






本博客为山东大学软件学院2024创新实训,25组可视化课程知识问答系统(VCR)的个人博客,记载个人任务进展
数据去重是数据清洗中的一个重要步骤,用于消除数据集中的重复项。以下是针对提到的两种去重方法的详细分析和代码实现。
a. 基于内容的去重
基于内容的去重依赖于文本内容的比较。当数据集很大时,直接比较每对文本可能会非常耗时。因此,通常会使用哈希算法或相似度算法来加速这一过程。
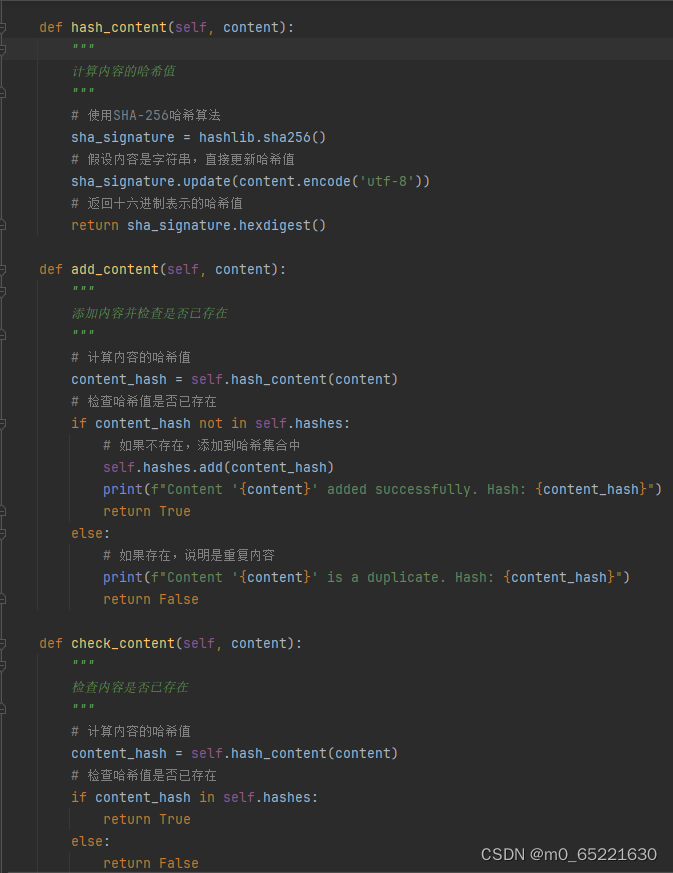
当使用哈希算法实现基于内容的去重时,将数据内容转换为哈希值,并存储这些哈希值以检查是否有重复。使用内置的hashlib库来计算字符串的哈希值,并使用集合(set)来存储和检查哈希值是否已存在。ContentDeduplicator类封装了基于哈希的去重逻辑。有一个hashes集合来存储所有唯一的哈希值。hash_content方法计算给定内容的哈希值,add_content方法添加内容并检查其哈希值是否已存在,而check_content方法仅检查给定内容的哈希值是否已存在。
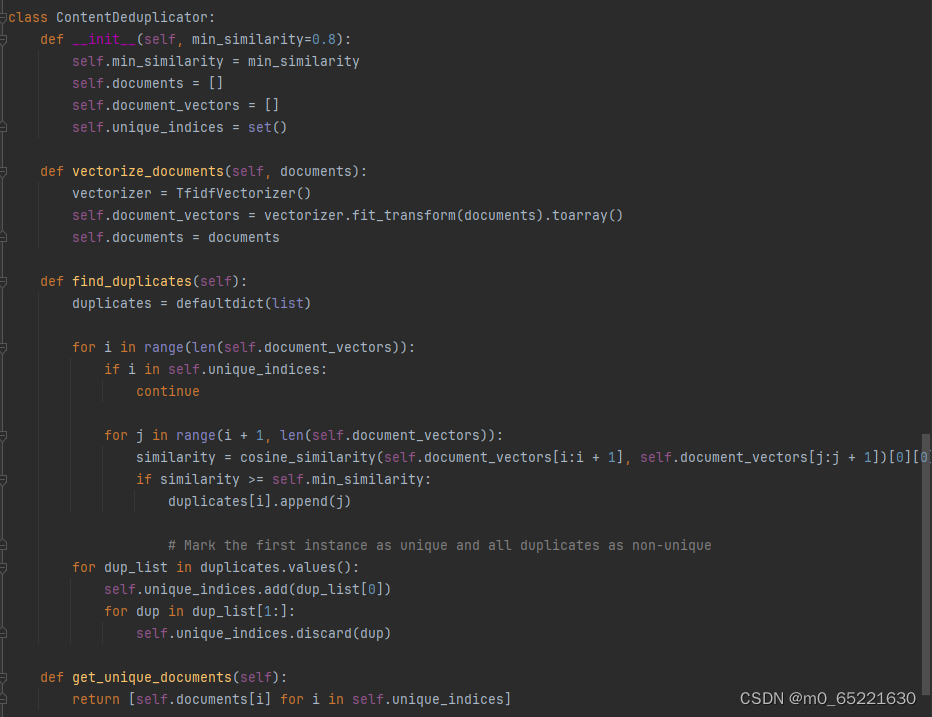
使用相似度算法实现基于内容的去重,选择一个适合内容类型的相似度度量方法,一个基于余弦相似度的文本去重,文本已经被转换为TF-IDF(词频-逆文档频率)向量。ContentDeduplicator类首先使用TF-IDF向量化器将文本转换为向量,然后计算这些向量之间的余弦相似度。如果两个文档的相似度高于设定的阈值(在这个例子中是0.8),则认为它们是重复的。在find_duplicates方法中,遍历所有文档对,并标记第一个出现的文档为唯一,而将其余相似的文档标记为非唯一。最后,get_unique_documents方法返回唯一的文档列表。
b. 基于来源的去重
基于来源的去重通常意味着有一个包含文档或数据项的列表,每个数据项都有一个与之关联的“来源”标识符。在这种情况下,去重意味着仅保留每个来源的最新或第一个数据项。
SourceDeduplicator类使用一个字典来存储唯一的数据项,其中键是来源,值是对应的数据项。如果尝试添加与现有来源关联的新数据项,则会更新该来源的数据项。deduplicate方法遍历包含的列表,并使用add_item方法添加或更新数据项。最后,get_unique_items方法返回基于来源去重后的数据项列表。















 1816
1816

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









