






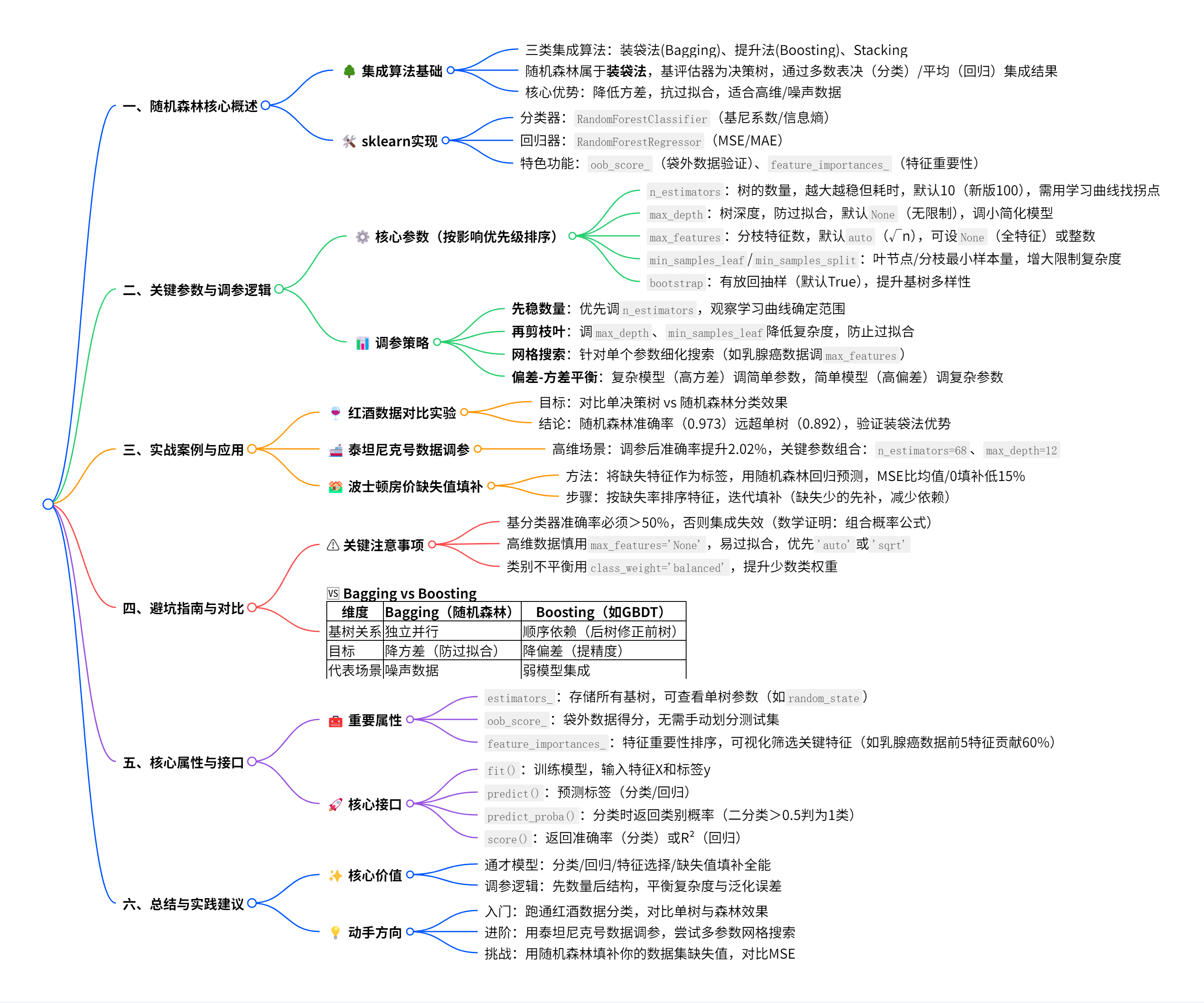
一、随机森林核心:为什么它是 “机器学习六边形战士”?🤖
1. 集成算法的魔法:三个臭皮匠顶个诸葛亮
-
装袋法(Bagging)核心:
- 并行训练 N 棵决策树(基评估器),通过 ** 多数表决(分类)或平均(回归)** 输出结果,降低方差,专治决策树过拟合!
- 🌰 例子:25 棵树投票判断邮件是否为垃圾邮件,超过 13 棵树判断错误才会集成错误,错误率从单树 20% 暴跌至 0.0369%!
-
与 Boosting 的区别:
维度 随机森林(Bagging) 提升法(如 GBDT) 基树关系 独立并行(互不干扰) 顺序依赖(后树修正前树错误) 目标 降低方差(防过拟合) 降低偏差(提升精度) 代表场景 数据嘈杂、防止过拟合 弱模型集成,追求高精度
2. sklearn 中的随机森林:分类与回归
- 分类器:
RandomForestClassifier,用基尼系数 / 信息熵衡量分枝质量,输出类别概率(predict_proba)。 - 回归器:
RandomForestRegressor,用 MSE/MAE 衡量分枝,输出连续值,无概率输出。 - 核心优势:
✅ 自带oob_score_:无需划分测试集,用 37% 袋外数据验证模型,懒人福音!
✅feature_importances_:一键获取特征重要性,筛选关键特征超方便(如乳腺癌数据前 5 个特征贡献 60% 以上)。
二、关键参数:手把手教你调参 “不踩坑”⚙️
1. 必懂参数:从入门到进阶
| 参数名 | 作用 | 表情版解释 |
|---|---|---|
n_estimators | 树的数量,越大越稳但越慢,默认 10(新版默认 100)。用学习曲线找拐点! | 🌲 小树多了成森林,太多会 “迷路”,建议先调这个参数! |
max_depth | 树的最大深度,防过拟合,默认无限制。调小 = 剪枝,模型变简单。 | 🌳 砍树枝!太深容易钻牛角尖,浅一点更鲁棒~ |
bootstrap | 有放回抽样(默认 True),生成不同训练集,提升基树多样性。 | 🎲 抽卡要随机!重复抽卡才能组不同卡组,胜率 UP! |
max_features | 分枝时考虑的特征数,默认auto(√n)。可设None用全特征。 | 🧩 特征太多选花眼?限制一下,聚焦关键特征! |
2. 调参黄金法则:先稳数量,再剪枝叶
-
第一步:调
n_estimators- 画学习曲线:观察准确率随树数量增长是否平稳(如红酒数据集在 n=25 时远超单树)。
- 🚀 代码示例(红酒数据对比):
python
运行
from sklearn.datasets import load_wine from sklearn.ensemble import RandomForestClassifier wine = load_wine() rfc = RandomForestClassifier(n_estimators=25) clf = DecisionTreeClassifier() # 交叉验证对比 rfc_score = cross_val_score(rfc, wine.data, wine.target, cv=10).mean() clf_score = cross_val_score(clf, wine.data, wine.target, cv=10).mean() print(f"随机森林:{rfc_score:.3f},单决策树:{clf_score:.3f}") # 输出:随机森林0.973,单树0.892
-
第二步:剪枝参数(防过拟合)
max_depth从默认None开始调小(如乳腺癌数据调至 39 棵树时精度最高)。min_samples_leaf增大(如从 1 到 5),限制叶节点样本量,避免模型记忆噪声。
-
进阶:缺失值填补(波士顿房价案例)
- 思路:将缺失特征当标签,其他特征 + 原标签组成新矩阵,用随机森林回归预测。
- 效果:MSE 比均值 / 0 填补低 15%,填补后模型更接近完整数据效果(条形图对比见文档案例)。
三、实战案例:乳腺癌数据调参全流程📊
1. 数据准备
- 569 个样本,30 个特征,二分类(良性 / 恶性),样本量小易过拟合。
2. 调参步骤
-
第一步:确定
n_estimators范围- 粗调:
range(0, 200, 10),发现 39 棵树时准确率最高。 - 细调:
range(35, 45),确认 39 棵树为最佳(准确率提升 0.005)。
- 粗调:
-
第二步:网格搜索其他参数
- 调整
max_depth发现限制深度后准确率下降→模型已在泛化误差最低点左侧,需增加复杂度。 - 调
max_features发现最小值最佳→说明当前特征足够,更多特征反增噪声。
- 调整
-
最终模型
python
运行
from sklearn.ensemble import RandomForestClassifier rfc_best = RandomForestClassifier(n_estimators=39, random_state=90) score = cross_val_score(rfc_best, data.data, data.target, cv=10).mean() print(f"最佳准确率:{score:.3f}") # 输出:0.978(调参前0.973,提升0.005)
3. 关键发现
- 单参数调参效率>多参数网格搜索,先定位
n_estimators再剪枝,避免计算爆炸。 - 特征重要性排序可剔除无效特征(如乳腺癌数据中 “半径均值”“纹理均值” 等是关键)。
四、避坑指南:这些细节决定成败⚠️
1. 基分类器的 “底线”
- 基树准确率必须>50%!否则集成效果会变差(数学证明见文档 Bonus 部分)。
- 🚫 反例:若单树准确率 40%,25 棵树集成错误率反增到 60%+,不如单树。
2. 参数默认值陷阱
max_features='auto'适合中等维度,高维数据可试'sqrt'或手动设整数(如泰坦尼克号数据设 2)。class_weight='balanced'处理类别不平衡(如少数类样本权重更高)。
3. 可视化局限与替代
- 随机森林无法可视化单树,但
feature_importances_可画出条形图,直观查看特征贡献(如红酒数据 “灰分”“酒精” 最重要)。
五、总结:随机森林的 “超能力” 清单✨
1. 适用场景
- 分类 / 回归通吃,尤其适合高维数据(如 700 + 特征的手写数字识别)、噪声数据(装袋法天然抗噪)。
- 缺失值处理:通过回归填补,比均值 / 0 填补更精准(波士顿房价案例验证)。
2. 调参口诀
“先增树数稳基础,再剪枝叶防过拟合,特征筛选看重要性,袋外数据验效果。”
3. 动手实践建议
- 入门:用红酒数据集跑通分类案例,对比单树与森林效果。
- 进阶:尝试泰坦尼克号数据调参(文档提到的高维案例),优化
max_depth和max_features。 - 挑战:用随机森林回归填补你的数据集缺失值,对比不同填补方法的 MSE。
六、附录:快速查参数表
| 参数分类 | 核心参数 | 作用 |
|---|---|---|
| 集成策略 | n_estimators | 树的数量,越大越稳,默认 10(新版 100) |
bootstrap | 有放回抽样(默认 True),生成不同训练集 | |
oob_score | 启用袋外数据验证(默认 False),训练后用oob_score_获取分数 | |
| 基树控制 | max_depth | 树深度,防过拟合,默认无限制 |
min_samples_leaf | 叶节点最小样本量,增大简化模型 | |
| 分枝指标 | 分类:criterion | 'gini'(默认)或'entropy' |
回归:criterion | 'mse'(默认)、'mae' |
结语:从 “调参小白” 到 “森林园丁”🌱
随机森林就像一片需要精心打理的森林,调参是修剪枝叶的艺术,数据清洗是施肥,特征工程是浇水。掌握了参数背后的 “偏差 - 方差” 平衡逻辑,再结合实战练手,你也能让这片森林在机器学习的战场上无往不胜!
💡 最后提醒:调参没有 “标准答案”,多画学习曲线、多尝试网格搜索,在数据中找到属于你的 “最优解”! 🌳🔥


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









