







网络小说在当今社会的需求日益增长,这可以归因于几个原因。首先,网络小说提供了丰富多样的题材和故事情节,满足了人们对娱乐和阅读的需求。不同类型的读者可以在网络小说中找到自己感兴趣的内容,包括玄幻、仙侠、都市、历史等各种题材。网络小说的广泛选择使读者能够根据个人喜好和兴趣进行选择,而且更新速度快,方便读者持续获取新的阅读材料。
其次,网络小说的便捷性也是其受欢迎的原因之一。人们可以通过电脑、手机、平板等设备随时随地访问网络小说平台,无需携带实体书籍。这使得读者可以在闲暇时间、旅途中或等待他人时轻松阅读,提高了阅读的便利性和灵活性。
然而,一些网络小说平台的收费方式确实存在一些不合理性。一方面,一些平台对网络小说的阅读设置了付费门槛,要求读者购买VIP会员或使用付费阅读币才能获取完整的内容,抑或有些平台有着铺天盖地的广告,这种付费限制对于一些经济条件较差或不愿意花费过多金钱的读者来说可能是一种不公平的对待,限制了他们对阅读的权利。
另一方面,一些平台对网络小说的定价存在着不合理性。有些平台收取过高的费用,使得读者需要支付较高的费用才能获取到网络小说的内容。对于一些热门作品,平台可能会采取分章付费的方式,迫使读者不得不多次购买,增加了读者的经济负担。这种不合理的收费模式可能会影响读者的阅读体验,甚至导致一些读者转向非法途径获取网络小说,从而损害了作家和平台的利益。
因而这里提供一个基于selenium的网络小说爬取项目,可以爬取小说并保存到本地,项目可以提供用户自由选择的小说,用户可以根据自己的喜好和兴趣下载感兴趣的小说。这种自由度使得用户能够根据个人偏好选择他们想要阅读的内容,并且无需依赖特定的平台或付费机制。
使用者可以自由将爬取的txt文件通过(eg.微信阅读等软件)导入到本地并阅读
当然,在进行任何网络爬取项目之前,需要了解并遵守相关法律法规以及网站的使用条款。同时,也要尊重作者和平台的权益,支持他们的创作和运营。如果想要提供免费小说阅读的平台,可以考虑与作者和平台合作,获取合法的授权,并通过合理的合作方式提供服务。
导入项目相关模块
from selenium.webdriver.common.by import By
from selenium import webdriver
from selenium.webdriver.common.keys import Keys
#selenium相关模块
import time
import multiprocessing
#多进程模块
定义爬虫主函数
def pa(url,ci,way,content,name):
driver = webdriver.Chrome()
driver.implicitly_wait(10)#隐式等待
driver.get(url)
for i in range(ci):
response = driver.find_elements(way, content)
textt = ''
for response1 in response:
text = response1.text
textt += text + '\n'
with open(f'{name}.txt',mode='a+',encoding='utf-8') as f:
f.write(f'第{i+1}章' + '\n\n')
f.write(textt)
print(f'第{i+1}章')
try:
driver.find_element(By.PARTIAL_LINK_TEXT, '下一章').click()
except:
driver.find_element(By.PARTIAL_LINK_TEXT, '下一页').click()
time.sleep(5)
driver.quit()此函数用于打开指定的网页,根据指定的元素定位方式和内容,获取指定数量的章节内容,并将其保存到以指定名称命名的文本文件中。
def pa(url, ci, way, content, name)::定义了一个名为pa的函数,接受5个参数:url表示目标网页的URL地址,ci表示要爬取的章节数量,way表示定位元素的方式,content表示定位元素的内容,name表示保存文件的名称。
driver = webdriver.Chrome():创建一个Chrome浏览器的实例,用于模拟用户的浏览操作。
driver.implicitly_wait(10):设置隐式等待时间,即最长等待10秒,用于在获取网页元素时等待页面加载完成。
driver.get(url):通过浏览器访问指定的url地址。
for i in range(ci)::使用循环遍历需要爬取的章节数量。
response = driver.find_elements(way, content):使用way和content定位网页中的元素,返回一个元素列表。
textt = '':初始化一个空字符串变量textt,用于存储爬取的文本内容。
for response1 in response::遍历每个获取到的元素。
text = response1.text:获取元素的文本内容,并将其赋值给text变量。
textt += text + '\n':将获取到的文本内容拼接到textt变量中,并添加换行符。
with open(f'{name}.txt', mode='a+', encoding='utf-8') as f::使用name变量作为文件名,以追加模式打开一个文本文件,设置编码为utf-8。
f.write(f'第{i+1}章' + '\n\n'):向文件中写入当前章节的标题。
f.write(textt):将章节内容写入文件。
print(f'第{i+1}章'):打印当前爬取的章节信息。
try::尝试执行下一步操作。
driver.find_element(By.PARTIAL_LINK_TEXT, '下一章').click():在当前网页中定位包含文本'下一章'的链接元素,并进行点击操作。
except::如果上一步操作失败,则执行以下操作。
driver.find_element(By.PARTIAL_LINK_TEXT, '下一页').click():在当前网页中定位包含文本'下一页'的链接元素,并进行点击操作。
time.sleep(5):暂停程序执行5秒,以便等待页面加载完成。
driver.quit():关闭浏览器实例,释放资源。
多进程同时爬取多本小说
if __name__ == '__main__':
multiprocessing.Process(target=pa,
kwargs={'url': 'http://www.sikushu.com/html/71/71250/35017804.html',
'ci': 869,
'way' : By.ID,
'content' : 'content',
'name' : '惊悚:因为担心不优雅而过度变态'}).start()
multiprocessing.Process(target=pa,
kwargs={'url': 'http://www.028huiyilu.com/b/362/362831/1597560/',
'ci': 1055,
'way' : By.ID,
'content' : 'posterror',
'name' : '无所谓'}).start()
# multiprocessing.Process(target=pa,
# kwargs={'url': 'https://www.biqugeabc.com/read/635439/204414.html',
# 'ci': 483,
# 'way' : By.CLASS_NAME,
# 'content' : 'text_row_txt',
# 'name' : '传说管理局'}).start()输入相对应的内容,从而爬取想要的小说即可,需要几本就同时爬取几本即可
注意:selenium的配置
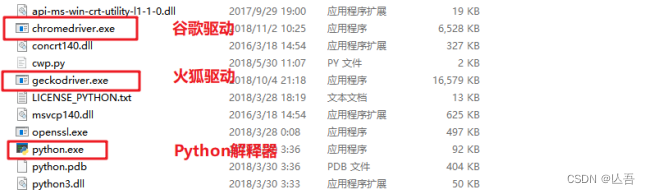
首先在电脑上下载浏览器,浏览器版本不宜过新,Selenium支持多种浏览器,最常见的就是火狐和谷歌浏览器
之后要配置浏览器驱动,Selenium才能操纵浏览器
火狐驱动下载地址:http://npm.taobao.org/mirrors/geckodriver/
谷歌驱动下载地址:CNPM Binaries Mirror
将下载好的浏览器驱动解压,将解压出的 `exe` 文件放到Python的安装目录下,也就是和`python.exe`同目录即可
Tips:
若爬取的小说有多行空行,可以:
import pandas as pd
import numpy as np
with open("小说名.txt", "r",encoding='utf-8') as f2:
str = f2.read()
str1 = str.replace('\n\n', '\n')
with open("new.txt", "w") as f:
f.write(str1)用该方式替换空行
最后附上完整代码
from selenium.webdriver.common.by import By
from selenium import webdriver
from selenium.webdriver.common.keys import Keys
import time
import multiprocessing
def pa(url,ci,way,content,name):
driver = webdriver.Chrome()
driver.implicitly_wait(10)
driver.get(url)
for i in range(ci):
# bt = driver.find_element(By.CLASS_NAME, 'content')
response = driver.find_elements(way, content)
# btt = bt.text
textt = ''
for response1 in response:
text = response1.text
textt += text + '\n'
with open(f'{name}.txt',mode='a+',encoding='utf-8') as f:
f.write(f'第{i+1}章' + '\n\n')
f.write(textt)
print(f'第{i+1}章')
try:
driver.find_element(By.PARTIAL_LINK_TEXT, '下一章').click()
except:
driver.find_element(By.PARTIAL_LINK_TEXT, '下一页').click()
time.sleep(5)
driver.quit()
if __name__ == '__main__':
multiprocessing.Process(target=pa,
kwargs={'url': 'http://www.sikushu.com/html/71/71250/35017804.html',
'ci': 869,
'way' : By.ID,
'content' : 'content',
'name' : '惊悚:因为担心不优雅而过度变态'}).start()
multiprocessing.Process(target=pa,
kwargs={'url': 'http://www.028huiyilu.com/b/362/362831/1597560/',
'ci': 1055,
'way' : By.ID,
'content' : 'posterror',
'name' : '无所谓'}).start()
# multiprocessing.Process(target=pa,
# kwargs={'url': 'https://www.biqugeabc.com/read/635439/204414.html',
# 'ci': 483,
# 'way' : By.CLASS_NAME,
# 'content' : 'text_row_txt',
# 'name' : '传说管理局'}).start()
















 532
532

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









