






1. 数据准备与缺失值处理
首先,使用 ucimlrepo 库获取了 UCI 的心脏病数据集(ID=45),并将其特征数据和目标数据转换为 NumPy 数组格式:
<PYTHON>
heart_disease = fetch_ucirepo(id=45)
features_array = heart_disease.data.features.to_numpy()
target_array = heart_disease.data.targets.to_numpy()在处理数据时,发现特征数据中存在缺失值。为了处理这些缺失值,使用了 Scikit-learn 的SimpleImputer 工具,采用众数填补策略:
<PYTHON>
imputer = SimpleImputer(strategy='most_frequent')
imputed_data = imputer.fit_transform(data)
imputed_data1 = imputer.fit_transform(data1)将填补后的数据重新赋值给原始特征数组,确保数据完整性:
<PYTHON>
features_array[:, -2] = imputed_data.reshape(-1)
features_array[:, -1] = imputed_data1.reshape(-1)2. 数据集划分与模型训练
为了构建机器学习模型,将数据集划分为训练集和测试集,其中测试集占 30%:
<PYTHON>
Xtrain, Xtest, Ytrain, Ytest = train_test_split(features_array, target_array, test_size=0.3)使用决策树分类器进行模型训练。在本次实验中,选择了基尼系数(Gini)作为划分标准,未设置最大深度和随机种子,以充分挖掘数据特性:
<PYTHON>
clf = tree.DecisionTreeClassifier(criterion="gini")
clf = clf.fit(Xtrain, Ytrain)3. 模型评估
训练完成后,使用测试集对模型进行评估,并输出准确率:
<PYTHON>
score = clf.score(Xtest, Ytest)print(score)通过这一步骤,可以初步了解模型在未见数据上的表现。
4. 学习曲线分析
为了进一步分析模型的性能,绘制了学习曲线。学习曲线展示了随着训练样本数量的增加,模型在训练集和验证集上的得分变化:
<PYTHON>
train_sizes, train_scores, test_scores = learning_curve(
clf, features_array, target_array, cv=5,
train_sizes=np.linspace(0.1, 1.0, 5)
)通过计算训练集和验证集得分的均值,使用 Matplotlib 绘制学习曲线:
<PYTHON>
plt.plot(train_sizes, train_scores_mean, label="Training score")
plt.plot(train_sizes, test_scores_mean, label="Cross-validation score")
plt.xlabel("Training examples")plt.ylabel("Score")
plt.title("Learning Curve")
plt.legend()
plt.show()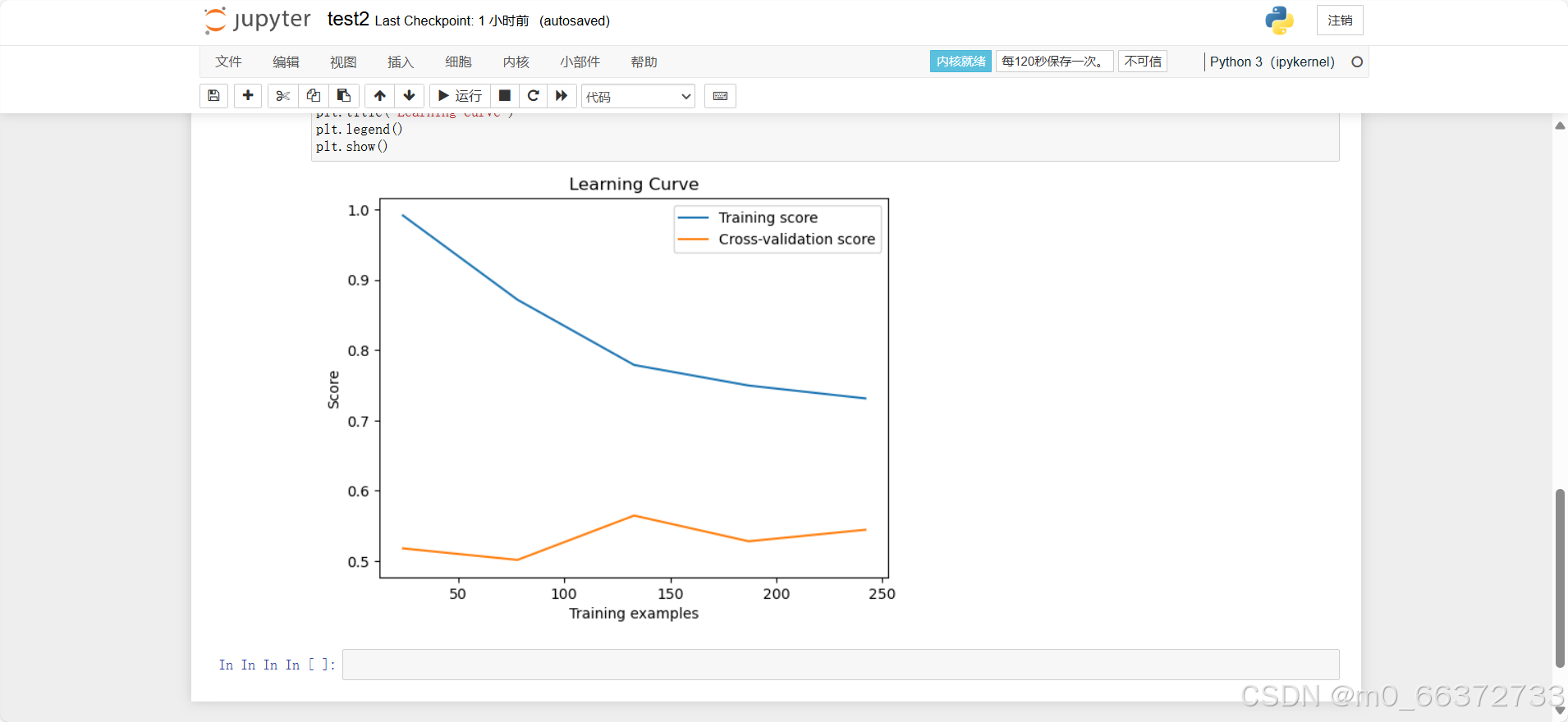 学习曲线的结果可以帮助判断模型是否存在过拟合或欠拟合问题。如果训练集得分和验证集得分都较高且接近,说明模型性能良好;如果两者差距较大,则可能存在过拟合。
学习曲线的结果可以帮助判断模型是否存在过拟合或欠拟合问题。如果训练集得分和验证集得分都较高且接近,说明模型性能良好;如果两者差距较大,则可能存在过拟合。
5. 总结与反思
通过本次实验,我学到了以下知识:
- 数据处理:如何利用
SimpleImputer处理缺失值,确保数据质量。 - 模型构建:如何使用决策树分类器构建机器学习模型,并理解其参数的含义。
- 模型评估:如何通过准确率和学习曲线评估模型性能。
- 可视化:如何通过 Matplotlib 绘制学习曲线,直观展示模型表现。
在实验过程中,遇到了以下问题:
- 数据特征理解不足:对心脏病数据集的具体特征含义不熟悉,可能影响模型参数的调整效果。
- 模型调优不足:本次实验中未对决策树的超参数(如
max_depth、random_state等)进行调优,未来可以尝试网格搜索或随机搜索优化模型。
6. 未来改进方向
- 数据探索与分析:对数据集进行更深入的探索,理解每个特征的含义及其对目标变量的影响。
- 模型调优:通过交叉验证和超参数调优(如
max_depth、min_samples_split等)进一步提升模型性能。 - 特征工程:尝试构建新特征或进行特征选择,提高模型的预测能力。
- 模型比较:尝试其他分类算法(如随机森林、支持向量机等),并与决策树模型进行对比。
通过本次实验,我对机器学习的基本流程有了更深入的理解,同时也认识到数据预处理和模型调优的重要性。未来将继续学习和实践,提升机器学习建模的能力。



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









