






1.Hadoop的优化和发展
(1)Hadoop1.0核心组件的不足:
(仅指MapReduce和HDFS,不包括Hadoop生态系统内的Pig、Hive、HBase等其他组件)
- 抽象层次低
- 表达能力有限
- 开发者自己管理作业之间的依赖关系
- 难以看到程序整体逻辑
- 执行迭代操作效率低
- 资源浪费
- 实时性差
(2)改进与提升
- 对MapReduce和HDFS许多方面做了有针对性的改进
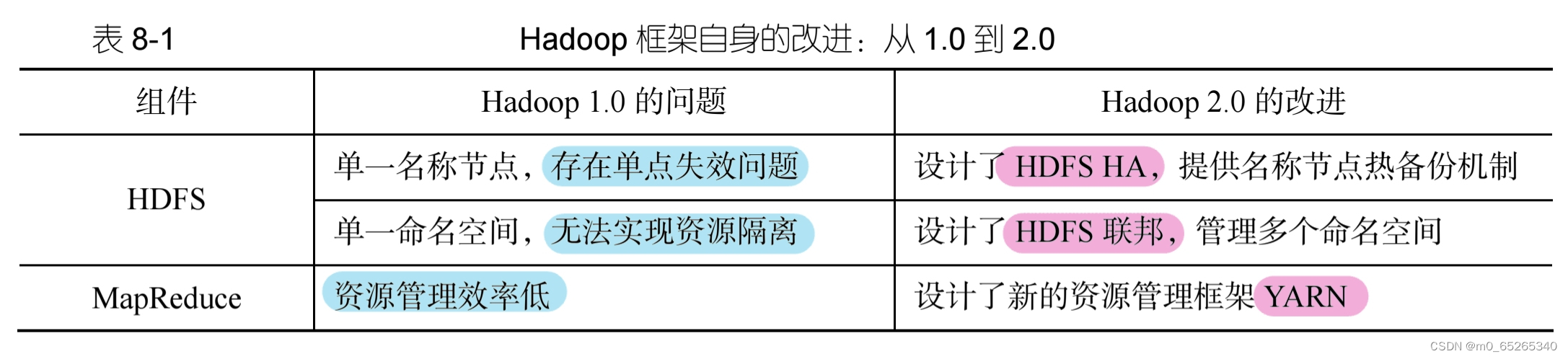
- 融入了更多的新产品:Pig、Oozie、Tez、Kafka等
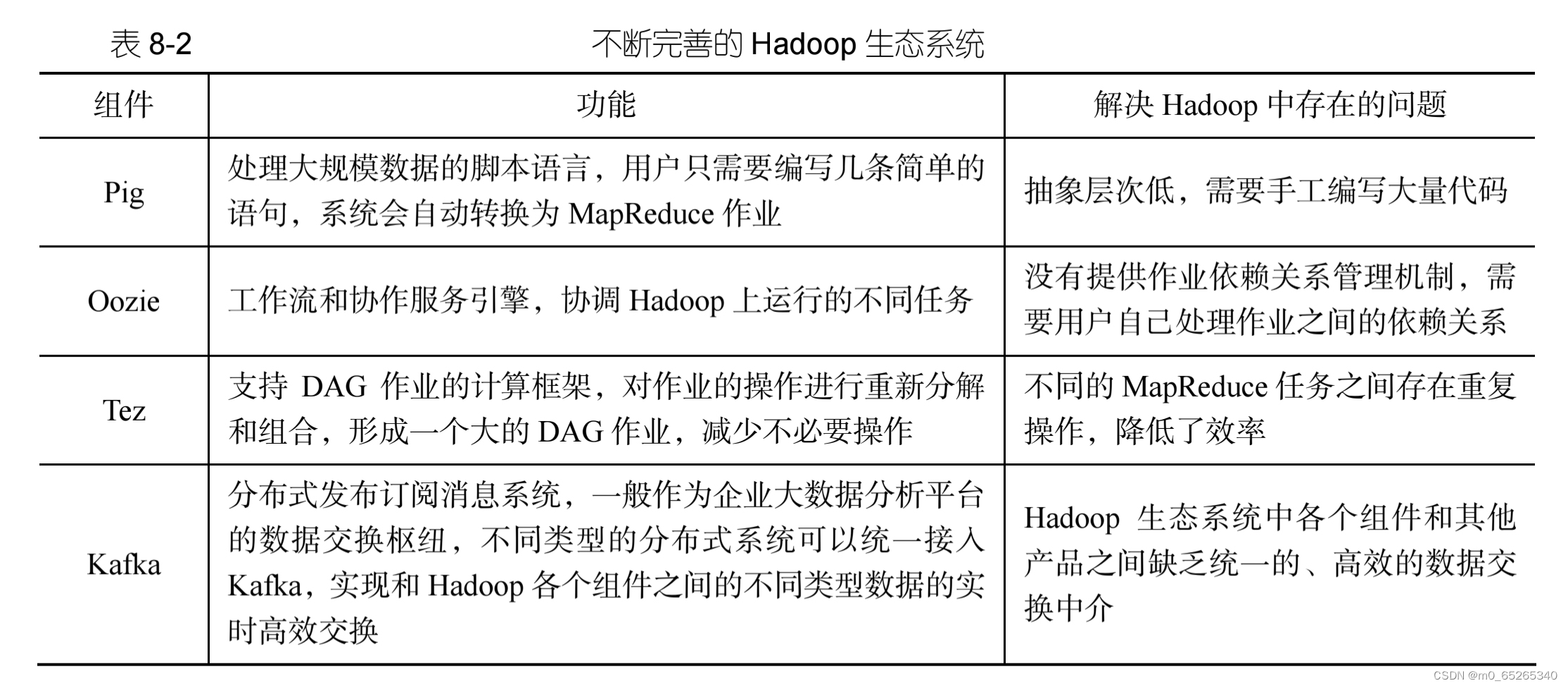
2.HDFS HA
为了解决HDFS 1.0中的“单点故障问题”,HDFS采用了高可用(High Availiablity,HA)架构。
在HDFS HA中,设置两个名称节点,其中一个名称节点处于“活跃”状态,另一个处于“待命”状态,处于待命状态的名称节点提供了“热备份”,一旦活跃名称节点出现故障,就可以立即切换到待命名称节点,不会影响到系统的正常对外服务。
3.HDFS 联邦
相对于HDFS 1.0的优势:
- HDFS集群可扩展性
- 系统整体性能更高
- 良好的隔离性
4.YARN
为了克服MapReduce 1.0版本的缺陷,在Hadoop 2.0以后的版本中对其核心子项目MapReduce 1.0的体系结构进行了重新设计,生成了MapReduce 2.0和YARN。
(1)MapRedece 1.0的缺陷
- 存在单点故障
- JobTracker“大包大揽”导致任务过重
- 容易出现内存溢出
- 资源划分不合理
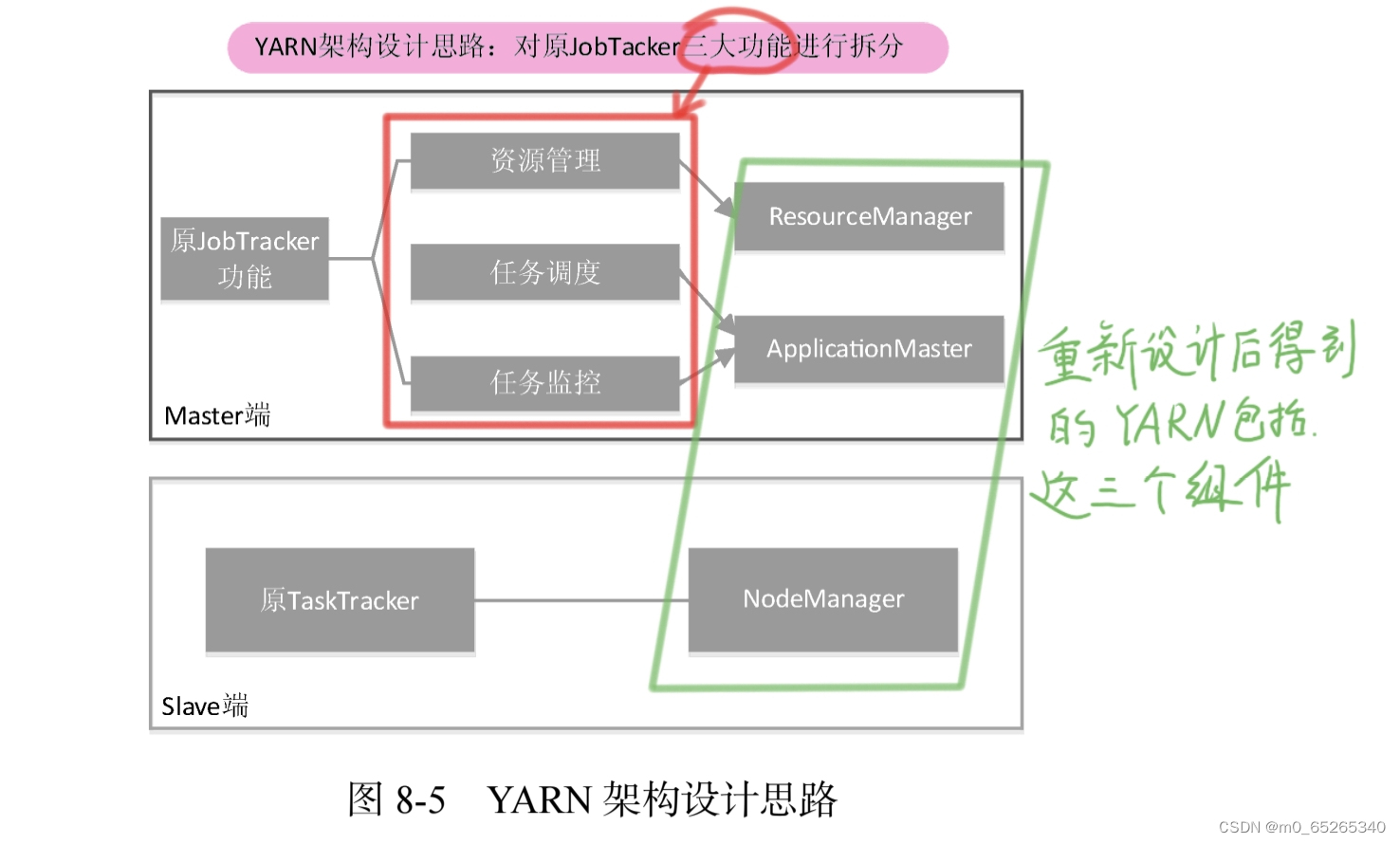
(2)YARN设计思路
对原JobTracker三大功能进行拆分。
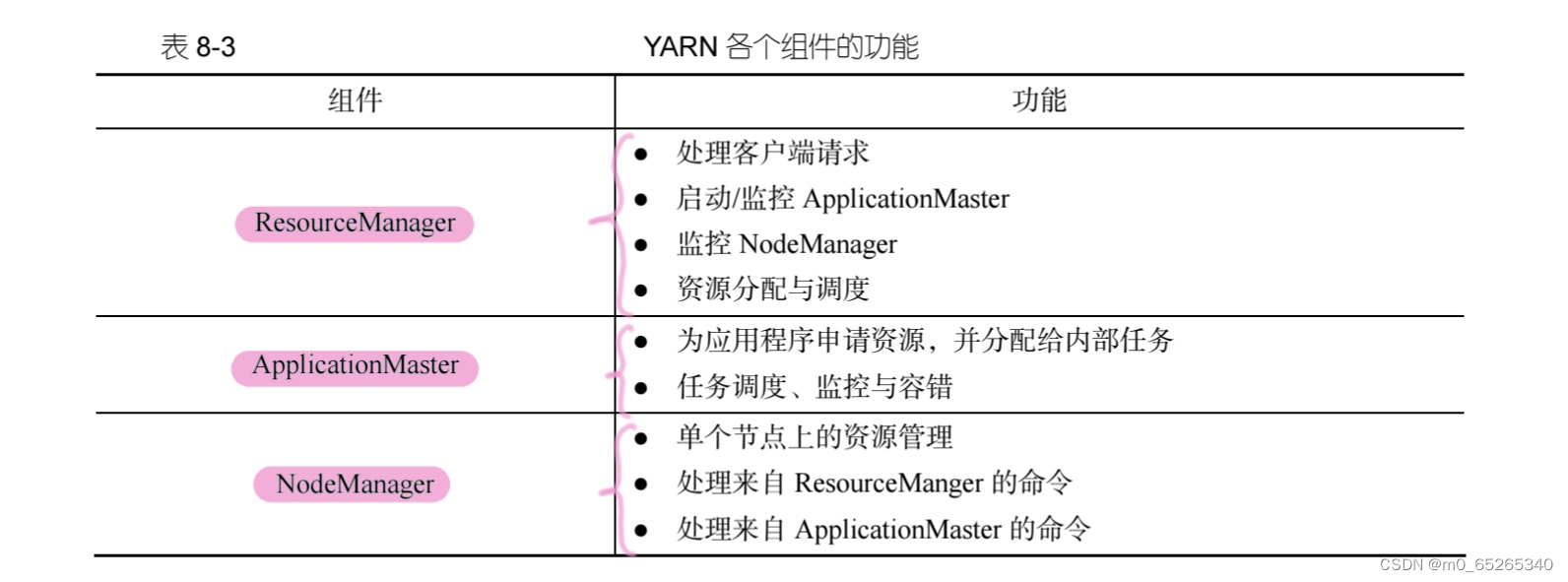
各个组件的功能:
(3)YARN工作流程
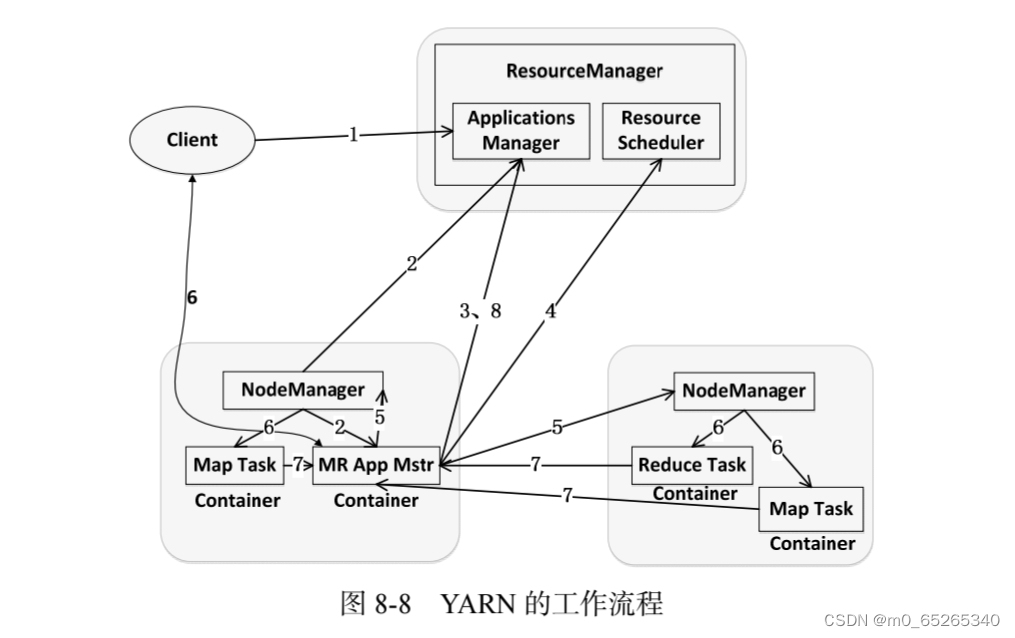
- 步骤1:用户编写客户端应用程序,向YARN提交应用程序,提交的内容包括ApplicationMaster程序、启动ApplicationMaster的命令、用户程序等
- 步骤2:YARN中的ResourceManager负责接收和处理来自客户端的请求,为应用程序分配一个容器,在该容器中启动一个ApplicationMaster
- 步骤3:ApplicationMaster被创建后会首先向ResourceManager注册
- 步骤4:ApplicationMaster采用轮询的方式向ResourceManager申请资源
- 步骤5:ResourceManager以“容器”的形式向提出申请的ApplicationMaster分配资源
- 步骤6:在容器中启动任务(运行环境、脚本)
- 步骤7:各个任务向ApplicationMaster汇报自己的状态和进度
- 步骤8:应用程序运行完成后,ApplicationMaster向ResourceManager的应用程序管理器注销并关闭自己















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









