






这是上课的时候老师留的作业,我在查证多方资料之后,终于做了出来,在此过程中我发现现在有很多这方面的代码讲解都是已经失效了的,故我将我的代码发不出来为自己存个档(完整代码在最下面)
-
首先要确定要爬取的网站
现在https://image.baidu.com/这个百度图片网站不让爬了,使用这里面的ajax链接爬的话一直会返回Forbid spider access,搜了一下这是反爬的意思,但是我用requests.get爬取时将网页检查里的所有headers和params都加了进去,还是不让我爬,很烦,应该会有更好的解决办法,但是我是小菜鸡一个,我采用的方法是换一个网站爬,这里我爬的是https://unsplash.com/ 这个网站(因为我们老师给的实例是爬搜狗图片,淦,所以我只能选别的),是国外的,所以下载图片会有点慢 -
确定资源位置
选好要爬取的网站后,接下来就要确定要爬取的资源的位置了,首先我们打开这个网址(我使用的是chrome浏览器) 之后按F12打开检查台,先选择最上方的Network,再在下面一栏选择Fetch/XHR(ajax请求,XHR就是XMLHttpRequest)
之后按F12打开检查台,先选择最上方的Network,再在下面一栏选择Fetch/XHR(ajax请求,XHR就是XMLHttpRequest)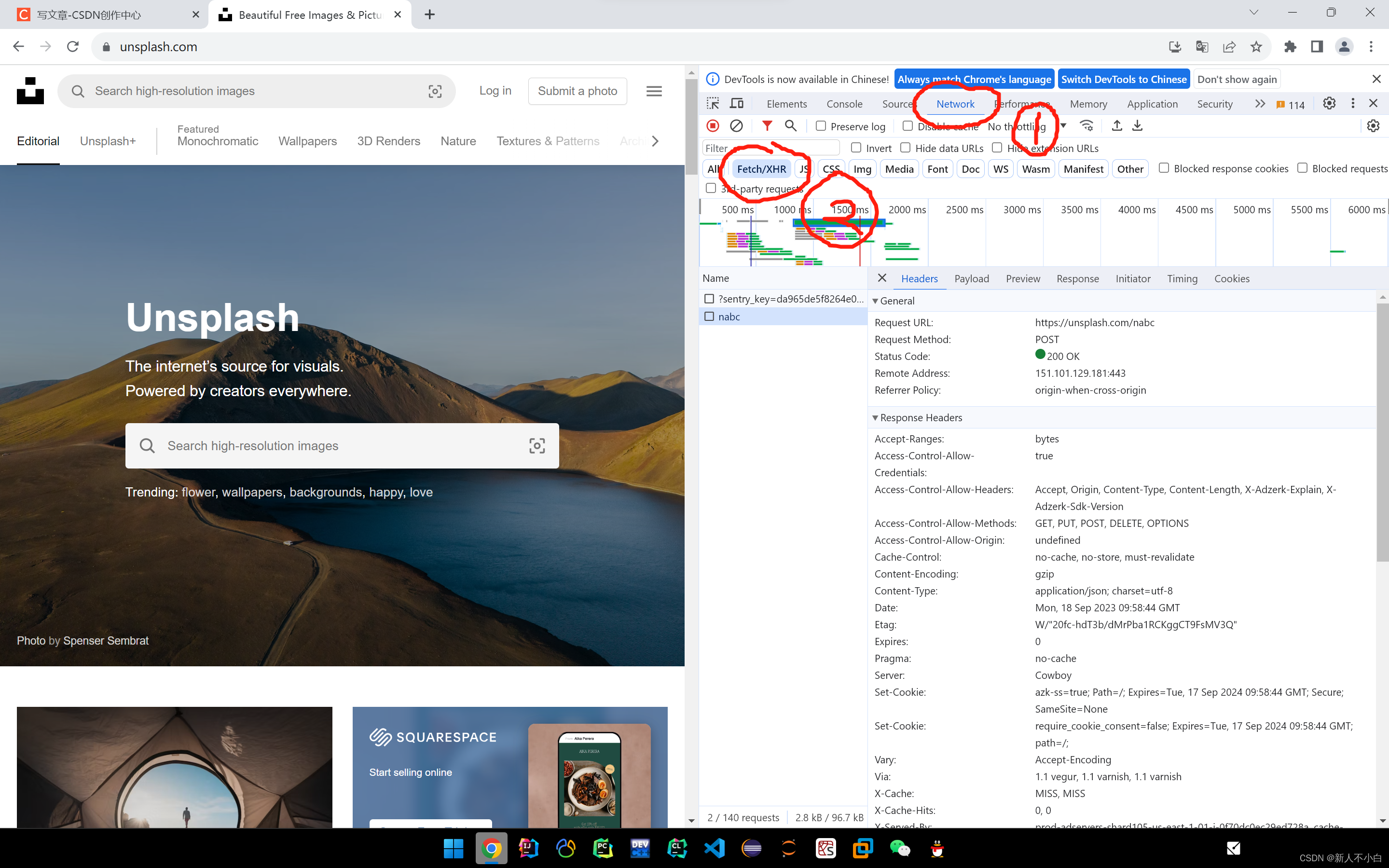 之后在左侧name那一栏里,可以找到我们的资源信息(现在还没有),接下来我们只需要往下滑动界面就可以,这个网页是动态显示的,向下滑的同时就可以持续的从数据库获取数据
之后在左侧name那一栏里,可以找到我们的资源信息(现在还没有),接下来我们只需要往下滑动界面就可以,这个网页是动态显示的,向下滑的同时就可以持续的从数据库获取数据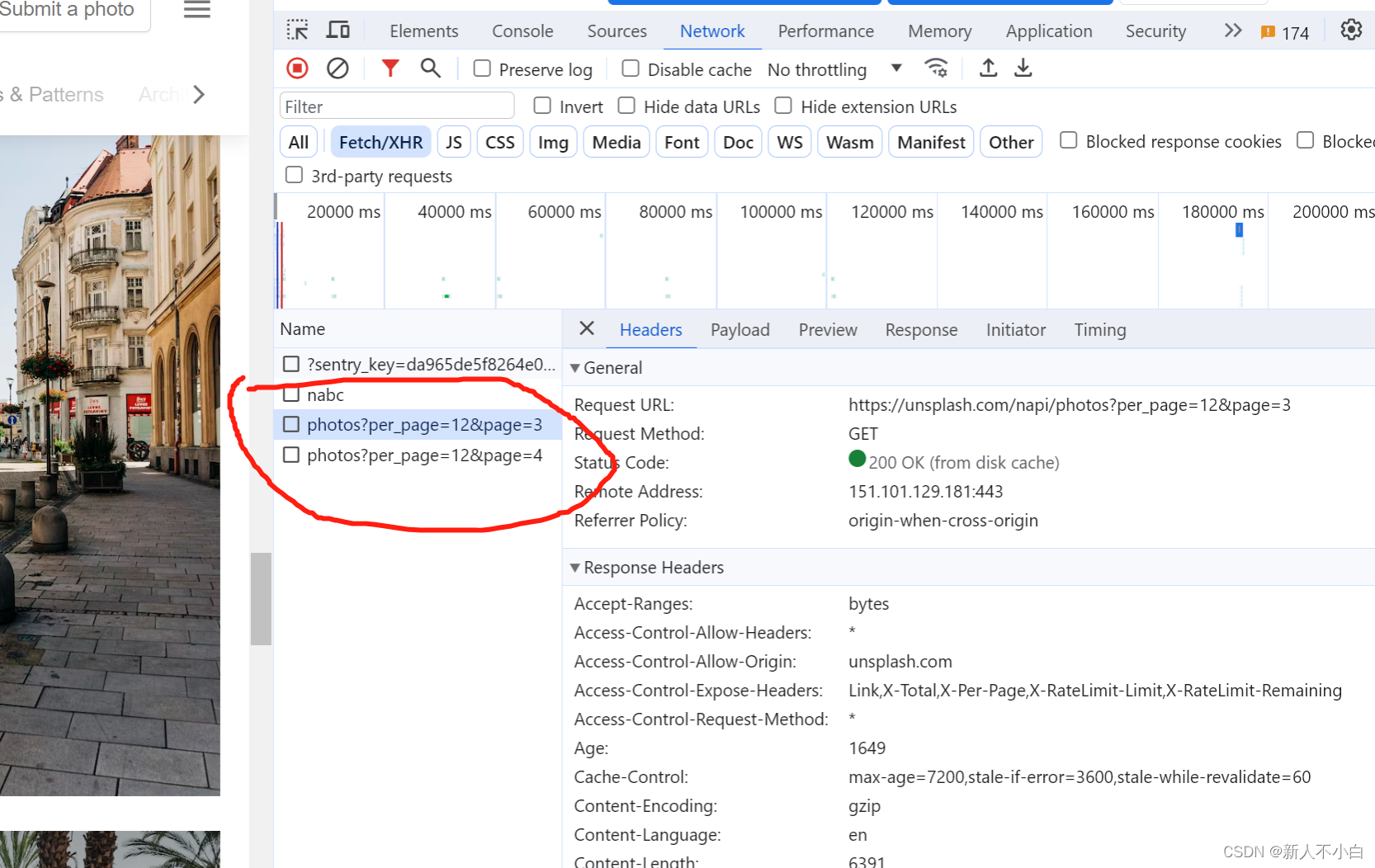 我们可以看到新增了两条信息,photo?per_page...这个就是我们需要的图片资源的请求,之后我们就可以在其中找到我们想要的信息,首先是headers,点击这个请求之后在右侧headers标签的最下方就有我们进行爬取是需要添加的请求头所有信息(我个人认为Referer和User-Agent这两个是必要的)
我们可以看到新增了两条信息,photo?per_page...这个就是我们需要的图片资源的请求,之后我们就可以在其中找到我们想要的信息,首先是headers,点击这个请求之后在右侧headers标签的最下方就有我们进行爬取是需要添加的请求头所有信息(我个人认为Referer和User-Agent这两个是必要的)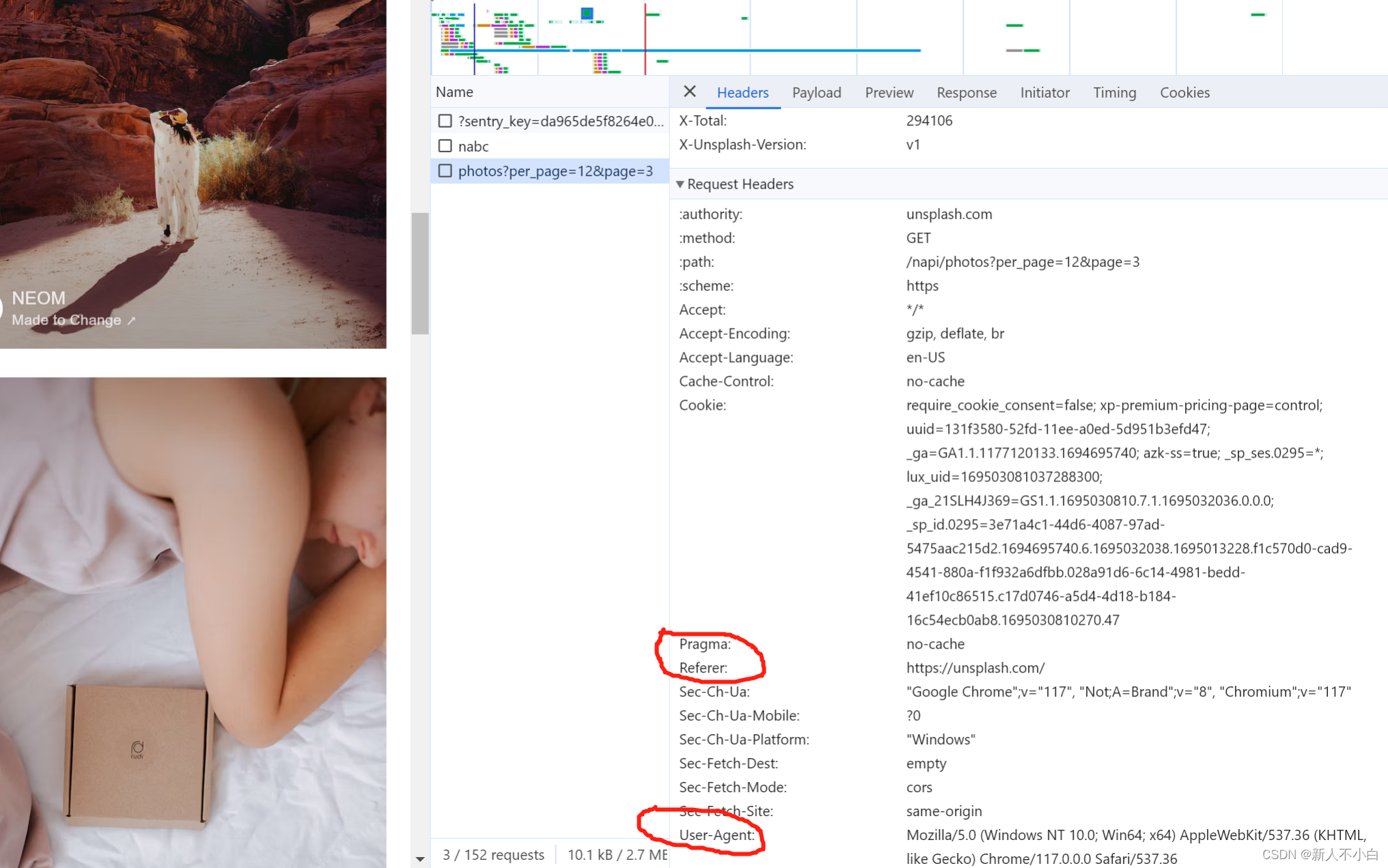 我的代码里面添加了这个
我的代码里面添加了这个 headers = { 'Accept-Encoding': 'gzip, deflate, br', 'Accept-Language': 'en-US', 'Referer': 'https://unsplash.com/', 'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) ' 'Chrome/117.0.0.0 Safari/537.36' }因为我们老师要求的是爬取特定关键词的图片,所以现在就需要我看一下这个网站的搜索请求什么样子的,这里我简单的搜索一下“壁纸”这个关键词
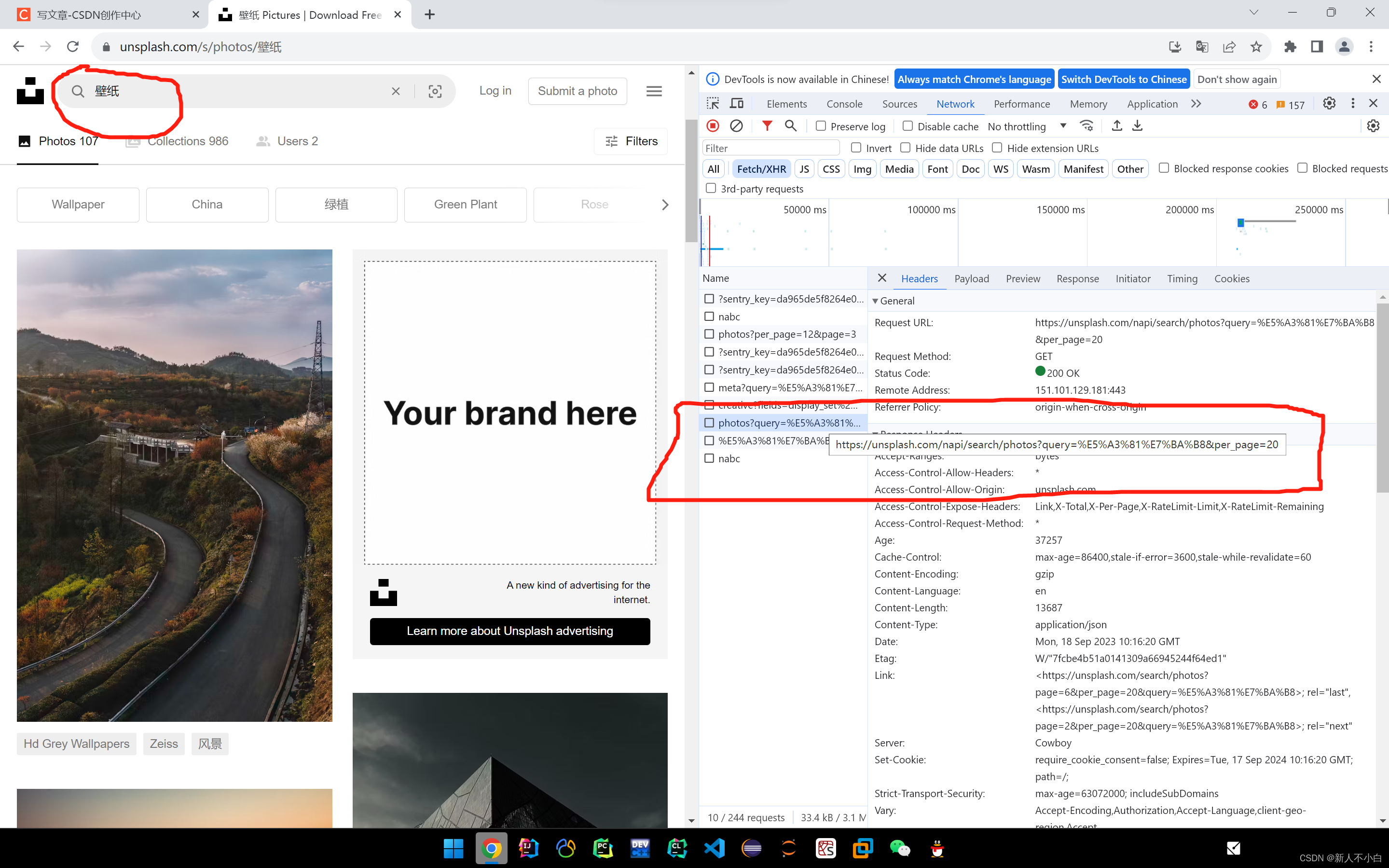 在我搜索之后出现的新请求里我们可以看到新加的这一行,这个就是我们之后需要爬取的关于搜索的url,之后我们切换到Payload标签下观察网址的参数情况
在我搜索之后出现的新请求里我们可以看到新加的这一行,这个就是我们之后需要爬取的关于搜索的url,之后我们切换到Payload标签下观察网址的参数情况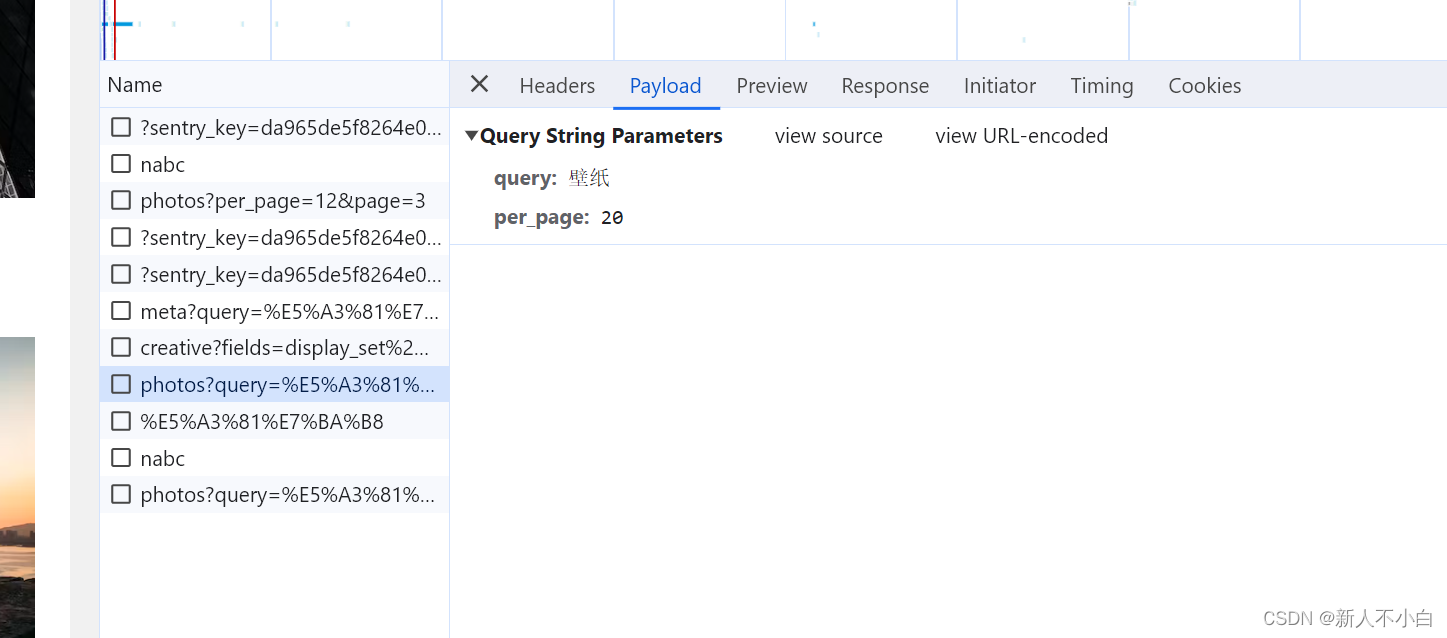 它现在有两个参数,一个是query,一个是per_page,显而易见,query就是我们要搜索的关键词,我猜测per_page就是每页上面显示的图片数量,之后我们继续向下滑动使其动态从数据库获取数据,会发现新增了一个请求,它的参数列表如下
它现在有两个参数,一个是query,一个是per_page,显而易见,query就是我们要搜索的关键词,我猜测per_page就是每页上面显示的图片数量,之后我们继续向下滑动使其动态从数据库获取数据,会发现新增了一个请求,它的参数列表如下 发现它新增了一个参数叫page,由此我们可以推断出这个page应该就是第几页的意思。接下来网站的搜索关键词图片的显示方法我们就能够掌握了,就是通过query参数传递搜索内容,per_page是每页显示的图片数,page是第几页,之后的事情就是寻找每个图片的连接地址即可(我没有使用re表达式来查找图片链接的地址,因为不管什么方法都需要亲自去preview里面找图片对应的标签名称才可以,所以我直接自己将结构解开了一下),接下来我们还在这里点击Payload旁边的Preview标签
发现它新增了一个参数叫page,由此我们可以推断出这个page应该就是第几页的意思。接下来网站的搜索关键词图片的显示方法我们就能够掌握了,就是通过query参数传递搜索内容,per_page是每页显示的图片数,page是第几页,之后的事情就是寻找每个图片的连接地址即可(我没有使用re表达式来查找图片链接的地址,因为不管什么方法都需要亲自去preview里面找图片对应的标签名称才可以,所以我直接自己将结构解开了一下),接下来我们还在这里点击Payload旁边的Preview标签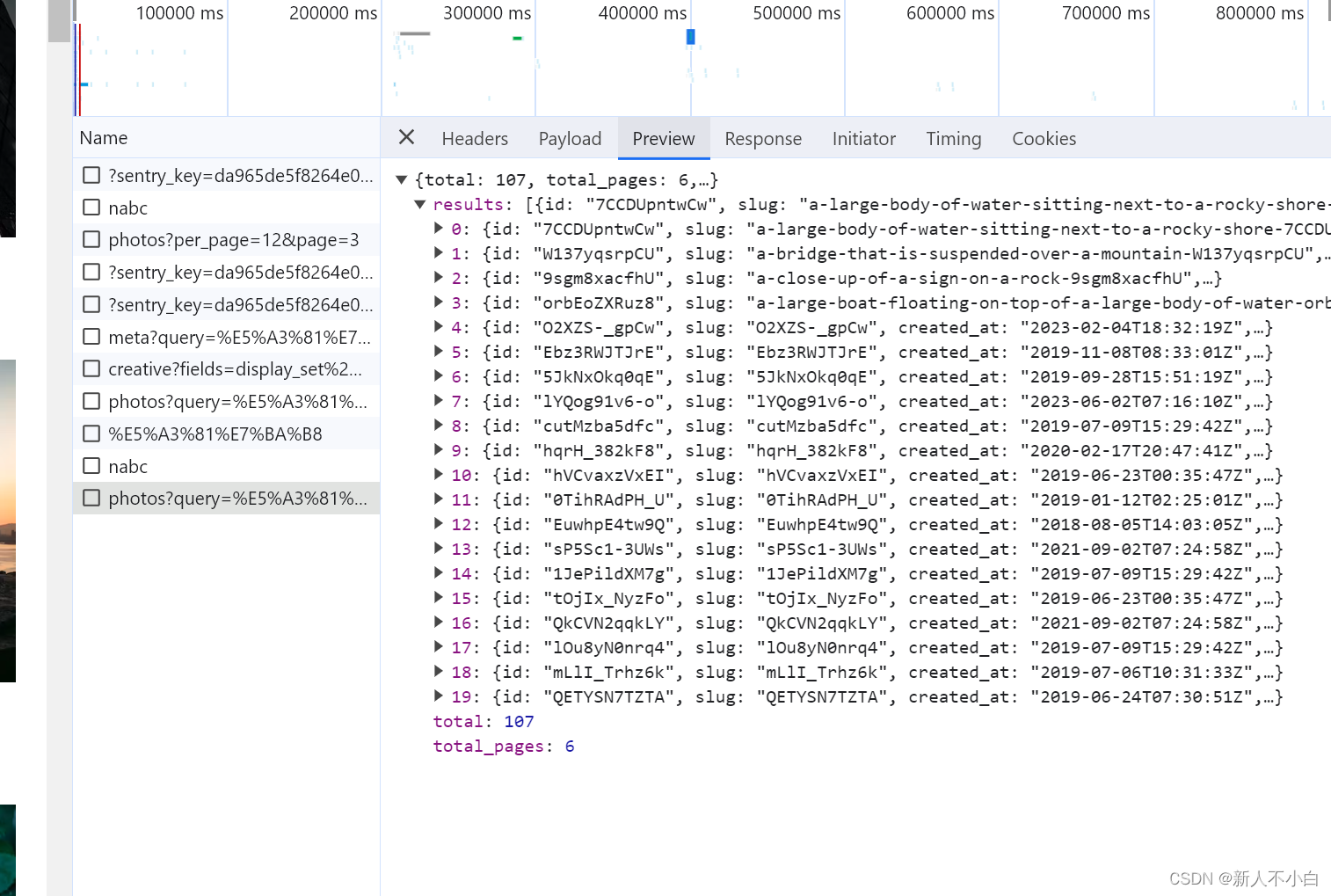 会发现,这里显示一个results数据,里面是20条信息,这恰好也应对了我们之前推断的per_page参数是图片个数的猜想。之后打开其中一个图片观察到,在每个代号的里面都有一个urls数据,其中有很多条链接
会发现,这里显示一个results数据,里面是20条信息,这恰好也应对了我们之前推断的per_page参数是图片个数的猜想。之后打开其中一个图片观察到,在每个代号的里面都有一个urls数据,其中有很多条链接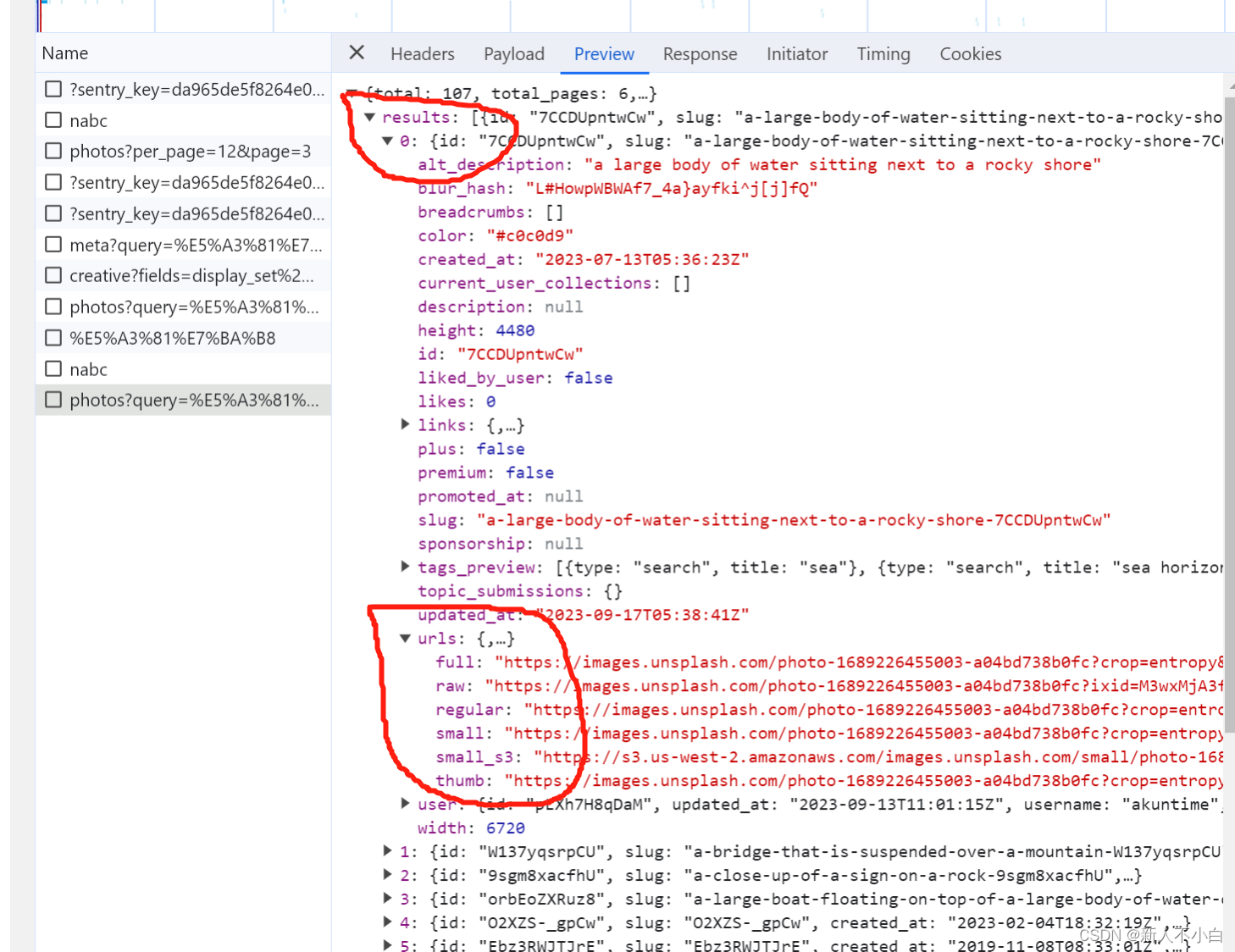 根据我山顶洞人般的英语推测,这个full应该是完整图片,raw是原图,small是小图,thumb是预览图,因为我之前说这是个国外的网站,所以我这次爬的是small图(我第一次爬的是full图,速度慢到我以为我的程序有bug)。将这些找完之后就可以愉快的写程序啦
根据我山顶洞人般的英语推测,这个full应该是完整图片,raw是原图,small是小图,thumb是预览图,因为我之前说这是个国外的网站,所以我这次爬的是small图(我第一次爬的是full图,速度慢到我以为我的程序有bug)。将这些找完之后就可以愉快的写程序啦 -
代码部分
首先是进行创建虚拟请求访问网址,这是爬虫最基础的东西,之后我们还需要三个参数,关键词、每页数量和页数。之后按照上面找好的位置进行每个图片链接的列表化# 图片网站网址 # 通过网站ajax请求(XHR-XMLHttpRequest)中的Payload得知 # 网站参数 query为关键词 per_page为每页的图片数量 page为第几页 url = 'https://unsplash.com/napi/search/photos?query=' + category + '&per_page=' + str(n) + '&page=' + str(i) # 写网址标头模拟浏览器防止被禁止访问 # 内容从浏览器检查网站ajax请求中Headers中取得 # User-Agent, Referer对于程序模拟浏览器来说比较重要 headers = { 'Accept-Encoding': 'gzip, deflate, br', 'Accept-Language': 'en-US', 'Referer': 'https://unsplash.com/', 'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) ' 'Chrome/117.0.0.0 Safari/537.36' } # 获取网页信息 imgs = requests.get(url, headers) # 网页信息转为json数据 jd = json.loads(imgs.text) # 通过阅读网站ajax请求中的preview标签内容 # 确定网址的所在地为results->urls->full/raw/small # 将json数据解开一层 jd = jd['results'] # 网页中图片网址列表 imgs_url = [] # 保存每个图片的网址 for j in jd: # 网址中各个图片的链接都在urls下 j = j['urls'] # 网站中有三种链接,full/raw/small # 取最小的图片链接下载(因为这是国外网站,图片太大下载很慢) imgs_url.append(j['small'])之后就是利用urlretrieve下载图片的过程,这里我的文件名称filepath是用参数的方式传递过来的
# 利用urlretrieve循环下载图片 for imgs_url in imgs_url: # 输出正在下载第几张图片 print('*****' + str(m) + '.jpg *****' + ' Downloading...') # 使用urlretrieve下载图片,以m.jpg命名 urllib.request.urlretrieve(imgs_url, filepath + str(m) + '.jpg') # 图片名称变量m递增 m += 1之后再加亿些细节,程序就可以跑起来啦 ,下面是完整的代码:
import json import requests import urllib.request def find_max_factor(n): """ 计算每页的图片数量 :param n:需要下载的图片总数量 :return:每页图片数量 """ # 从总数量的二分之一开始到2,倒序寻找最大因数 for i in range(int(n / 2), 1, -1): # 若为因数则退出 if n % i == 0: return i # 若寻找到2都没有最大因数,则其没有因数(为质数) return n def get_unsplash_imag(category, img_num, filepath): """ 根据信息从网页下载图片 :param category:搜索关键词类型 :param img_num:下载图片数量 :param filepath:下载路径 :return:null """ # 图片名称递增变量 m = 1 # 算出每页的图片数量 n = find_max_factor(img_num) # 计算需要多少页并循环下载每一页的图片 for i in range(1, int(img_num / n) - 1): # 图片网站网址 # 通过网站ajax请求(XHR-XMLHttpRequest)中的Payload得知 # 网站参数 query为关键词 per_page为每页的图片数量 page为第几页 url = 'https://unsplash.com/napi/search/photos?query=' + category + '&per_page=' + str(n) + '&page=' + str(i) # 写网址标头模拟浏览器防止被禁止访问 # 内容从浏览器检查网站ajax请求中Headers中取得 # User-Agent, Referer对于程序模拟浏览器来说比较重要 headers = { 'Accept-Encoding': 'gzip, deflate, br', 'Accept-Language': 'en-US', 'Referer': 'https://unsplash.com/', 'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) ' 'Chrome/117.0.0.0 Safari/537.36' } # 获取网页信息 imgs = requests.get(url, headers) # 网页信息转为json数据 jd = json.loads(imgs.text) # 通过阅读网站ajax请求中的preview标签内容 # 确定网址的所在地为results->urls->full/raw/small # 将json数据解开一层 jd = jd['results'] # 网页中图片网址列表 imgs_url = [] # 保存每个图片的网址 for j in jd: # 网址中各个图片的链接都在urls下 j = j['urls'] # 网站中有三种链接,full/raw/small # 取最小的图片链接下载(因为这是国外网站,图片太大下载很慢) imgs_url.append(j['small']) # 利用urlretrieve循环下载图片 for imgs_url in imgs_url: # 输出正在下载第几张图片 print('*****' + str(m) + '.jpg *****' + ' Downloading...') # 使用urlretrieve下载图片,以m.jpg命名 urllib.request.urlretrieve(imgs_url, filepath + str(m) + '.jpg') # 图片名称变量m递增 m += 1 # 下载完成 print('Download complete!') # 程序入口 # 获取下载要求信息 cate = input('请输入关键词:') num = eval(input('输入需要下载的图片数量:')) path = input('输入图片保存位置(输入已存在的文件夹):') # 处理文件路径问题 if path[-1] != '/': path = path + '/' # 执行下载方法 get_unsplash_imag(cate, int(num), path)这下心里的石头终于落地了,作业一交就完事,其实最好爬的还是百度图片,但是现在怎么也访问不到了,不知道是不是我自己的问题,希望这篇文章可以帮助到和我有一样问题的朋友们!
















 3925
3925











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











