







一、GPU硬件与CUDA程序开发工具
1.1 GPU硬件简介
CPU与GPU的结构对比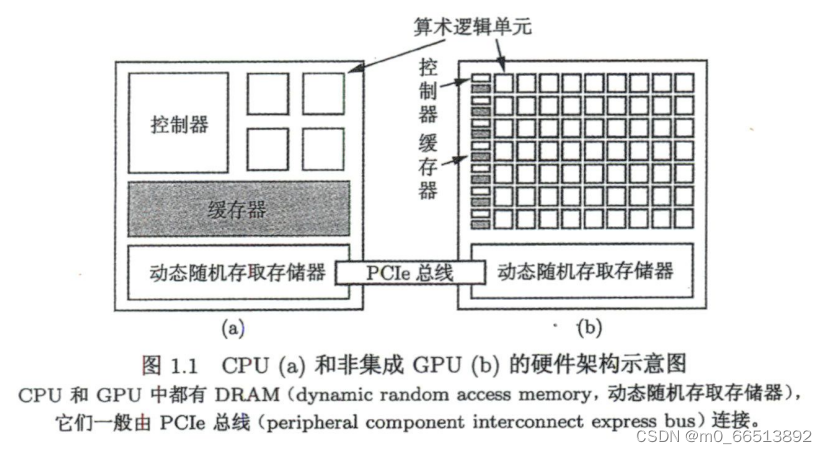
GPU计算不是指单独的GPU计算’而是指CPU+GPU的异构(heterogeneous)计算。
在由CPU和GPU构成的异构计算平台中’通常将起控制作用的CPU称为主机(host),将起加速作用的GPU称为设备(device),主机和(非集成)设备都有自己的DRAM它们之间一般由PCIe总线连接。
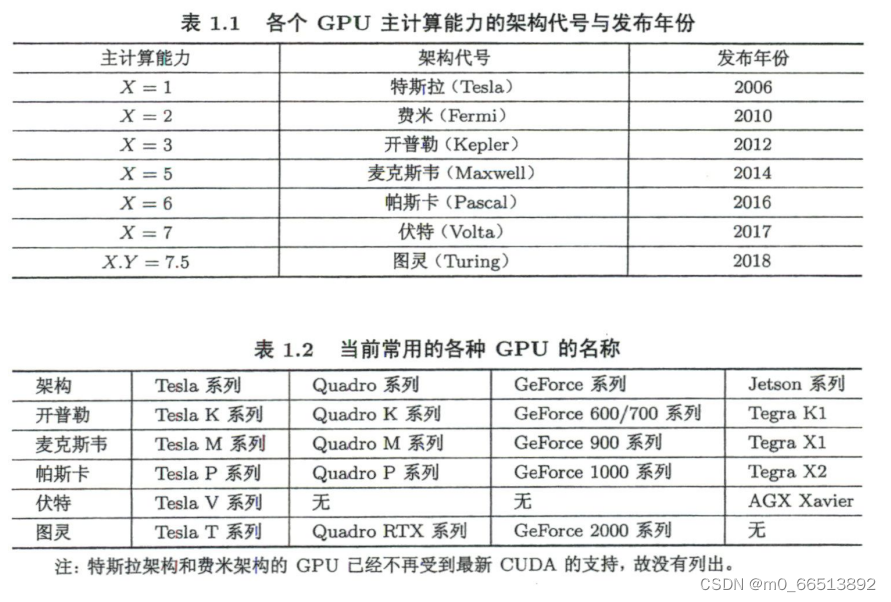
NVIDIA几个系列的GPU:
(1)Tesla系列:其中的内存为纠错内存(error-correctingcodememory,ECC 内存),稳定性好,主要用于高性能、高强度的科学计算。
(2)Quadro系列:支持高速OpenGL(open gaphics library)渲染,主要用于专业绘图设计。
(3)GeForce系列:主要用于游戏与娱乐,但也常用于科学计算。
(4)Jetson系列:嵌入式设备中的GPU。
NVIDIA公司的GPU通常以物理学家命名:
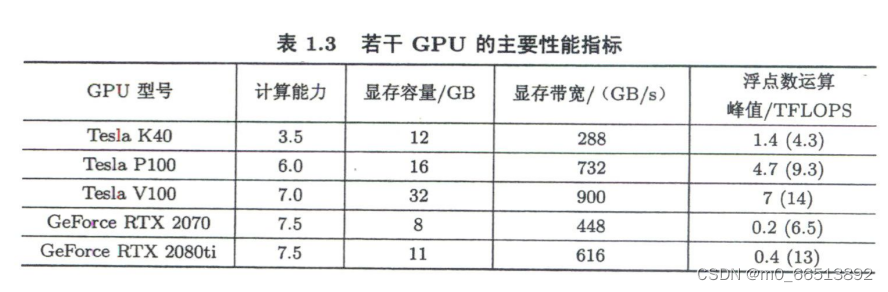
GPU的性能衡量:
表征计算性能的一个重要参数是浮点数运算峰值,即每秒最多能执行的浮点数运算次数(Foating-point operatjons persecond,FLOPS)。TFLOPS:1000000000000FLOPS
1.2 CUDA程序开发工具
(1)CUDA
(2)OpenCL:一个更为通用的为各种异构平台编写并行程序的框架,也是AMD(AdvancedMicroDevices)公司的GPU的主要程序开发工具。
(3)OpenACC:—个由多个公司共同开发的异构并行编程标准。
CUDA简介:
CUDA编程语言最初主要是基于C语言的,但目前越来越多地支持C++ 语言。
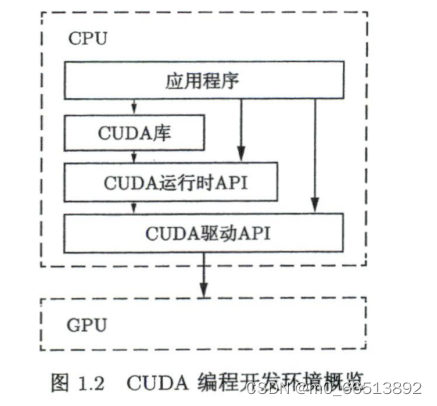
CUDA提供了两层API供程序员使用,即CUDA驱动(driver)API和CUDA运行时(runtime)API。
官方手册资料:https://docs.nvidia.com/cuda
二、CUDA中的线程组织
1、主机函数与核函数
一个CUDA程序中包括CPU执行的程序段与GPU执行的程序段。
CUDA程序的编译器驱动nvcc在编译一个CUDA程序时,会将纯粹的C++代码交给C++的编译器去处理’它自己则 负责编译剩下的部分。
主机函数指的是交给CPU运行的函数,核函数指的是交给GPU完成的函数。
声明核函数用 __global__ void 声明,__global__ void的先后顺序不区分。
如 __globa__void hello_from_gpu()
调用核函数的格式
对于 __globa__void hello_from_gpu()的调用为:
hello_from_gpu<<<grid_size,block_size>>>();
示例程序段:

其中grid_size与block_size是自己定义的GPU中线程组织的网格大小和线程块大小。—个核函数的全部线程块构成—个网格(grid),而线程块的个数就记为网格大小(grid size)。每个线程块中含有同样数目的线程,该数目称为线程块大小(blocksize)。通常grid_size不应大于2的31次方-1,block_size不应大于1024。
线程索引
每个线程在核函数中都有—个唯—的身份标识。由于我们用两个参数指定了线程数目,那么自然地,每个线程的身份可由两个参数确定。
在<<<grid size,blocksize>>>中定义的两个参数的值被放在两个内建变量(built-in variable)中:
(1)gridDim.x:该变量的数值等于执行配置中变量grid_size的数值。
(2)blockDim.x:该变量的数值等于执行配置中变量block-size的数值。
根据上述两个变量,核函数会自动对定义的线程进行id编码,形成另外两个参数:
(1)blockIdx.x:该变量指定—个线程在一个网格中的线程块指标,其取值范围是从0到gridDim.x-1
(2)threadidx.x:该变量指定一个线程在一个线程块中的线程指标,其取值范围是从0到blockDim.x-1。
CUDA编程思路
在执行程序时,我们可以将CPU执行与GPU执行与工人搬砖进行对比。
首先搬砖是一项重复性很高的任务,只需要不断进行一件事,那就是把砖从一楼搬到三楼。
CPU相当于一个大力士一次能搬100kg的砖。当工程需要搬5000kg的砖时,大力士需要对搬砖操作进行500次,用程序表示就是50次的while循环。
而采用GPU执行程序,相当于一个工程队,工程队有250人,虽然每个人每次只能搬20kg的砖,但完成工程只需要一次操作,就是让所有人都搬一次砖。此时就不需要while循环。但需要进行的操作是对每个人进行任务分配,这个任务分配就相当于线程索引。
















 2235
2235











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









