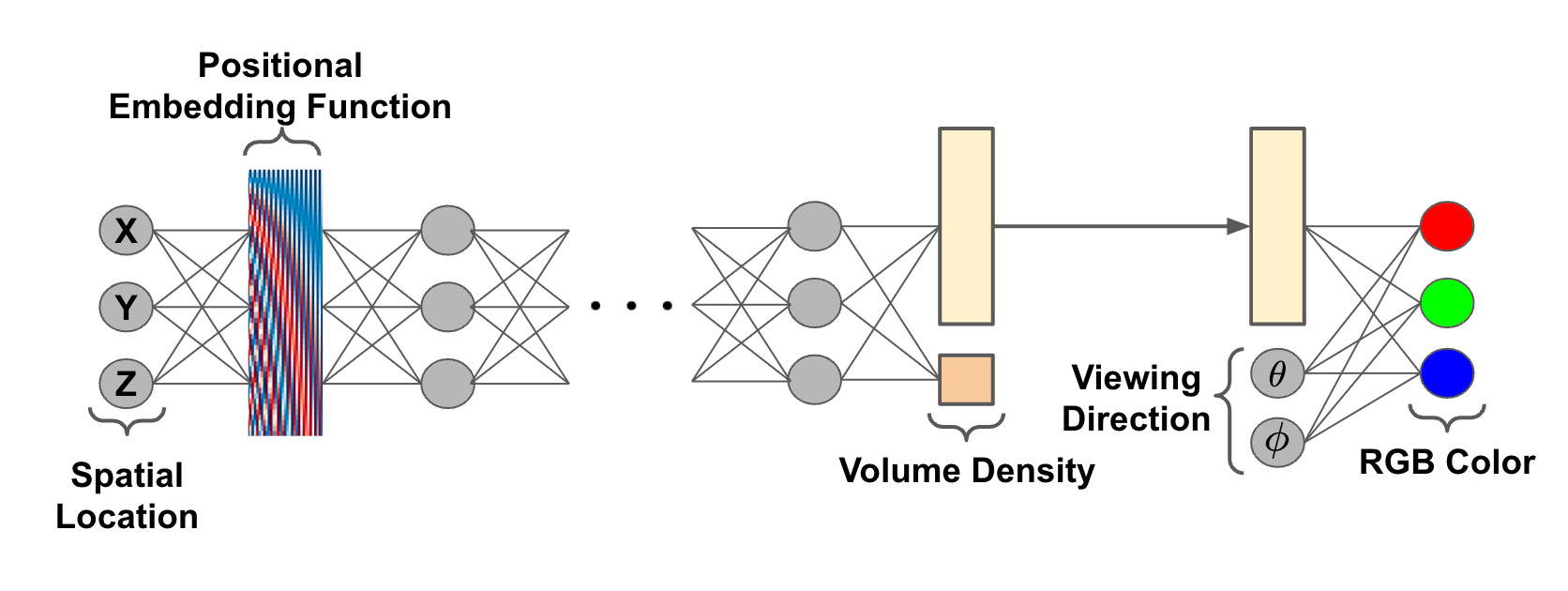
NeRF 架构中的位置编码。Positional encoding in the NeRF architecture.
位置编码。positional encodings.同样,当我们将 3D 坐标作为输入传递给 NeRF 的前馈网络时,我们不想直接使用这些坐标作为输入。相反,我们使用位置编码方案将它们转换为更高维的向量;往上看。这种位置编码方案与用于将位置信息添加到转换器内的标记化输入的技术完全相同[6]。在 NeRF 中,位置编码已被证明可以显着改善场景渲染。
可学习的嵌入层。learnable embedding layers.位置编码方案有一个问题—— —它们是固定的。如果我们想学习这些编码怎么办?实现此目的的一种方法是构造一个 嵌入矩阵embedding matrix。给定一个将每个空间位置映射到该矩阵中的索引的函数,我们可以检索每个空间位置的相应嵌入并将其用作输入。然后,这些嵌入可以像正常模型参数一样进行训练!
哈希编码
具有多分辨率哈希编码的即时神经图形基元Instant Neural Graphics Primitives with a Multiresolution Hash Encoding

(来自[2])(from [2])
PixelNeRF [1] 允许我们从底层场景的少量图像中恢复场景表示。但是,请记住 NeRF 的训练过程也很慢(即,PixelNeRF [1] 在单个 GPU 上需要2 天)!2 days考虑到这一点,我们可能会问自己: 我们训练 NeRF 的速度能快多少?h[2]中的即时神经图形基元(InstantNGP)的提议向我们展示了我们可以更快地训练。
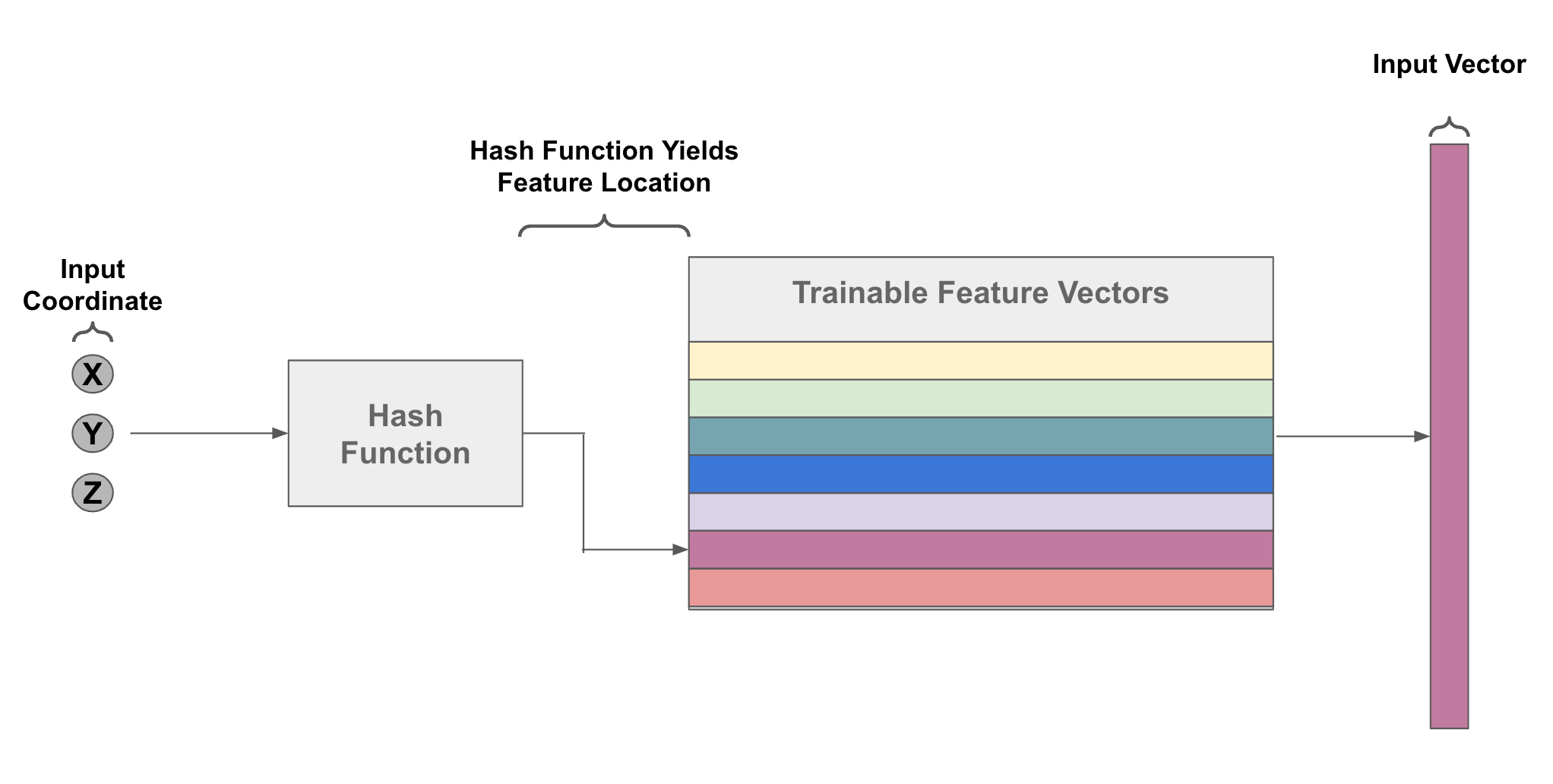
使用哈希函数对简单的特征嵌入矩阵进行索引。
InstantNGP 的方法与 NeRF [4] 类似,唯一的区别在于我们如何构建前馈网络的输入。我们不使用位置编码方案,而是构建一个多分辨率哈希表,将每个输入坐标映射到可训练的特征向量;往上看。这种方法(i)为 NeRF 添加了更多可学习的参数,(ii)为每个输入坐标生成丰富的输入表示,从而使前馈网络变得更小。总体而言,这种方法可以显着加速 NeRF 训练过程。
方法。method. 构建和查询输入特征哈希表的实际方法(不幸的是)比上面描述的简单图更复杂。让我们进一步探讨一下 InstantNGP [2] 如何准确处理输入特征。
InstantNGP 采用参数化方法对输入进行编码。与使用位置嵌入函数将坐标映射到固定的高维输入的 NeRF 不同,InstantNGP在训练期间学习 learns输入特征。在较高层面上,这是通过以下方式完成的:
-
将输入特征存储在嵌入矩阵中。
-
根据输入坐标对嵌入矩阵进行索引。
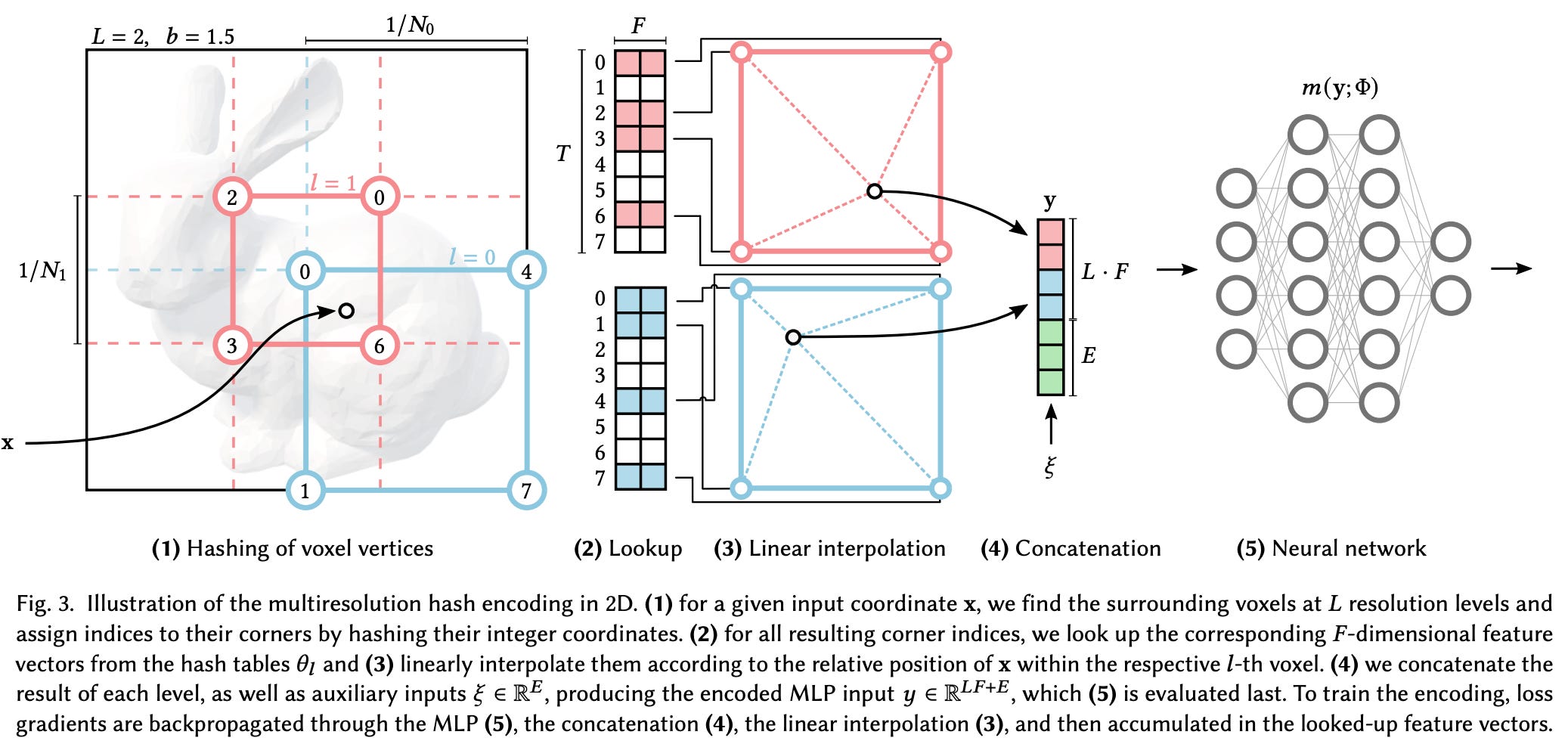
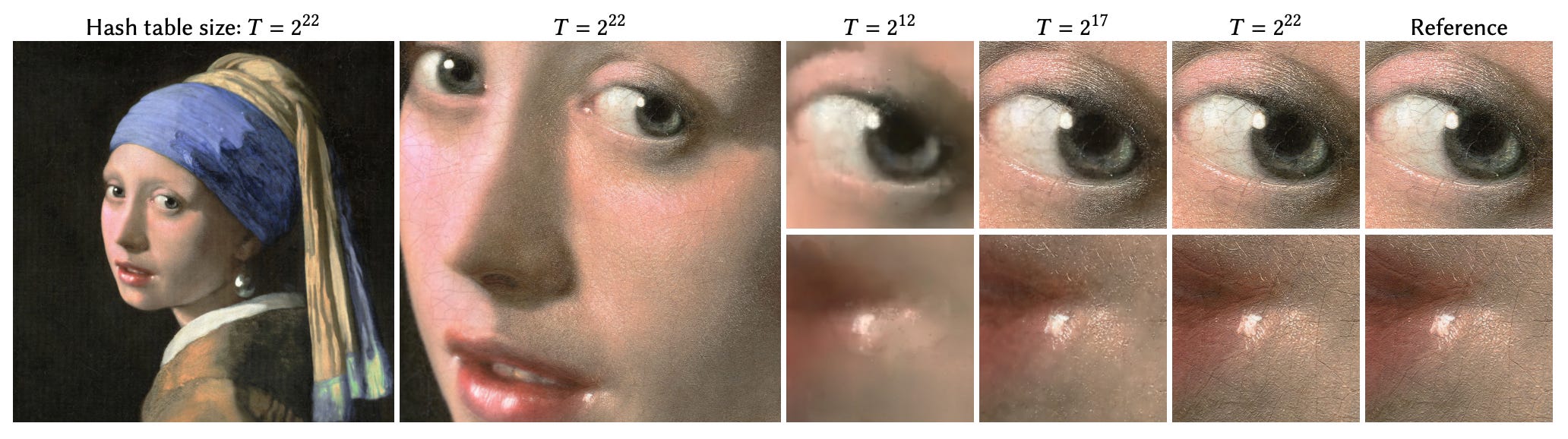
让我们一一讨论这些组件。首先,我们需要创建可以索引的可学习输入特征表。在[2]中,输入特征存储在包含特征级别(即不同的嵌入矩阵)的多分辨率表中。表的每个级别都有 T维度的特征向量 F(即大小为 的矩阵 T x F)。通常,这些参数遵循如下所示的设置。)

(来自[2])(from [2])
每个级别都旨在以不同的分辨率(从(最低分辨率)到 (最高分辨率))表示 3D 空间。我们可以将其视为将 3D 空间划分为 不同粒度级别的体素网格(例如,voxel grids将使用非常大/粗糙的体素)。通过以这种方式划分 3D 空间,我们可以确定输入坐标所在的体素 - 这对于每个分辨率级别都是不同的。然后使用坐标所在的体素将该坐标映射到每个级别的嵌入矩阵中的条目。
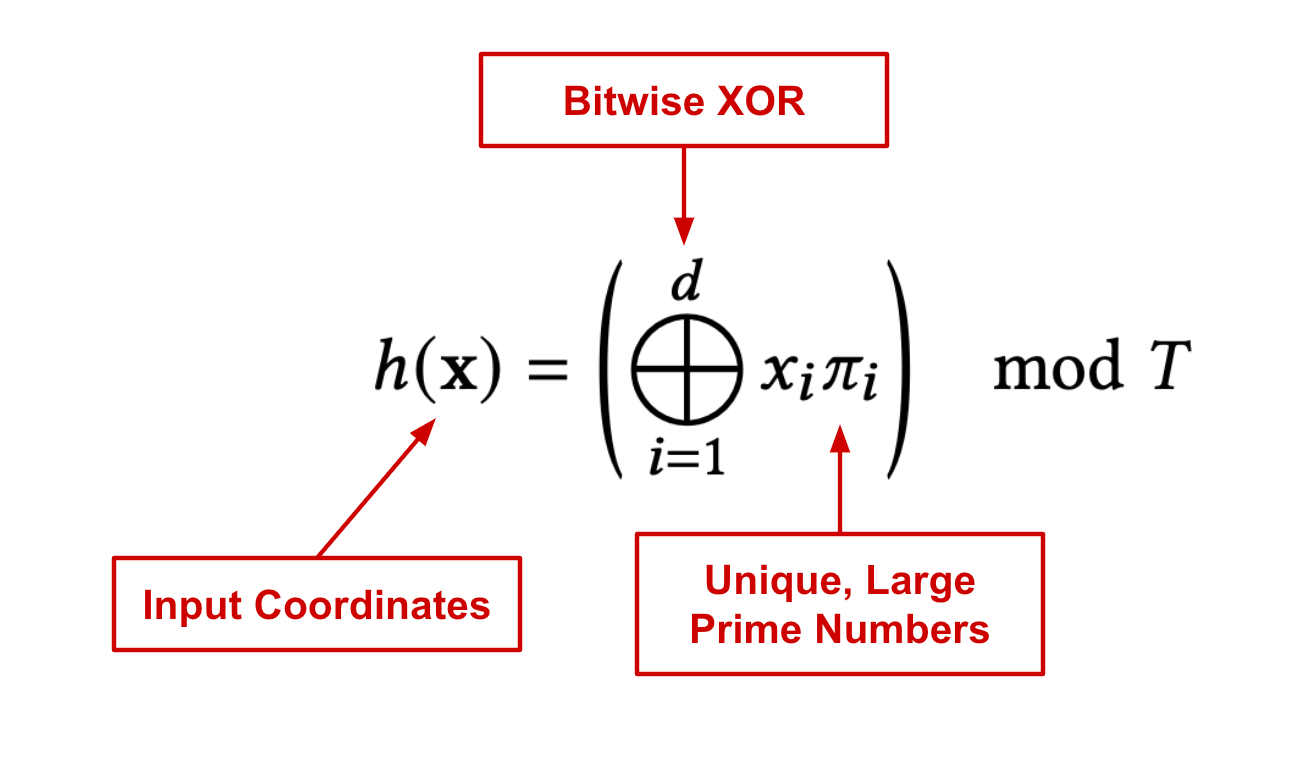
(来自[2])(from [2])
更具体地说,[2] 中的作者使用上面所示的哈希函数将体素位置(即,由体素边缘的坐标给出)映射到每个分辨率级别的嵌入矩阵中的条目的索引。值得注意的是,具有较粗分辨率(即较大的体素)的级别将具有较少的哈希冲突,这意味着完全不同位置的输入坐标不太可能映射到相同的特征向量。
(来自[2])(from [2])
当我们在每个分辨率级别检索相应的特征向量后,我们就有了与单个输入坐标相对应的多个特征向量。为了组合这些向量,我们对它们进行线性插值,其中插值的权重是使用每个级别的体素内输入坐标的相对位置导出的。从这里,我们将这些向量与其他输入信息(例如,位置编码的观看方向)连接起来以形成最终输入!InstantNGP 中完整的多分辨率方法如上图所示。

(来自[2])(from [2])
由于使用更高质量、可学习的输入特征,InstantNGP 能够使用相对于 NeRF 更小的前馈网络,同时在质量方面取得相似的结果;往上看。当这些修改与更高效的实现相结合时(即,最大限度地减少带宽和浪费的操作的完全融合的 cuda 内核),NeRF 的训练时间可以大大减少。事实上, 我们可以使用 InstantNGP 在几秒钟内获得高质量的场景表示。
结果。results. 除了修改后的输入编码方案和更小的前馈神经网络之外,InstantNGP 使用与[4]中提出的几乎相同的设置来训练 NeRF。坐标输入使用多分辨率哈希表进行编码,而观看方向使用正常的位置嵌入进行编码。
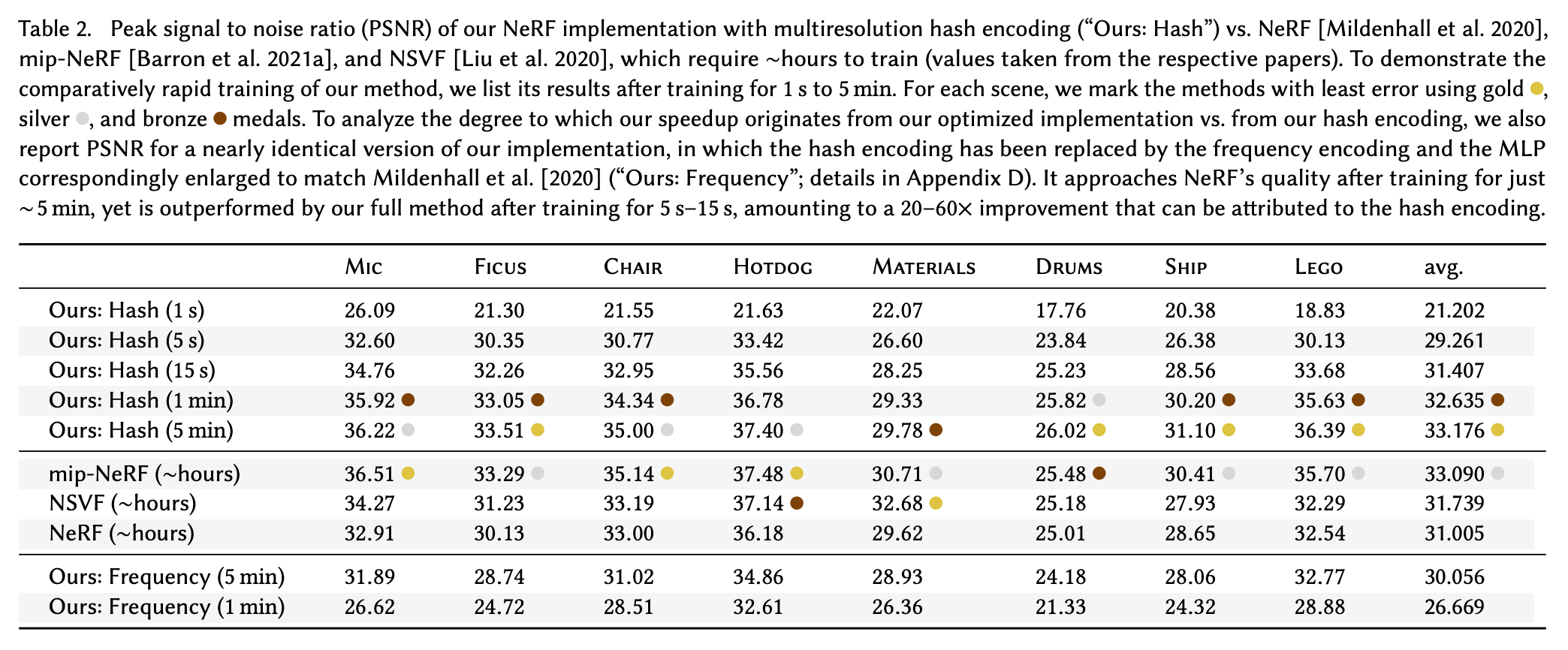
(来自[2])(from [2])
使用所提出的方法和更快的渲染过程,[2] 中的作者发现 InstantNGP 可以在几秒钟内训练场景表示,甚至以 60 FPS 渲染场景!相对于 NeRF,这是效率的巨大提升;往上看。 值得注意的是,InstantNGP只需 15 秒的训练就可以与 NeRF(需要数小时的训练)竞争!!
为了确定这种加速是来自更高效的 cuda 实现还是多分辨率哈希表,作者做了一些分析。他们发现,有效的实现确实提供了很大的加速,但单独使用哈希表和较小的前馈网络可以在训练 NeRF 时产生 20 倍到 60 倍的加速。
“我们用频率编码取代哈希编码,并扩大 MLP 以大致匹配 [NeRF] 的架构……我们的这个版本的算法在仅训练 ∼5 分钟后就接近 NeRF 的质量,但在训练 5 分钟后,其性能优于我们的完整方法。持续时间更短(5 秒到 15 秒),由于哈希编码和更小的 MLP,性能提升了 20 到 60 倍。”
在某些情况下,我们确实发现在包含复杂、依赖于视图的反射和非朗伯non-Lambertian效应的场景中,基线方法优于 InstantNGP 。作者声称这是由于[2]中使用了较小的前馈网络所致;见下文。
我们还能用这个做什么?what else can we use this for? 尽管我们专注于 NeRF 的改进,但 InstantNGP 的方法非常通用——它可以提高各种计算机图形基元(即表征外观的函数)的效率。例如,[2] 中显示 InstantNGP 在以下方面有效:
-
对有符号距离函数signed distance functions(SDF)进行建模 (SDFs)
要点Takeaways
尽管 NeRF 彻底改变了神经场景表示的质量,但我们在本概述中看到还有很大的改进空间!NeRF 仍然需要很长的时间来训练,并且需要大量的训练数据才能很好地工作。下面概述了我们如何缓解这些问题的一些基本要点。
提高样本复杂性。improving sample complexity. 在其原始形式中,NeRF 需要对底层场景进行许多输入观察来执行视图合成。这主要是因为 NeRF 是按场景单独训练的,从而防止任何先验信息被用于生成新视图。PixelNeRF [1] 通过添加预先训练的图像特征作为 NeRF 前馈网络的输入来缓解这个问题。这种方法允许利用从其他训练数据中学到的先验信息。因此,该方法只需少量图像作为输入就可以生成场景表示!
更高质量的输入会有很大帮助!higher-quality input goes a long way!正如 InstantNGP [2] 所示,NeRF 使用的输入编码方案非常重要。对输入使用更丰富、可学习的编码方案使我们能够减小前馈网络的大小,从而显着提高训练和渲染效率。在我看来,这样的发现可以启发很多未来的工作。我们能找到更好的编码方案吗?是否有其他类型的深度学习模型可以应用这个概念?
限制。limitations.我们在本概述中看到的方法在解决 NeRF 的已知局限性方面做了很多工作,但它们并不完美。InstantNGP 在 NeRF 训练时间上提供了令人难以置信的加速,但生成的场景表示的质量并不总是最好的。与基线相比,InstantNGP 很难捕获复杂的效果,例如反射,这表明我们为了更快的训练而牺牲了表示质量。
“一方面,我们的方法在具有高几何细节的场景上表现最佳......另一方面,mip-NeRF 和 NSVF 在具有复杂的、依赖于视图的反射的场景上优于我们的方法......我们将其归因于我们必然需要的更小的 MLP与这些竞争性的实施相比,我们可以将速度提高几个数量级。” “
此外,PixelNeRF [1](由于在其初始前馈组件中单独处理每个输入图像)的运行时间随着用作输入的视图数量线性增加。这种线性相关性可能会导致训练和渲染都非常慢。因此,我们可以用 NeRF 解决一些主要问题,但可能会付出一点代价!

















 1206
1206

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









