






一、我是如何理解RAGFlow的
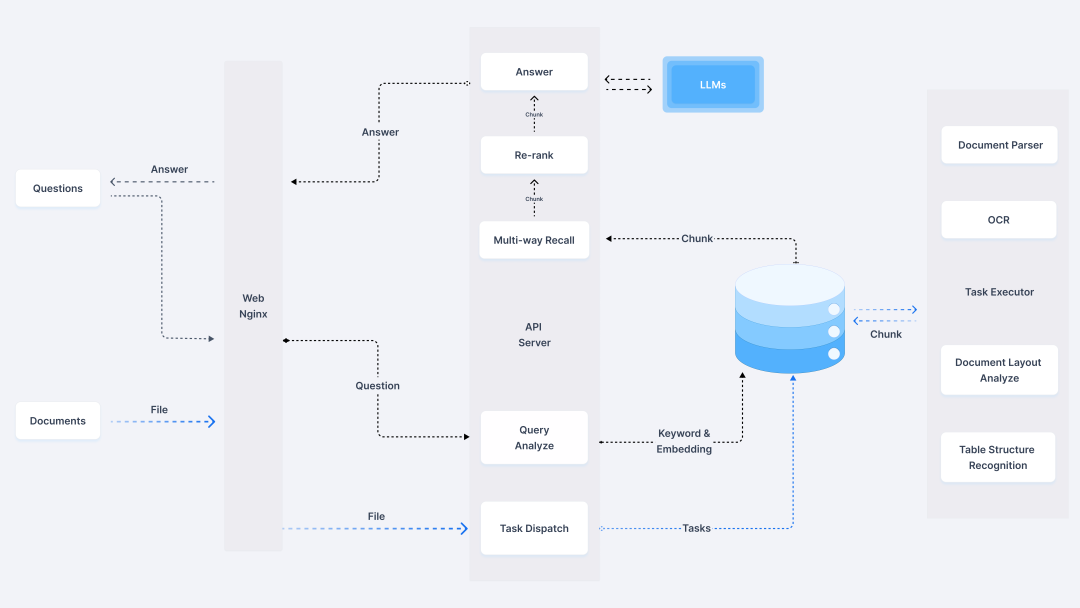
作为一款基于深度文档理解的开源RAG引擎,RAGFlow在我实际使用中展现了其独特的优势。它通过混合检索(关键词+向量+语义)和多模态解析能力,能够处理PDF、扫描件、表格等复杂格式文档,解决了传统RAG工具对非结构化数据解析精度不足的问题。例如,我曾上传一份包含扫描合同和Excel表格的压缩包,RAGFlow不仅准确提取了文字和表格结构,还能在后续问答中引用具体条款。
核心特性:
-
深度文档解析:支持OCR、表格识别、代码块提取,甚至影印件中的倾斜文字矫正;
-
混合检索优化:结合Elasticsearch和自研算法实现多路召回+重排序,显著提升答案准确性;
-
工作流编排:可自定义解析→检索→生成流程,例如设定“若置信度低于阈值则触发人工审核”;
-
多模态支持:实验性功能已支持音频文件转文字并生成摘要;
-
可解释性:生成答案时自动标注来源段落,便于溯源验证。
二、我的部署实践(以Ubuntu 22.04为例)
步骤1:环境准备
安装Docker及Compose(需版本≥24.0.0和v2.26.1) sudo apt-get install docker.io sudo curl -L "https://github.com/docker/compose/releases/download/v2.26.1/docker-compose-$(uname -s)-$(uname -m)" -o /usr/local/bin/docker-compose sudo chmod +x /usr/local/bin/docker-compose 配置系统参数(防止ES启动失败) sudo sysctl -w vm.max_map_count=262144
步骤2:获取项目并启动
git clone https://github.com/infiniflow/ragflow cd ragflow/docker 修改.env文件(关键配置项) RAGFLOW_VERSION=latest # 指定版本,如v0.8.1 ELASTICSEARCH_HTTP_PORT=9201 # 避免与其他ES实例冲突 构建并启动容器 docker-compose up -d
注意点:
-
首次启动需下载约9GB的镜像,建议使用国内镜像加速;
-
若Redis端口冲突(常见于同时运行Dify),可修改
docker-compose.yml中的6379:6379为6380:6379; -
访问
http://localhost:80完成初始注册,建议使用强密码(尽管是本地部署)。
步骤3:模型配置
在Web界面中:
-
进入“模型管理”,填写本地LLM(如Ollama)地址为
http://host.docker.internal:11434; -
选择Embedding模型(推荐bge-large-zh-v1.5),测试连接状态。
三、与Dify的对比体验
在同时使用RAGFlow和Dify后,我发现两者的定位差异显著:
|
维度
|
RAGFlow
|
Dify
|
| — | — | — |
|
核心能力
|
文档解析精度高,答案可溯源
|
工作流编排灵活,支持多模型协作
|
|
使用场景
|
法律合同审查、医疗报告分析
|
智能客服、自动化报表生成
|
|
开发门槛
|
需调整解析参数和检索策略
|
可视化拖拽,适合无代码基础用户
|
|
扩展性
|
通过插件支持私有数据源
|
开放API,可集成CRM等外部系统
|
典型案例对比:
-
当我需要批量解析扫描版财务报表时,RAGFlow的表格识别准确率比Dify高出约30%;
-
但若想快速搭建一个集成GPT-4和Stable Diffusion的多模态应用,Dify的可视化流程设计器更高效。
四、优化建议
-
硬件资源:部署后监控显示,8核CPU+32GB内存可支撑20并发问答;
-
知识库分片:按业务类型拆分知识库(如“财务制度库”和“技术文档库”),提升检索速度;
-
安全加固:通过Nginx添加HTTPS和IP白名单,避免内网暴露风险。
如需更完整的配置案例,可参考官方文档或社区讨论。总体而言,RAGFlow是企业级文档智能处理的首选工具,而Dify更适合需要快速迭代的通用AI应用场景。
AI大模型学习福利
作为一名热心肠的互联网老兵,我决定把宝贵的AI知识分享给大家。 至于能学习到多少就看你的学习毅力和能力了 。我已将重要的AI大模型资料包括AI大模型入门学习思维导图、精品AI大模型学习书籍手册、视频教程、实战学习等录播视频免费分享出来。

大模型&AI产品经理如何学习
求大家的点赞和收藏,我花2万买的大模型学习资料免费共享给你们,来看看有哪些东西。
1.学习路线图

第一阶段: 从大模型系统设计入手,讲解大模型的主要方法;
第二阶段: 在通过大模型提示词工程从Prompts角度入手更好发挥模型的作用;
第三阶段: 大模型平台应用开发借助阿里云PAI平台构建电商领域虚拟试衣系统;
第四阶段: 大模型知识库应用开发以LangChain框架为例,构建物流行业咨询智能问答系统;
第五阶段: 大模型微调开发借助以大健康、新零售、新媒体领域构建适合当前领域大模型;
第六阶段: 以SD多模态大模型为主,搭建了文生图小程序案例;
第七阶段: 以大模型平台应用与开发为主,通过星火大模型,文心大模型等成熟大模型构建大模型行业应用。
2.视频教程
网上虽然也有很多的学习资源,但基本上都残缺不全的,这是我自己整理的大模型视频教程,上面路线图的每一个知识点,我都有配套的视频讲解。


(都打包成一块的了,不能一一展开,总共300多集)
因篇幅有限,仅展示部分资料,需要点击下方图片前往获取
3.技术文档和电子书
这里主要整理了大模型相关PDF书籍、行业报告、文档,有几百本,都是目前行业最新的。

4.LLM面试题和面经合集
这里主要整理了行业目前最新的大模型面试题和各种大厂offer面经合集。

👉学会后的收获:👈
• 基于大模型全栈工程实现(前端、后端、产品经理、设计、数据分析等),通过这门课可获得不同能力;
• 能够利用大模型解决相关实际项目需求: 大数据时代,越来越多的企业和机构需要处理海量数据,利用大模型技术可以更好地处理这些数据,提高数据分析和决策的准确性。因此,掌握大模型应用开发技能,可以让程序员更好地应对实际项目需求;
• 基于大模型和企业数据AI应用开发,实现大模型理论、掌握GPU算力、硬件、LangChain开发框架和项目实战技能, 学会Fine-tuning垂直训练大模型(数据准备、数据蒸馏、大模型部署)一站式掌握;
• 能够完成时下热门大模型垂直领域模型训练能力,提高程序员的编码能力: 大模型应用开发需要掌握机器学习算法、深度学习框架等技术,这些技术的掌握可以提高程序员的编码能力和分析能力,让程序员更加熟练地编写高质量的代码。

1.AI大模型学习路线图
2.100套AI大模型商业化落地方案
3.100集大模型视频教程
4.200本大模型PDF书籍
5.LLM面试题合集
6.AI产品经理资源合集
👉获取方式:
😝有需要的小伙伴,可以保存图片到wx扫描二v码免费领取【保证100%免费】🆓



















 6053
6053

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











