







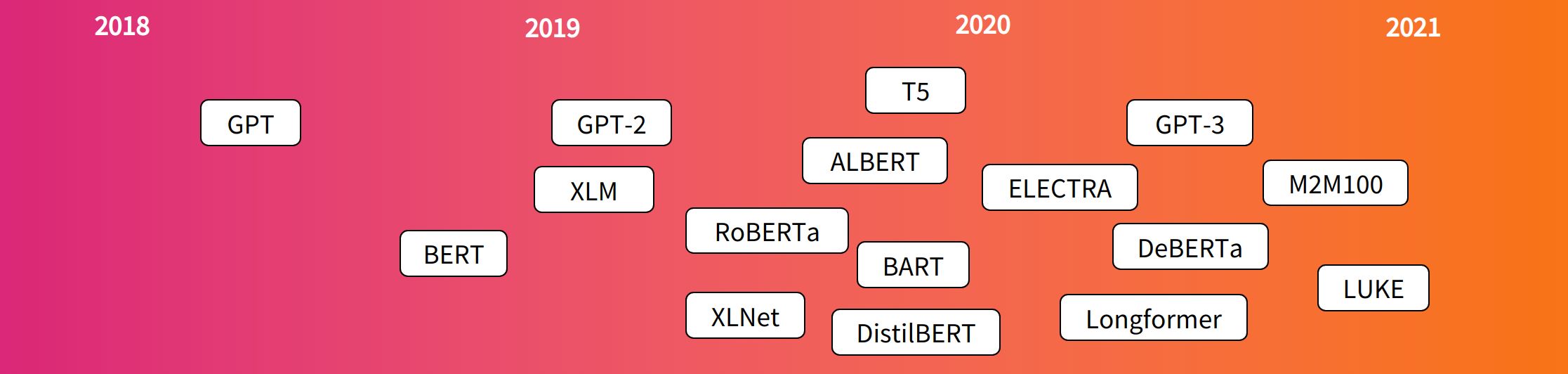
Transformer提出大致时间线:
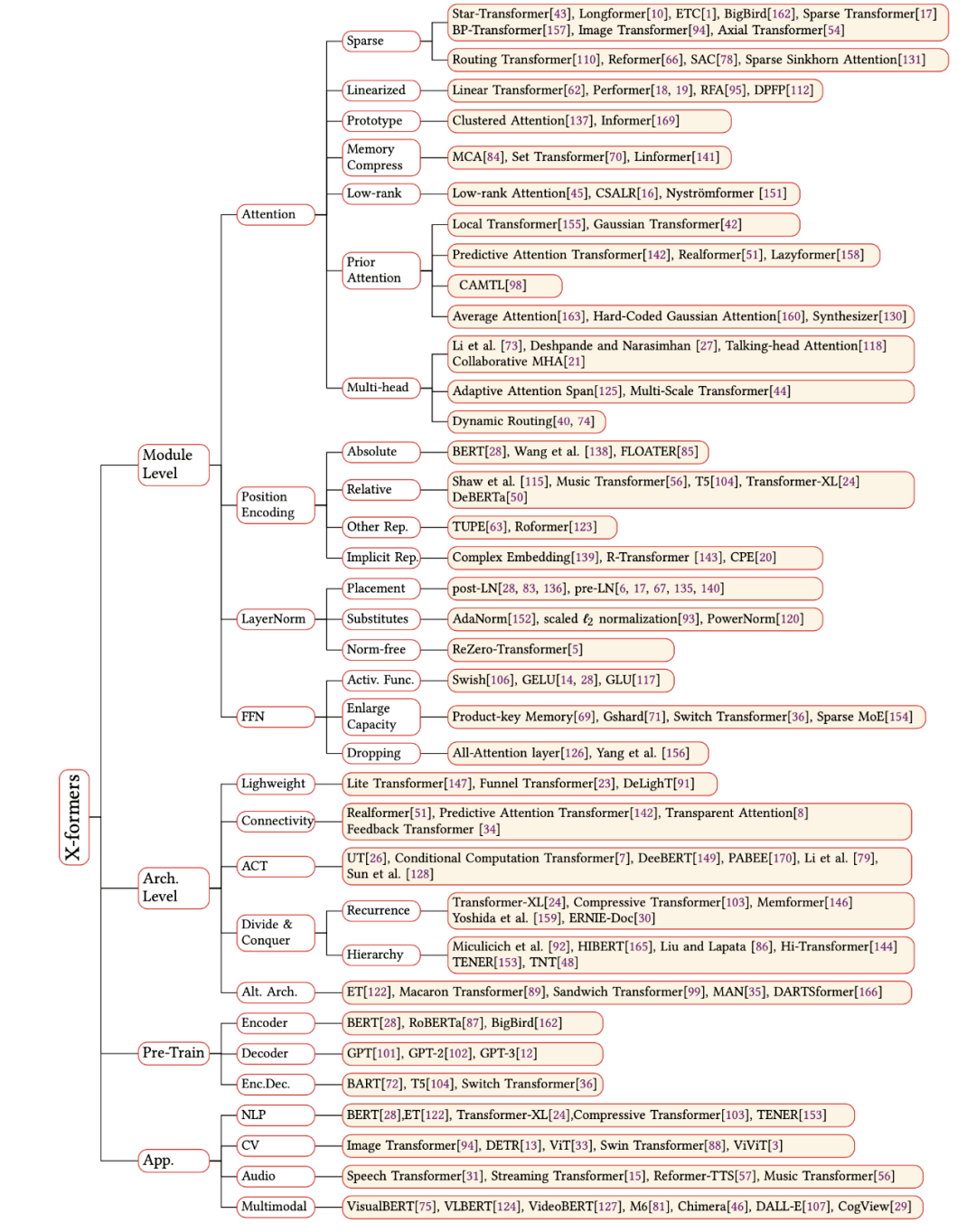
Transformer 分类:
目录
- Vanilla Transformer(2017)
- Reformer(2020.1)
- Linear Transformer(2020.1):注意力计算线性复杂度
- Performer(2020.9)
- Longformer(2020.4)
- Informer(2020.12)
- Autoformer(2021.6)
- Transformer-XL(2019.1):引入跨层的循环机制,支持长距离依赖建模
- Compressive Transformer(2019.11):增加压缩记忆模块,增长捕捉的语义长度
- Infinite-former(2021.9):使用连续空间注意力框架,它的注意力复杂性与上下文的长度无关
1. Vanilla Transformer(2017)
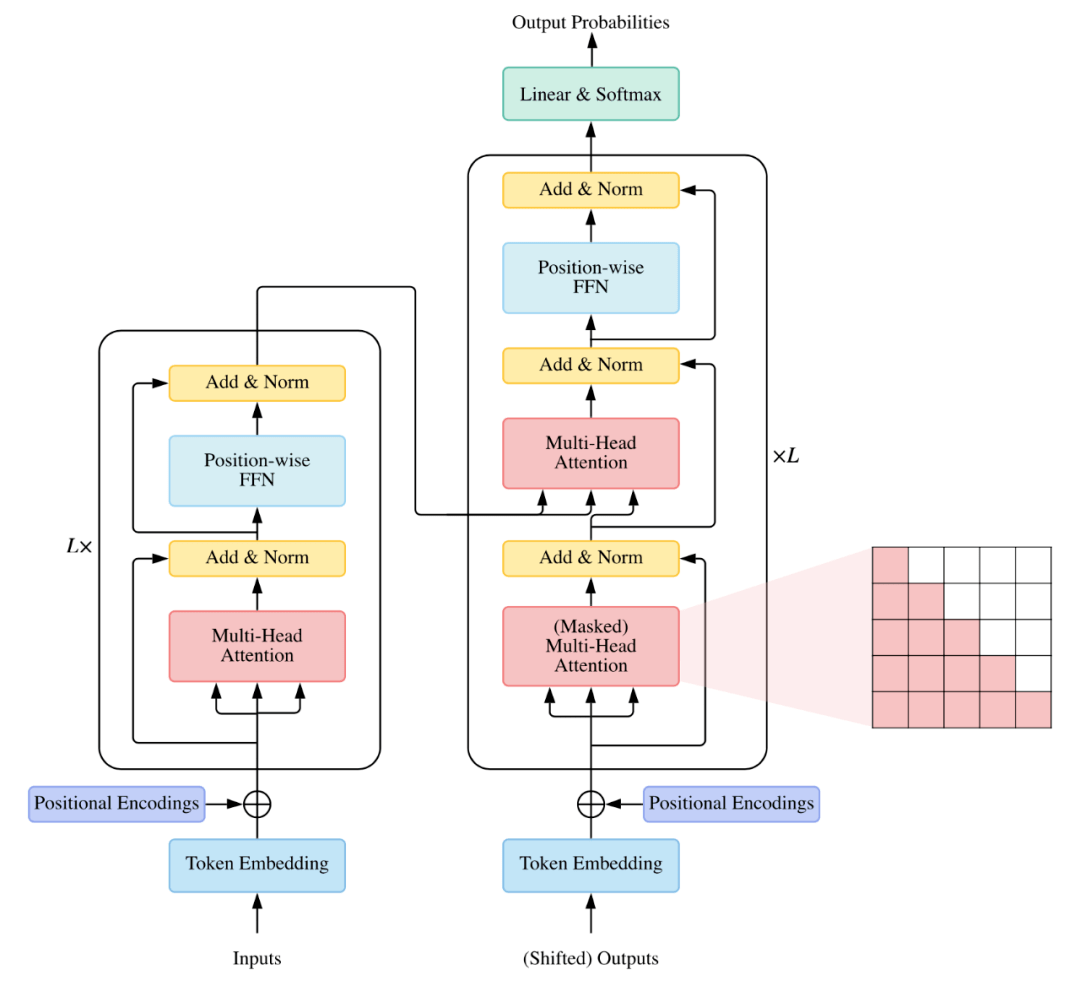
注意力机制:
理想情况下,位置嵌入(Positional Encoding)的设计应该满足以下条件:
- 它应该为每个字输出唯一的编码
- 不同长度的句子之间,任何两个字之间的差值应该保持一致
- 它的值应该是有界的
相对位置编码(Sinusoidal Position Encoding):可区别位置关系但无法区别前后关系
绝对位置编码(Learned Positional Embedding):不同位置随机初始化可学习参数编码
![]() 绝对位置编码展开:
绝对位置编码展开:

2. Reformer(2020)
一个基于局部敏感哈希(LSH)的注意力模型,引入了可逆的Transformer层,有助于进一步减少内存占用量。复杂度从 O(N^2) 降为 O(N logN),N 为句子长度。
模型的关键思想,是附近的向量应获得相似的哈希值,而远距离的向量则不应获得相似的哈希值,因此被称为“局部敏感”。
并且,标准残差 Layer 替换为可逆残差 Layer,使得训练中只存储一次激活值,而不是 N 次,N 为 Layer 数量。
3. Linear Transformer(2020)
这个模型通过使用基于核的自注意力机制、和矩阵产品的关联特性,将自注意力的复杂性从二次降低为线性O(N)。已经被证明可以在基本保持预测性能的情况下,将推理速度提高多达三个数量级。
- 将softmax attention 线性化: 使用特征图的线性点积来逼近 softmax
- 具有线性复杂度和常数内存的自回归变换器模型
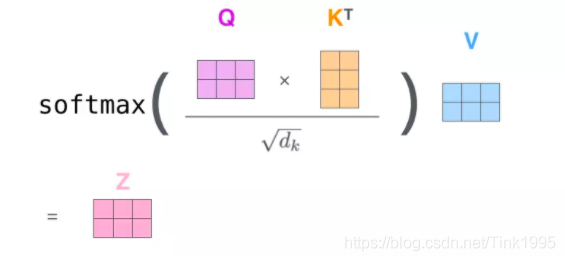
Attention自注意力机制广义公式,Q 和 K 利用相似(sim)函数计算出一个分数,之后除以分数总和获得 Attention 权重,之后去 V 里取值:
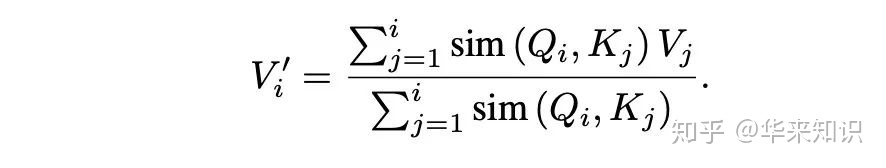
接着用核函数 ,对 sim 函数进行处理,再利用结合律,将 Q 运算提出来
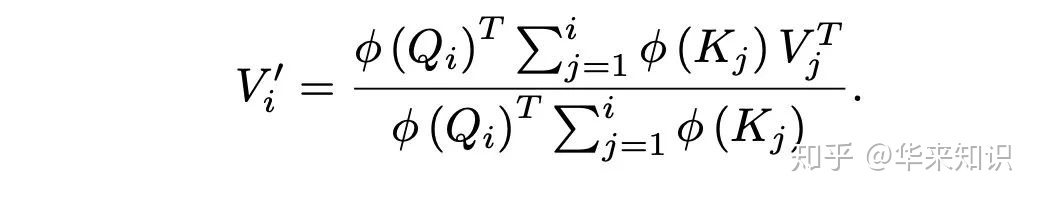
简化
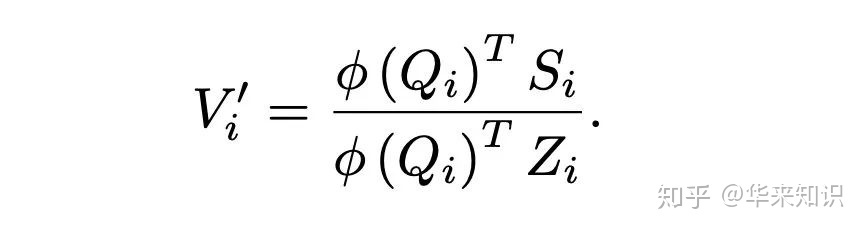
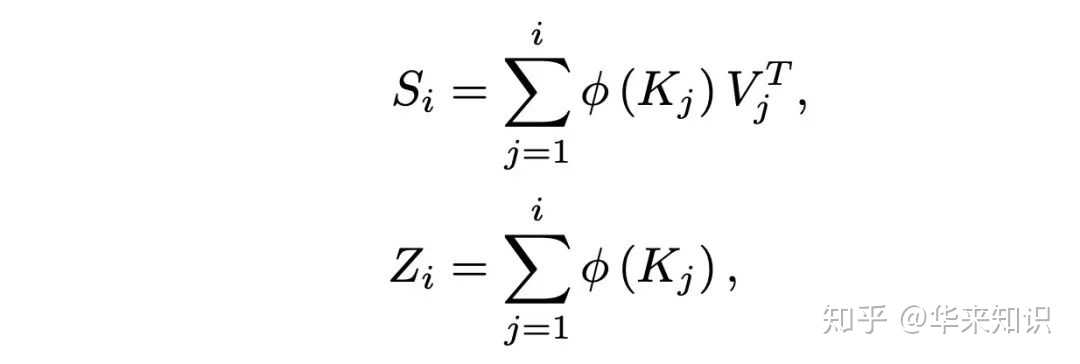
4. Performer(2020)
这个模型利用正交随机特征(ORF),采用近似的方法避免存储和计算注意力矩阵。
5. Autoformer
Autoformer算法与代码分析_布川酷籽的博客-CSDN博客
6. Transformer-XL(2020)
原Transformer的问题:
- segments之间独立训练,所以不同的token之间,最长的依赖关系,就取决于segment的长度;
- 出于效率的考虑,在划分segments的时候,不考虑句子的自然边界,而是根据固定的长度来划分序列,导致分割出来的segments在语义上是不完整的(context fragmentation)
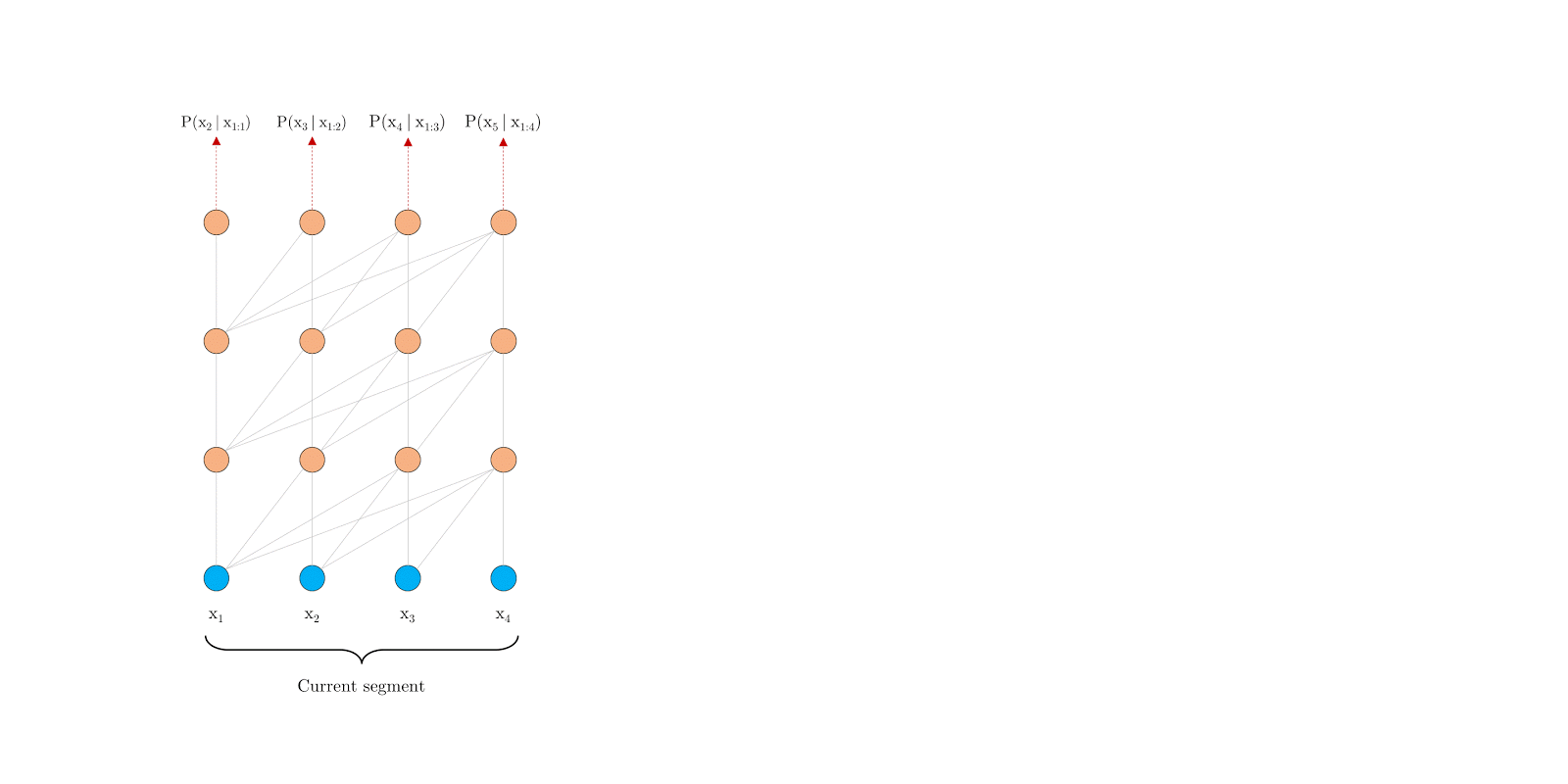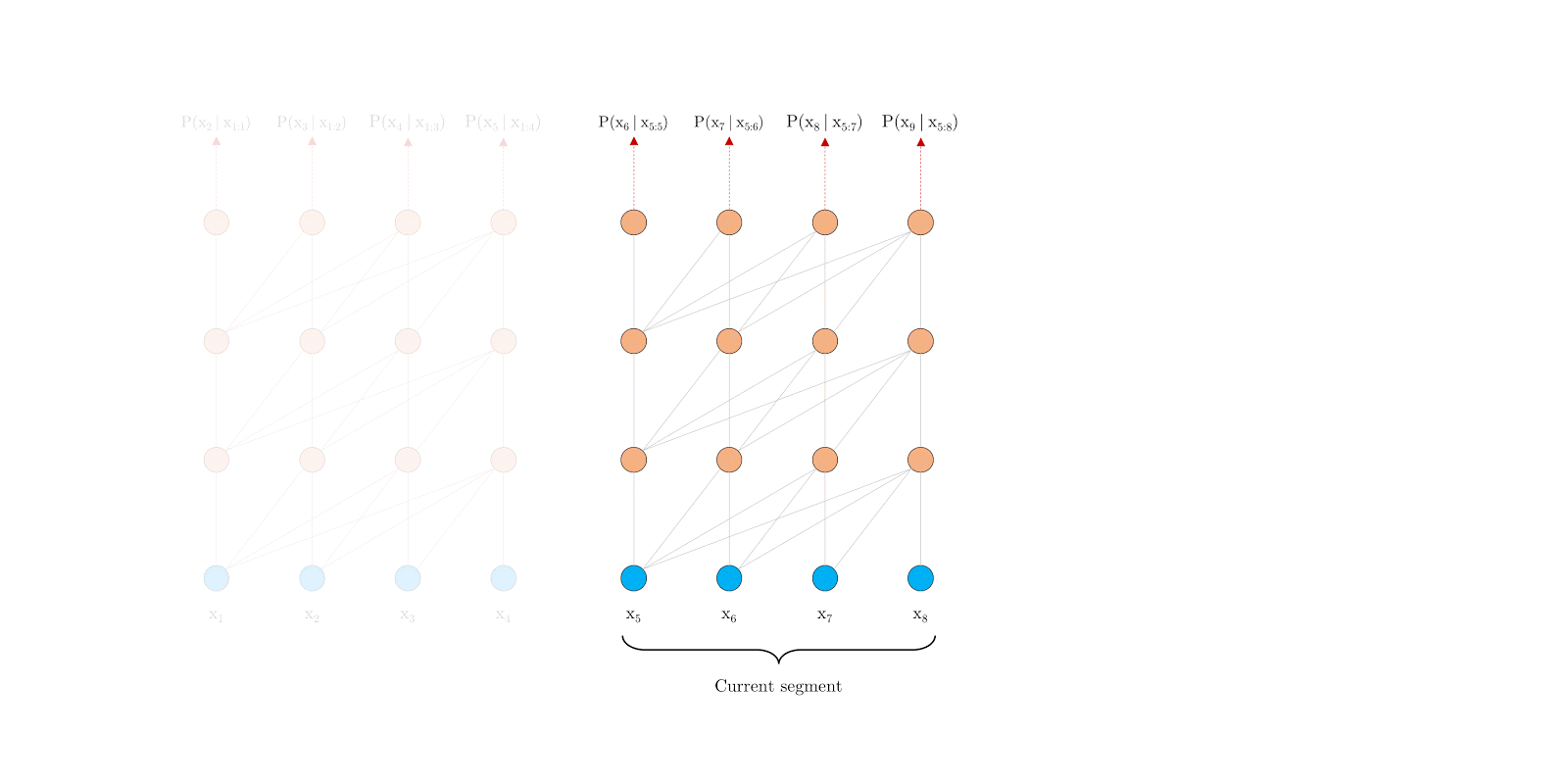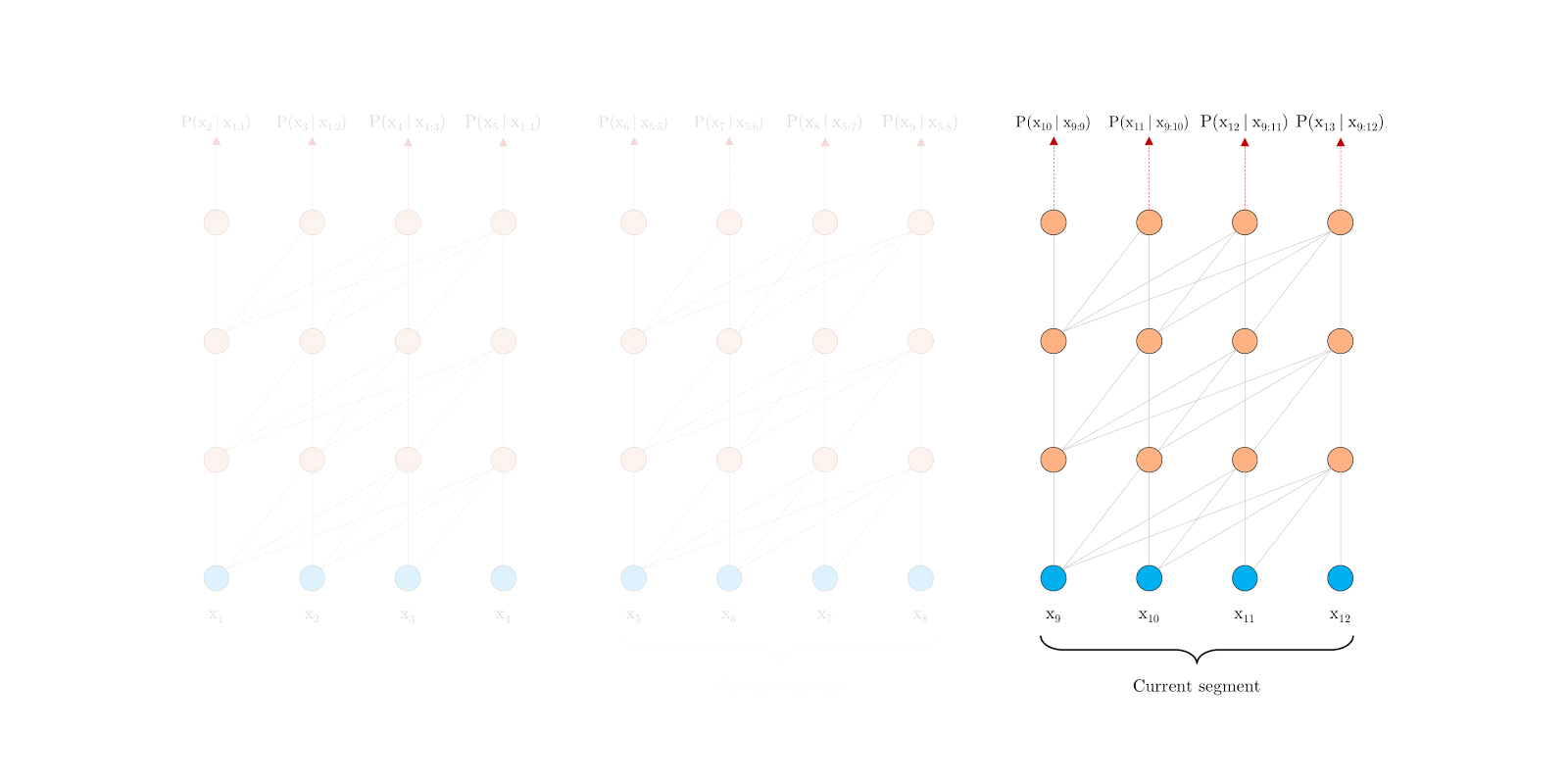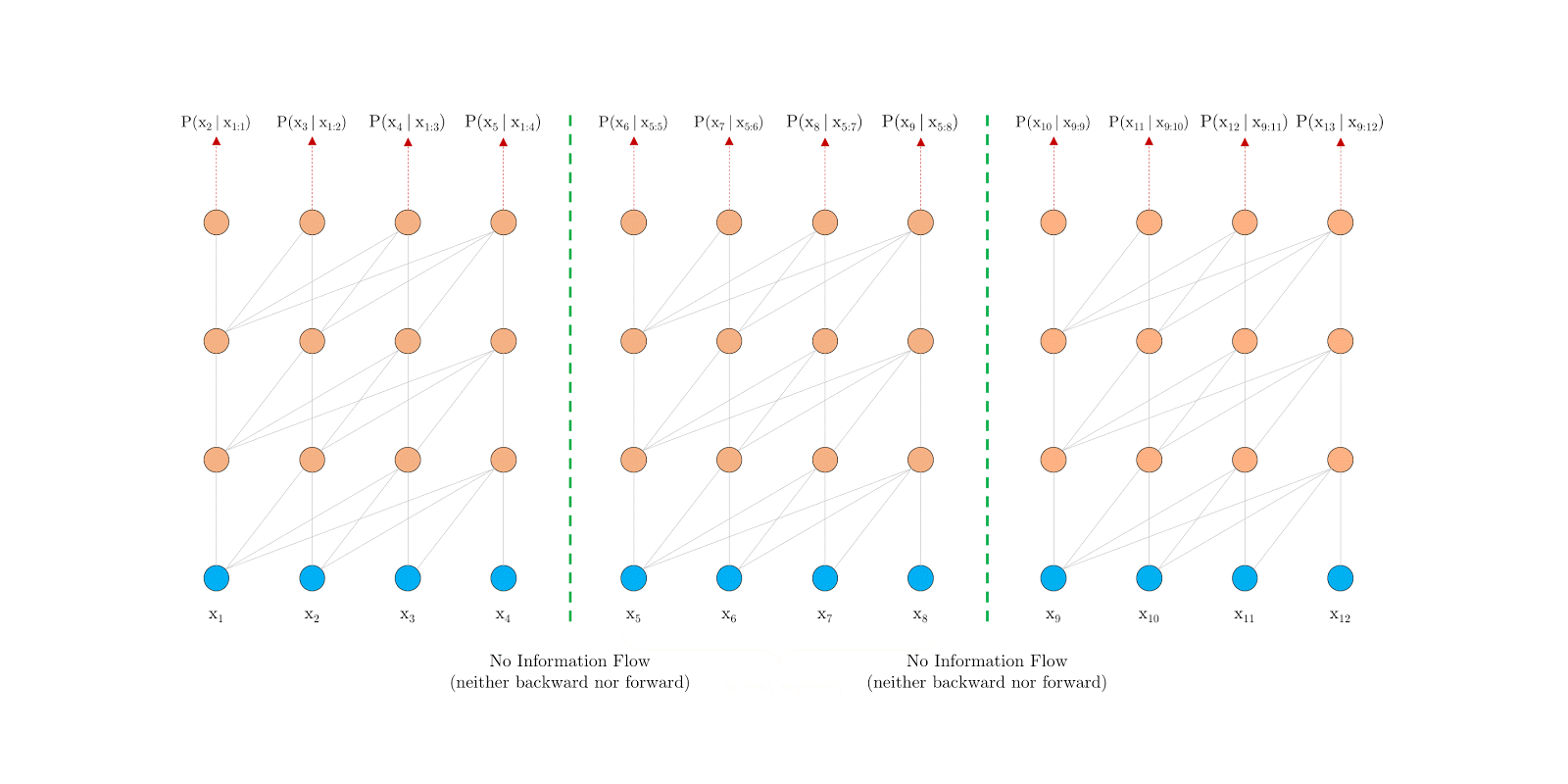
Transformer-XL很有RNN的味道:设法利用之前的segment留下的信息eval时滚动向前,但每次要重新计算整个segment,eval的时候滚动向前,不用重复计算前面segment因为每次在滚动向前,这样就需要使用相对位置编码,而不能使用绝对位置编码。
围绕如何建模长距离依赖,提出Transformer-XL:
Segment-Level Recurrence 片段递归
提出片段级递归机制(segment-level recurrence mechanism),引入一个记忆(memory)模块(类似于cache或cell),循环用来建模片段之间的联系。这部分输出是通过cache的机制传导过来,所以不会参与梯度的计算。原则上只要GPU内存允许,该方法可以利用前面更多段的信息。
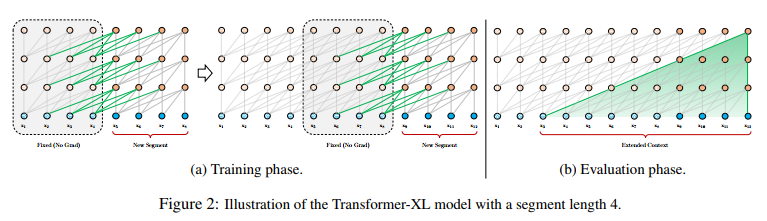
在预测阶段:
如果预测 x4 我们只要拿之前预测好的 [x1, x2, x3] 的结果拿过来,直接预测。同理在预测 x5 的时候,直接在 [x1,x2,x3,x4] 的基础上计算,不用像Vanilla Transformer一样每次预测一个字就要重新计算前面固定个数的词。
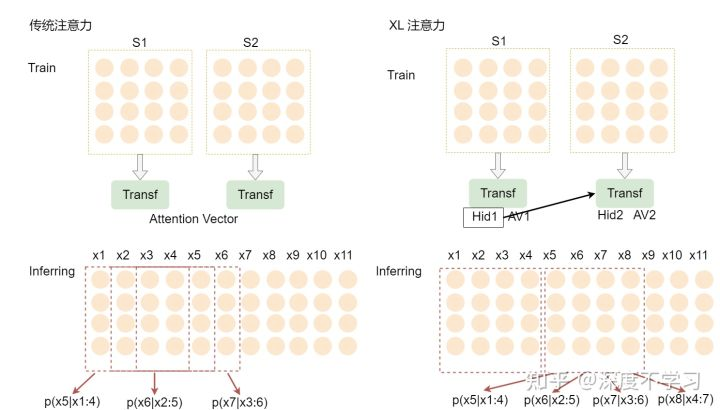
Relative Position Encodings 相对位置编码
在memory的循环计算过程中,避免时序混淆,需要位置编码可重用
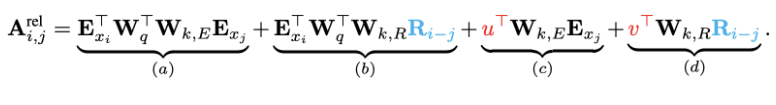
其中:
表示的是i和j的相对距离,是sinusoid encoding matrix,没有额外的训练参数。实际上和vanilla的位置编码一样的,关键是这里的位置编码只给key用,而key的长度,在第一个片段和query的长度一样,之后的片段,key长度=上一个片段hidden state长度+当前片段key的长度,因此
- 因为无论query在序列中的绝对位置如何,其相对于自身的相对位置都是一样的与在序列中的绝对位置无关,应当保持不变.。因此用两个可训练的参数u、v
- vanilla版本的key位置编码与embedding都是采用同样的变化矩阵,xl中,把key的位置编码和embedding分别用了不同的线性变化
每个分项分别代表的含义如下:
- (a)描述了基于内容的Attention,即没有添加原始位置编码的原始分数;
- (b)描述了内容对于每个相对位置的bias,即相对于当前内容的位置偏置;
- (c)描述了全局的内容偏置,用于衡量key的重要性;
- (d)描述了全局的位置偏置,根据query和key之间的距离调整重要性。
7. Compressive Transformers(2020)
这个模型是Transformer-XL的扩展,但不同于Transformer-XL,后者在跨段移动时会丢弃过去的激活,而它的关键思想则是保持对过去段激活的细粒度记忆。
压缩如下:
![]() 其中d是隐藏层的维度,c是压缩比例,c越大 压缩越多
其中d是隐藏层的维度,c是压缩比例,c越大 压缩越多
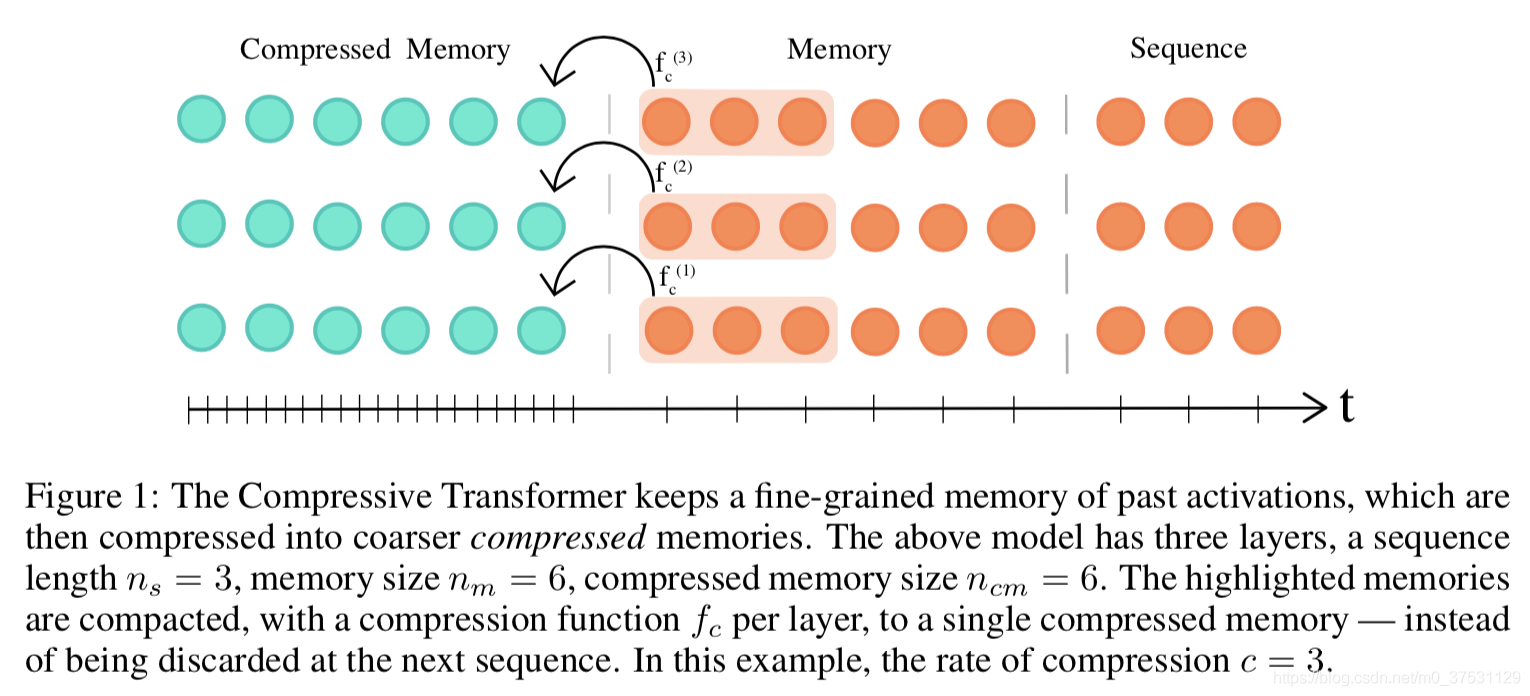
压缩算法步骤
首先 有 2个memory: 一个是存放正常的前几个segment的hidden state ,计做 m, 一个是存放压缩的记忆模块 cm。
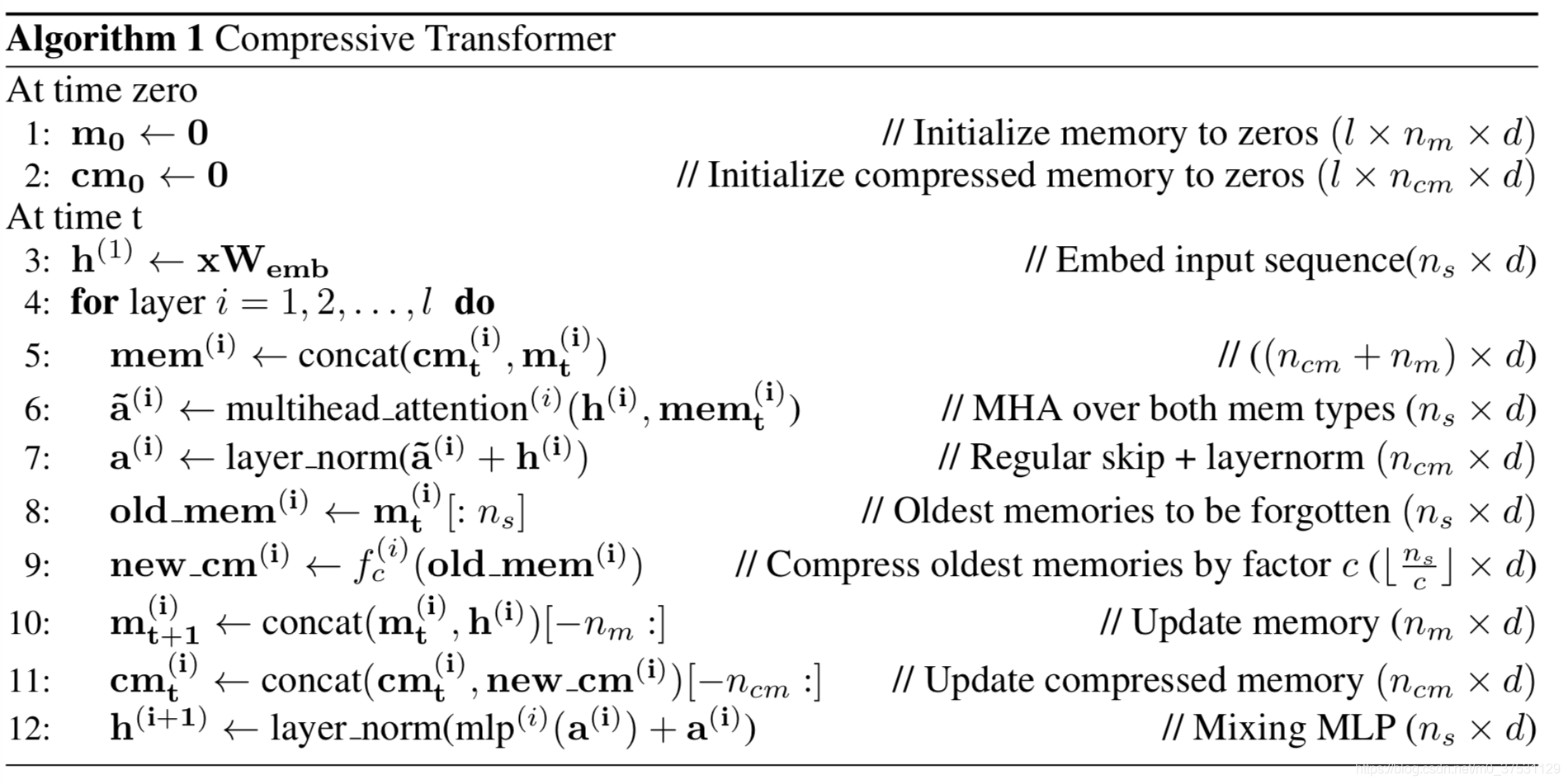
压缩函数 f_c不同构建方式:
- max/mean pooling: kernel 和步长设置为 压缩比例 c。 这个是最快最简单的baseline。
- 1D convolution :kernel和步长也是设置为c.
- dilated convolutions :膨胀卷积。卷积压缩方法 包含需要训练的参数。
- most-used :memories 存储 通过他们的平均attention 和最常使用来存储。这个来源于垃圾回收机制,不常用的记忆模块被删除掉。
Compressive Transformer 和 Transformer-XL比较
 计算复杂度
计算复杂度
7. Infinite-transformer
References
A Survey of Transformers(2021),https://arxiv.org/abs/2106.04554
Efficient Transformers: A Survey(2020)
Transformers Meet Visual Learning Understanding: A Comprehensive Review(2022)















 1101
1101











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









