







文章目录
前言
在人脸识别领域,FisherFaces 算法凭借有监督学习的优势,成为经典的判别式方法之一。
一、FisherFaces 算法核心原理
1. 算法思想:最大化类间差异,最小化类内差异
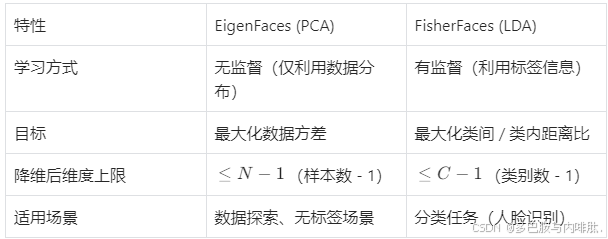
FisherFaces 基于线性判别分析(LDA),与 EigenFaces(PCA)的无监督降维不同,它是有监督学习方法,目标是找到一个投影方向。PCA方法是EigenFaces人脸识别的核心,但是其具有明显的缺点,在操作过程中会损失许多人脸的特征信息。因此在某些特殊的情况下,如果损失的信息刚好是用于分类的关键信息,必然导致结果预测错误。
Fisherfaces采用LDA(Linear Discriminant Analysis,线性判别分析)实现人脸识别。
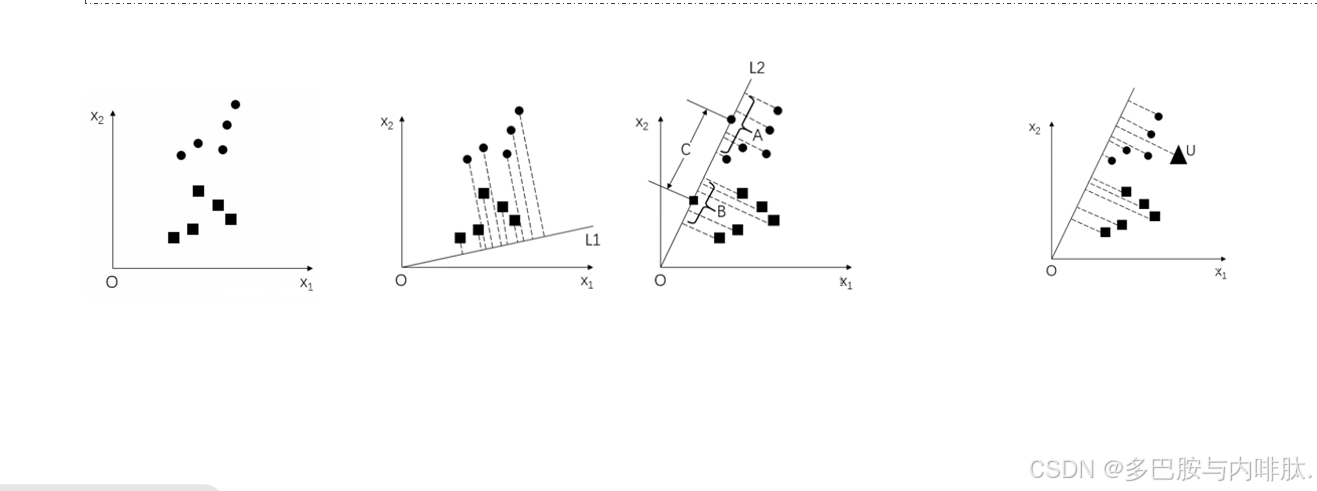
其基本原理:在低维表示下,首先将训练集样本集投影到一条直线A上,让投影后的点满足:
- 同类间的点尽可能地靠近,
- 异类间的点尽可能地远离。
2. 数学推导
- 数据准备:假设训练集有(C)个类别(人脸身份),每个类别有 (n_i)张图像,总样本数(N=\sum n_i)
- 计算类内散度矩阵
((S_W)):(S_W = \sum_{c=1}^C \sum_{x \in X_c} (x - \mu_c)(x - \mu_c)^T)((\mu_c)为第(c)类的均值向量) - 计算类间散度矩阵
((S_B)):(S_B = \sum_{c=1}^C n_c (\mu_c - \mu)(\mu_c - \mu)^T)((\mu)为所有样本的全局均值) - 广义特征值分解:
求解广义特征值问题 (S_B w = \lambda S_W w),提取前(d)个最大特征值对应的特征向量,构成投影矩阵(W)。
3. 与 EigenFaces 的核心区别
二、Python 实战
1. 环境准备
pip install opencv-python numpy matplotlib
依赖库:OpenCV(算法实现)、NumPy(数值计算)、Matplotlib(可视化)
2. 数据集准备
使用经典的ORL 人脸数据集(40 人,每人 10 张图像,尺寸 112×92),需提前解压到项目目录的ORL_faces文件夹。
3. 代码实现与分步解析
数据加载与预处理
import cv2
import numpy as np
import os
from matplotlib import pyplot as plt
4. 加载数据集(含标签)
def load_dataset(path):
faces = [] # 存储人脸图像向量(一维)
labels = [] # 存储标签(0~39对应40个人)
label = 0 # 标签计数器
# 遍历文件夹(每个子文件夹对应一个人)
for root, dirs, files in os.walk(path):
for file in files:
img_path = os.path.join(root, file)
# 灰度图读取并转为一维向量(112*92=10304维)
img = cv2.imread(img_path, cv2.IMREAD_GRAYSCALE)
faces.append(img.flatten())
labels.append(label)
label += 1 # 切换到下一个人的标签
return np.array(faces), np.array(labels)
- 关键点:图像需统一尺寸并灰度化,转换为一维向量以便矩阵运算
- 标签逻辑:每个子文件夹对应一个唯一标签(0 开始递增)
5.训练FisherFaces模型
def train_fisherfaces_model(faces, labels, num_components=39): # 最大维度为C-1=39
model = cv2.face.FisherFaceRecognizer_create(
num_components=num_components, # 保留的特征数量(不超过C-1)
threshold=0.0 # 识别阈值(置信度低于该值则认为“未识别”)
)
model.train(faces, labels) # 输入训练数据(样本矩阵,标签数组)
return model
6.主程序:加载数据并训练
data_path = 'ORL_faces'
faces, labels = load_dataset(data_path)
fisherfaces_model = train_fisherfaces_model(faces, labels)
- API 说明:cv2.face.FisherFaceRecognizer_create提供参数控制降维维度和识别阈值
- 维度限制:由于 LDA 最大维度为类别数 - 1(40 人对应 39 维),num_components最大设为 39
7. 预测函数(返回标签和置信度)
def predict_face(model, test_face):
# 注意:输入需是二维矩阵(n_samples, n_features)
test_face_2d = test_face.reshape(1, -1)
predicted_label, confidence = model.predict(test_face_2d)
return predicted_label, confidence
8.选取第50张图像(属于第5个人,标签4)
test_index = 50
test_face = faces[test_index]
pred_label, conf = predict_face(fisherfaces_model, test_face)
print(f"预测标签:{pred_label},真实标签:{labels[test_index]}")
print(f"置信度(值越小越可靠):{conf:.2f}")
- 置信度含义:FisherFaces 的置信度是预测时的距离度量值,值越小表示匹配越准确
- 维度转换:输入模型的测试数据必须是二维矩阵(即使单样本也需 reshape 为 (1, n_features))
9.可视化平均脸和特征脸
def visualize_features(model, face_size=(112, 92)):
mean_face = model.getMean().reshape(face_size) # 全局平均脸
eigenvectors = model.getEigenVectors() # 获取投影矩阵(特征向量)
plt.figure(figsize=(12, 6))
# 显示平均脸
plt.subplot(2, 5, 1)
plt.imshow(mean_face, cmap='gray')
plt.title("平均脸")
# 显示前9个特征脸
for i in range(9):
eigenface = eigenvectors[i].reshape(face_size)
plt.subplot(2, 5, i+2)
plt.imshow(eigenface, cmap='gray')
plt.title(f"特征脸{i+1}")
plt.show()
visualize_features(fisherfaces_model)
- 平均脸:所有训练样本的平均值,体现数据集整体特征
- 特征脸:LDA 提取的判别式特征,可视化呈现对分类最关键的面部变化模式
三、优化技巧与典型问题处理
1. 参数调优关键点
num_components:通常设为类别数 - 1(如 40 人用 39 维),但可通过交叉验证选择最优值(如保留 20~35 维)
threshold:根据业务需求设定识别阈值(如置信度 > 500 时认为 “未知人脸”),需通过测试集确定合理范围
2. 数据增强策略
当训练数据不足时,可对图像进行:
添加高斯噪声、模糊处理
直方图均衡化(提升光照鲁棒性)
3. 常见报错处理
维度不匹配:确保输入模型的图像是一维向量(如 112×92→10304 维),且标签为整数数组
类别数过少:LDA 要求类别数≥2,单类别数据会导致算法失效
四、FisherFaces 的优缺点与适用场景
1. 核心优势
有监督学习:利用标签信息提升分类性能,优于 EigenFaces 等无监督方法
小样本高效:在类别数较多但每类样本少(如每人 3~5 张图像)时表现良好
轻量高效:模型复杂度低,适合嵌入式设备或实时识别场景
2. 局限性
维度限制:最大降维维度为类别数 - 1,当类别数极少时(如 2 类),仅能提取 1 维特征
对光照 / 姿态敏感:未显式处理图像变化因素,复杂场景下需结合预处理增强鲁棒性
3. 典型应用场景
中小规模人脸库的门禁系统(如企业、校园)
视频监控中的简单人脸分类(如员工 / 访客区分)
作为基线算法验证深度学习模型的改进效果
五、总结
FisherFaces 算法是传统人脸识别中 “判别式学习” 的代表,通过引入标签信息弥补了 PCA 的无监督缺陷。尽管在复杂场景下逐渐被深度学习取代,但其简洁的数学原理和轻量的实现方式,依然是理解人脸识别核心逻辑的重要切入点。

















 18万+
18万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









