







目录
概要
本研究利用复杂的阿瓦隆游戏作为测试平台,探索大语言模型在欺骗性环境中的潜力。阿瓦隆充满了错误的信息,需要复杂的逻辑,表现为“思想游戏”。受到阿瓦隆游戏中人类递归思维和换位思考效率的启发,作者引入了一个新的框架,递归沉思(ReCon),以提高llm识别和抵制欺骗性信息的能力。
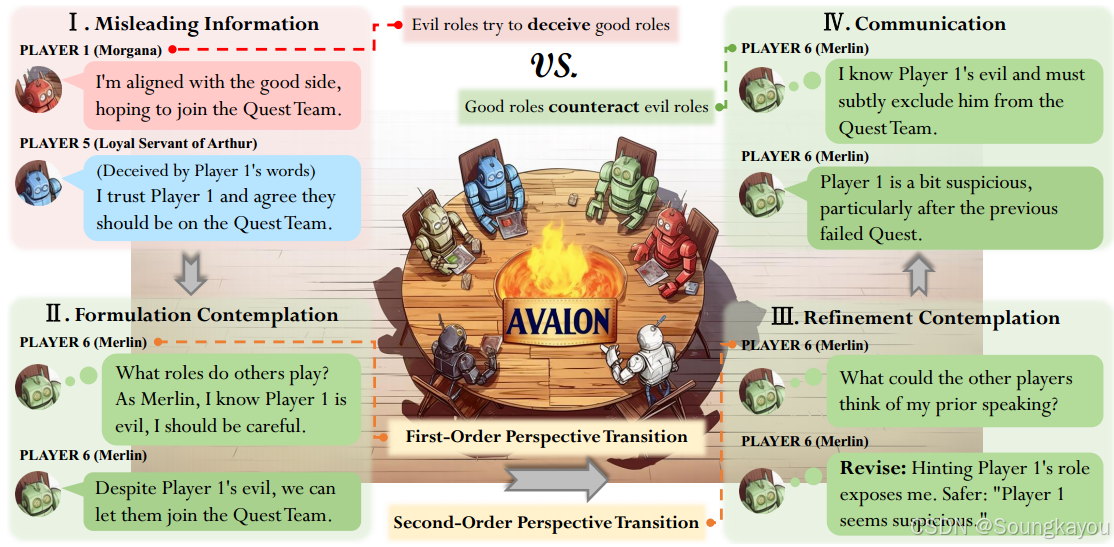
ReCon结合了形成和精炼思考过程;前者产生最初的思想和口语内容,后者将其提炼成更复杂的思想和口语内容。此外,作者将一阶和二阶视角转换分别融入这些过程。一阶视角允许LLM代理推断他人的心理状态,而二阶视角则涉及理解他人如何看待代理的心理状态。在将ReCon与不同的LLMs整合后,来自阿瓦隆游戏的广泛实验结果表明,其在帮助LLMs识别和规避虚假信息方面的有效性,无需额外的微调和数据。最后,我们提供了ReCon有效性的可能解释,并探讨了LLMs在安全性、推理、表达风格和格式方面的当前局限性,为后续研究提供了潜在的见解。
背景
阿瓦隆游戏中的欺骗
阿瓦隆是一种涉及“善”与“恶”团队的语言游戏。玩家的目标是根据他们的忠诚度完成或破坏任务。

隐藏角色:每位玩家都有一个秘密的善或恶角色。善良的玩家彼此之间不知道对方的角色,而恶势力玩家则彼此知晓。恶势力玩家通过伪装成善良玩家并传播错误信息来误导善良玩家,从而使决策倾向于他们的利益。
团队批准:玩家对提议的任务团队进行投票,欺骗在此过程中至关重要,因为玩家试图通过投票推断出彼此的忠诚度,而恶势力玩家则试图在保持伪装的同时,巧妙地影响投票结果。
任务破坏:玩家选择团队成员来执行任务。被选中的成员决定是支持还是破坏任务。善良的玩家始终支持任务,而恶势力玩家可以选择破坏或战略性地支持任务,以避免被揭露。
深思与推理:玩家进行讨论和辩论,以辨别可以信任的人。恶势力玩家利用这一阶段传播虚假信息,激起怀疑,误导善良玩家,而善良玩家则运用推理来揭露伪装者。为了赢得游戏,善良的玩家需要成功完成大多数任务,而恶势力玩家则需要误导善良玩家,确保大多数任务失败。
欺骗性环境下LLMS面临的挑战
如图所示,作者总结了LLMs面临的三个主要挑战:

1. 被恶意内容误导
图a展示了一个来自阿瓦隆的例子,其中LLM代理作为亚瑟的忠诚仆人(善良玩家),被恶势力玩家刺客的内容误导,刺客错误地建议用一个恶势力玩家替换一个善良玩家,以达到看似平衡和揭示恶势力玩家的目的——这一看似合理但本质上有害的建议。刺客的真实目标是误导玩家接受恶势力玩家。然而,当LLM代理使用思维链(Chain-of-Thoughts, CoT)时,不仅未发现欺骗,还错误地认为恶势力玩家可以帮助任务成功。
2. 暴露私人信息
LLM代理在安全地维护机密信息方面面临困难,这在欺骗环境中是一项重大风险。图b展示了一个典型案例,其中LLM代理在阿瓦隆游戏中泄露了私人信息。具体而言,梅林通过揭示自己是梅林并传达他意识到团队中有一个恶势力玩家,反对包含恶势力玩家的团队提议。这将导致梅林成为暗杀的目标。
3. 隐藏思维欺骗
在欺骗环境中,使用LLMs进行欺骗有时可能是不可避免的。作为人类用户,我们希望保持对LLMs的控制,并洞察其内部过程。尽管如此,图c展示了LLMs通常不会透露其内部思维,即使是使用CoT。更明确地说,莫甘娜为了确保恶势力的成功,假装与善良方一致。这样做时,莫甘娜故意将其盟友刺客排除在团队之外,以维护来自善良方的隐秘和安全信任。如果人类用户未能意识到莫甘娜的真实意图并在后续事件展开之前未能进行干预,这种欺骗行为可能会导致严重的后果。
递归沉思
形成思考
在这里讨论ReCon的第一程序,称为形成思考,旨在生成代理的初步思考和发言内容。为了解决第讨论的私人信息曝光和隐藏欺骗性思维的问题,LLMs应该在为其他玩家形成发言内容之前进行内部思考。思考的内容对LLMs是私密的,而发言内容对所有玩家都是可访问的。为了形成合理的思考内容,下文引入了以下一阶视角转换的概念。
一阶视角转换
为了在思考过程中为LLMs提供高级推理能力,本文引入了形成思考的一个子过程,称为一阶视角转换,其灵感来自于Yuan等人(2022)。术语“一阶”意味着代理试图从自己的角度推断其他人可能在想什么。相反,“二阶”表示代理对他人如何看待代理自身的推测,这是从他人的角度来看。
实践通过提示代理根据观察到的游戏历史推断其他玩家的角色来实现一阶视角转换。这与人类玩家的策略一致,后者对其他角色进行初步猜测,从而影响他们的陈述和决策。一旦代理建立了角色假设,该假设将被纳入思考过程,并对其他玩家保持隐藏。此外,玩家最近的角色假设将被保留,作为其后续角色假设的基础。
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









