







 本文介绍了神经网络中的计算图理论,展示了如何通过链式法则进行自动微分,并详细阐述了反向传播算法的工作原理,包括前向传播、误差计算、反向传播以及权重更新,以提升大规模数据处理的效率。
本文介绍了神经网络中的计算图理论,展示了如何通过链式法则进行自动微分,并详细阐述了反向传播算法的工作原理,包括前向传播、误差计算、反向传播以及权重更新,以提升大规模数据处理的效率。
目录
前言
上一篇我们探讨了神经网络的学习过程,即神经网络的前向传播。在计算梯度时采用随机梯度下降法;但是随着参数数量的不断增长,简单的逐个逐次计算参数梯度效率十分低下,没有充分利用关联数据和中间结果,忽略了参数梯度之间的关联。本篇我们一起来了解误差反向传播算法,反向传播算法具有高效、并行计算、适应大规模数据、适用于多层网络以及学习复杂的非线性关系等优势,它是目前应用最广泛的神经网络训练算法之一。
一、计算图
神经网络具有复杂的结构,计算过程同样十分复杂。但究其根源,都可以概括为加法与乘法的排列组合。计算图就是通过图形化手段,将复杂的计算过程逐步分解为适合计算机并行计算的结构。
计算图由节点(node)和边(edge)组成,每个节点代表一个计算步骤,边代表数据流向。计算图可以帮助我们更清晰地理解计算过程,并方便地进行计算和优化。通过计算图,我们可以将复杂的计算过程拆解为简单的计算步骤,并将其组织起来形成一个有序的流程。每个节点都表示一个计算步骤,节点之间的边表示数据的传递。
计算图的优点之一是可以进行自动微分。通过链式法则,我们可以根据计算图中每个节点的输入和输出,计算相对于输入的梯度。这对于深度学习中的反向传播算法非常重要,可以高效地计算梯度并更新模型参数。
我们来看这样一个很简单的例子:
小明在商场购物,他想为自己买一件上衣和两条裤子,商场举办促销活动,全场商品打七折。上衣原价400元,裤子原价300元,那么小明应该支付多少钱呢?
这是一个十分简单的数学问题,我们通过口算即可得出答案。那么如果我们使用计算图应该如何让表达该问题的计算流程呢?
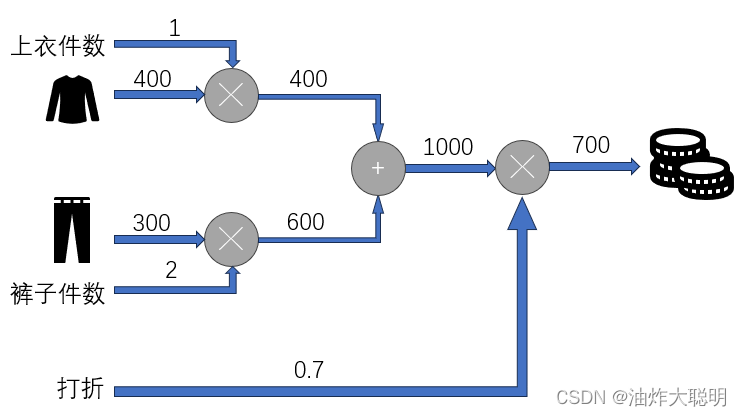
观察我们所得到的计算图,我们将原来需要解决的计算问题分为清晰的三层去解决。在参数数量较少,计算规模较小的情况下,计算图的优势不是很明显。但如果面临的问题规模很大,参数数量庞大的问题,使用计算图可以使问题的计算流程更加清晰,其中分层计算的思想为快速的反向传播算法提供了基础,计算图的特征之一是可以通过局部计算获得最终结果,它只关注与自己相关的某个小范围,使得神经网络可以用层的形式像搭建积木一样组合起来,只需关注相邻层之间的输入输出即可。如果我们不使用以链式法则为基础的误差反向传播算法,每次求解参数都需要找到原始的误差函数进行计算,没有利用到相邻层参数梯度之间的关系,从而进行了大量重复计算,效率低下。
二、链式法则
链式法则是微积分中的一个重要的求导法则,用于计算复合函数的导数。它在求解一些复杂函数的导数时非常有用。
链式法则的表述如下:
如果函数 y = f(g(x)) 是由两个函数 g(x) 和 f(u) 组合而成的复合函数,其中 g(x) 的导数存在且 f(u) 的导数也存在,那么复合函数 y 的导数可以用链式法则表示为:
dy/dx = dy/du * du/dx
其中 dy/du 表示 f(u) 的导数,du/dx 表示 g(x) 的导数,也可以写成 f'(u) 和 g'(x)。
链式法则的直观解释是:复合函数的导数等于外层函数的导数乘以内层函数对自变量的导数。
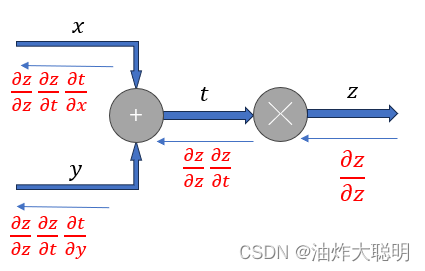
偏导数是多元函数的一个重要概念,用来描述函数关于某个变量的变化率。它和单变量函数的导数类似,但是偏导数只考虑函数关于某个变量的变化,而将其他变量视为常数。
对于一个多元函数,假设有n个自变量x1, x2, ..., xn,如果函数关于其中一个自变量xi的偏导数存在,那么我们可以将其记作∂f/∂xi。∂f/∂xi表示函数f关于变量xi的变化率,而将其他变量视为常数。可以类比单变量函数的导数,偏导数可以表示函数在某一点上的切线的斜率。链式法则对于偏导数同样适用。
三、反向传播算法(BP)
我们根据链式法则对小明买衣服的问题所得到的计算题进行反向传播分析,如下图所示:
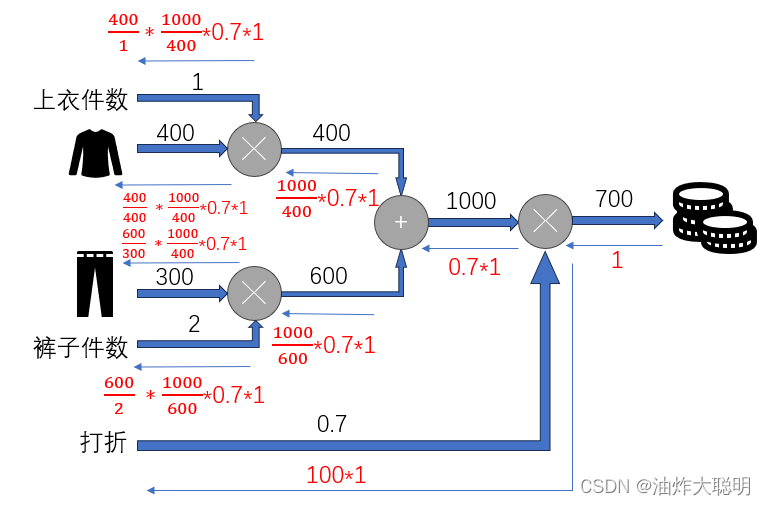
误差反向传播算法(Backpropagation)是一种用于训练神经网络的算法。它的基本思想是通过计算网络输出与期望输出之间的差异(误差),然后将误差向后传播到网络的每一层,根据每一层的权重和激活函数的导数来调整网络的参数,以最小化误差。
具体步骤如下:
-
前向传播:将输入样本数据通过神经网络的每一层,在每一层的神经元中进行加权求和和激活函数处理,得到网络的输出。
-
计算误差:将网络的输出与期望输出进行比较,计算出误差。
-
反向传播:将误差从网络的输出层往前传播到每一层,计算每一层的误差。
-
更新权重:根据每一层的误差和上一层的输出,使用梯度下降算法来更新每一层的权重。
-
重复步骤1-4,直到达到预定的训练停止条件(例如达到最大训练次数或误差达到阈值)。
误差反向传播算法的关键在于误差的反向传播和权重的更新。通过不断迭代训练,可以使网络逐渐调整权重,使得网络的输出与期望输出尽可能接近,从而实现对样本数据的预测和分类。















 491
491











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









