






本篇内容主要包括几个方面:
1.jetson nano的GPU架构
2.线程组织
3.nvprof简单介绍和使用
4.编写简单例子并分析
ps:由于本人之前学习过一些cuda知识,并且cuda内容挺多挺复杂的,所以我主要是结合jetson nano来进行学习的。
jetson nano的GPU架构
jetson nano被定位为一个边缘计算设备,其特点就是轻量,并且仍然有较强的并行处理能力。
线程是被分配到单个的核心上进行计算的,那么GPU上有多少计算核心,是如何进行计算的呢?
在编写程序的时候,会将需要进行并行处理的代码编写为一个kernel,该kernel是送到GPU上给计算核心进行计算的最小单位,一个计算核心同时只能有一个kernel在计算。jetson nano搭载的gpu是Maxwell架构的,只有一个SM(流多处理器),该SM上有128个核心,这128个核心被分为了4个warp,每一个warp有32个核心,每一个warp都有一定的逻辑处理器和寄存器。

另外需要搞清楚一个概念:线程
线程就是一段程序,但该程序从运行到结束都会始终占用一个核心,所以有时候我们会直接把线程和计算核心当一个东西来说,但其实是有区别的。gpu上的计算核心是有限的,但我们可以通过线程组织管理来让有限的核心计算超出核心数量的线程,那就是因为需要计算的线程其实是被按照一个一个的warp来进行组织的,而一个warp会被同时执行,当这个warp执行完毕,会通过warp调度来加载下一个warp进行计算,所以gpu能够高效计算超出计算核心数量的线程。
总结:jetson nano平台上,cpu有4个计算核心。gpu有128个核心(被分成了4个warp)。
线程组织
一个kernel执行需要多少线程是由处理的数据来决定的。比如需要处理两个258维向量相加,那么一个线程用来处理向量中一个数据相加,那么总共就需要计算256次,但是计算核心只有128个,所以同时是不可能计算完的,那我们就可以通过将256个线程分配成两批,一批128个线程刚好使用128个核心计算,然后每一批的128线程刚好使用满计算核心能够一次计算完成。
线程的层次结构:
grid:一个kernel所有的线程组成一个grid;
block:一个grid被分为多个block,一个block被分配到一个SM上进行计算;
thread:一个block由多个thread组成。
由于jetson nano上只有一个SM,所以组织出来的所有block会全部通过硬件调度全部都在这一个SM上计算,但一次只能有一个block在SM上计算,所以在某个block在计算时,后面的block需要等待。
当一个block被调度到SM上后,该block会被划分为以32个线程为一个warp(线程束)。warp是gpu调度的最小单位,为什么这么说呢?因为在一个block被调度到SM上后,一个block会被划分为很多warp,但从硬件上来看一个SM同时只能够运行4个warp,当这4个warp中有运行结束的,会有调度器将满足条件的warp装载到SM上进行计算,而一个warp里面的线程都是同时被装载到SM上,并且同时运行结束的,所以一个warp是调度和运行的最小单位,而不是线程。
nvprof使用
#include <stdio.h>
__global__
void test(){
printf("hello world\n");
}
int main(){
dim3 grid(1,1);
dim3 block(5,5);
test<<<grid,block>>>();
cudaDeviceSynchronize();
return 0;
}
这段代码就是使用gpu实现并行的运行kernel。现线程组织方面,我组织为了一个二维的grid,该grid内有1*1=1个block;block也是二维的,每一个block内有线程数量为5*5=25,所以总共组织了1*25=25个线程运行这个kernel函数。所以当运行该代码时,总共会打印出25条hello world。
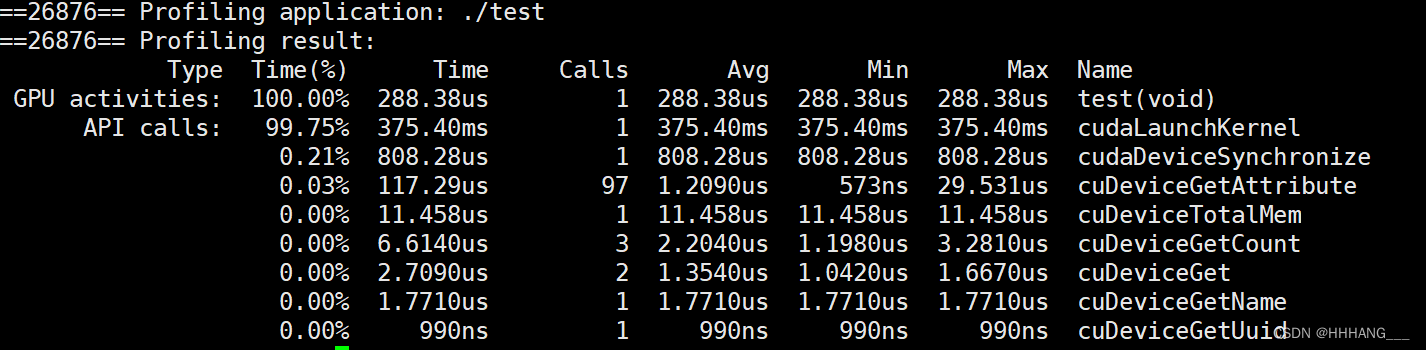
具体应该是nvprof能够分析gpu的活跃程度,以及各个api的运行时间。















 385
385











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









