







1. Focal Loss函数概念解释
Focal loss 的作用是解决类别不平衡问题和难易样本问题。
- 类别不平衡问题: Focal loss 通过平衡因子 α t α_t αt 来调整正负样本的权重,使模型更加关注数量较少的正样本。
- 样本问题: Focal loss 通过聚焦因子 γ \gamma γ来调整难易样本的权重,使模型更加关注难样本。
类别不平衡问题
在一些数据集,正负样本的数量可能存在很大的差异,例如,在图像分类任务中,背景图片的数量可能远远大于目标物体的数量。这种类别不平衡会导致模型过度关注数量较多的负样本,而忽略数量较少的正样本。
难易样本问题
模型更容易学习容易样本,而更难学习难样本。这会导致模型在测试集上的性能下降。
1.1 样本相关
样本:训练集中(或者训练时每个batch中),1张图片就算是1个样本(sample)
标签:训练集中每个样本对应1个标签(label),标签表示该样本是否为猫,我们用
来
y
y
y 表示。标签为1,表示该样本是猫;标签为0,表示该样本不是猫。
正负样本:
- 如果样本对应的标签为1,则该样本为正样本(positive sample)。
- 如果样本对应的标签为0,则该样本为负样本(negative sample)。
难/易分样本:
如果模型很容易就能将其正确分类,那该样本对于模型就是易分样本(置信度高);
如果模型很难将其正确分类,那该样本对于模型就是难分样本(置信度低)。

1.2 损失函数相关
损失:在机器学习模型中,对于每一个样本的预测值与真实值的差称为损失。
损失函数:是一个用来计算损失的函数。它是一个非负实值函数,通常使用L(Y, f(x))来表示。
损失函数作用:度量一个模型进行每一次预测的好坏(即预测值与真实值的差距程度)。差距程度越小,则损失越小,该学习模型越好。
损失函数如何使用:损失函数主要是用在模型的训练阶段。
①在每一个批次的训练数据送入模型后,通过前向传播输出预测值,然后损失函数会计算出预测值与真实值的差异值,即损失值。
②得到损失值后,模型通过反向传播去更新各个参数,来降低真实值与预测值之间的损失,使得模型生成的预测值往真实值靠拢,从而达到学习的目的。
③在训练完该模型后,此时模型通过反向传播后,已经使得每个参数都为最优。所以使用该模型进行预测得到的结果一定是接近真实结果的。
1.3 损失函数分类
分类任务损失:
0-1 loss、熵与交叉熵loss、softmax loss及其变种、KL散度、Hinge loss、Exponential loss、Logistic loss、Focal Loss等待。
回归任务损失:
L1 loss、L2 loss、perceptual loss、生成对抗网络损失、GAN的基本损失、-log D trick、Wasserstein GAN、LS-GAN、Loss-sensitive-GAN等等。
2. 基础函数
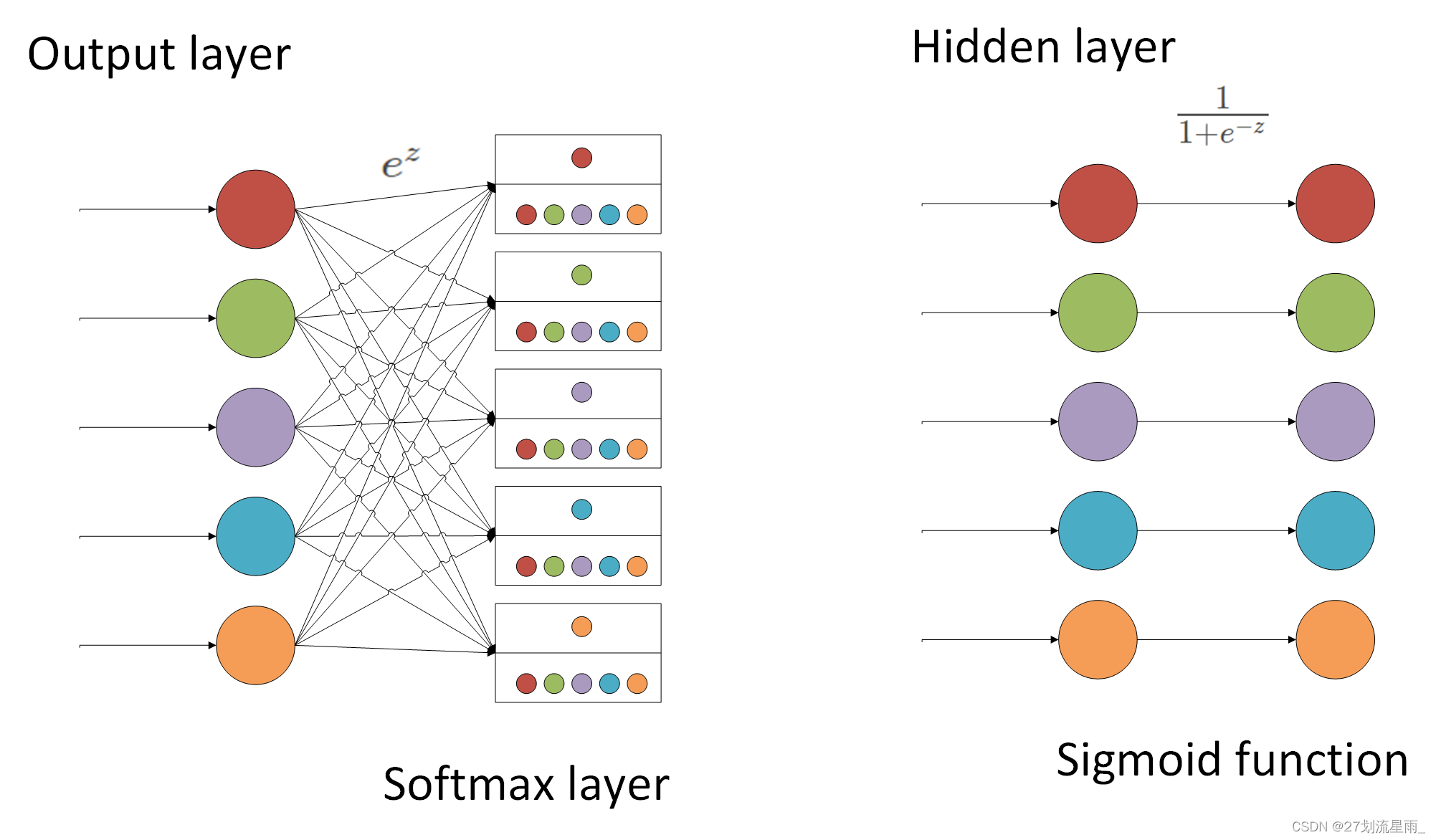
2.1 sigmoid和softmax

1. 输出范围
- Sigmoid: 输出范围是 0 到 1,适合用于二分类任务。
- Softmax: 输出范围是 0 到 1,并且所有元素的概率值之和为 1,适合用于多分类任务。
2. 应用场景
- Sigmoid: 常用于二分类任务,例如图像分类、文本分类等。
- Softmax: 常用于多分类任务,例如图像分类、文本分类等。
3. 计算复杂度
- Sigmoid: 计算复杂度较低。
- Softmax: 计算复杂度较高。
4. 梯度消失问题
- Sigmoid: 在梯度下降过程中,当输入值过大或过小时,可能会出现梯度消失问题。
- Softmax: 不存在梯度消失问题。
5. 总结
| 特征 | Sigmoid | Softmax |
|---|---|---|
| 输出范围 | 0 到 1 | 0 到 1,所有元素之和为 1 |
| 应用场景 | 二分类任务 | 多分类任务 |
| 计算复杂度 | 较低 | 较高 |
| 梯度消失问题 | 存在 | 不存在 |
选择哪种激活函数取决于具体的应用场景和需求。
- 二分类任务: 使用 Sigmoid 函数。
- 多分类任务: 使用 Softmax 函数。
- 计算复杂度要求较高: 使用 Sigmoid 函数。
- 需要避免梯度消失问题: 使用 Softmax 函数。
2.2 分类损失函数
-
二分类交叉熵
在做二分类的任务时,一般是用sigmoid作为最后的激活函数,输出只有一个代表样本为正的概率值p,二分类非正即负,所以样本为负的概率值为1-p。则以sigmoid作为激活函数的二分类任务交叉熵损失的计算公式为:
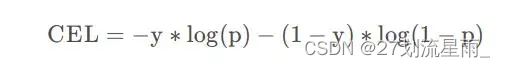
其中y是实际标签,正样本为1,负样本为0,p是sigmoid激活函数的输出值。 -
多分类交叉熵
在做多分类的时候,一般是以softmax作为最后的激活函数的,输出有多个值,对应每个分类的概率值,和为1。则以sofmax作为激活函数的多分类任务的交叉熵损失计算公式为:
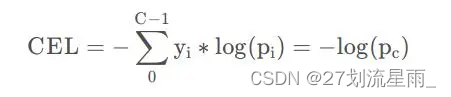
其中p c 表示softmax激活函数输出结果中第c类的对应的值。
简单归纳为: -
二分类用sigmoid,因为只有正负两种情况;
-
多分类用softmax,因为需要将多种类别的概率归一化后来进行运算。
3.Focal Loss原理
3.1 FocalLoss如何调节正负样本权重
二分类问题我们通常使用交叉熵计算Loss,损失函数如下:
C
E
(
p
,
y
)
=
{
−
l
o
g
(
p
)
i
f
y
=
1
−
l
o
g
(
1
−
p
)
i
f
y
=
0
CE(p, y) = \begin{cases} -log(p) & if y=1\\ -log(1-p) & if y=0 \end{cases}
CE(p,y)={−log(p)−log(1−p)ify=1ify=0
其中
C
E
CE
CE是CrossEntropy的缩写,
p
p
p 是预测结果,例如0.8。
y
y
y 是标签值。
假设我们99%的样本都是负样本,那么最终计算出的loss负样本占比极大。要进行调节,很简单,只需要乘个权重就行了。比如:
C
E
(
p
,
y
)
=
{
−
l
o
g
(
p
)
∗
0.9
i
f
y
=
1
−
l
o
g
(
1
−
p
)
∗
0.1
i
f
y
=
0
CE(p, y) = \begin{cases} -log(p)*0.9 & if y=1\\ -log(1-p)*0.1 & if y=0 \end{cases}
CE(p,y)={−log(p)∗0.9−log(1−p)∗0.1ify=1ify=0
我们让正样本和负样本的loss给个9:1的权重就行了。将其0.9写成变量
α
\alpha
α 为:
C
E
(
p
,
y
)
=
{
−
l
o
g
(
p
)
∗
α
i
f
y
=
1
−
l
o
g
(
1
−
p
)
∗
(
1
−
α
)
i
f
y
=
0
CE(p, y) = \begin{cases} -log(p)*\alpha & if y=1\\ -log(1-p)*(1-\alpha) & if y=0 \end{cases}
CE(p,y)={−log(p)∗α−log(1−p)∗(1−α)ify=1ify=0
其中,
α
∈
(
0
,
1
)
\alpha \in (0,1)
α∈(0,1)为超参数。这就是FocalLoss调节正负样本权重的方式.
3.2 FocalLoss如何调节难易样本权重
当我们在训练二分类问题时,经过sigmoid后最终的输出是0到1的概率,表示为正样本的概率是多少。
那假设标签为1的样本:
- 若预测为为0.95,意味该样本是一个比较简单的样本。
- 若预测值为0.65,意味着该样本稍微有点难
- 若预测值为0.28,意味着该样本非常难。
负样本同理。即 预测值距离真值越远,则样本越难。
难样本想要多学习,那就给它的loss分个较大的权重,简单样本易学习,那就给个较小的权重。那我们可以直接用它的难易程度给它分权重嘛,例如:
假设标签为1的样本:
- 若预测为为0.95,意味该样本是一个比较简单的样本。权重为 (1-0.95) = 0.05
- 若预测值为0.65,意味着该样本稍微有点难。权重为 (1-0.65) = 0.35
- 若预测值为0.28,意味着该样本非常难。权重为 (1-0.28) = 0.72
- 按照这个思路,我们就可以得到如下损失函数:
C E ( p , y ) = { − l o g ( p ) ∗ ( 1 − p ) i f y = 1 − l o g ( 1 − p ) ∗ p i f y = 0 CE(p, y) = \begin{cases} -log(p)*(1-p) & if y=1\\ -log(1-p)*p & if y=0 \end{cases} CE(p,y)={−log(p)∗(1−p)−log(1−p)∗pify=1ify=0
你想让简单样本权重更低,难样本权重更高,那么也很简单,只需要加个平方就行了,这样小的会更小,大的会更大。这样我们会得到如下公式:
C
E
(
p
,
y
)
=
{
−
l
o
g
(
p
)
∗
(
1
−
p
)
γ
i
f
y
=
1
−
l
o
g
(
1
−
p
)
∗
p
γ
i
f
y
=
0
CE(p, y) = \begin{cases} -log(p)*(1-p)^\gamma & if y=1\\ -log(1-p)*p^\gamma & if y=0 \end{cases}
CE(p,y)={−log(p)∗(1−p)γ−log(1−p)∗pγify=1ify=0
这样我们就完成了难易样本权重的调节。最后再总结一下参数$\gamma$:
- 当 γ = 0 \gamma=0 γ=0 时,损失函数退化成了原始的CrossEntropy。
- γ \gamma γ 越大,对权重的调节就越狠,反之则越轻。越狠的意思是:容易样本的权重会越低,难样本的权重会越高。
- γ \gamma γ 通常取 2 22
2.3 整合上述过程,完成FocalLoss
整合过程很简单,把
α
\alpha
α 和
γ
\gamma
γ 一块放到公式里就行了,FocalLoss公式如下:
F
L
(
p
,
y
,
α
.
γ
)
=
{
−
l
o
g
(
p
)
∗
α
∗
(
1
−
p
)
γ
i
f
y
=
1
−
l
o
g
(
1
−
p
)
∗
(
1
−
α
)
∗
p
γ
i
f
y
=
0
FL(p, y, \alpha. \gamma) = \begin{cases} -log(p)*\alpha * (1-p)^\gamma & if y=1\\ -log(1-p)*(1-\alpha)*p^\gamma & if y=0 \end{cases}
FL(p,y,α.γ)={−log(p)∗α∗(1−p)γ−log(1−p)∗(1−α)∗pγify=1ify=0
这样写稍显难看,所以我们定义两个新的变量
α
t
\alpha_t
αt 和
p
t
p_t
pt,其中:
α
t
=
{
α
i
f
y
=
1
1
−
α
i
f
y
=
0
\alpha_t = \begin{cases} \alpha &if y=1\\ 1-\alpha &if y=0 \end{cases}
αt={α1−αify=1ify=0
p
t
=
{
p
i
f
y
=
1
1
−
p
i
f
y
=
0
p_t = \begin{cases} p &if y=1\\ 1-p &if y=0 \end{cases}
pt={p1−pify=1ify=0
那么FocalLoss就可以写成如下的最终公式:
F
L
(
p
t
)
=
−
α
t
(
1
−
p
t
)
γ
l
o
g
(
p
t
)
FL(p_t) = -\alpha_t(1-p_t)^\gamma log(p_t)
FL(pt)=−αt(1−pt)γlog(pt)
2.4 pytorch代码实现
class FocalLoss(nn.Module):
'''
loss_fcn:损失函数
alpha: 平衡因子,调整正负样本的权重,使模型更加关注数量较少的正样本
gamma:聚焦因子 γ 来调整难易样本的权重,使模型更加关注难样本
```
def __init__(self, loss_fcn, gamma=1.5, alpha=0.25):
super(FocalLoss, self).__init__()
self.loss_fcn = loss_fcn # must be nn.BCEWithLogitsLoss()
self.gamma = gamma
self.alpha = alpha
self.reduction = loss_fcn.reduction
self.loss_fcn.reduction = 'none' # required to apply FL to each element
def forward(self, pred, true):
loss = self.loss_fcn(pred, true) # 预测值和真实值
# 使用 sigmoid 函数将预测值转换为概率值。sigmoid 函数将所有实数映射到 0 到 1 之间的值。
pred_prob = torch.sigmoid(pred) # prob from logits
#这行代码计算预测正确的概率 p_t。对于正确的预测,true 为 1,p_t =pred_prob
#对于错误的预测,true 为 0,p_t = 1 - pred_prob
p_t = true * pred_prob + (1 - true) * (1 - pred_prob)
#这行代码计算 alpha 因子。alpha 因子用于平衡正负样本的权重。当 true 为 1 时,
#alpha 因子等于 self.alpha,否则等于 1 - self.alpha。
alpha_factor = true * self.alpha + (1 - true) * (1 - self.alpha)
modulating_factor = (1.0 - p_t) ** self.gamma
# FL = loss * alpha_factor * modulating_factor
loss *= alpha_factor * modulating_factor
if self.reduction == 'mean':
return loss.mean()
elif self.reduction == 'sum':
return loss.sum()
else: # 'none'
return loss
# 二分类交叉熵函数
class BCEBlurWithLogitsLoss(nn.Module):
# BCEwithLogitLoss() with reduced missing label effects.
def __init__(self, alpha=0.05):
super(BCEBlurWithLogitsLoss, self).__init__()
self.loss_fcn = nn.BCEWithLogitsLoss(reduction='none') # must be nn.BCEWithLogitsLoss()
self.alpha = alpha
def forward(self, pred, true):
loss = self.loss_fcn(pred, true)
pred = torch.sigmoid(pred) # prob from logits
dx = pred - true # reduce only missing label effects
# dx = (pred - true).abs() # reduce missing label and false label effects
alpha_factor = 1 - torch.exp((dx - 1) / (self.alpha + 1e-4))
loss *= alpha_factor
return loss.mean()
参考链接:
FocalLoss原理通俗解释及其二分类和多分类场景下的原理与实现
彻底搞懂python super函数的作用















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









