






 本文介绍了逻辑回归的基本概念,包括线性模型、回归思想、Sigmoid函数的作用以及极大似然法的应用。还详细展示了如何通过梯度上升法实现逻辑回归,并讨论了该方法的优缺点,如处理非线性关系和多类别问题的局限性。
本文介绍了逻辑回归的基本概念,包括线性模型、回归思想、Sigmoid函数的作用以及极大似然法的应用。还详细展示了如何通过梯度上升法实现逻辑回归,并讨论了该方法的优缺点,如处理非线性关系和多类别问题的局限性。
一、logistic回归
1. 线性模型与回归
线性模型:
回归:对现有的一些数据点,用一条直线对这些点进行拟合,该条直线为最佳拟合直线,拟合的过程称为回归。
线性回归的目的:尽可能准确地预测实值输出标记。
,使得
2. logistic回归的基本思想
Logistic回归是一种用于处理二分类问题的统计学习方法。Logistic回归的基本思想是通过一个或多个特征的线性组合来预测输入样本属于某个类别的概率。
3. Sigmoid函数
对于logistic回归,我们需要一个函数,接受所有的输入然后预测出类别。单位阶跃函数虽然能够清楚地将0和1分类,但在从0到1的过程是瞬间跃迁的,这个过程很难处理,因此,我们需要一种更平滑的曲线来过度从0到1的过程,于是,选择了sigmoid函数。目的是将线性输出映射到一个概率范围,通常是0到1之间。Sigmoid函数是一种S形函数,其数学表达式为:
函数图像为
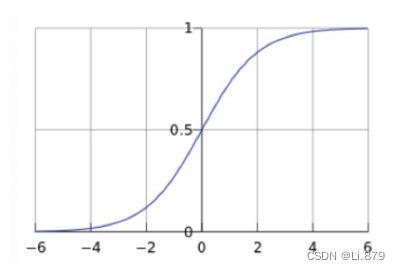
其中,z是线性组合的结果(输入特征的加权和加上偏置项),而 是映射到0到1之间的概率值。这个概率可以被解释为样本属于正类的概率,而1减去这个概率即为样本属于负类的概率。
在图像中,当z=0时,sigmoid函数值为0.5,随着z的增大,sigmoid的值逼近于1;而随着z的减小,sigmoid的值逼近于0。将坐标轴无限放大,也类似一种阶跃函数。这就实现了0和1的分类,并且0到1的过程中是平滑的。
4. 极大似然法
对于0-1型二分布变量,
y=1的概率分布公式定义:P(y=0)=p
y=0的概率分布公式定义:P(y=1)=1-p
那么有:
P(y=1|x,θ)=hθ(x)
P(y=0|x,θ)=1−hθ(x)
两式合并:
P(y|x,θ)=hθ(x)y(1−hθ(x))1-y
其中y的取值只能是0或者1。
得到了y的概率分布函数表达式,就可以用似然函数最大化来求解模型系数θ。
似然函数的代数表达式为:
其中,m为样本的个数
为了方便求解,使用极大似然法,对数似然函数取反即为我们的损失函数J(θ)。
二、Logistic回归实现
1. 数据处理
数据集中包含两个特征,读取数据
def loadDataSet():
dataMat = []
labelMat = []
fr = open(filename)
for line in fr.readlines():
lineArr = line.strip().split()
dataMat.append([1.0, float(lineArr[0]), float(lineArr[1])])
labelMat.append(int(lineArr[2]))
return dataMat,labelMat2. 定义sigmoid函数
def sigmoid(inX):
return 1.0/(1+exp(-inX))3. 梯度上升法求参数
def gradAscent(dataMat, labelMat):
dataMatrix=mat(dataMat)
classLabels=mat(labelMat).transpose()
m,n = shape(dataMatrix)
alpha = 0.001
maxCycles = 500
weights = ones((n,1))
for k in range(maxCycles):
h = sigmoid(dataMatrix*weights)
error = (classLabels - h)
weights = weights + alpha * dataMatrix.transpose()* error
return weights4. 完整实验代码
import numpy as np
import matplotlib.pyplot as plt
filename='C:/Desktop/LogisticTest.txt'
def loadDataSet():
dataMat = []
labelMat = []
fr = open(filename)
for line in fr.readlines():
lineArr = line.strip().split()
dataMat.append([1.0, float(lineArr[0]), float(lineArr[1])]) #
labelMat.append(int(lineArr[2]))
return dataMat,labelMat
def sigmoid(inX):
return 1.0/(1+exp(-inX))
def gradAscent(dataMat, labelMat):
dataMatrix=mat(dataMat)
classLabels=mat(labelMat).transpose()
m,n = shape(dataMatrix)
alpha = 0.001
maxCycles = 500
weights = ones((n,1))
for k in range(maxCycles):
h = sigmoid(dataMatrix*weights)
error = (classLabels - h)
weights = weights + alpha * dataMatrix.transpose()* error
return weights
def plotBestFit(weights):
import matplotlib.pyplot as plt
dataMat,labelMat=loadDataSet()
dataArr = array(dataMat)
n = shape(dataArr)[0]
xcord1 = []; ycord1 = []
xcord2 = []; ycord2 = []
for i in range(n):
if int(labelMat[i])== 1:
xcord1.append(dataArr[i,1])
ycord1.append(dataArr[i,2])
else:
xcord2.append(dataArr[i,1])
ycord2.append(dataArr[i,2])
fig = plt.figure()
ax = fig.add_subplot(111)
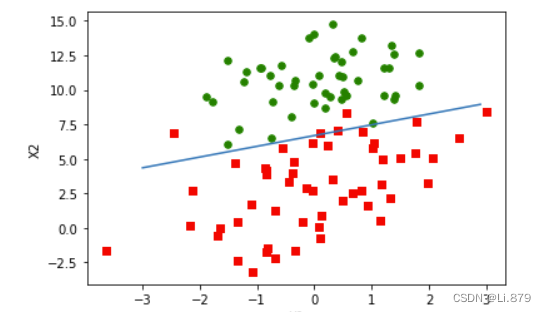
ax.scatter(xcord1, ycord1, s=30, c='red', marker='s')
ax.scatter(xcord2, ycord2, s=30, c='green')
x = arange(-3.0, 3.0, 0.1)
y = (-weights[0]-weights[1]*x)/weights[2]
ax.plot(x, y)
plt.xlabel('X1')
plt.ylabel('X2')
plt.show()
def main():
dataMat, labelMat = loadDataSet()
weights=gradAscent(dataMat, labelMat).getA()
plotBestFit(weights)
if __name__=='__main__':
main()
运行结果:
三、总结
1. logistic回归的优缺点
优点:
-
简单高效: Logistic回归是一种简单而高效的分类算法。模型相对简单,易于实现和理解,适用于二分类问题。
-
适用性广泛: Logistic回归广泛用于医学、社会科学、经济学等领域,特别使用于小样本数据集。
- 可解释性强: 模型的输出可以被解释为概率,对结果的解释直观,有助于理解预测的意义。
- 不容易过拟合: 在数据不是很复杂的情况下,Logistic回归很少过拟合,因为它对高维数据的需求相对较低。
缺点:
-
处理非线性关系困难: Logistic回归假设特征之间是线性关系,因此在处理非线性关系时表现较差。如果数据包含复杂的非线性关系,其他模型可能更适合。
-
对异常值敏感: Logistic回归对异常值比较敏感,异常值的存在可能影响模型的性能。
-
不能处理复杂的特征关系: 由于其线性假设,Logistic回归不能很好地处理特征之间复杂的非线性关系,因此在处理高度复杂数据时可能不如其他模型。
-
依赖特征工程: 对于模型的性能,特征工程的质量至关重要。需要仔细选择和设计特征,以提高模型的预测能力。
-
多类别问题处理困难: Logistic回归本质上是二分类算法。

















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









