







文章目录
前言
在深度学习中,学习率(Learning Rate) 是优化算法中最重要的超参数之一。对于卷积神经网络(CNN)而言,合理的学习率调整策略直接影响模型的收敛速度、训练稳定性和最终性能。本文将系统性地介绍CNN训练中常用的学习率调整方法,并结合PyTorch代码示例和实践经验,帮助读者掌握这一关键技巧。
一、学习率
1、什么学习率
学习率是优化算法中一个重要的超参数,用于控制模型参数在每次更新时的调整幅度。学习率决定了模型在参数空间中搜索的步长大小。调整学习率是指在训练过程中根据需要改变学习率的值。
2、什么是调整学习率
常用的学习率有0.1、0.01以及0.001等,学习率越大则权重更新越快。一般来说,我们希望在训练初期学习率大一些,使得网络收敛迅速,在训练后期学习率小一些,使得网络更好的收敛到最优解。
- 使用库函数进行调整
- 手动调整学习率

3、目的
调整学习率的目的是为了能够更好地优化模型,避免训练过程中出现的一些问题,如梯度爆炸或梯度消失、陷入局部极小值等。
二、调整方法
Pytorch学习率调整策略通过 torch.optim.lr_sheduler 接口实现,本篇介绍3种库函数调整方法:
(1)有序调整:等间隔调整(Step),多间隔调整(MultiStep),指数衰减(Exponential),余弦退火(CosineAnnealing);
(2)自适应调整:依训练状况伺机而变,通过监测某个指标的变化情况(loss、accuracy),当该指标不怎么变化 时,就是调整学习率的时机(ReduceLROnPlateau);
(3)自定义调整:通过自定义关于epoch的lambda函数调整学习率(LambdaLR)。
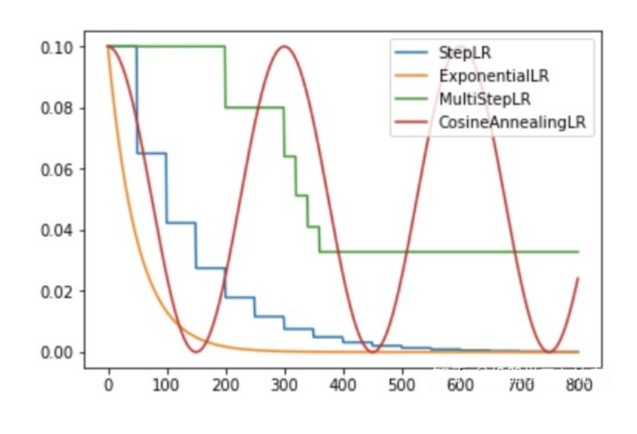
1、有序调整
1)有序调整StepLR(等间隔调整学习率)
"""等间隔调整"""
torch.optim.lr_scheduler.StepLR(optimizer, step_size, gamma=0.1)
# optimizer: 神经网络训练中使用的优化器,
# 如optimizer = torch.optim.Adam(model.parameters(),lr=0.001)
# step_size(int): 学习率下降间隔数,单位是epoch,而不是iteration.
# gamma(float):学习率调整倍数,默认为0.1
# 每训练step_size个epoch,学习率调整为lr=lr*gamma.
2)有序调整MultiStepLR(多间隔调整学习率)
"""多间隔调整"""
torch.optim.lr_shceduler.MultiStepLR(optimizer, milestones, gamma=0.1)
milestone(list): 一个列表参数,表示多个学习率需要调整的epoch值,
如milestones=[10, 30, 80],即10轮时将gamma乘以学习率lr,30轮时、80轮时
3)有序调整ExponentialLR (指数衰减调整学习率)
'''指数衰减调整'''
torch.optim.lr_scheduler.ExponentialLR(optimizer, gamma)
参数:
gamma(float):学习率调整倍数的底数,指数为epoch,初始值我lr, 倍数为γepoch,每一轮都调整.
4)有序调整CosineAnnealing (余弦退火函数调整学习率)
'''余弦退火函数调整'''
torch.optim.lr_scheduler.CosineAnnealingLR(optimizer, T_max, eta_min=0)
参数:
Tmax(int):学习率下降到最小值时的epoch数,即当epoch=T_max时,学习率下降到余弦函数最小值,当epoch>T_max时,学习率将增大;
etamin: 学习率调整的最小值,即epoch=Tmax时,lrmin=etamin, 默认为0.
2、自适应调整
当某指标(loss或accuracy)在最近几个epoch中都没有变化(下降或升高超过给定阈值)时,调整学习率。
1)自适应调整ReduceLROnPlateau (根据指标调整学习率)
"""根据指标调整学习率"""
torch.optim.lr_scheduler.ReduceLROnPlateau(optimizer, mode='min', factor=0.1,patience=10,verbose=False, threshold=0.0001, threshold_mode='rel', cooldown=0, min_lr=0, eps=1e-08)
-
optimizer: 被包装的优化器。
-
mode: 可以是 ‘min’ 或 ‘max’。如果是 ‘min’,当监测的指标停止下降时学习率会被降低;如果是
-
‘max’,当指标停止上升时学习率会被降低。
-
factor: 学习率降低的因子,新的学习率会是旧学习率乘以这个因子。
-
patience: 在指标停止改善之后等待多少个周期才降低学习率。
-
threshold: 用于衡量新的最优值的阈值,只关注显著的变化。
-
threshold_mode: 可以是 ‘rel’ 或 ‘abs’。在 ‘rel’ 模式下,动态阈值会根据最佳值和阈值的相对关系来设定;在 ‘abs’ 模式下,动态阈值会根据最佳值加上或减去阈值来设定。
-
cooldown: 在学习率被降低之后,等待多少个周期再继续正常操作。
-
min_lr: 所有参数组或每个组的学习率的下限。
-
eps: 应用于学习率的最小衰减。如果新旧学习率之间的差异小于 eps,则忽略这次更新。
3、自定义调整
可以为不同层设置不同的学习率。
1)自定义调整LambdaLR (自定义调整学习率)
torch.optim.lr_scheduler.LambdaLR(optimizer, lr_lambda)
参数:
lr_lambda(function or list): 自定义计算学习率调整倍数的函数,通常时epoch的函数,当有多个参数组时,设为list.
三、代码参考
loss_fn = nn.CrossEntropyLoss() # 创建交叉熵损失函数对象
optimizer = torch.optim.Adam(model.parameters(),lr=0.001) #创建一个优化器,一开始lr可以大一些
scheduler = torch.optim.lr_scheduler.StepLR(optimizer,step_size=5,gamma=0.5) # 调整学习率
"""optimizer是一个PyTorch优化器对象
step_size表示学习率调整的步长
gamma表示学习率的衰减因子,即每次调整后将当前学习率乘以gamma
"""
"""训练模型"""
train_dataloader = DataLoader(training_data, batch_size=64, shuffle=True)
test_dataloader = DataLoader(test_data, batch_size=64, shuffle=True)
epochs = 10
acc_s = []
loss_s = []
for t in range(epochs):
print(f"Epoch {t+1}\n---------------------------")
train(train_dataloader,model,loss_fn,optimizer)
test(test_dataloader, model, loss_fn)
scheduler.step()
print(bast_acc)
总结
没有"放之四海皆准"的最优策略,通过实验找到适合具体任务的方法才是王道。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









